HTML
--> --> -->The mathematical theory of extreme statistics with long-term correlations is still developing, but the results already obtained are also helpful for understanding extreme characteristics and can give some clues to extreme estimations of long-term correlated series. One result shows that correlations would not affect the extreme distribution. This conclusion is evident to the POT extremes (i.e., peaks or values over a threshold). If a series is randomly shuffled, statistical correlations in this series will be destroyed but the POT extremes will not change. The situation is more complex for the block extreme (i.e., the maximum value during a fixed time period). A theorem states that the block extreme distribution of a stationary Gaussian sequence will converge to the Gumbel distribution as the time period increases to infinity, provided that the autocovariace




Another result states that extremes in a long-term correlated time series always appear in clusters (Bunde et al., 2005). As a result, the distribution of the extreme return period will deviate from the exponential distribution, which is obeyed in cases without correlations (Ross, 1996; Liu et al., 2014). Besides, the relation between the mean return period of extremes and the probability of extreme occurrences (hereafter called the T?P relation) becomes more complex. In this paper, we firstly analyze the long-term correlations of wind speed time series by fluctuation analysis (section 3.1). Then, a new T?P relation of extreme wind speeds is proposed (section 3.2). Here, we use the POT extreme because it is of greater utility and higher significance to climate time series compared to the block extreme (Ding et al., 2008), and it is also widely used in wind engineering (Holmes and Moriarty, 1999; Palutikof et al., 1999; Larsén et al., 2015). Finally, the classical extreme estimation method for series without correlations is briefly reviewed (section 4.1) and generalized to cases with long-term correlations (section 4.2).
| Station | T0 (day/month/year) | Nm |
| Schiphol | 1/3/1950 | 0 |
| De Bilt | 1/1/1961 | 1 |
| Soesterberg | 1/3/1958 | 4 |
| Leeuwarden | 1/4/1961 | 0 |
| Eelde | 1/1/1961 | 1 |
| Vlissingen | 2/1/1961 | 0 |
| Zestienhoven | 1/10/1961 | 4 |
| Eindhoven | 1/1/1960 | 1 |
| Beek | 1/1/1962 | 1 |
Table1. The KNMI HYDRA project data used in this paper.


3.1. Fluctuation analysis
Autocovariance is a useful tool to describe statistical correlations in random time series. The autocovariance of a time series
where





Generally, autocovariance calculated by Eq. (1) is more and more scattered with the increase of k. Thus, it is difficult to obtain a reliable estimation of γ by autocovariance analysis (Beran, 1994; Kantelhardt et al., 2001). Fluctuation analysis is a commonly used method to detect long-term correlations in time series (Peng et al., 1992). It can also give a better estimation of γ than the autocovariance analysis. Fluctuation analysis comes from a more general method named detrended fluctuation analysis (DFA). In DFA, trends in the cumulative summation of time series, obtained by fitting with a high-order polynomial, are eliminated (Peng et al., 1994). Very often, it is difficult to estimate the underlying trends in data, and inappropriate detrending could lead to artificial results (Kantelhardt et al., 2001). Besides, Bryce and Sprague (2012) pointed out that, in contrast to the mystery surrounding the action and interpretation of DFA, use of the fluctuation analysis method is straightforward and interpretable. In practice, wind trends are also interesting in many wind engineering applications. Thus, we do not detrend the data and only use fluctuation analysis in this paper.
Fluctuation analysis is described as follows. The path of a time series

where

and its standard deviation F(s) is called the fluctuation function. If


Figure 1 is a fluctuation analysis of the wind speed time series listed in Table 1. It shows that wind speed time series are long-term correlated because the values of α are evidently greater than 0.5 for all samples. We note that the scaling exponent of the fluctuation function seems to be universal for wind speed time series. Although observation time and sites vary in the samples, all the values of α approximate to 0.7.
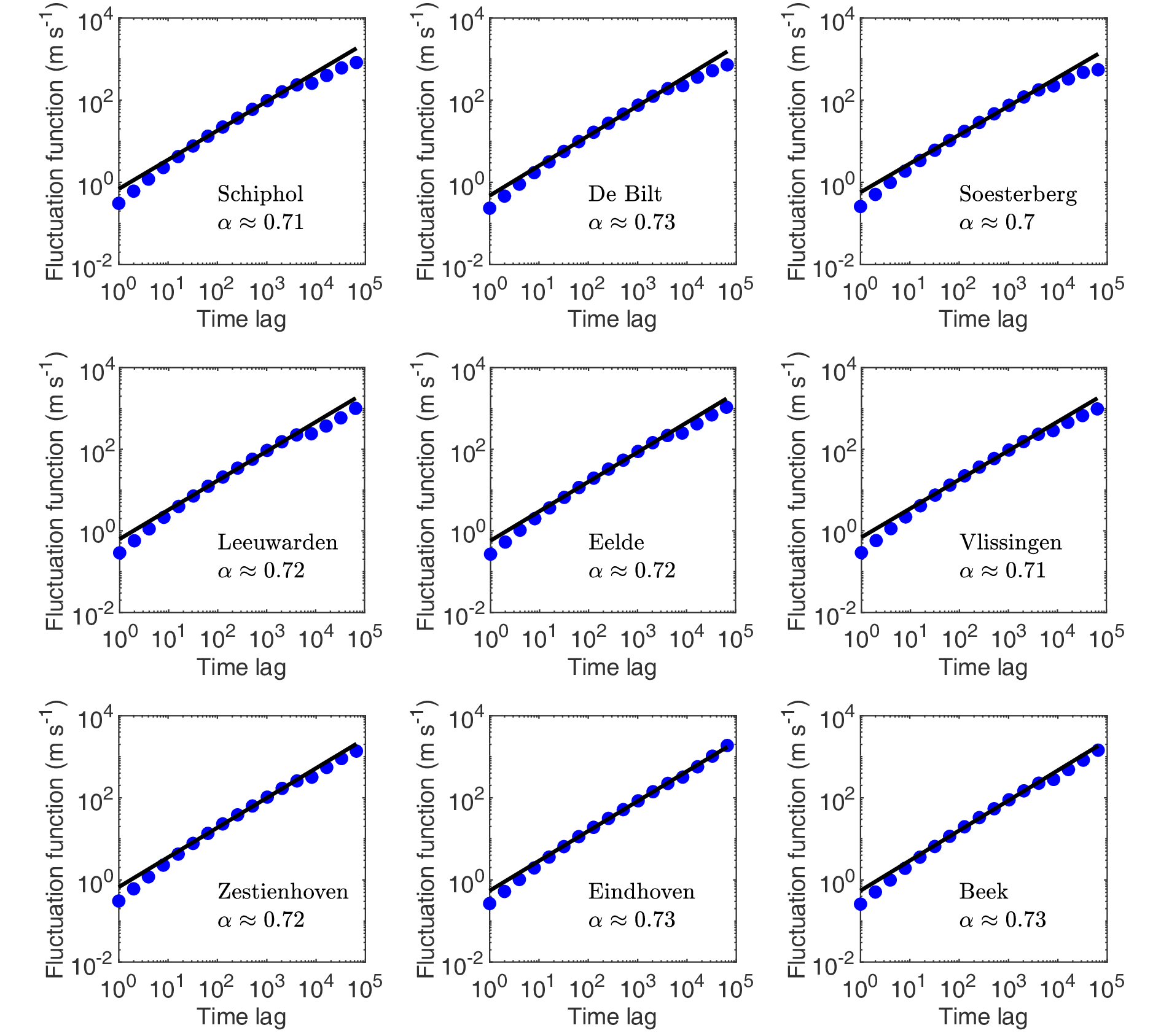 Figure1. Fluctuation analysis of wind speed time series listed in Table 1. Lines are linear fittings in log-log plots, and the fitted scaling exponent of the fluctuation function
Figure1. Fluctuation analysis of wind speed time series listed in Table 1. Lines are linear fittings in log-log plots, and the fitted scaling exponent of the fluctuation function 
2
3.2. The T?P relation
In this paper, the relation between the mean return period of extremes and the probability of extreme occurrences is called the T?P relation. This relation is critical for extreme estimations and is very different between cases with or without correlations. If the time series is assumed to be statistically independent (i.e., without correlations), the return periods of values greater than a threshold is exponentially distributed (Ross, 1996; Liu et al., 2014) and the corresponding T?P relation is derived bywhere T is the mean return period, ?t is the sampling time, and Pz is the probability of values greater than a value of z.
Unlike cases without correlations, the return periods of POT extremes in long-term correlated time series will deviate from the exponential distribution. Figure 2 is an example of return period distributions of extreme wind speeds over different thresholds. Because the wind speed time series is long-term correlated (section 3.1), the data decay much slower than the exponential distribution (see the dashed line in Fig. 2). It was found that the so-called stretched exponential distribution can fit the data better (see the black line in Fig. 2). In fact, data analysis and numerical simulations have found that the stretched exponential distribution can fit return periods in various time series (Altmann and Kantz, 2005; Bunde et al., 2005; Santhanam and Kantz, 2005; Liu et al., 2014). Besides, we found that the statistics of return periods of extreme wind speeds can be simply normalized. If the return periods are normalized by their mean, the distributions with different thresholds will collapse into a single curve except for large values of return periods. The scattered tails may be caused by limited data.
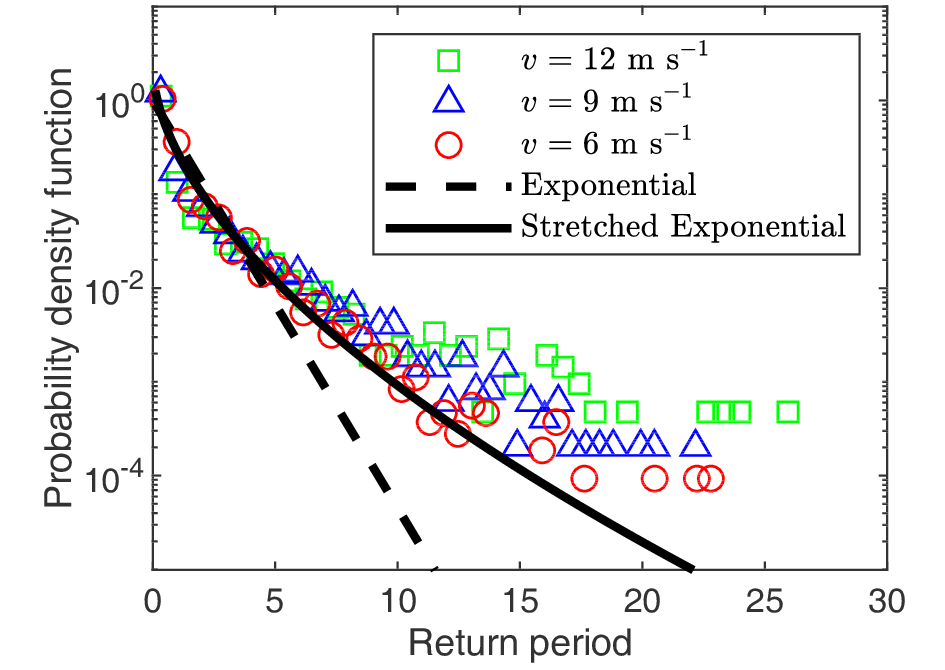 Figure2. Probability density functions of return periods for wind speeds (the Schiphol data) greater than different thresholds of
Figure2. Probability density functions of return periods for wind speeds (the Schiphol data) greater than different thresholds of 
The stretched exponential distribution is defined by
where parameters a, b and


If



In Fig. 2, the value of

where
Generally, the parameter b is a function of






We found that Eq. (10) is indeed a good approximation of the T?P relation of extreme wind speeds (see Fig. 3). Besides, one can see that if the mean return periods are normalized by

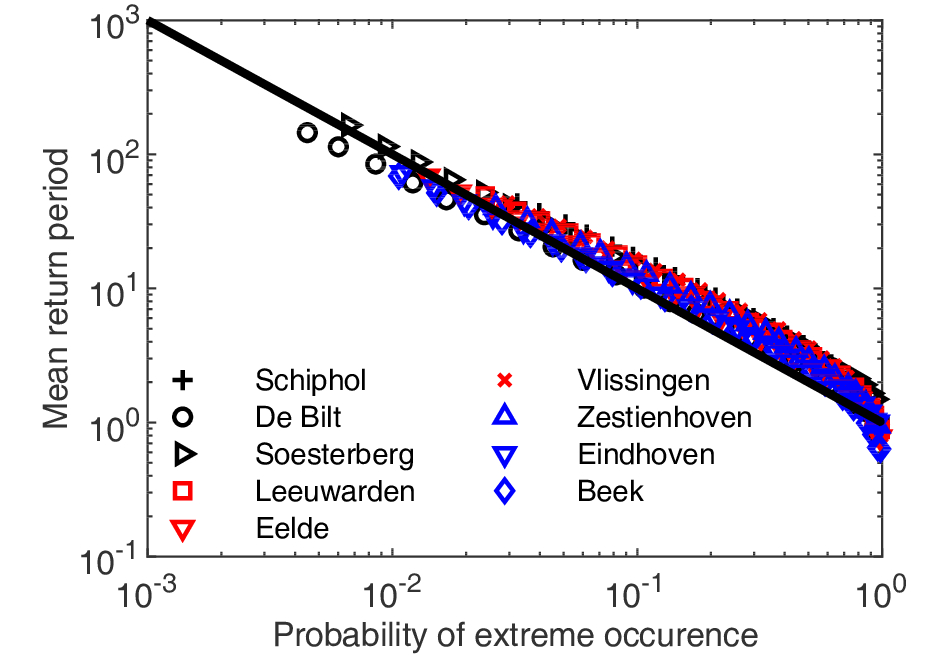 Figure3. The T?P relation for wind speed time series listed in Table 1. Note that the mean return period is divided by
Figure3. The T?P relation for wind speed time series listed in Table 1. Note that the mean return period is divided by 


 Figure4. (a) The wind speed time series measured at Schiphol from 1 January 2005 to 31 December 2005. (b) The time series in (a) having been randomly shuffled. An arbitrarily chosen threshold is denoted by a dashed line in each panel.
Figure4. (a) The wind speed time series measured at Schiphol from 1 January 2005 to 31 December 2005. (b) The time series in (a) having been randomly shuffled. An arbitrarily chosen threshold is denoted by a dashed line in each panel.2
4.1. The classical method
The classical method dealing with series without correlations is briefly introduced here. More details can be referred to in the book by Coles (2001). The limiting conditional probability of POT extremes as the threshold
where




where



2
4.2. A new method with long-term correlations
As discussed in section 1, the limiting distribution of POT extremes as the threshold increases is the same whether or not the series is long-term correlated. Parameters in the GPD can be estimated by the maximum likelihood method (Coles, 2001). We compare the empirical conditional probabilities of extreme wind speeds with the GPD and find that the former is well described by the latter except for very large values (see Fig. 5). Deviations at large values would be caused by unreliable statistics of limited data. In practice, the threshold v is selected by a balance between bias and variance. If v is too low, the conditional probability cannot be well approximated by the GPD. If v is too large, the variance of parameters is large due to limited data. As far as we know, there is not a well-established method for the threshold selection (Scarrott and MacDonald, 2012). The commonly used upper 10% rule is just used here (DuMouchel, 1983). According to this rule, the threshold is defined to be the 90th percentile of samples. Table 2 lists the thresholds, the maximum likelihood estimations of GPD parameters and the corresponding confidence intervals.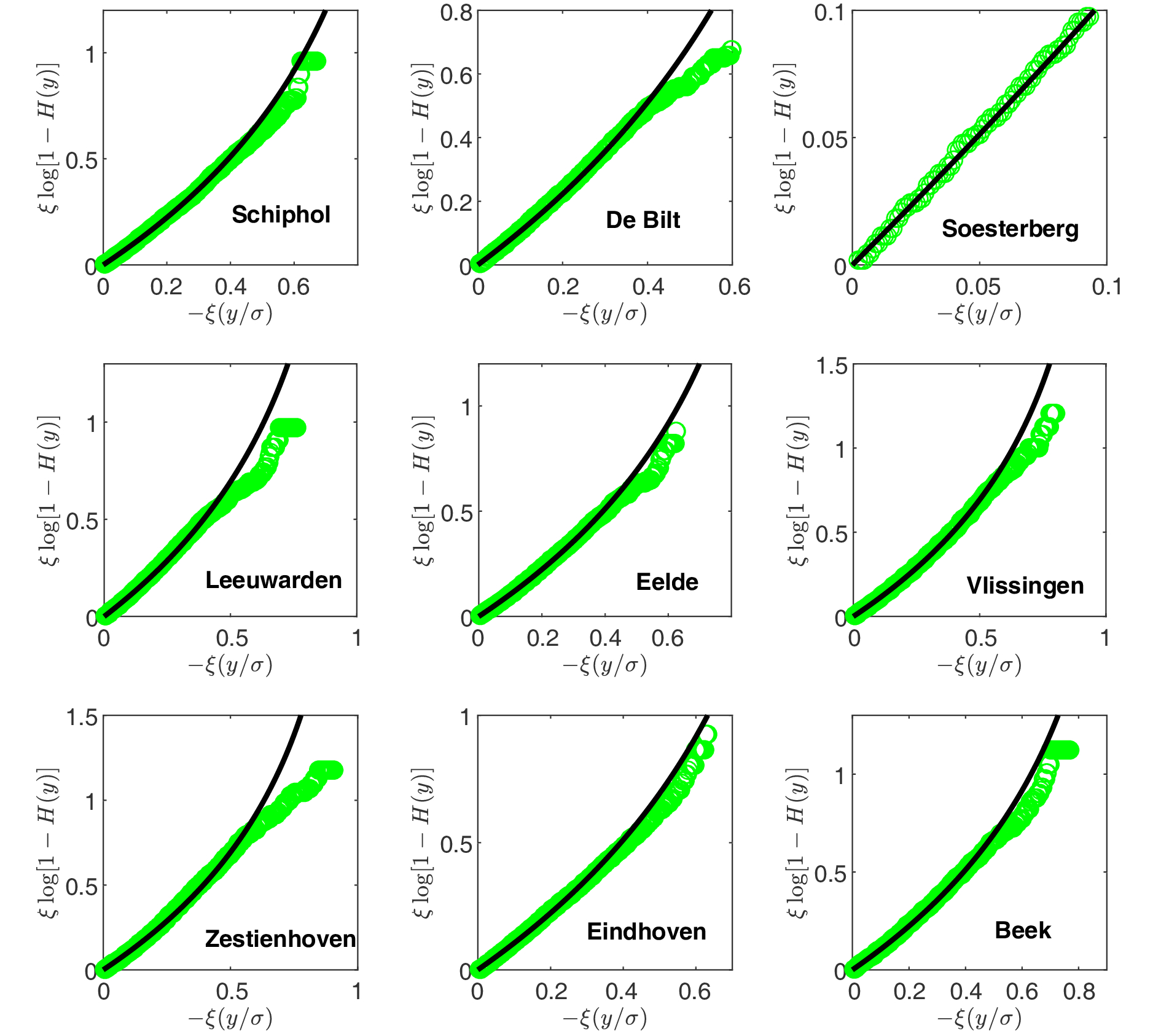 Figure5. Diagnostic plots of the GPD fittings to the wind speed time series listed in Table 1. Points show the empirical conditional probability of extreme wind speeds. Lines show the GPD with their parameters estimated by the maximum likelihood method (see Table 2)
Figure5. Diagnostic plots of the GPD fittings to the wind speed time series listed in Table 1. Points show the empirical conditional probability of extreme wind speeds. Lines show the GPD with their parameters estimated by the maximum likelihood method (see Table 2)| Station | $v\;\left( {{\rm{m}}\;{{\rm{s}}^{ - 1}}} \right)$ | $\xi$ | ${\rm{CI}}\left( \xi \right)$ | $\sigma $ | ${\rm{CI}}\left( \sigma \right)$ |
| Schiphol | 9.5 | ?0.0893 | (?0.0967, ?0.0819) | 2.4566 | (2.4282, 2.4854) |
| De Bilt | 7.2 | ?0.0799 | (?0.0876, ?0.0722) | 1.8141 | (1.7913, 1.8372) |
| Soesterberg | 7.6 | ?0.0406 | (?0.0491, ?0.0320) | 1.7858 | (1.7630, 1.8089) |
| Leeuwarden | 9.1 | ?0.0921 | (?0.0994, ?0.0848) | 2.2890 | (2.2609, 2.3175) |
| Eelde | 8.3 | ?0.0831 | (?0.0914, ?0.0748) | 2.0926 | (2.0658, 2.1198) |
| Vlissingen | 9.5 | ?0.1142 | (?0.1219, ?0.1066) | 2.3182 | (2.2893, 2.3474) |
| Zestienhoven | 9.3 | ?0.1195 | (?0.1249, ?0.1141) | 2.3018 | (2.2759, 2.3281) |
| Eindhoven | 8.0 | ?0.0876 | (?0.0957, ?0.0796) | 2.1138 | (2.0869, 2.1410) |
| Beek | 8.1 | ?0.1065 | (?0.1143, ?0.0987) | 2.0573 | (2.0314, 2.0836) |
Table2. Thresholds



According to Eqs. (10) and (11), the T-year return level of long-term correlated wind speeds is calculated by
Comparing Eqs. (12) and (13), we have
The above equation states that the T-year return level of long-term correlated wind speeds can be simply obtained by just scaling the value of T in the classical method dealing with series without correlations. It means that the classical method, already implemented in many commercial software or open source programs, does not need to be discarded in cases with long-term correlations.
The procedure of the extreme wind speed estimations is illustrated in Fig. 6. For wind speed time series, α ≈ 0.7 (see Fig. 1). Thus,



 Figure6. The maximum likelihood estimator of T-year return level
Figure6. The maximum likelihood estimator of T-year return level 


Acknowledgments. We thank the Royal Netherlands Meteorological Institute for supplying the data. Many thanks also to Mrs. Engel ANDRIESSEN for her kind help with using the data. The latest datasets are downloadable at http://projects.knmi.nl/klimatologie/onderzoeksgegevens/potentiele_wind/index.cgi?language=eng. This work was supported by the National Key R&D Program of China (Grant No. 2016YFC0208802) and the National Natural Science Foundation of China (Grant Nos. 41675012 and 11472272).
