按照感兴趣目标光谱信息使用层次的不同,高光谱图像目标检测可分为光谱匹配检测和异常目标检测[5]。前者需要使用目标光谱的先验信息,而后者不需要任何先验信息,是对图像中与周围背景存在显著差异的异常目标进行检测。目前,由于完备实用的光谱数据库尚未建立,而且反射率反演算法的精确度仍有待提高,导致获取光谱信号的先验信息成为目标检测的难点,因此光谱匹配检测难以应用于实际,而无需目标光谱先验信息的异常目标检测成为高光谱目标检测应用研究的重点[6]。其中由Reed和Yu提出的RXD(Reed-Xiaoli Detector)算法是目前研究和应用最为广泛、实用性强的一种高光谱异常目标检测算法,它不需要目标光谱的先验信息而只需统计背景协方差矩阵[7]。Liu和Chang在RXD算法的基础上进行研究,提出了包括采用嵌套多个大小可变的空域局部窗等方法在内的一系列改进检测算法[8]。Kwon和Nasrabadi利用核函数改进传统的小目标检测算法,将原始已有算法推广到高维特征空间,使得目标与背景更好地分离以降低检测算法的虚警率,取得相对于传统高光谱小目标检测算法更好的性能[9]。针对高光谱图像数据量大和数据维数高的特性,有不少研究机构开展了基于现场可编程门阵列(FPGA)的高光谱图像处理技术方面的研究,如北京理工大学的何光林和彭林科基于FPGA采用奇异值分解算法实现了对高光谱图像的降维预处理[10],中国科学院的于涛等基于Xilinx FPGA设计了实时的高光谱数据处理系统[11]。目前,基于FPGA的高光谱目标检测算法已取得很大进展。Wang等利用坐标旋转数字计算机(CORDIC)设计FPGA,可以将矢量的Givens旋转转换为移位添加操作,实现了基于约束能量最小化(CEM)的高光谱目标检测算法[12]。赵宝玮等在FPGA和多数字信号处理的硬件平台上实现了RXD并行处理算法,该平台通过FPGA完成高光谱图像的奇异值分解降维,利用多数字信号处理完成RXD算法的并行化,实现了高光谱异常目标检测的快速处理[13]。Yang等提出了以流水式局部背景统计方法(SBS)实现对高光谱目标检测算法的改进,在保证检测效果的同时极大地降低计算难度,而且在同一片FPGA上集成了CEM和RXD算法,分别用于目标检测和异常检测,通过双模式处理节省了大量硬件资源以满足高光谱图像在轨实时处理要求,为解决高光谱数据维数高和实时处理困难等问题探索了新途径[14]。
针对高光谱异常目标检测RXD算法实现中协方差矩阵及其逆的计算量过大的问题,本文围绕分块并行的矩阵相乘和正交三角(QR)分解求逆矩阵的加速思想展开,利用高层次综合(HLS)工具实现用于FPGA加速的算法并通过添加约束项等方式对RXD算法进行优化,进而提出RXD算法在FPGA平台上的加速方案。实验结果分析表明,所提出的RXD算法加速方案可以充分发挥HLS工具设计硬件电路的优势并在FPGA平台上有效地实现。
1 RXD算法基本理论 1.1 信号统计检测理论 高光谱异常目标检测通常可以看作一个二元信号检测问题,即观测样本中的待测像素可能是属于目标亦或是属于背景,由二元假设检验表示如下:H0表示待测像素不是目标,H1表示待测像素是目标,则有
 | (1) |
式中:t为待测样本;nB为背景向量;sT为目标向量;c为常数,且c≥0。当c=0时,H0假设成立,样本中不存在目标,将t判为背景;当c > 0时,H1假设成立,待测样本中存在目标,将t判为目标。
广义似然比检验(Generalized Likelihood Ratio Test, GLRT)是通过最大似然的方法估计未知参量用于似然比检验,是信号参量统计检测的重要方法。对于一个待测像素t,可以利用条件概率密度函数来定义似然比函数LR(t)为
 | (2) |
但在实际的异常检测过程中,式(2)中的条件概率密度函数与背景和目标的分布密切相关,而背景和目标通常都是先验未知的,无法直接求得。于是,假设在H0下,设未知参数为θ0,则样本条件概率密度函数为p(t|θ0; H0)。同理,假设在H1下,设未知参数为θ1,则其条件概率密度函数为p(t|θ1; H1)。要得到LR(t)的具体形式,需要根据统计学原理中利用最大似然估计量代替未知参量θi(i=0, 1)的方法,求得条件概率密度函数的逼近值,从而得到利用GLRT进行检测的判决式
 | (3) |
式中:LG(t)为广义似然比函数;


1.2 RXD算法检测原理 高光谱异常目标检测RXD算法是由Reed和Yu提出的一种基于GLRT的检测方法[7]。该算法假设图像背景服从空间均值快变而方差慢变的多维高斯随机过程[15],适用于背景分布较为简单情形下的异常目标检测。RXD算法可以表示为
 | (4) |
式中:δRXD(r)为RXD算子,r为图像中任意L×1维的像素向量,L为波段数;μ为样本均值向量,定义为
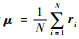


显然,式(4)中的δRXD(r)有着与马氏距离相同的形式。本质上RXD算法可以看作是主成分分析(Principle Component Analysis, PCA)的逆过程。PCA可以根据协方差矩阵K的几个最大特征值对应的特征向量求得信息分布的主要方向。恰恰相反,某些图像中出现概率较低的小目标或异常目标将不包含在这些主要分量中[16],因为其对应的能量很小,很可能会出现在协方差矩阵K的小特征值对应的特征向量方向上。由式(4)可知,特征值越小,δRXD(r)越大,这正是RXD算法可以有效地应用于高光谱异常目标检测的原因所在。考虑到存在目标光谱的一阶统计信息特征明显的情况,Chang引入了RXD算法的一个重要变体[17],即通过样本自相关矩阵R替换矩阵K,同时由r代替式(4)中的r-μ,得到基于自相关矩阵的R-RXD算法,可以表示为
 | (5) |
式中:R为样本自相关矩阵,定义为R=

2 基于FPGA的RXD算法加速方案 高光谱数据量大和维数高的特性使得各种目标检测算法在实现时往往运算量很大,例如RXD算法中样本协方差矩阵及其逆的计算[18]。随着电子设计自动化技术的发展,兼具高度灵活性和高性能计算力的FPGA在高光谱图像处理方面所起的作用越来越重要。FPGA具有强大的并行计算能力、灵活的设计方式以及速度和面积互换原则,而HLS工具使得用户可以通过编写C或C++等高级语言来实现用于硬件加速的算法,克服了传统硬件描述语言开发FPGA周期长、调试困难等问题,大大提升了FPGA设计和开发的效率[19]。因此,本文主要结合RXD算法的实现流程,重点研究协方差矩阵及其逆运算的加速思想,充分发挥高层次综合工具设计硬件电路的优势,通过添加约束项等方式实现算法优化,进而提出RXD算法在FPGA平台上的加速方案。
2.1 算法加速方案主要思想
2.1.1 矩阵相乘加速思想 分析RXD算法流程可知,无论是样本协方差矩阵K或是自相关矩阵R,其维数和计算量都会随着波段数L的增加而迅速增大[20]。由于协方差矩阵K可以看作是由高光谱数据去除样本均值μ之后再做自相关计算求得,因此本文主要以自相关矩阵R的计算过程为例来讨论矩阵相乘的加速思想。
自相关矩阵R是基于矩阵相乘得到的,所以想要求得自相关矩阵的关键在于矩阵相乘的实现。但是由于高光谱图像的数据量一般都比较大,这使得计算自相关矩阵的难度也随之增加,因为要想在硬件计算中一次性读入所有的图像数据进行运算几乎是不可能实现的,同时也是不科学的。为了能够在FPGA平台实现矩阵相乘的加速计算,本文提出了在自相关矩阵计算过程中进行分块并行处理的加速思想。矩阵相乘加速方案的具体步骤如下:
步骤1??首先进行图像的划分,将预处理后的高光谱图像数据(即L×N维的矩阵,其中L为波段数,N为像素数)划分为每次计算n个像素和每次更新s个波段的小块,则每次计算生成矩阵相乘的结果为s×L维的小矩阵。
步骤2??将需要计算的矩阵元素从片外DDR导入片内资源,分块地进行矩阵相乘,计算完n个像素后,更新之后的n个像素再进行计算,并将计算结果与之前的结果进行累加更新,直到所有的N个像素累加完毕。
步骤3??待当前s个波段的所有像素更新完毕后,输出并存储结果后更新计算单元,然后开始计算s~2s-1部分的波段,直到所有的L个波段计算完毕。
步骤4??输出并存储最终的结果,得到L×L维的自相关矩阵R。
对于上述步骤,做出更为直观的图形化描述如图 1所示。分析可知,该方案可分为2个计算单元:①划分L0~Ls波段、N0~Nn像素的图像单元;②L0波段的N0~Nn像素单元。
 |
| 图 1 分块相乘求自相关矩阵的描述 Fig. 1 Description of finding autocorrelation matrix by block multiplication |
| 图选项 |
运算过程中,计算单元②中的数据由波段L0~LL不断进行更新。考虑到FPGA强大的并行计算能力,可将计算单元②中的a个波段进行并行加速,同时需要扩充a个相乘单元存储模块和矩阵相乘模块,而存储相乘结果的block RAM需要划分为a个block,此并行结构的示意图如图 2所示。
 |
| 图 2 并行结构示意图 Fig. 2 Schematic diagram of parallel structure |
| 图选项 |
其中,并行的矩阵相乘模块可以存储为间隔b个波段的不同波段,并行处理时分别串行向下进行更新以实现加速。即图 2中的相乘单元0更新为0~b-1波段,而相乘单元1更新为b~2b-1波段。
2.1.2 矩阵求逆加速思想 结合高光谱数据特性与RXD算法流程可知,协方差矩阵K和自相关矩阵R的阶数一般都比较高。而伴随矩阵法、初等行列变换法等从数学角度提出的求逆算法只适用于低阶矩阵求逆的计算,在实际的算法实现中是不可行的[21]。为了避免对矩阵直接求逆所导致的巨大运算量,本文采用实际工程中广泛应用的QR分解算法来实现矩阵求逆,并通过研究可以降低逆矩阵计算复杂度的QR分解过程来讨论矩阵求逆的加速思想。
设A为任意的m×n阶矩阵,则A可以分解为m×m阶正交矩阵Q1和m×n阶上三角矩阵R1的乘积,即
 | (6) |
式(6)称为矩阵A的QR分解,接下来采用Givens变换来进行分解计算。
对于矩阵A,右乘一个旋转矩阵G[2][2],只改变矩阵A的第i行j列的元素,而其他行的元素不变,这种变换称为Givens变换。在平面几何中,使向量x顺时针旋转角度θ后变为向量y的变换如图 3所示。
 |
| 图 3 旋转变换示意图 Fig. 3 Schematic diagram of rotation transformation |
| 图选项 |
由图 3可知,旋转变换是不改变向量模值的正交变换,所以T是正交矩阵,det T=1。更一般地,对于n维欧氏空间,可令e1, e2, …, en为空间的一个标准正交基。
设实数c1和c2满足c12+c22=1,则称n阶方阵为一个初等旋转矩阵,记为Tij(c1, c2)。
 |
显然c12+c22=1,则必存在实数θ,使得c1=cos θ, c2=sin θ。因为Tij的n个列向量两两正交,所以Tij是正交矩阵。由于|Tij|=1,则
 | (7) |
设x=(x1, x2, …, xn)T,若给列向量x左乘初等旋转矩阵,有Tijx=(y1, y2, …, yn)T,当k≠i, j时,则有yk=xk,当k=i或j时,则有
 | (8) |
当xi2+xj2≠0时,取



设非零向量x=(x1, x2, …, xn)T∈Rn, e1=(1, 0, …, 0)T,存在有限个初等旋转矩阵的乘积T,使得
 | (9) |
式中:T=T1nT1n-1…T12。
对于n阶矩阵A,存在有限个初等旋转矩阵的乘积T,使得TA=R1为上三角矩阵,即存在正交矩阵Q1=T-1,使得A=Q1R1。对任意的n阶上三角矩阵R1求逆,先由原矩阵R1主对角线元素取倒数计算得到所求逆矩阵主对角线上的元素值。然后依次求出平行于主对角线且距离主对角线最近的斜列上的元素值,再通过相同的方法依次求得距离由近及远的斜列上的元素值,直到求出整个逆矩阵V。利用上述方法计算上三角矩阵R1的逆矩阵V的公式如式(10)所示。
根据A=Q1R1=T-1R1,可知A-1=R1-1T=VT。于是可利用2.1.1节所介绍的矩阵相乘原理求得A-1, 从而实现矩阵的QR分解求逆。利用上述加速思想通过QR分解实现矩阵求逆的方案描述如图 4所示。
 | (10) |
 |
| 图 4 QR分解求逆矩阵的实现方案 Fig. 4 Implementation scheme of finding inverse matrix by QR decomposition |
| 图选项 |
2.2 基于HLS的算法优化 HLS工具是Xilinx公司推出的新一代FPGA设计开发工具。该工具的问世,使得用户通过编写C或C++等程序代码,综合生成寄存器传输级(Register Transfer Level, RTL)代码从而实现所需的硬件功能。该工具的发展突破了传统FPGA只能通过硬件描述语言(Hardware Description Language, HDL)设计实现的瓶颈,而且可以根据不同需求来添加约束项,进行算法的优化与加速,具有明显的优势[22]。HLS的关键优化策略主要包括数组与循环、延迟和吞吐量的处理[23]。
2.2.1 数组的处理 数组是算法实现中一种常见而直观的软件结构,HLS支持数组分割(array partition)以提高设计吞吐量[24]。数组分割可以将数组分割为更小的单元,且允许分割成任意的维度以实现存储器更加优化的配置。若维数为0,则表示所有的维数。HLS工具还提供了block、cyclic和complete 3种不同的分割类型,相应的处理产生不同的结构,如图 5所示。
 |
| 图 5 数组分割的不同类型 Fig. 5 Different types of array partition |
| 图选项 |
① block型:将D个数据的数组均等分割,分别存储在不同的BRAM中,例如0~(D/2-1)存在一个BRAM,而D/2~(D-1)存于另一个BRAM,这样做可以使得一个时钟内得到每个BRAM中位置相同的数据;②cyclic型:与block型类似地将一个数组等分,但数据的存放方式不同于block,例如可将第0, 2, 4, …, D-2个数据存入第1个BRAM,而将第1, 3, 5, …, D-1个数据存到第2个BRAM,这样也可以在一个时钟内得到多个数据;③complete型:将数组中的D个数据存入D个寄存器,可以在一个时钟内获取任意多的数据,但是当数组元素较多时,这种方式所占用的资源将迅速增加。
2.2.2 循环的处理 HLS在默认不添加约束的情况下对循环综合时,将循环综合为与软件环境中相同的顺序执行的电路。对于硬件而言,如果每次循环操作彼此独立,则可以利用HLS提供的UNROLL约束进行并行操作来提高处理速度,由此付出的代价是硬件资源利用率的增大,是一种典型的以面积换取速度的方法。
例如,循环体如下:
void foo_top(…) {
????…
????Add: for(k=3; k > =0; k--){
????sum=arr[k]+sum;
????????????…}
}
其中:arr[k]和sum均为数组。
循环体默认结构是折叠起来的,如图 6(a)所示。HLS工具提供的UNROLL约束可以根据用户需求将循环完全展开,如图 6(b)所示,当然也可以按照设计需求只进行部分展开循环。
 |
| 图 6 循环展开示意图 Fig. 6 Schematic diagram of cyclic unrolling |
| 图选项 |
2.2.3 延迟和吞吐量的处理 延迟是指从输入到输出结果所用的周期数,而吞吐量表示2个新输入的数据之间的周期数。HLS工具提供的PIPELINE约束,可以将一个函数或循环设计成具有指定间隔的流水线结构,从而提高吞吐量。
例如,对于图 7(a)所示函数结构,默认不使用流水线的情况下,只有当输入的数据完成所有处理过程并输出后,输入端才能够接收下一组新的数据,此时吞吐量为3个周期,如图 7(b)所示;而当添加流水线约束后,吞吐量有了明显提高,减小为1个周期,如图 7(c)所示。若对于多重循环使用流水线策略,可以有效地减小整个循环的延迟。一般情况下,添加流水线结构会使得寄存器资源消耗增多,因为流水结构的实现需要寄存前级流水线所生成的中间数据。
 |
| 图 7 流水线处理示意图 Fig. 7 Schematic diagram of pipeline processing |
| 图选项 |
3 实验结果与分析 3.1 高光谱数据描述 本文所用的模拟高光谱数据TE是由AVIRIS成像仪拍摄的Cuprite数据中的地物光谱信息设计合成的[25]。图 8(a)给出了Cuprite图像场景,其中右上角标有“BKG”区域的均值光谱用于后续设计模拟图像场景的背景。该矿区数据集提供的背景和5种地物A(明矾石,Alunite)、B(水铵长石,Buddingtonite)、C(方解石,Calcite)、K(高岭石,Kaolinite)、M(白云母,Muscovite)的光谱曲线如图 8(b)所示。图 8(c)给出了这5种地物的位置分布。
 |
| 图 8 Cuprite数据描述 Fig. 8 Cuprite data description |
| 图选项 |
根据图 8(c)中5种地物A、B、C、K、M的光谱信息(图 8(b)),通过一定方法设计得到包含25个异常目标的模拟高光谱图像数据如图 9所示。其每一列有5个大小形状相同但类别不同的异常目标,且每一行的5个异常目标由同种地物的光谱特性组成。在这25个异常目标中,每一行的第1列为大小是4×4的纯像素,第2列为2×2的纯像素,第3列为2×2的混合像素,第4列与第5列为1×1的亚像素,其中混合像素的大致构成已在图 9中给出。需要注意的是,这25个异常目标是通过将目标像素叠加在大小为200×200、由背景光谱特性构成的合成图像中来嵌入目标的,并在背景中加入信噪比为20:1的加性高斯噪声。
 |
| 图 9 模拟图像中25个异常目标分布 Fig. 9 25 anomaly target distributions in simulated images |
| 图选项 |
3.2 矩阵相乘对比分析 为了验证2.1.1节中提出的分块并行矩阵相乘加速思想的有效性,采用模拟高光谱数据TE作为数据输入,借助HLS工具通过该加速方法实现自相关矩阵R的计算。由于高光谱数据为三维矩阵,首先在MATLAB中利用reshape函数将其转化为189×40 000的二维矩阵,记为矩阵M,其中189为波段数,40 000为像素数。将其导出为文本文件作为HLS工具的测试文件,则所求的自相关矩阵R为189×189的二维矩阵。
为充分体现加速方案的优势,在HLS工具中还采用了传统的整体矩阵元素对应相乘并累加求和的方法来实现自相关矩阵的计算。对2种实现方法选择相同的目标FPGA型号,均为virtex7系列的xc7vx485tffg1761-2,利用2.2.2节所述HLS优化算法的策略对2种方法均添加合适的约束项,得到二者的时序估计结果如表 1所示。
表 1 添加约束项后2种方法的时序 Table 1 Timing sequence after adding constraints of two methods
| 方法 | 最小时延/ clk | 最大时延/ clk | 最小数据间隔/clk | 最大数据间隔/clk |
| 传统法 | 4286520030 | 4286520030 | 4286520031 | 4286520031 |
| 加速法 | 733332624 | 733332624 | 733332625 | 733332625 |
| 注:clk—一个时钟周期。 | ||||
表选项
由表 1可知,添加优化策略后,加速法综合后的处理时延和数据间隔要比传统法小得多,仅仅是传统法的1/6。在处理速度得到大幅提升的同时,还要综合考虑添加约束项后加速法所消耗资源的情况,加速法的综合报告中资源利用情况如表 2所示。
表 2 加速法的资源利用情况 Table 2 Resource utilization results of acceleration scheme
| 资源利用数 | BRAM_18K | DSP48E | FF | LUT |
| 表达式资源数 | 0 | 74 | ||
| 实例资源数 | 131 | 11472 | 27045 | |
| 存储资源数 | 40 | 0 | 0 | |
| 乘法器资源数 | 1747 | |||
| 寄存器资源数 | 203 | |||
| 总计 | 40 | 131 | 11675 | 28866 |
| 可用资源数 | 2060 | 2800 | 607200 | 303600 |
| 资源利用率/% | 1 | 4 | 1 | 9 |
表选项
由表 2所示的资源利用情况可以看出,由于添加了对数组、循环以及延迟和吞吐量的优化策略,综合后所占用的BRAM_18K、DSP48E、FF以及LUT资源数均有所上升,这是以面积换取速度的结果。分析可知,对于目标FPGA而言,综合后可用的资源数仍比较多,意味着添加约束项后的加速法使用并不多的硬件资源就达到了处理速度的大幅提高,完全可以在FPGA平台上有效地实现。
3.3 矩阵求逆对比分析 为验证2.1.2节中提出的降低计算复杂度的QR分解矩阵求逆加速思想的可行有效性,采用3.2节所求得的189×189的二维矩阵R作为数据输入,借助HLS工具通过QR分解的方法实现逆矩阵R-1的计算。类似地,将矩阵R导出为文本文件作为HLS工具的测试文件,用于求逆矩阵R-1。
为充分体现加速方案在HLS中实现的优势,采用默认的不添加任何约束项与添加优化策略后这2种实现QR分解求逆的综合结果进行对比分析。同样的,对2种实现方法选择相同的目标FPGA型号,均为virtex7系列的xc7vx485tffg1761-2,得到二者综合报告中的时序估计结果如表 3所示,资源利用情况如表 4所示。表 3中方案①和方案②分别表示不添加任何约束项和添加优化策略后的时序结果。表 4中“/”前后分别为不添加任何约束项和添加优化策略后的资源利用情况。
表 3 2种方案的时序情况对比 Table 3 Comparison of timing sequence between two schemes
| 方案 | 最小时延/ clk | 最大时延/ clk | 最小数据间隔/clk | 最大数据间隔/clk |
| ① | 169502204 | 354001169 | 169502205 | 354001170 |
| ② | 57877695 | 256307850 | 57877696 | 256307851 |
表选项
表 4 添加优化前后2种方案的资源利用情况 Table 4 Comparison of resource utilization results before and after optimization between two schemes
| 资源利用数 | BRAM_18K | DSP48E | FF | LUT |
| 实例资源数 | 512/288 | 94/88 | 14 512/21238 | 20691/61334 |
| 存储资源数 | 768/432 | 0 | 0 | |
| 乘法器资源数 | 58/418 | |||
| 寄存器资源数 | 9/9 | |||
| 总计 | 1280/720 | 94/88 | 14521/21247 | 20749/61752 |
| 可用资源数 | 2060 | 2800 | 607200 | 303600 |
| 资源利用率/% | 62/34 | 3/3 | 2/3 | 6/20 |
表选项
由表 3可以看出,结合默认不添加约束情况下综合后估计的处理时钟周期为8.42 ns这一条件,根据最小和最大时延(分别为169 502 204和354 001 169个时钟周期)来计算此时最优与最差情况下的处理时间,分别为1.427 s和2.981 s。然后通过添加适当的约束项,如增加并行性提升时序性能,建立流水线结构提高吞吐率等策略进行优化后再次综合,综合后估计的处理时钟周期略有增加,为8.63 ns。而处理的最小与最大时延均有明显的降低,分别为57 877 695和256 307 850个时钟周期,相应的优化后的最优与最差情况下的处理时间,分别为0.499 s和2.212 s。由此可见,添加优化策略后的处理速度有了明显的提升,特别是最优情况下的速度达到了默认未加约束时的近3倍之多。
由表 4可知,添加约束项的情况下BRAM资源占用有了明显的降低,而LUT资源消耗较未添加约束项时有所增加。这是由于对数组添加PARTITION约束并建立流水线结构后,会减少BRAM资源占用而使用寄存器来寄存中间数据以减少读取造成的延迟。同时,LUT的资源消耗数也有所上升,是利用以面积换取速度原则将循环并行操作后的结果。综合上述结果的对比分析,再次体现了HLS工具设计实现QR分解求逆矩阵这一加速方案的优势。
3.4 多平台算法实现对比分析 为了验证所提出加速方案的正确有效性,仍采用模拟高光谱数据TE作为数据输入,借助HLS工具通过上述加速方案进行RXD算法的完整实现。首先在MATLAB中利用reshape函数将TE数据转化为189×40 000的二维矩阵M,其中189为波段数,40 000为像素数。将其导出为文本文件作为HLS工具测试文件的输入,运行HLS工具中的C语言仿真功能,经过上述加速的RXD算法处理后得到包含200×200个RXD算子δRXD(r)值的文本文件即为输出。在此首先给出MATLAB仿真实验的结果用于对比分析,如图 10(a)所示。然后将HLS中的输出δRXD(r)值导入MATLAB平台并以JPG格式保存,实现结果如图 10(b)所示。
 |
| 图 10 HLS与MATLAB实现结果对比 Fig. 10 Comparison of implementation results between HLS and MATLAB |
| 图选项 |
对比图 10(a)和图 10(b)不难发现,2种平台实现的结果对于TE数据中25个异常目标的检测性能都表现得非常好,几乎看不出任何差别。出于严谨性,计算得到HLS实现结果与MATLAB仿真结果之间的相对误差,并给出图形化显示如图 11所示。
 |
| 图 11 HLS与MATLAB实现结果的相对误差 Fig. 11 Relative error of implementation results of HLS and MATLAB |
| 图选项 |
从图 11中可以看出,两者之间最大的相对误差仅为10-13数量级,这一结果有力地证明了所提出的RXD算法加速方案的正确性。接下来将189×40 000的矩阵M划分为9×200的单元块进行并行相乘,利用添加约束项的QR分解实现矩阵求逆,并对算法不断添加恰当的优化策略后运行HLS主界面的C语言综合功能,最终得到综合报告的时序估计结果如表 5所示,资源利用情况如表 6所示。
表 5 基于FPGA的RXD算法实现的时序估计结果 Table 5 Timing sequence estimation results for FPGA-based implementation of RXD algorithn
| 时钟周期/ns | 最小时延/ clk | 最大时延/ clk | 最小数据间隔/clk | 最大数据间隔/clk |
| 9.78 | 1552545313 | 1779318286 | 1552545314 | 1779318287 |
表选项
表 6 基于FPGA的RXD算法实现的资源利用情况 Table 6 Resource utilization results for FPGA-based implementation of RXD algorithn
| 资源利用数 | BRAM_18K | DSP48E | FF | LUT |
| 表达式资源数 | 1 | 0 | 5390 | |
| 实例资源数 | 40 | 244 | 66088 | 92578 |
| 存储资源数 | 978 | 0 | 0 | |
| 乘法器资源数 | 10556 | |||
| 寄存器资源数 | 4109 | 32 | ||
| 总计 | 1018 | 246 | 70197 | 108556 |
| 可用资源数 | 2060 | 2800 | 607200 | 303600 |
| 资源利用率/% | 49 | 8 | 11 | 35 |
表选项
结合表 5和表 6可以看出,综合后估计的处理时钟周期为9.78 ns,在此时钟频率下的处理最小时延为1 552 545 313 clk,而且在硬件资源消耗不是特别多的条件下就可以实现RXD算法的加速。
为了进一步验证算法加速方案的有效性,同时还针对TE数据在CPU平台上进行了RXD算法的性能测试。算法采用C语言在Visual Studio 2012软件中实现,其运行环境与HLS工具保持一致,均为Intel Core i5-4210M、主频2.6 GHz的CPU,内存(RAM)为4 GB。其中CPU程序通过C语言的计时函数clock()获取运行时间,FPGA平台实现算法的时间可通过HLS综合报告中的时钟周期与计算获得,从而可以得到对于高光谱数据TE采用RXD算法分别在CPU和FPGA平台上的处理时间以及相应的加速比,如表 7所示。
表 7 CPU和FPGA平台实现RXD算法的处理时间对比 Table 7 Comparison of processing time measured for RXD algorithm between CPU and FPGA implementations
| CPU 处理时间/s | FPGA | 加速比 | ||
| 时钟周期/ ns | 最小时延/ clk | 处理时间/s | ||
| 111.29 | 9.78 | 1552545313 | 15.81 | 7.04 |
表选项
由表 7可知,在同一运行环境下针对同样的高光谱数据进行处理,相比于CPU平台的C语言实现,提出的基于FPGA的RXD算法加速方案处理速度可以达到其7.04倍之多,说明该方案完全可以充分发挥HLS工具的优势并在FPGA平台上有效地实现。
4 结论 1) 针对高光谱异常目标检测RXD算法中样本协方差矩阵及其逆的计算量庞大这一难题,提出了分块并行的矩阵相乘和QR分解求逆矩阵的加速方案。
2) 利用高层次综合工具HLS对算法优化后进行设计实现,得到分块并行矩阵相乘加速法的处理时延和数据间隔仅是传统法的1/6,QR分解求逆矩阵的速度可以达到默认未加约束时的近3倍之多,充分体现了加速方案的优势。
3) RXD算法在HLS、MATLAB和CPU多平台实现的对比分析表明,本文提出的加速方案可以在保持算法检测性能的同时达到相较于CPU实现7.04倍的加速,验证了基于FPGA平台的RXD算法加速方案的正确有效性。
参考文献
| [1] | QU J H, LEI J, LI Y S, et al. Structure tensor-based algorithm for hyperspectral and panchromatic images fusion[J]. Remote Sensing, 2018, 10(3): 373-391. DOI:10.3390/rs10030373 |
| [2] | LI Y S, HU J, ZHAO X, et al. Hyperspectral image super-resolution using deep convolutional neural network[J]. Neurocomputing, 2017, 266: 29-41. DOI:10.1016/j.neucom.2017.05.024 |
| [3] | 赵兵.基于FPGA的高光谱图像RX异常检测研究[D].杭州: 杭州电子科技大学, 2012: 1-2. ZHAO B.Research on RX anomaly detection of hyperspectral image based on FPGA[D].Hangzhou: Hangzhou Dianzi University, 2012: 1-2(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10336-1013218096.htm |
| [4] | BIOUCAS-DIAS J M, PLAZA A, CAMPS-VALLS G, et al. Hyperspectral remote sensing data analysis and future challenges[J]. IEEE Geoscience & Remote Sensing Magazine, 2013, 1(2): 6-36. |
| [5] | 贺霖, 潘泉, 邸韡, 等. 高光谱图像目标检测研究进展[J]. 电子学报, 2009, 37(9): 2016-2024. HE L, PAN Q, DI W, et al. Research advance on target detection for hyperspectral imagery[J]. Acta Electronica Sinica, 2009, 37(9): 2016-2024. DOI:10.3321/j.issn:0372-2112.2009.09.024 (in Chinese) |
| [6] | LIU W H, FENG X P, WANG S, et al. Random selection-based adaptive saliency-weighted RXD anomaly detection for hyperspectral imagery[J]. International Journal of Remote Sensing, 2018, 39(8): 2139-2158. DOI:10.1080/01431161.2017.1420931 |
| [7] | REED I S, YU X L. Adaptive multiple-band CFAR detection of an optical pattern with unknown spectral distribution[J]. IEEE Transactions on Acoustics Speech & Signal Processing, 1990, 38(10): 1760-1770. |
| [8] | LIU W M, CHANG C I.A nested spatial window-based approach to target detection for hyperspectral imagery[C]//Proceedings of IEEE International Geoscience and Remote Sensing Symposium, 2004.Piscataway NJ: IEEE Press, 2004: 266-268. |
| [9] | KWON H, NASRABADI N M. Kernel adaptive subspace detector for hyperspectral imagery[J]. IEEE Geoscience & Remote Sensing Letters, 2006, 3(2): 271-275. |
| [10] | 何光林, 彭林科. 基于FPGA的高光谱图像奇异值分解降维技术[J]. 中国激光, 2009, 36(11): 2983-2988. HE G L, PENG L K. FPGA implement of SVD for dimensionality reduction in hyperspectral images[J]. Chinese Journal of Lasers, 2009, 36(11): 2983-2988. (in Chinese) |
| [11] | 于涛, 胡炳樑, 高晓惠, 等. 高光谱图像运动误差实时校正处理平台设计与实现[J]. 光谱学与光谱分析, 2012, 32(8): 2275-2279. YU T, HU B L, GAO X H, et al. Design and implementation of real-time processing platform for movement error correction of hyperspectrual imaging[J]. Spectroscopy and Spectral Analysis, 2012, 32(8): 2275-2279. DOI:10.3964/j.issn.1000-0593(2012)08-2275-05 (in Chinese) |
| [12] | WANG J, CHANG C, CAO M.FPGA design for constrained energy minimization[C]//Proceedings of SPIE-The International Society for Optical Engineering. Bellingham: SPIE, 2004, 5268: 262-273. |
| [13] | 赵宝玮, 相里斌, 吕群波, 等. FPGA和多DSP系统的并行RX探测算法[J]. 西安电子科技大学学报(自然科学版), 2014, 41(3): 152-156. ZHAO B W, XIANG L B, Lü Q B, et al. Parallel RX algorithm implementation based on the FPGA and multi-DSP system[J]. Journal of Xidian University, 2014, 41(3): 152-156. DOI:10.3969/j.issn.1001-2400.2014.03.022 (in Chinese) |
| [14] | YANG B, YANG M, PLAZA A, et al. Dual-mode FPGA implementation of target and anomaly detection algorithms for real-time hyperspectral imaging[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2015, 8(6): 2950-2961. |
| [15] | 成宝芝.基于光谱特性的高光谱图像异常目标检测算法研究[D].哈尔滨: 哈尔滨工程大学, 2012: 45-48. CHENG B Z.Research on spectral feature based anomaly target detection algorithms in hyperspectral imagery[D].Harbin: Harbin Engineering University, 2012: 45-48(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10217-1014134049.htm |
| [16] | 欧阳征平.高光谱遥感图像局部异常检测算法研究[D].长沙: 国防科学技术大学, 2011: 14-16. OUYANG Z P.Study on algorithms of local anomaly detection for hyperspectral remote sensing imagery[D].Changsha: National University of Defense Technology, 2011: 14-16(in Chinese). http://cdmd.cnki.com.cn/article/cdmd-90002-1012021039.htm |
| [17] | CHANG C I. Hyperspectral imaging:Techniques for spectral detection and classification[M]. New York: Kluwer Academic/Plenum Publishers, 2003: 89-103. |
| [18] | YANG B, YANG M, GAO L, et al.A dual mode FPGA implementation of real-time target detection for hyperspectral imagery[C]//International Workshop on Earth Observation and Remote Sensing Applications. Piscataway, NJ: IEEE Press, 2014: 340-344. |
| [19] | LEI J, LI Y S, ZHAO D S, et al. A deep pipelined implementation of hyperspectral target detection algorithm on FPGA using HLS[J]. Remote Sensing, 2018, 10(4): 516. DOI:10.3390/rs10040516 |
| [20] | ZHAO C H, YOU W, WANG Y L, et al.GPU implementation for real-time hyperspectral anomaly detection[C]//IEEE International Conference on Digital Signal Processing. Piscataway, NJ: IEEE Press, 2015: 940-943. |
| [21] | 倪涛, 丁海锋, 阮黎婷, 等. 基于QR分解算法的任意阶复矩阵求逆的DSP实现[J]. 电子科技, 2010, 23(4): 99-101. NI T, DING H F, RUAN L T, et al. Implementation of arbitrary order complex matrix inversion based on the QR decomposition algorithm in DSP[J]. Electronic Science and Technology, 2010, 23(4): 99-101. (in Chinese) |
| [22] | PAPAKONSTANTINOU A.High-level automation of custom hardware design for high-performance computing[D].Champaign: University of Illinois at Urbana-Champaign, 2012: 5-8. http://www.ideals.illinois.edu/handle/2142/42137 |
| [23] | 何宾. Xilinx FPGA设计权威指南[M]. 北京: 清华大学出版社, 2012: 183-202. HE B. Xilinx FPGA:Design and application[M]. Beijing: Tsinghua University Press, 2012: 183-202. (in Chinese) |
| [24] | WANG Y, LI P, ZHANG P, et al.Memory partitioning for multidimensional arrays in high-level synthesis[C]//Design Automation Conference. Piscataway, NJ: IEEE Press, 2013: 1-8. |
| [25] | 赵春晖, 王立国, 齐滨. 高光谱遥感图像处理方法及应用[M]. 北京: 电子工业出版社, 2016: 300-302. ZHAO C H, WANG L G, QI B. Hyperspectral remote sensing images processing methods and applications[M]. Beijing: Publishing House of Electronics Industry, 2016: 300-302. (in Chinese) |
