| 基于向量场的深度计算方法 |
| 路海明1, 王一娇2, 谢朝霞1 |
| 1. 清华大学 信息技术研究院, 北京 100084; 2. 清华大学 自动化系, 北京 100084 |
| Vector field based depth acquisition algorithm |
| LU Haiming1, WANG Yijiao2, XIE Zhaoxia1 |
| 1. Research Institute of Information Technology, Tsinghua University, Beijing 100084, China; 2. Department of Automation, Tsinghua University, Beijing 100084, China |
摘要:
| |||
| 摘要基于深度图像可以方便地区分前景和背景, 有效提高自然人机交互的性能。其中基于面结构光技术的深度摄像头实用性强, 得到了迅速发展, 其深度信息获取基于图像块匹配算法, 在计算每个像素点的深度时, 需要在测量范围内进行逐点搜索、图像块匹配和寻优等大量运算, 这些运算要通过高性能计算机或专用并行运算芯片才能达到实时性, 导致了深度摄像头成本的增加。本文研究基于向量场模式识别的深度图算法DepthVH, 通过生成具有深度相关特征的向量场, 将深度信息变换为特征信息, 通过直接识别各个深度点周围的向量场特征, 将该特征信息逆变换为深度信息, 实现类似Hash映射的搜索, 避免了线性搜索匹配算法的巨大运算量。采用DepthVH, 智能电视只要增加一个红外发射元件, 就可以具有自然人机交互功能。 | |||
| 关键词 :深度图,结构光,向量场 | |||
| Abstract:Scene foregrounds and backgrounds can be separated according to their depth to greatly improve human-computer interaction (HCI). Depth sensors using surface structured light are practical and widely used. The depth information is obtained using an image block matching algorithm, which searches for the optimal matching block in the image. However, the complex computations require high-performance computers or special chips to achieve real-time performance which increase the depth sensor cost. This paper describes a depth acquisition method based on vector field pattern recognition. The scene depth information is obtained by feature recognition of the vector field for every depth point. The vector field is first generated based on the depth features, then the depth information hidden in the vector field is converted to feature information by the pattern recognition algorithm. The depth information is then obtained by feature matching after an inverse transformation. The inverse transformation uses a searching strategy similar to Hash mapping, which avoids the complexity of a linear search. A smart TV with an infrared transmitter can easily realize natural HCI using this method. | |||
| Key words:depth imagestructured lightvector field | |||
| 收稿日期: 2014-04-14 出版日期: 2015-09-30 | |||
| |||
| 引用本文: |
| 路海明, 王一娇, 谢朝霞. 基于向量场的深度计算方法[J]. 清华大学学报(自然科学版), 2015, 55(8): 916-920. LU Haiming, WANG Yijiao, XIE Zhaoxia. Vector field based depth acquisition algorithm. Journal of Tsinghua University(Science and Technology), 2015, 55(8): 916-920. |
| 链接本文: |
| http://jst.tsinghuajournals.com/CN/或 http://jst.tsinghuajournals.com/CN/Y2015/V55/I8/916 |
图表:
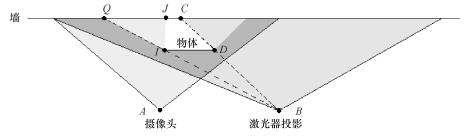 |
| 图1 偏移分析示意图 |
 |
| 图2 结构光图案 |
 |
| 图3 标准圆 |
 |
| 图4 斜率标准值与计算值对比 |
 |
| 图5 1\4匹配图示 |
 |
| 图6 原始图像 |
 |
| 图7 深度值的灰度显示图 |
 |
| 表1 不同匹配算法下的平台处标准差 |
参考文献:
| [1] Malassiotis S, Strintzis M G. Real-time hand posture recognition using range data [J]. Image and Vision Computer, 2008, 26: 1027-1037. [2] CHEN Lulu, WEI Hong, Ferryman J M. A survey of human motion analysis using depth imagery [J]. Pattern Recognition Letters, 2013, 34(15): 1995-2006. [3] 顾骋, 钱惟贤, 陈钱, 等. 基于双目立体视觉的快速人头检测方法 [J]. 中国激光, 2014, 41(1): 0108001-1-0108001-6. GU Chi, QIAN Weixian, CHEN Qian, et al. Rapid head detection method based on binocular stereo vision [J]. Chinese Journal of Lasers, 2014, 41(1): 0108001-1-0108001-6. (in Chinese) [4] SUN Xianfang, Rosin P L, Martin R R, et al. Noise analysis and synthesis for 3d laser depth scanners [J]. Graphical Models, 2009, 71(2): 34-48. [5] XU Jing, XI Ning, ZHANG Chi, et al. Rapid 3D surface profile measurement of industrial parts using two-level structured light patterns [J]. Optics and Lasers in Engineering, 2011, 49(7): 907-914. [6] 于晓洋, 单鹂娜, 曹沈楠, 等. 结构光时间编码技术进展 [J]. 哈尔滨理工大学学报, 2011, 15(1): 98-102. YU Xiaoyang, SHAN Lina, CAO Shennan, et al. The review of structured light time encoding technologies [J]. Journal of Harbin university of science and technology, 2011, 15(1): 98-102. (in Chinese) [7] ZHAO Peng, NI Guoqiang. Simultaneous perimeter measurement for 3D object with a binocular stereo vision measurement system [J]. Optics and Lasers in Engineering, 2010, 48(4): 505-511. [8] ZHAO Peng, WANG Nihong. Precise perimeter measurement for 3D object with a binocular stereo vision measurement system [J]. Optik-International Journal for Light and Electron Optics, 2010, 121(10): 953-957. [9] Lamine H M, Wilfried W, Zohir D, et al. Analysis and estimation of NEP and DR in CMOS TOF-3D image sensor based on MDSI [J]. Sensors and Actuators A: Physical, 2011, 169(1): 66-73. [10] Andrea S, Fabrizio L, Gianluca P, et al. A kinect-based natural interface for quadrotor control [J]. Entertainment Computing, 2013, 4(3): 179-186. [11] Hernández J, Quintanilla A, López L, et al. Detecting objects using color and depth segmentation with kinect sensor [J]. Procedia Technology, 2012, 3: 196-204. [12] 邓瑞, 周玲玲, 应忍冬. 基于 Kinect 深度信息的手势提取与识别研究 [J]. 计算机应用研究, 2013, 30(4): 1263-1265.DENG Rui, ZHOU Lingling, YING Rendong. Gesture extraction and recognition research base on Kinect depth data [J]. Application Research of Computers, 2013, 30(4): 1263-1265. (in Chinese) [13] 杨晓敏, 张奇志,周亚丽. 基于 Kinect 深度信息的人体运动跟踪算法 [J]. 北京信息科技大学学报, 2013, 28(1): 33-37. YANG Xiaomin, ZHANG Qizhi, ZHOU Yali. Human motion tracing algorithm based on Kinect depth information [J]. Journal of Beijing Information Science and Technology University, 2013, 28(1): 33-37. (in Chinese) |
相关文章:
|
