 ,1,2, 陆忠华,1,*, 张鉴,1, 刘夏真,1,2, 袁武,1,2, 梁姗,1
,1,2, 陆忠华,1,*, 张鉴,1, 刘夏真,1,2, 袁武,1,2, 梁姗,1Parallel Optimization of CFD Core Algorithms Based on Domestic Processor
CAO Yikui,1,2, LU Zhonghua,1,*, ZHANG Jian,1, LIU Xiazhen,1,2, YUAN Wu,1,2, LIANG Shan,1通讯作者: *陆忠华(E-mail:zhlu@sccas.cn)
收稿日期:2021-03-3
| 基金资助: |
Received:2021-03-3
作者简介 About authors

曹义魁, 中国科学院计算机网络信息中心,在读硕士生,主要研究方向为高性能计算与应用。
本文承担工作为:负责CCFD V3.0程序在国产加速器上的移植、优化与应用测试。
CAO Yikui is a master student at CNIC. His activities mainly focus on high perfor mance computition.
In this paper, he is mainly responsible for transplantation, optimization and application test of CCFD V3.0 program on domestic processors.
E-mail:

陆忠华,中国科学院计算机网络信息中心,博士,研究员,主要研究方向为网格计算、高性能计算与应用。
本文承担工作为:CCFD V3.0程序开发指导。
LU Zhonghua, Ph.D., is a reserch fellow at CNIC. Her activities mainly focus on grid computing and high performance computition.
In this paper, she is mainly responsible for development gui-dance of CCFD V3.0 program.
E-mail:

张鉴,中国科学院计算机网络信息中心,博士,研究员,主要研究方向为科学计算、高性能计算。
本文承担工作为:CCFD V3.0程序移植、优化指导。
ZHANG Jian, Ph.D., is a reserch fellow at CNIC. His activities mainly focus on scientific computing and high performance computition.
In this paper, he is mainly responsible for transplantation and optimization guidance of CCFD V3.0
E-mail:

刘夏真,中国科学院计算机网络信息中心,在读博士,主要研究方向为高性能计算,计算流体力学。
本文承担工作为:CCFD V3.0程序移植与优化指导,正确性验证。
LIU Xiazhen is Ph.D. candidate at CN-IC. He works in high performance com-putition and computational fluid dyna-mics.
In this paper, he is mainly responsible for transplantation and optimization guidance of CCFD V3.0 and the correctness veri-fication.
E-mail:

袁武,中国科学院计算机网络信息中心,博士,副研究员,主要研究方向为高性能计算,计算流体力学。
本文承担工作为:CCFD V3.0程序移植、优化指导。
YUAN Wu, Ph.D., is an associate research fellow at CNIC. He works in high perfor-mance computition and computational fluid dynamics.
In this paper, he is mainly responsible for transplantation and optimization guidance of CCFD V3.0.
E-mail:

梁姗,中国科学院计算机网络信息中心,博士,高级工程师,主要研究方向为高性能计算,计算流体力学。
本文承担工作为:CCFD V3.0程序移植、优化指导。
LIANG Shan, Ph.D., is a senior engin-eer at CNIC. Her activities mainly focus on high performance computition and computational fluid dynamics.
In this paper, she is mainly responsible for transplantation and optimization guidance of CCFD V3.0.
E-mail:

摘要
【目的】为了加快国产CFD软件的计算速度,本文设计并实现了基于国产加速器的加速版本。【方法】基于CCFD V3.0版本,将软件的核心算法移植到国产加速器,并采用多种方法进行优化。【结果】使用128*128*128大小的网格进行实验,移植后的程序模拟结果与原CPU版本基本一致,单加速卡相比于单CPU核心,对流项计算部分取得了166倍的加速,ADI迭代计算部分取得了59倍的加速。【局限】由于CFD软件模块较多,未对整个程序进行移植优化,未来会将软件都移植到国产加速器上进行加速。【结论】本文实现了基于国产加速器的CFD核心算法并行优化,取得了较好的加速效果,为以后CFD软件的移植与优化工作提供了经验和参考。
关键词:
Abstract
[Objective] In order to accelerate the calculation of domestic CFD software, this paper designs and implements an accelerated version of CFD core algorithms based on the domestic processor. [Methods] Based on the CCFD V3.0 version, the core algorithms of the software were ported to the domestic processor and optimized by various methods. [Results] Using a 128*128*128 grid for experiments, the simulation results of the ported program are basically the same as the original CPU version. Compared with a single CPU core, one acceleration card has achieved 166 times acceleration on convection calculations, and 59 times acceleration on ADI iterative calculations. [Limitations] Because there are many modules in CFD software, the target CFD program has not been ported and optimized entirely. In the future, the software will be ported completely to the domestic processors for acceleration. [Conclusions] This article has realized the parallel optimization of the CFD core algorithms based on domestic processors and achieved good acceleration results, which provides experience and reference for porting and optimizing CFD software in the future.
Keywords:
PDF (8216KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
曹义魁, 陆忠华, 张鉴, 刘夏真, 袁武, 梁姗. 面向国产加速器的CFD核心算法并行优化[J]. 数据与计算发展前沿, 2021, 3(4): 93-103 doi:10.11871/jfdc.issn.2096-742X.2021.04.008
CAO Yikui, LU Zhonghua, ZHANG Jian, LIU Xiazhen, YUAN Wu, LIANG Shan.
引言
计算流体动力学(Computational Fluid Dynamics, CFD)是一门新兴的交叉型学科,它结合数学中的离散方法,利用计算机强大的算力对流体力学中复杂的微分方程进行求解,在科研和工程领域都发挥着巨大的作用。目前的CFD商业软件、开源CFD软件等,大多数是基于CPU开发的。但随着计算规模的不断扩大,CPU的计算、访存及通信性能已经不能满足人们的需要[1],所以寻求新的方法实现对大规模数据进行并行处理已经成为国产CFD软件发展的必要条件。CPU+加速器异构架构的出现,为人们解决复杂的大规模计算提供了新的方法,它充分集合了CPU和加速器的各自优势特点,将具有并行性的计算密集部分放到加速器上进行加速,极大的提高了程序的运行速度,这也成为了目前高性能计算的主流方法[2]。为了能够充分利用加速器的性能,需要针对程序中的算法特点设计具有高并行度、高访存带宽的并行方法。国内外已有较多将CFD应用移植到CPU+加速器异构平台并进行优化的相关研究。
Corrigan 等[3]基于CPU/GPU异构平台对流体力学中的格子玻尔兹曼方法实现了并行加速,并采用多种方法实现了简单高效的数据访存模式,使全局访存带宽利用率达到了86%,相应程序也得到33.6倍的加速效果。Jespersen[4]设计并实现了基于对称逐次超松弛方法的CFD软件的GPU并行方案,并对其中的Jacobi迭代部分进行了并行加速,单GPU卡相对于单CPU核心实现了大约3倍的加速效果。李大力等[5]针对高阶精度加权紧致非线性格式的CFD软件,实现并优化了Jacobi解法器的 GPU并行计算,与单CPU核心相比运行时间加速了9.8倍。董廷星等人[6]利用GPU加速计算流体力学中经典的N-S(Navier-Stokes)方程和欧拉(Euler)方程的求解,并采用3个测试算例进行实验,单GPU卡相对于单CPU核心最高能得到33.2倍的加速效果。邓亮等人[7]基于ADI解法器的有限体积CFD应用,设计了两种GPU并行方案,并讨论了若干性能优化方法,使整个CFD应用得到了17.3倍的加速效果。V.Emelyanov[8]在GPU上开发了基于有限体积法的非定常可压缩的欧拉方程和N-S方程求解器,并利用精简计算、访存优化等方法对GPU程序进行优化,最终得到20~50倍的加速效果。此外,他们还在GPU上对不同声速下的翼型外流场进行了数值模拟[9]。Lai等[10]基于CPU/GPU异构平台,利用雷诺数为118的双椭球绕流问题验证了可压缩NS方程求解器的计算能力,并从数据传输方面对程序进行了优化。随后,他们又设计了高效的多GPU并行算法对高超声速流场进行了研究,当使用4张GPU加速卡时,可以获得147倍的加速[11]。党冠麟等[12]基于CPU/GPU异构系统,利用自主开发的高精度有限差分CFD求解器,对钝锥边界层转捩问题进行了数值模拟,并对核函数进行了细致的优化,单GPU卡相对单CPU核心获得了60倍的加速。
以上工作都是在CPU+GPU的异构系统上完成。为了打破高性能行业的技术封锁,近年来国家高度重视国产高性能计算机的发展,并取得了突出成就,多次斩获超级计算TOP500榜单首名,并且我国在E级超级计算机系统的研发上也处于世界领先地位。使用国产加速器替代GPU等加速器已经成为一种必然趋势[13]。本文利用CPU+国产加速器的异构系统对国产自主CFD软件进行加速,国产加速器采用类GPU体系架构,相关资料尚未被授权公开,此处对其架构不展开介绍。国产加速器可以完全兼容运行在GPU上的CUDA程序,其优化思路也大致和GPU相同。
1 CFD软件介绍
1.1 CFD软件计算流程
本文中用于移植的CFD软件的初始版本是CCFD V3.0,此软件全部用Fortran语言编写。CCFD系列软件是国家“863计划”“十一五”和“十二五”连续支持的面向大型飞机设计的大规模流场数值模拟软件[14],也是“863计划”中我国集中科研资源重点发展的高性能计算软件之一[15]。课题组在CCFD V1.0和V2.0的基础上,瞄准国产高性能计算平台发展V3.0版本,并在神威-太湖之光等平台上开展了相关研究。CCFD V3.0软件的计算流程主要包括三个阶段,如下图1所示:图1
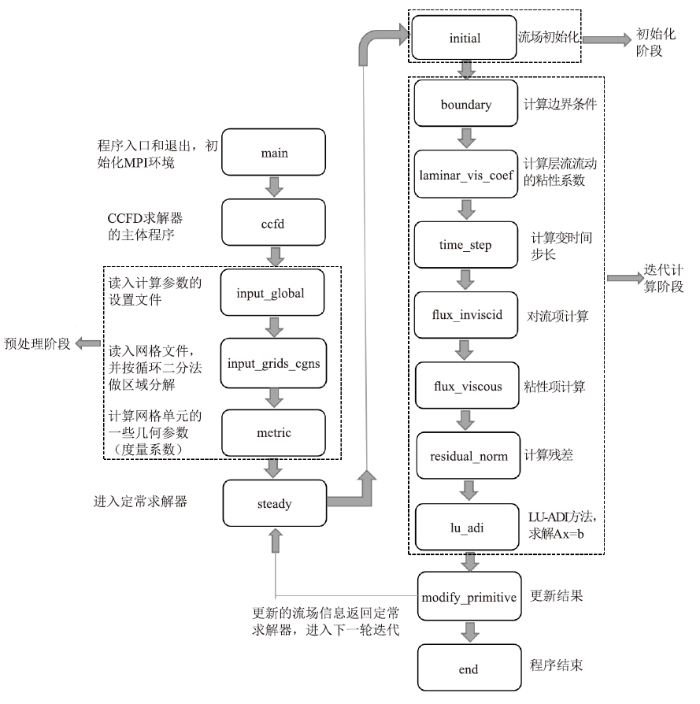 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1CCFD V3.0软件定常计算流程图
Fig.1CCFD V3.0 software steady state calculation flow chart
(1) 预处理阶段。主要进行网格划分,设置计算参数,进行度量系数的计算。
(2) 初始化阶段。进行流场信息的初始化,处理初始边界条件。
(3) 迭代计算阶段。包括边界更新、时间推进、对流项的计算、方程求解等模块。
1.2 CFD核心算法
根据程序特点,本文对CCFD V3.0的定常求解器steady部分做了移植。经过测试发现,flux函数部分和lu_adi函数部分约占整个程序运行时间的90%,所以本文主要介绍有关对流项计算的flux函数部分以及使用LU_ADI算法求解的lu_adi函数部分,这两部分也是整个CFD求解器的核心部分。对流项的空间离散方法在CFD计算中至关重要,它不仅会影响计算的稳定性,对计算结果在精度上也会有很大影响。CCFD V3.0软件集成了多种国际上评价较高的上风格式(Roe's FDS[16]、Van Leer's FVS[17]、AUSM+[18])和Jameson中心格式[19]。其中,本文研究是Roe's FDS格式,它是基于黎曼解的通量差分分裂格式,是目前使用最广泛、评价最高的迎风格式之一。
时间推进方法上,工程CFD软件普遍采用隐式算法,典型的隐式算法有对角化方法、交替隐式追赶方法(ADI)[20]和LU-SGS[21]方法等。其中,交替方向隐式追赶方法(ADI)对通过系数矩阵在三个方向上作近似因子(AF)分解,并基于LU分裂将方程求解分为上下三角的两个子过程,稳定性好且计算效率高,在不要求时间精度的定常计算中应用广泛。
flux函数的对流项计算部分是典型的模版计算,lu_adi函数中的LU_ADI算法是典型的数据依赖方法,这两部分是CFD软件基础算法的主要部分。由于推导过程会占据大量篇幅,所以此处不再赘述,本文只在下文相应章节处给出具体的相应代码,详细的公式推导及具体算法介绍见参考文献18。
2 核心算法并行方案
国产加速器架构类似于GPU,都是通过将数据分散到成千上万个小的计算核心实现并行加速。本文的移植方案先将软件移植到CPU+GPU异构系统得到基础版本,之后再移植到国产加速器上进行优化。GPU使用CUDA编程模型[22],线程按照线程格(Grid)、线程块(Block)、线程(Thread)的多层次模型进行组织。其中,Block以三维的形式组织在同一个Grid内,Thread以三维的形式组织在同一个Block内,并分别通过内置变量blockIdx(x,y,z)和threadIdx(x,y,z)进行标识,从而可以对每个线程进行索引。
下面将分别介绍flux函数和lu_adi函数两部分在GPU上的并行方案。
2.1 flux 函数的GPU并行方案
对流通量项计算函数(flux函数)是一个典型的模版计算函数,每个网格数据点的计算都是独立进行的,仅需要将相应网格点的数据映射到GPU上的单个线程,可以实现高效的三维并行,具体的映射关系如图2所示。根据flux函数的计算流程,将每个方向的计算都拆分成了4个核函数,分别命名为flux_kernel1-flux_kernel4,拆分的作用是为了实现对内点和边界点的分别计算以及数据计算的最大并行。图2
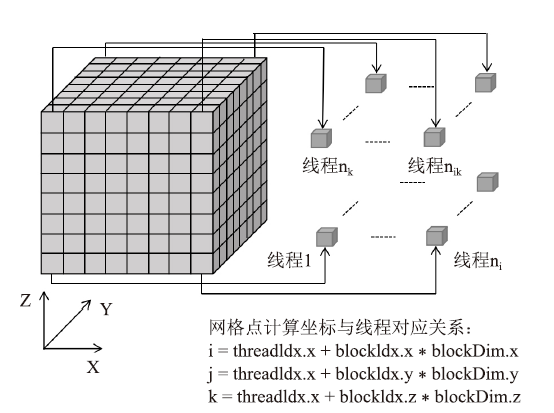 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2右端项计算的线程映射
Fig.2Thread mapping of right end item calculation
2.2 lu_adi函数的GPU并行方案
在CPU版本中,lu_adi函数分别在X、Y、Z三个方向利用LU_ADI方法求解三维定常可压缩N-S方程。该算法最大的特点是在每个计算方向上都存在强数据依赖性,网格中任一内点的更新都需要自身点和同一条网格线上邻点参与计算,且需要往返各更新一次,具体的计算方式如下图3所示。图3
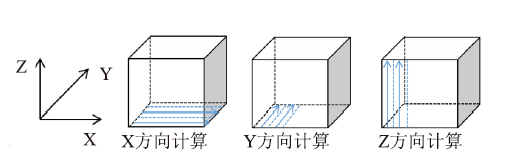 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3ADI迭代计算
Fig.3ADI iterative computation
针对上述ADI算法特点,对lu_adi函数中没有数据依赖的计算部分仍采用三维并行,网格数据与线程的映射和图3相同。而对lu_adi函数中具有强数据依赖性的计算部分,只能在没有数据依赖的另外两个方向上实现两维并行,有数据依赖的方向使用循环串行执行,每个线程负责控制一条网格线上相关点的计算,具体的网格数据与线程的映射关系如图4所示。本文根据lu_adi函数特点,将每个方向的计算都拆分成了5个核函数,分别命名为ADI_kernel1-ADI_kernel5,拆分的目的是为了实现数据计算的最大并行化。
图4
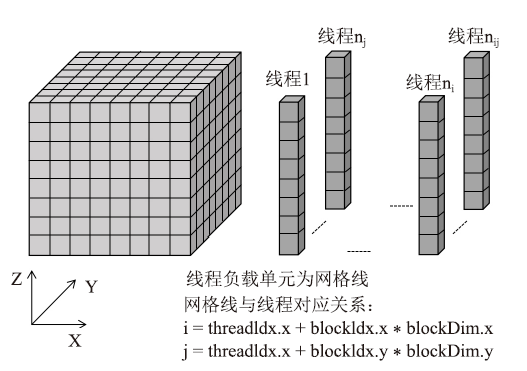 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4LU_ADI迭代计算的线程映射
Fig.4Thread mapping of LU_ ADI iterative calculation
3 基于国产加速器的性能优化策略
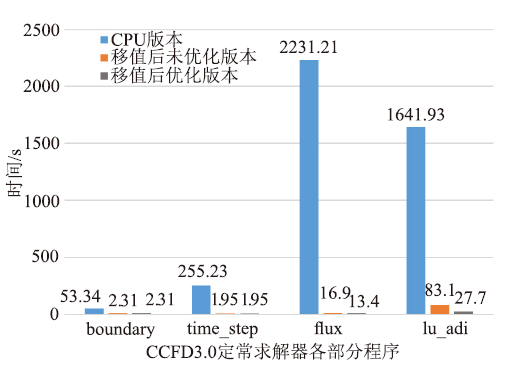
利用上述并行方案实现了GPU的加速版本后,再通过国产加速器自带的转码工具将程序移植到国产加速器,得到了移植后的基础版本。使用128立方的三维网格进行测试,单加速卡相对于单CPU核心,移植前后flux函数部分的运行时间从2231.21s降为16.9s,加速了132倍,lu_adi函数部分的运行实践从1641.93s降到83.1s,加速了19.7倍。但此基础版本仍有很大的优化空间,后续本文会基于国产加速器架构特点,充分利用国产加速器上寄存器、共享内存等内存资源,采用核函数合并与分解、访存合并、调整块大小等方法对移植后的程序进行优化。3.1 核函数的分解与合并
在对核函数进行优化时,应充分利用寄存器资源进行计算。但是寄存器资源非常稀少,所以当核函数过大,中间变量过多时,可以采用拆分核函数的方法,减少同一个核函数内寄存器的使用数量,从而增大线程块并发的数量。当核函数规模较小,中间变量较少,可以将相关核函数进行合并,在保证线程块具有较高并行性的情况下,充分利用寄存器资源。本课题中对lu_adi函数进行了相关优化,lu_adi函数共由五个核函数组成,前两个核函数ADI_kernel1和ADI_kernel2的计算中有大量中间数组的重复使用。针对此特点,可以将这些使用到的中间数组数据用寄存器存储起来,之后的相关计算也都在寄存器上进行。此外,ADI_kernel2核函数中的一些计算可以合并到ADI_kernel1核函数中,并且不会对程序结果产生影响。通过测试发现,将这两种优化方法结合起来使用,这两个核函数的总时间从16.54秒降到10.95秒,速度提升了33.8%。3.2 全局访存的合并与对齐
通常情况下,计算数据都是存储在加速器的全局内存(Global Memory)上,并且内存带宽往往是影响程序性能的主要因素。因此,设计较好的访存模式实现较高的访存带宽对程序的优化至关重要。在GPU上核函数的内存访问是在物理设备内存和片上内存间以128字节或32字节内存事物来实现的,在国产加速器上的访存机制与GPU类似。为了最大化带宽利用率,我们可以对程序的访存模式进行设计,将设备内存事务的首地址设置为128字节的偶数倍,并让同一线程束内连续的线程获取连续的内存数据,从而实现访存的合并与对齐,提高核函数的运行速度。在我们的程序中,以ADI_kernel3_i核函数为例,原程序中对残差数组三个维度的计算都从第三个点开始,其对数据的访问是非对齐的。为了实现合并对齐访问,我们对x方向的计算仍从第三个点开始,另外两个方向的计算都从第一个点开始,这样既不会影响程序的正确性,又可以实现对全局内存的合并对齐访问。经过这样的优化后,ADI_kernel3_i核函数的运行时间从1.86s降为1.58s,性能提升了15%。3.3 共享内存的使用
共享内存是国产加速器上的一块具有固定大小的可编程缓存,与全局内存相比,它具有较低的访存延迟和较高的内存带宽。存储在共享内存上的数据可以被同一个线程块内的线程共享。国产加速器的一个计算卡上有64kB的共享内存,当数据是双精度浮点类型时,一个核函数使用的共享内存数组大小不能超过8192。根据程序特点,使用共享内存存储全局内存数据,可以减少对Global Memory不必要的频繁访问,提升程序的整体性能。特别是一些具有数据依赖的计算,使用共享内存进行优化是优先选择。但是使用共享内存时还要注意避免bank冲突,通常解决bank冲突的方法是对数据进行内存填充,改变数据到共享内存存储体的映射。此外,还可以利用共享内存对内存访问模式进行设计,以便实现访存的合并。3.3.1 对lu_adi函数使用共享内存优化
在本课题中,lu_adi函数的数据依赖部分主要集中在第四个核函数ADI_kernel4,并且对i方向数据的访问是非合并的,具体的计算形式如下所示。

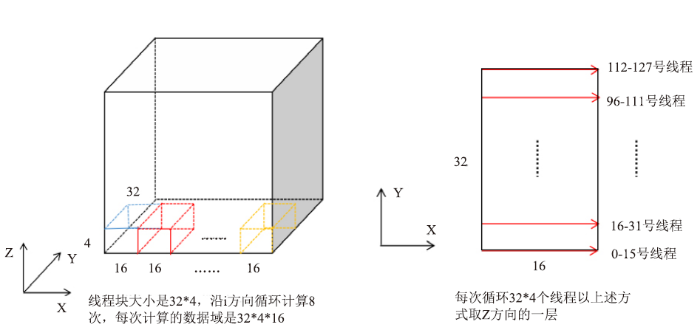
针对i方向访存不连续的问题,本文使用共享内存设计了一种实现合并的内存访问模式。由于一个核函数的共享内存大小不能超过64kB,所以沿i正向计算时使用三个大小为4*32*17的共享内存数组,分别存放res、flmp和diag数组,并且控制连续的16个线程访问连续的16个全局内存数据,将其存储到共享内存数组中,这样便实现了合并访存。i方向的每一条网格线分成n次来计算,n的大小由网格大小确定。每次循环沿i方向取16个数据,并且在进行下次计算之前将需要用到的数据提前存放到共享内存数组中,这也是将共享内存数组的最后一个维度声明为17的原因。n次循环之后,一个线程实际负责了一条网格线上数据点的计算,反向计算原理相同。此外,n次循环中,每次取数据之后要进行同步,计算之后也要进行同步,否则可能会出现未知错误,同步的方法是使用syncthreads()函数,此函数的作用是同步同一线程块内的线程操作。设计的具体访存模式如图5所示。
图5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5ADI_kernel4核函数i方向访存模式
Fig.5ADI_ Kernel4 kernel function i-direction memory access mode
而对于j、k方向数据的访存本就是合并的,使用共享内存仅仅只能减少对全局内存的访存次数,而使用寄存器可以达到同样的效果,并且比共享内存更加方便,所以对j、k方向使用寄存器进行计算,每次沿相应方向连续更新计算一条网格线上的所有点。使用此方法进行优化后,ADI_kernel4部分实现了5.4倍的加速。
3.3.2 对flux函数使用共享内存优化
flux函数中的第一个核函数flux_kernel1的计算需要用到相同数组的相邻两点,具体计算形式如下所示。

并且数据的访问已经实现了合并与对齐,利用共享内存可以减少对全局内存的访问次数,从而减少程序的运行时间。具体方案和对ADI_kernel4的优化思路大致相同,不同之处在于使用的共享内存数组大小为4*8*33,并且没有循环过程,也没有数据依赖。使用共享内存进行优化后,flux_kernel1部分相比原来的版本实现了28%的加速。
3.4 调整线程块的大小
线程块大小会影响每个线程所能分配的内核资源,从而影响整个程序的并发性。调整线程块大小是比较基础的优化方法,当已经使用了其他优化方法或者找不到更好的优化方法时,对线程块大小进行调整通常可以取到一定的效果。本课题对lu_adi函数中有关i方向计算的两个比较简单的核函数ADI_kernel1_i和ADI_kernel5_i采用此方法进行优化,并取得了一定的加速效果。具体的线程块配置如表1所示。Table 1
表1
表1ADI_kernel1_i和ADI_kernel5_i在不同线程块大小下的运行时间
Table 1
| Block大小 | ADI_kernel1_i | ADI_kernel5_i |
|---|---|---|
| 32*4*1 32*8*1 32*4*2 32*4*4 32*8*2 32*8*4 | 2.86 s 2.26 s 2.31 s 2.64 s 2.16 s 2.26 s | 1.84 s 1.58 s 1.69 s 1.18 s 1.25 s 1.04 s |
新窗口打开|下载CSV
从图中可以看到,相同的线程块大小配置对于不同的核函数影响是不同的。ADI_kernel1_i核函数中计算操作较多,用到了较多的寄存器,使用32*8*2的线程网格大小既可以增大每个线程分配的寄存器的资源,又可以得到最大的并行性,所以其加速效果也最好。而ADI_kernel3_i核函数中计算较少,主要是读写内存操作,使用32*8*4的线程网格可以保证其最大并行性。所以,对每个核函数应根据自身特点,合理设计线程块大小,设计相应核函数的最佳线程块配置,而不应该采用统一的线程网格大小。
4 实验结果与分析
4.1 实验平台
在CPU+国产加速器异构平台进行测试,系统环境配置:国产x86处理器(32核心),内存容量为128GB DDR4,国产加速器具有16GB HBM2显存,带宽1TB/s。本文采用Intel编译器编译Fortran程序,使用国产加速器自带的编译器编译移植后的程序,并且使用“-O2”优化,最终将编译后的文件用ifort命令进行链接生成可执行文件。在CPU上所进行的运算只使用单核,国产加速器上使用单张加速卡进行加速。4.2 正确性验证
本文的算例是求解三维方腔流问题,使用了128*128*128和256*256*128两种规模的网格模型进行测试,其中网格的最外面两层为虚网格点,其作用是用来更新内点,网格数据全部为双精度,设置定常迭代步数为2000。通过打印输出原CPU程序和移植优化后的最终全部流场信息,验证移植与优化的正确性。两种测试结果表明,移植前后全部流场信息的绝对误差的最大值都控制在小数点后15位,完全满足工程上的精度要求。4.3 实验结果
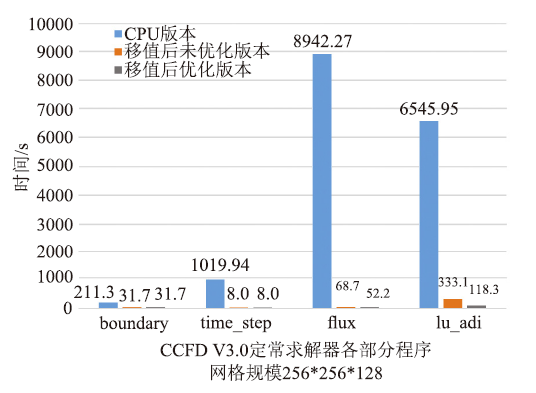
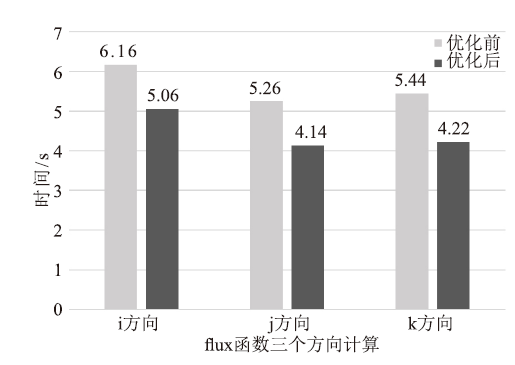
本文采用两套不同网格规模进行测试,图6和图7给出了两种网格移植前后CCFD V3.0程序各部分的运行时间对比。通过对测试结果的初步分析,发现128立方大小的网格和256*256*128大小的网格的优化效果基本一致。限于篇幅,本文只给出128立方大小网格详细的优化结果。表2是对ADI_kernel1和ADI_kernel2采用核函数的合并与分解方法的具体优化效果,表3、表4分别是对ADI_kernel4、flux_kernel1核函数使用共享内存方法优化的三个方向优化效果。图8和图9分别给出了移植的初始版本和综合使用上述几种优化方法后,flux函数和lu_adi函数各个方向计算的最终时间对比。图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6CCFD V3.0三个版本程序时间对比,网格规模:128*128*128
Fig.6Time comparison of three versions of CCFD V3.0,grid size:128*128*128
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7CCFD V3.0三个版本程序时间对比,网格规模:256*256*128
Fig.7Time comparison of three versions of CCFD V3.0,grid size:256*256*128
Table 2
表2
表2ADI_kernel1和ADI_kernel2优化效果
Table 2
| i方向 | j方向 | k方向 | 总时间 | |
|---|---|---|---|---|
| 优化前 优化后 | 5.63 s 3.77 s | 5.44 s 3.50 s | 5.47 s 3.69 s | 16.54 s 10.95 s |
新窗口打开|下载CSV
Table 3
表3
表3ADI_kernel4核函数三个方向优化效果
Table 3
| i方向 | j方向 | k方向 | 总时间 | |
|---|---|---|---|---|
| 优化前 优化后 | 35.91 s 3.41 s | 3.55 s 2.86 s | 1.71 s 1.40 s | 41.17 s 7.67 s |
新窗口打开|下载CSV
Table 4
表4
表4flux_kernel1核函数三个方向优化效果
Table 4
| i方向 | j方向 | k方向 | 总时间 | |
|---|---|---|---|---|
| 优化前 优化后 | 1.13 s 0.83 s | 1.11 s 0.83 s | 1.18 s 0.80 s | 3.42 s 2.46 s |
新窗口打开|下载CSV
图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8flux函数优化前后时间对比
Fig.8Comparison of time before and after optimization of flux function
图9
 新窗口打开|下载原图ZIP|生成PPT
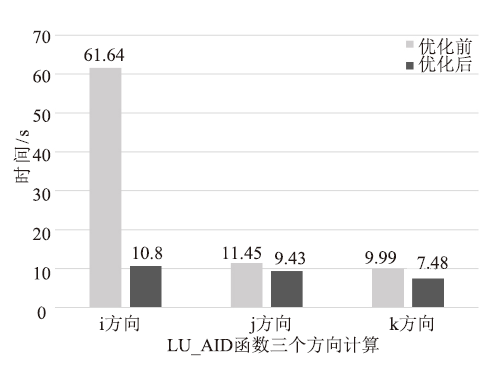
新窗口打开|下载原图ZIP|生成PPT图9lu_adi函数优化前后时间对比
Fig.9Comparison of time before and after optimization of lu_adi function
从上述图表可以看出将移植到国产异构系统可以对程序的性能有明显的提升,并且采用上述优化方法进行优化后,程序性能会进一步得到提升。其中,对lu_adi函数i方向的相关计算在优化后的性能提升最明显,这是因为i方向的数据在初步移植后的访存是非合并的,优化后实现了访存的合并,性能得到了很好的提升。
5 实验结果与分析
本文将CCFD V3.0软件的定常求解器部分移植到国产异构平台,并针对CFD软件的主要核心算法,对flux函数部分和lu_adi函数部分实现了在国产异构平台上的并行优化。根据异构平台特点,使用了寄存器、共享内存、对核函数进行合并与分解、实现访存的合并与对齐、调整线程块大小等优化方法,对移植后的程序进行优化,最终取得了很好的加速效果,flux函数部分实现了166倍的加速,lu_adi函数部分实现了59倍的加速,整个CCFD V3.0程序实现了90倍的加速(国产加速器上的单个加速卡相对于单个CPU核心)。下一步将整个CCFD V3.0程序移植到CPU+国产加速器的异构平台,并将上述优化方法应用到软件的其它模块中,从而对整个CCFD V3.0应用程序实现更好的加速效果。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.camwa.2010.01.054URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1155/2010/564806URL [本文引用: 1]
[C/OL]. [
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C]
[本文引用: 1]
[C]
[本文引用: 1]
[本文引用: 1]
[J].
DOI:10.1016/j.compfluid.2003.10.004URL [本文引用: 1]
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}