 ,1,4,*
,1,4,*Direct Numerical Simulation of Hypersonic Turbulence Based on CPU/GPU Heterogeneous System Architecture
Dang Guanlin1,4, Liu Shiwei3,4, Hu Xiaodong2, Zhang Jian2, Li Xinliang,1,4,*通讯作者: * 李新亮(E-mail:lixl@imech.ac.cn)
收稿日期:2019-12-6网络出版日期:2020-02-20
| 基金资助: |
Received:2019-12-6Online:2020-02-20
作者简介 About authors

党冠麟,中国科学院力学研究所,在读博士研究生。主要研究方向为可压缩湍流与转捩、直接数值模拟、高性能计算。
本文承担工作为:程序实现、优化与应用测试。
Dang Guanlin is a PhD candidate in Institute of Mechanics, Chinese Academy of Sciences. His research interests include compressible turbulence and transition, direct numerical simulation, and high-performance computing.
In this paper he undertakes the following tasks: code implementation, optimization, and application testing.
E-mail:dangguanlin@imech.ac.cn

刘世伟,中国科学院数学与系统科学研究院,计算数学与科学工程计算研究所在读博士研究生,主要研究方向为计算流体力学高精度格式、大涡模拟,以及OpenCFD在GPU上的异构并行程序移植与优化。
本文承担工作为:框架代码实现、程序优化与测试。
Liu Shiwei is currently pursuing the PhD degree with the Institute of Computational Mathematics and Scientific/Engineering Computing, Academy of Mathematics and Systems Science, Chinese Academy of Sciences. His research interests include high-order schemes of computational fluid dynamics, large eddy simulation, as well as porting and optimization of heterogeneous parallel programs of OpenCFD on CUDA platform.
In this paper he undertakes the following tasks: code implementations of the whole framework,program optimization and testing.
E-mail:liusw@lsec.cc.ac.cn

胡晓东,中国科学院计算机网络信息中心,博士,工程师,主要研究方向为并行计算、计算流体力学。
本文承担工作为:程序优化、编程指导。
Hu Xiaodong is an engineer in Supercomputing Center of Computer Network Information Center, Chinese Academy of Sciences. He received master’s degree in fluid dynamics from Northwestern Polytechnical University in 2011, and the PhD degree in computer software and theory form University of Chinese Academy of Sciences in 2019. His current research interests include computational fluid dynamics and high-performance computing.
In this paper he undertakes the following tasks: program optimization and guidance of programing.
E-mail:huxd@sccas.cn

张鉴,中国科学院计算机网络信息中心,博士,研究员,主要研究方向为科学计算、高性能计算和计算机可视化。
本文承担工作为:程序整体结构设计、编程指导。
Zhang Jian received the BS degree in computational mathematics from Peking University, PR China, in 1995, and the PhD degree in applied mathematics from the University of Minnesota in May 2005. He is a professor in Computer Network Information Center, Chinese Academy of Sciences. From June 2005 to June 2009, he was a postdoc in the Pennsylvania State University working on scientific computing and modeling. His current research interests include scientific computing, high-performance computing, and scientific visualization.
In this paper he undertakes the following tasks: code design and execution director of programing.
E-mail:zhangjian@sccas.cn

李新亮,中国科学院力学研究所高温气体动力学国家重点实验室,理学博士,中国科学院力学研究所高温气体动力学国家重点实验室研究员,中国科学院大学岗位教授,博士生导师。任中国空气动力学会物理力学专业委员会副主任委员,计算物理学会常务理事,Computers & Fluids 杂志编委,《空气动力学报》及《计算物理》杂志编委等职。
目前主要从事计算流体力学及湍流研究。构造了优化保单调、加权群速度控制格式等高精度激波捕捉格式,并在此基础上开发一套开源的高精度计算流体力学软件OpenCFD;进行了一系列典型超声速、高超声速可压缩湍流的直接数值模拟,并在此基础上对湍流机理、模型及控制进行了深入探索。
本文承担工作为:程序结构设计与开发、DNS研究指导。
Li Xinliang, is the professor in laboratory of high-temperature gas dynamics, institute of mechanics, Chinese academy of sciences (CAS) and University of Chinese academy of sciences (UCAS). Prof. Li got his PhD in institute of mechanics, CAS in 2000, and then worked as a postdoctoral researcher in Tsinghua University. Dr. Li works in institute of mechanics, CAS since 2002, and his is major in CFD and DNS of turbulent flows.
In this paper he undertakes the following tasks: code design and research guidance of the DNS.E-mail:lixl@imech.ac.cn

摘要
[目的]高超声速湍流直接数值模拟(DNS)对空间及时间分辨率要求高,计算量非常大。过大的计算量及过长的计算时间是导致DNS难以在工程中被大范围应用的重要原因。为加快计算速度,作者设计并开发了一套CPU/GPU异构系统架构(HSA)下的高性能计算流体力学程序OpenCFD-SCU。[方法]该程序以作者前期开发的高精度有限差分求解器OpenCFD-SC为基础,经GPU系统的移植及优化而得。GPU程序的计算部分使用CUDA编程,确保所有算术运算都在GPU上完成。[结果]利用GPU程序OpenCFD-SCU, 进行了来流Mach数6,6°攻角钝锥边界层转捩的直接数值模拟,得到了转捩过程中的时空演化流场。针对这一算例,GPU程序OpenCFD-SCU与CPU程序OpenCFD-SC相比,实现了60倍的加速效果(单GPU卡对单CPU核心),大大加速了DNS计算过程。[结论]未来,相信会有更多高超声速湍流模拟选择在GPU上开展。
关键词:
Abstract
[Objective] The direct numerical simulation (DNS) of hypersonic turbulence requires great many grids points and time steps. Therefore, the amount of calculation is very large. Excessively long time of calculation is an important reason that DNS cannot be applied in real applications. In order to accelerate the calculation, design of a high-performance computational fluid mechanics program OpenCFD-SCU under the CPU/GPU Heterogeneous System Architecture (HSA) is introduced in this paper. [Method] This program is based on the CPU [fortran] code OpenCFD-SC which is a high-precision finite difference solver developed by the authors. OpenCFD-SCU has the same program framework as OpenCFD-SC, and the computing part of the GPU program is programmed by CUDA to ensure that all arithmetic operations are completed on the GPU. [Results] In a same DNS task, the GPU version of OpenCFD-SCU is 60 times faster than the CPU version of OpenCFD-SC. The computing power of GPU is much higher than that of CPU. Using GPU can effectively accelerate the calculation, which is the future trend of DNS programs for hypersonic turbulence. [Conclusion] In the future, we believe that more and more hypersonic turbulence simulation can be moved to the GPU.
Keywords:
PDF (9068KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
党冠麟, 刘世伟, 胡晓东, 张鉴, 李新亮. 基于CPU/GPU异构系统架构的高超声速湍流直接数值模拟研究. 数据与计算发展前沿[J], 2020, 2(1): 105-116 doi:10.11871/jfdc.issn.2096-742X.2020.01.009
Dang Guanlin.
引言
湍流是常见的自然现象,自然界的流动多以湍流形式呈现。人们对湍流的系统性研究始于上世纪20年代。经过百年的发展,现今人们对一些湍流现象已经可以较好地进行描述和预测,但过往大多数湍流研究结论都还是经验性的,对湍流的基础性理解依然欠缺。2000年,美国克雷(Clay Mathematics Institute, CMI)数学研究所悬赏了七个重要的数学难题,N-S方程(Navier-Stokes方程,流动控制方程)的求解位列第六。深入研究湍流,可以加强人们对随机性和确定性的认识。在工程方面,受航空航天等领域需求的引导,高超声速湍流(一般指来流马赫数大于5)成为当前流体力学研究的热点。飞行器表面流体从层流转捩到湍流后,摩阻和热流变为原来的数倍。理解湍流与转捩的机理,对解决运载火箭\导弹热防护、大型飞机减阻降噪、吸气式高超声速飞行器发动机燃烧室湍流混合等问题有重要意义。
直接数值模拟(DNS)是研究湍流的重要手段。DNS是使用足够密的网格直接离散求解N-S方程,可以识别最小尺度的湍流涡,能够得到湍流与转捩过程时空间演化的全部信息,是目前最为可靠的湍流计算手段。精细的DNS不仅可以帮助人们对湍流机理开展研究,也能为飞行器等工程装备设计提供参考与评估,甚至可以发现实验中难以观察到的现象,扩展人类认知的边界。高超声速湍流DNS开展较晚,近十余年左右才发展起来,主要原因之一是湍流DNS对空间网格规模与时间推进步数的要求极高,计算量极大,根据Lesieur M的推算,在积分尺度为L的实际问题中,对应雷诺数为ReL,则 DNS所需的空间网格数和时间步数至少要达到O(ReL9/4)和O(ReL1/2) [1]。美国Boeing公司的Edward N. Tinoco在2009年估计,以当时的计算机发展速度,到2080年才有可能对民航客机全机进行DNS[2]。
在过往对高超声速湍流的DNS中,往往通过在大规模CPU集群上做并行计算来实现,节点间采用MPI(Message Passing Interface)、ZeroMQ(0MQ)、Hadoop等方式进行数据通讯。然而,多核架构的CPU的计算能力现今已被众核架构的GPU甩在身后,图1、图2分别展示了2003年以来Nvidia GPU与Intel CPU的单、双精度浮点运算峰值性能和访存带宽的对比,可以看出,GPU的峰值性能与访存带宽如今都已经达到CPU的近百倍。表1展示了2019年11月公布的超级计算top500榜单前十位,其中一半超算采用了异构加速器的模式,说明利用GPU等加速器进行加速计算的异构模式已经成为高性能计算发展的主流。
图1
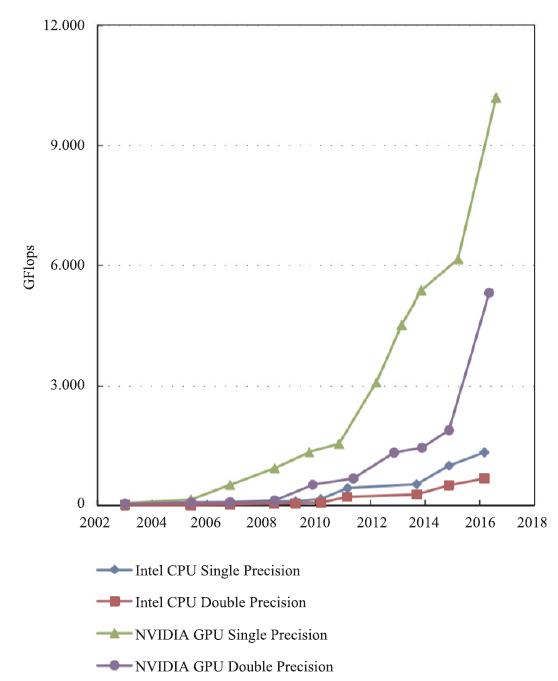 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1CPU与GPU浮点运算能力[16]
Fig.1Floating-point operations per second for CPU and GPU[16]
图2
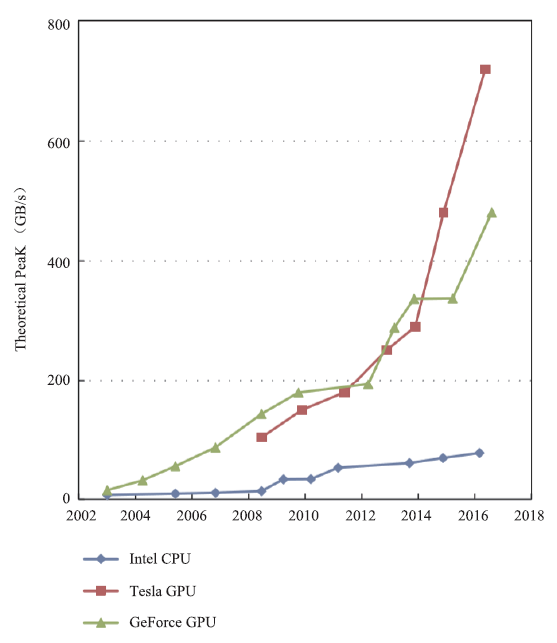 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2CPU与GPU的带宽[16]
Fig.2Memory bandwidth for the CPU and GPU[16]
Table 1
表1
表1超级计算TOP500榜单中前十名[17]
Table 1
| Rank | Machine | Architecture |
|---|---|---|
| 1 2 | Summit Sreera | 异构加速器 |
| 3 | 神威太湖之光 | 异构众核 |
| 4 | TH-2 | 异构加速器 |
| 5 | Frontera | 同构众核 |
| 6 | Piz Daint | 异构加速器 |
| 7 | Trinity | 同构众核 |
| 8 | ABCI | 异构加速器 |
| 9 | SuperMUC-NG | 同构众核 |
| 10 | Lassen | 异构加速器 |
新窗口打开|下载CSV
利用GPU求解流体力学问题前人已经开展过一些工作,2003年Takashi Amada在GPU上实现了基于平滑分子动力学(Smoothed Particle Hydrodynamics)的粒子流动模拟[3],同年,J.Kruger利用GPU求解了二维不可压N-S方程[4]。2007年,T.Brandvik完成了二维Euler方程在GPU上的求解[5],随后他将求解器扩展到了三维[6]。2010年,D.Jacobsen利用MPI-CUDA在128个GPU上并行求解了不可压N-S方程,但弱扩展性只有17%[7,8]。随后他将GPU并行数量扩展到256,三维并行效率依然没有提高[9]。2012年,Khajeh-Saeed使用192块GPU对均匀各项同性湍流进行了DNS[10]。2014年,Wang利用GPU对壁湍流分别进行了LES和DNS,他的工作是基于求解LBE(Lattice Boltzmann Equation)[11]。2015年V.Emelyanov开发了基于GPU的三维可压缩的欧拉方程与N-S方程有限体积法求解器,获得20到50倍的加速[12],之后他们对亚、跨、超声速翼型外流场利用GPU开展了数值模拟,最高马赫数为1.6[13]。2018年,Lai等人利用CPU/GPU异构系统架构下的可压缩NS方程求解器,对高超声速的双椭球绕流进行了计算,马赫数为8.02[14]。随后,他们又开展了对最大马赫数为10.02的高超声速三维航天飞机模型的数值模拟,在4块GPU上取得了比单块CPU最大147倍的加速效果[15]。
本文利用GPU对高超声速湍流问题进行DNS,最大扩展到64块GPU卡,证明GPU可以用于高超声速湍流DNS,并能大大缩短计算时间。
1 控制方程与数值方法
1.1 控制方程
本文使用的有限差分法求解器基于三维可压缩N-S方程。形式如下:其中U为守恒变量,包含质量密度、动量密度与能量密度,F1,F2,F3为三个方向的无粘通量,G1,G2,G3为三个方向的粘性通量。
其中粘性通量中的粘性应力由牛顿应力方程获得。总能E由内能与动能组成。为使方程封闭补充,另需补充理想气体状态方程。
计算基于无量纲的N-S方程。
在计算时,利用三维Jacobian变换,将物理空间的网格变换到直角坐标系下的计算空间后进行计算。
1.2 空间离散格式
为减少无粘项的混淆误差,保证计算稳定,无粘项先使用Steger-Warming分裂[18],后利用7阶Weno-SYMBO[19]格式离散。Weno-SYMBO格式相比于传统Weno格式,在保持高精度的同时,具有更小的数值耗散,更利于计算湍流问题。粘性项使用6阶中心格式进行离散。
1.3 时间推进格式
湍流问题具有极强的非定常性,为能够分辨出湍流结构实时变化,时间步长不能取得太大。显式格式计算量小,物理问题所必须的较小时间步长正好保证了计算稳定性,非常适合湍流计算。此处使用TVD型的三步三阶Runge-Kutta方法。1.4 滤波
高超声速问题由于流场动能非常接近于总能,计算如果产生非物理波很可能使动能超过总能,进而出现负温度导致的计算发散,为增加计算稳定性,在计算过程中,每经过10步计算进行一次滤波,以滤除流场中高频非物理波。守恒型滤波色散误差小,对计算结果影响较小。这里采用守恒型的捕捉激波滤波[19]。2 Opencfd-SCU程序流程与GPU程序特点
CPU/GPU异构系统架构(HSA)下的计算流体力学程序OpenCFD-SCU(OpenCFD Scientific Computing - CUDA)以作者前期开发的高精度有限差分求解器OpenCFD-SC[20]为基础,两者使用相同的程序框架,程序框架如图3。图 3
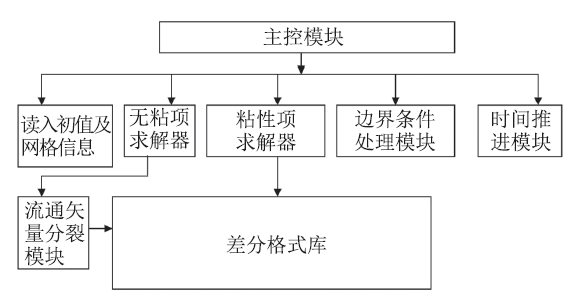 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 3OpenCFD-SC计算流程
Fig.3The program hierarchy of OpenCFD-SC
程序先读入控制文件中的参数信息,并通过MPI_bcast广播到各个进程,之后,各个进程读取初值与网格,并使用Memcpy3D将初值与网格信息传递到GPU的全局内存(Global Memory),而后,利用GPU计算Jocabian系数。程序初始化完成,正式进入计算环节。
程序的所有计算都在GPU上进行,为了避免过多的CPU-GPU间数据传输影响程序性能,数据在传递到GPU上之后,全程储存在GPU的全局内存中,CPU-GPU间数据通讯只在需要进行数据交换时启动。
为最大化减少数据交换量,以提高并行效率,我们只对差分需要的边界上3-4层数据进行交换。如图4所示,以二维为例,只有MPI进程之间差分计算涉及的重叠部分网格点上的数据需要进行数据交换。交换时。需要交换的数据要先从GPU传递到CPU,然后,CPU之间通过MPI进行数据交换,最后,CPU将交换得到的数据再传至GPU,GPU继续接下来的计算。CPU上的MPI分割采用三维剖分。目前为了保证计算的稳定,采用阻塞式通讯。
图 4
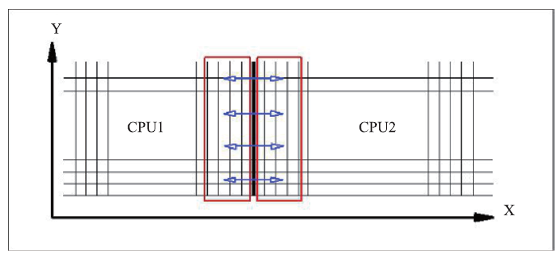 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 4区域分割示意图
Fig.4Sketch Map of region segmentation
程序中所有数据都是双精度。
3 Opencfd-SCU程序优化
GPU程序编程思想与CPU程序不同,GPU编程实际是控制线程索引与数据地址指针的关系,从而操作成大量线程同时对数据进行计算。GPU上的资源类型较复杂,在GPU上进行程序优化,主要以最大化利用GPU资源为思想。以下是我们做的一些工作。3.1 数据重排列
在进行CPU-GPU间数据交换时,我们在GPU上将所有需要交换的数据重排列为连续一维数组,再通过Memcpy传递至CPU。之所以进行重排列操作,是因为需要传输的数据是数据块边界上的数据,只是完整数据块中靠外的几层,他们在全局内存中的存储并不连续,而GPU较高的访存带宽是通过高访存位宽实现的,只有对在内存中连续排列的大数据块,GPU高访存的特性才能充分发挥,在计算时,可以通过对内存进行对齐与合并,再控制指针访问内存中的数据,从而降低数据内存不连续带来的影响。然而,在使用Memcpy函数拷贝数据时,函数默认的访存与传输方式难以控制,不连续的数据对Memcpy函数效率影响明显,直接影响了CPU-GPU间数据传递速度。在我们的测试中,重排列的操作可以明显提升Memcpy速度。
3.2 对块的大小进行控制
GPU的线程层次由线程格、线程块、线程(Grid,Block,Thread)三层组成,每层又可以构成一个x,y,z方向的三维结构。而GPU程序运行时,可以理解为数据被划分为许许多多的数据单元,由流式多处理器(Streaming Multiprocessor,SM)控制线程对各个数据单元进行操作。SM是GPU上重要的共享资源,每个GPU上SM数量固定,Nvidia Tesla V100为80个,最大化SM占用率,才能最大化GPU性能。
SM通过控制线程束(Warp)来操作线程的行为,线程束是线程调度的最小单位。实际上,GPU对每个SM可容纳的Block数、每个SM可容纳Warp数、每个SM可容纳Thread数都有限制,每个Warp所包含的Thread数量也是固定的。以Volta 架构的Nvidia Tesla V100 为例,其计算能力(Compute Capability)为7.0,对应每个SM最多可容纳32个Block、64个Warp、2048个Thread,每个Warp包含的Thread数量为32。也就意味着,对Tesla V100而言,Block的大小必须是32的整数倍,且为了使SM控制的Thread数最大,占用率最高,Block最小尺寸应大于64(SM可容纳的最大Threads数/SM可容纳最大Block数)。
与此同时,Block的大小又受限于GPU上其他的共享资源,例如:共享内存(Shared Memory),寄存器(Register)。以Nvidia Tesla V100 GPU为例,GPU上共有65536个大小为32bit的Register,为所有线程共享。若将所有寄存器分配给一个SM,并在一个SM控制2048个Thread的情况下,则每个Thread中使用的Register用量最多不超过32。如果Thread中使用的Register超过32,CUDA会强制减少Block数,从而导致SM利用率的下降,此时,应尽可能减少Register使用量,如果Register用量不能减少,也应适当调整Block的大小,使Block大小适应SM可启动的最大线程规模。此外, Shared Memory是Block内的共享资源,如果对Shared Memory的申请超过最大限额,GPU会从Global Memory中寻找替代资源,导致核函数执行速度下降,此时应减小Block的大小。
在我们的测试中也发现过大过小的Block都会影响性能。表2列举了在我们的测试中对6阶中心差分格式的核函数dx0设置不同Block大小时核函数的执行时间,结果发现,对dx0而言,最合适的Block大小为32*2*2。不同核函数资源需求量不同,Block的最优尺寸可能也不同,应视情况而定。
Table 2
表2
表2线程块大小与函数运算耗时
Table 2
| Block大小 | 时间(ms) |
|---|---|
| 32*1*1 | 821.47 |
| 32*2*1 | 449.34 |
| 32*2*2 | 349.12 |
| 32*4*2 | 349.37 |
| 32*4*4 | 371.04 |
新窗口打开|下载CSV
3.3 对寄存器、共享内存、常量内存的使用
GPU上的内存层次分为多层。尽可能利用好各种类型的内存资源,如寄存器(Register)、共享内存(Shared Memory)、常量内存(Constant Memory),有利于提高程序性能。上面已经说到,过多使用寄存器,会导致SM利用率下降,线程并发数量减少,影响程序性能。在我们的程序中,我们令核函数内临时变量尽可能复用,以减少Register的开销,此外也采用将寄存器用量过多的核函数进行拆分的方式减少单个核函数的寄存器用量。
Shared Memory 是GPU上可编程缓存,与1级缓存有同样高的访存速度,与Global Memory相比,延迟低20到30倍,带宽大约高10倍。它可以在核函数外声明,并在核函数内调用,Shared Memory在Block内是共享的。Nvidia Tesla V100 GPU具有98 304字节大小的Shared Memory,我们在各个核函数中采用一个名称相同的一维向量作为中间变量,并在Shared Memory上为其开辟内存。这样可以提高访存速度。在我们的程序中,例如7阶WENO-SYMBO格式进行数值通量的计算时,先从Global Memory获取流场数据,加权计算得到通量放在Shared Memory中再进行最后一步的差分,这样的操作可以使核函数的性能提升20%。
Constant Memory是GPU上一个高速只读内存,将程序始终不变的常量存放于Constant Memeoy中,也可以提高访问速度,而且能使寄存器用量减少。以7阶WENO-SYMBO格式为例,有接近60个常量系数,如果放到寄存器中,势必会导致核函数开销过大进而并发数减少,将这些系数放到Constant Memory中是保障核函数性能的关键,在我们的测试中,网格量为2563时利用Constant Memory可以用32*4*4的Block规模来运行程序,而未使用Constant Memory时程序最大只能以32*4*2的Block规模运行,并发数和性能都有一倍的差距。
3.4 访存的合并与对齐
GPU在线程操作时以线程束为基本单位,具有一定并发性,而在访存时,GPU也是并发操作的,它利用高访存位宽获取了高的访存带宽。在V100上,访问Global Memroy时有两种方式:(1)通过1级缓存一次访问128字节的数据;(2)通过2级缓存一次访问32字节的数据。GPU默认的访存方式是2级缓存访问。在此情况下,一次访问操作会访问4个双精度数据,为了不浪费访存带宽,最大化提高带宽利用率。在访问时,我们让每一个线程束访问首地址为32字节(128字节)整数倍的位置,并获取连续32字节整数倍的数据。在我们的程序中,以6阶中心差分格式核函数dx0为例,为了使访存能够合并,我们在一个kernel中执行两次reinterpret(double4),读入8个点的数据,在一个kernel上进行2个点的差分运算。执行一次reinterpret(double4)读入的数据长度为32字节,确保每次获取的都是连续的32字节数据,此时访存是合并的。在经过这样的优化后,dx0执行时间从未优化前的349ms缩减到了147ms,核函数运行速度快了一倍以上。
4 高超声速湍流DNS
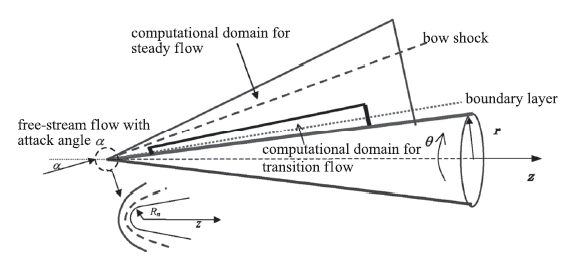
钝锥是火箭、导弹等外形的典型头部特征,对钝锥开展DNS具有重要工程意义。我们通过异构程序使用最多64块GPU对6°攻角,1mm头半径的小钝头锥开展了DNS,有攻角钝锥边界层流动如图5。图 5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 5有攻角钝锥边界层流动[21]
Fig.5Schematic of boundary layer flow over a blunt cone with angle of attack[21]
在进行DNS模拟之前,我们使用粗网格,利用有限体积程序OpenCFD-EC[22]获取定常的层流流场,利用该流场插值出用于DNS的初值与边界条件。
有限体积法的层流计算时,无粘项使用Van Leer分裂与MUSCL限制器,时间推进采用LU-SGS方法。
为促进转捩,模拟钝锥表面粗糙单元,在钝锥头部90mm到100mm位置添加吹吸气扰动,扰动幅值为来流速度的千分之一。
4.1 网格与流场设置
参数设置如表3。来流马赫数为6,来流攻角6°,初始壁温为294K,来流温度为79K。钝锥半锥角为7°,头半径为1mm。Table 3
表3
表3流动参数设置
Table 3
| Ren Maffl | a(AOA) | Tw | half cone angle | |
|---|---|---|---|---|
| 10000 6 | 6° | 294K | 79K | r |
新窗口打开|下载CSV
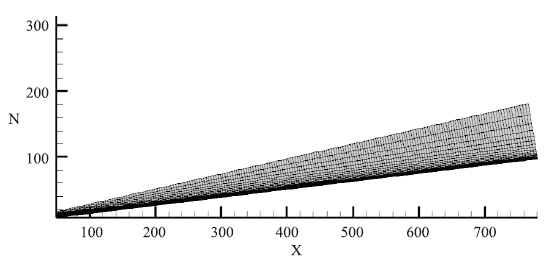
网格规模为1600*1200*120,其中流线网格数1600,周向网格数1200,法向网格数120,总网格2.3亿,流向网格在头部进行加密,周向采用非均匀网格在迎风面对网格进行加密。壁面第一层网格为0.01mm。流向与周向网格见图6、图7。
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6钝锥表面流向网格
Fig.6The flow direction’s grids of blunt cone
图7
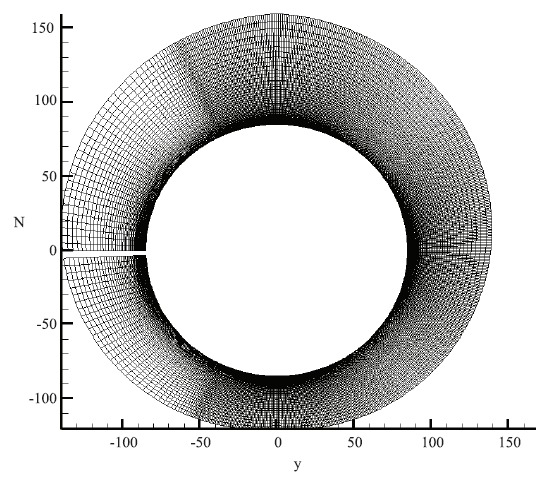 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7钝锥表面周向网格
Fig.7The circumferential direction’s grids of blunt cone
4.2 计算结果
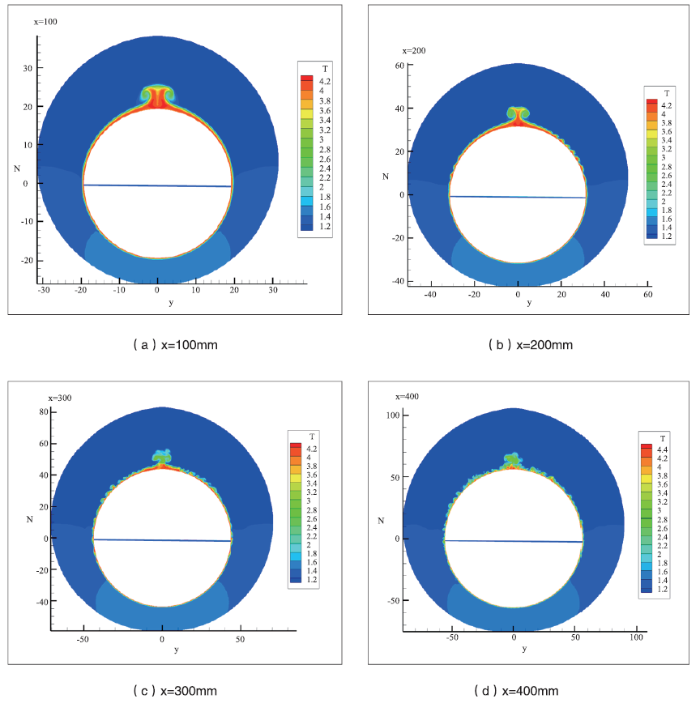
图8为距离头部100mm、200mm、300mm、400mm位置,钝锥表面的热流分布。可以看出钝锥在x=100mm位置,表面卷起蘑菇状涡,随后在周向表面出现波纹状结构,在x=300mm位置已经开始转捩,x=400mm位置流场已经是充分发展的非均匀湍流。图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8钝锥不同位置温度分布
Fig.8Heat flow distribution in different positions of blunt cone
图9是我们绘制的从不同方向观察的钝锥表面摩阻分布。可以看到,由于来流的冲击作用,钝锥下表面迎风面的摩阻明显高于上表面背风面的摩阻。且迎风面摩阻分布较均匀,被风面摩阻分布呈条带状结构。条带状的摩阻结构证明流动已经进入湍流。
图9
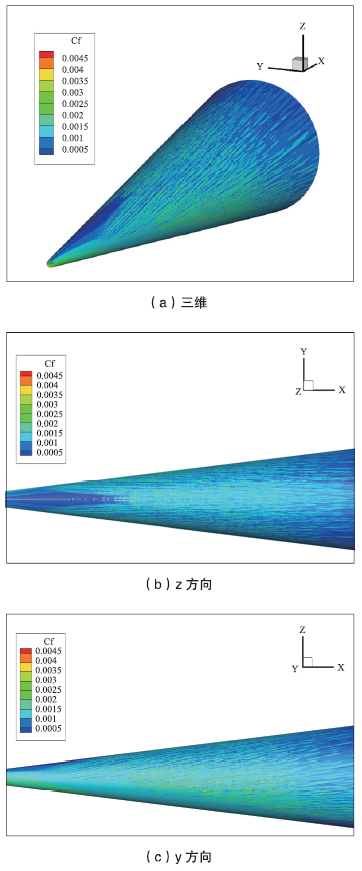 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9钝锥表面摩阻分布
Fig.9Surface friction distribution of blunt cone
4.3 计算时间
在使用GPU计算之前,我们先使用CPU端的程序OpenCFD-SC对这一算例计算,使用1024个CPU核心,CPU核心的频率为2.5GHz,系统内存频率为2666MHz,单核峰值性能0.01 TFlops/S。使用此CPU计算每迭代一时间步耗时1.498s(100次迭代取平均)。而后,我们通过异构程序OpenCFD-SCU在GPU上对相同算例进行计算,我们使用的GPU频率为1455MHz,显存带宽900GB/S,双精度浮点性能7TFlops/S。我们分别使用16、32、48、64块GPU卡对其进行计算,表4列出了在这4种规模下,计算每迭代一时间步所耗时间(100次迭代取平均)。
Table 4
表4
表4不同GPU数量,每步迭代耗时
Table 4
| GPU卡数 | 每步计算时间 (S/秒) | |
|---|---|---|
| case 1 | 16 | 1.591 |
| case 2 | 32 | 0.745 |
| case 3 | 48 | 0.551 |
| case 4 | 64 | 0.395 |
新窗口打开|下载CSV
可以看出,在使用16块GPU卡对钝锥算例进行计算时,每步迭代时间已经接近使用1024个CPU核心进行计算的时间。程序在单块GPU上取得了比单个CPU核心快60倍的加速效果。使用更多GPU卡,单GPU比单CPU加速效果甚至更明显。图10、图11中展示了在GPU上程序的加速比与并行效率,可以看出有超线性的情况,这可能是此算例对16个GPU而言负载过大,但也可以看出,OpenCFD-SCU程序整体扩展性很好,在最大64块GPU卡上,并行效率基本没有变化。
图 10
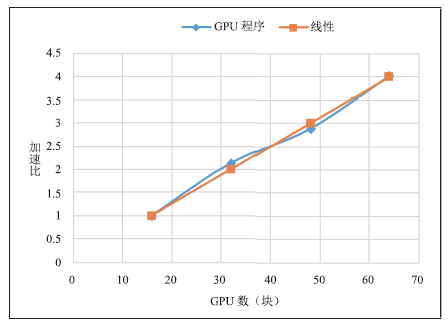 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 10GPU程序加速比
Fig.10GPU program speedup
图 11
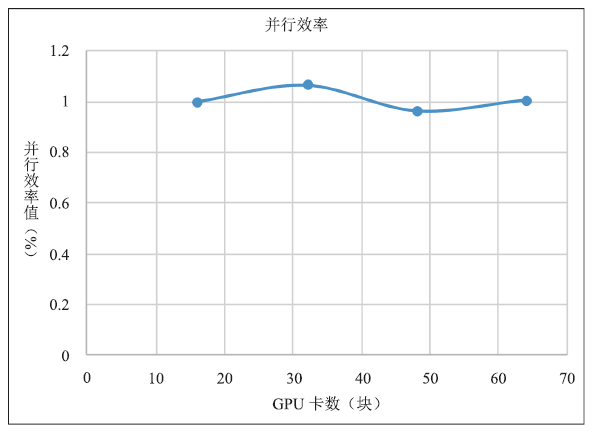 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 11GPU程序并行效率
Fig.11Program parallel efficiency
在整个算例的计算中,我们迭代了10万步,使用64块GPU只用11个小时左右就得出了结果,而以往对相同类型算例的计算,使用200余个主频2.5GHz的CPU核心,往往需要花费一周时间。如果是对更大规模的算例,可能需要数月时间,利用GPU能将耗时缩短一个数量级。
5 小结
本文介绍了GPU在高超声速湍流计算上的应用。描述了GPU程序优化相关技术,并使用CPU/GPU异构程序对来流马赫数为6的6°攻角小钝头锥开展了DNS。结果表明,GPU可以胜任高超声速湍流直接数值模拟,并能取得了较好的加速效果,程序在单GPU上比单CPU核加速了60倍,大大缩短了模拟时间。可以想象,在未来会有更多高超声速湍流模拟问题在GPU上开展。
目前,OpenCFD-SCU的功能模块尚不够丰富,核函数还有优化空间,未来将继续添加功能以适应更多不同的算例,还将对核函数进行深度优化,以提升程序性能。此外,在程序结构上,目前仍采用单线程阻塞式MPI通讯,为加速整体性能,未来将对程序结构做调整,完成CPU上计算与MPI通讯重叠,在GPU方面,也将使用更多流(Stream)操作来提升GPU并发性,并使GPU上的计算与主机、设备间内存拷贝进行重叠,进而提升整体性能。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[M].
[本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[M].
[本文引用: 1]
[M].
[本文引用: 1]
[M] .
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
URL [本文引用: 4]
URL [本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
URL [本文引用: 1]
[J].
[本文引用: 2]
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}