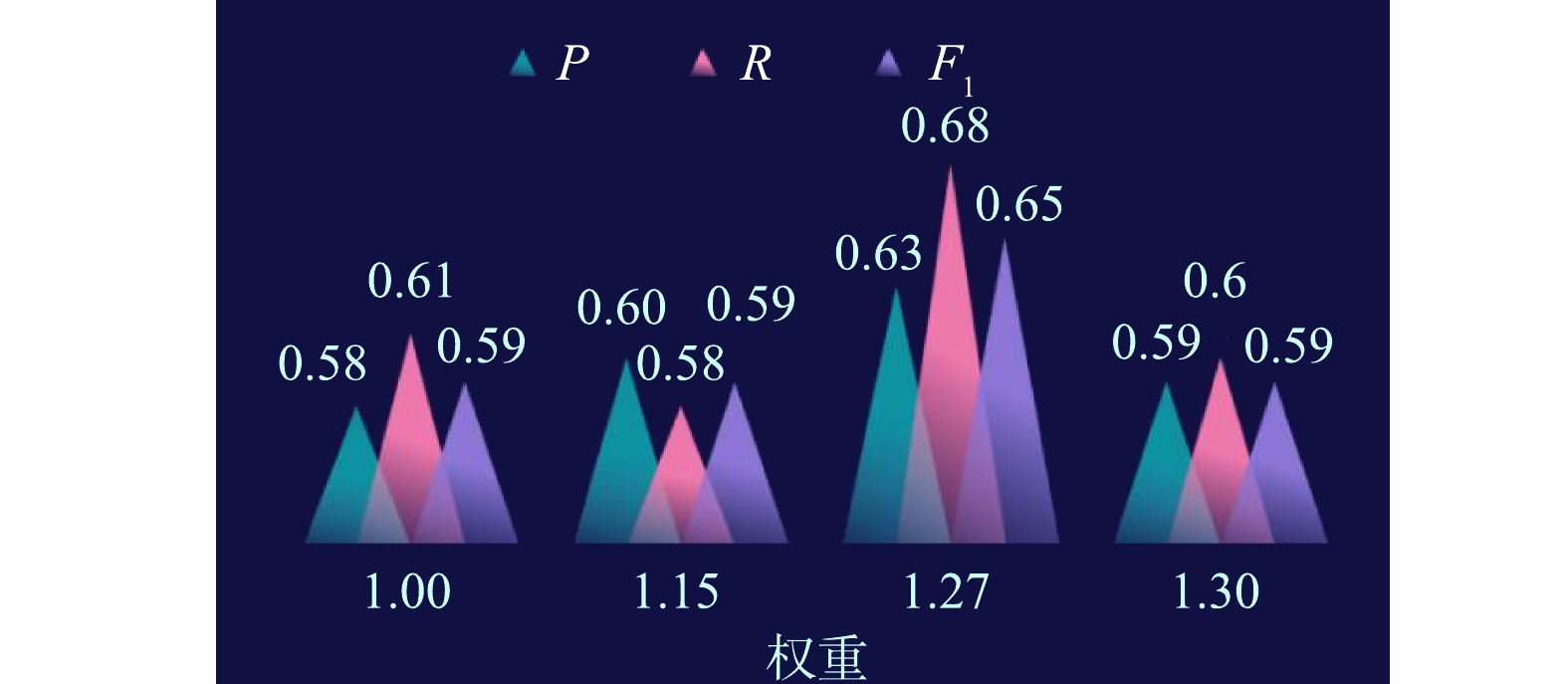
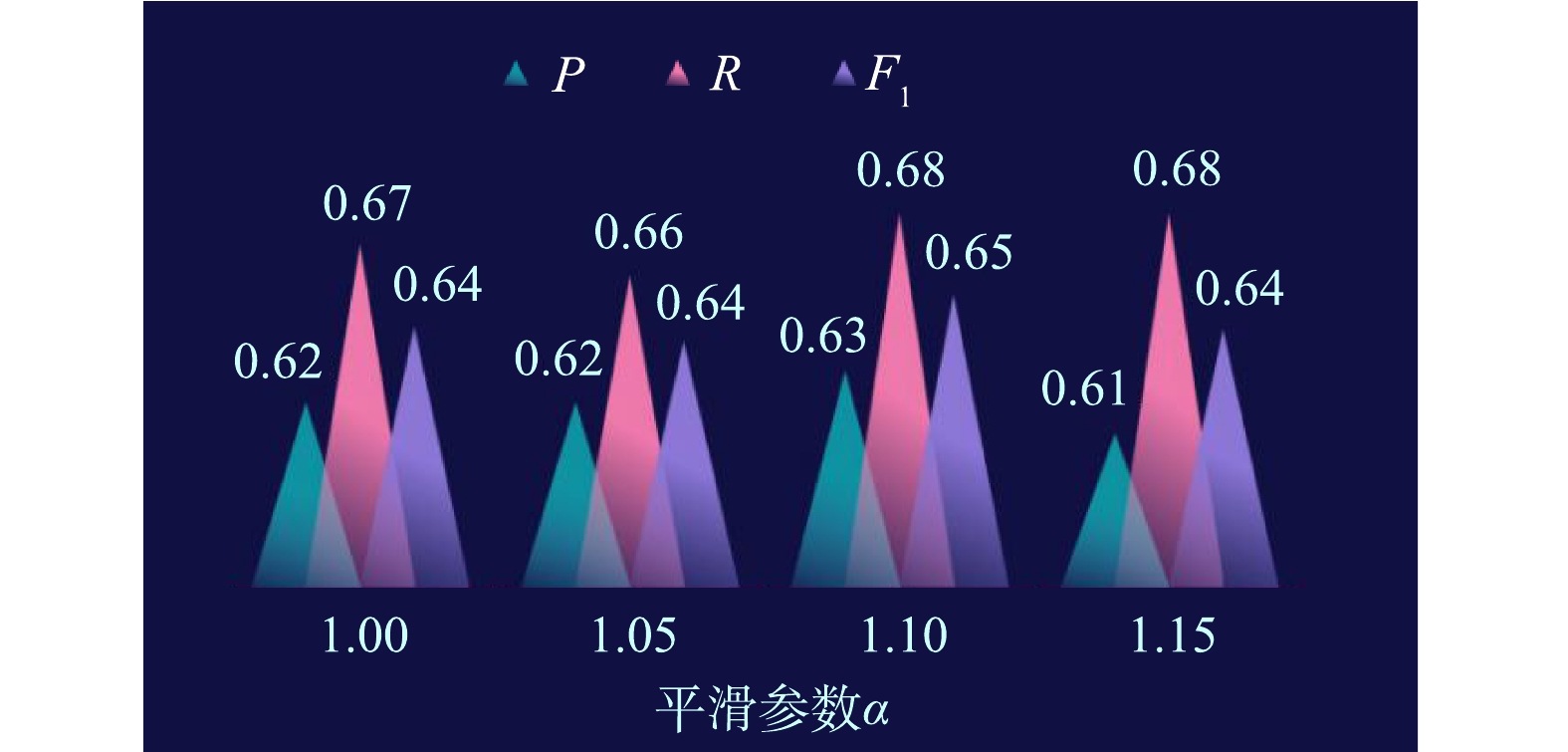
Abstract:Aiming at the problems of low accuracy, inadequate scientific basis, bad wholeness and the difficulty in data sharing of soil contamination identification, a typical city in South China was selected as the research area. Based on the natural language processing and machine learning, an improved naive Bayesian model was constructed by the weights of hot words from an abstract and then utilized to predict the middle-class industries and identify the relevant contamination enterprises from point of interest (POI) data with a big data platform. The results showed that the performance of the naive Bayesian aggregation was better than that of random forest and XGBoost aggregations; the precision, recall and F1 values of the naive Bayesian aggregation were improved by 0.23, 0.23 and 0.23 after the semantic vocabulary database was constructed by enterprise name and business scope; the naive Bayesian model that constructed under the weight of 1.27 and smoothing parameter α value of 1.10 could be used for the prediction of the middle-class industries with the precision, recall and F1 value of 0.63, 0.62 and 0.63, respectively, and 1774 suspected soil contamination enterprises affiliated to 26 industry categories were identified in the research area. Therefore, the improved naive Bayesian model with the good precision and recall values can be effectively used to predict the suspected contamination enterprises, and provides the theoretical bases and design parameters for site contamination identification and risk management. Key words:soil contamination/ natural language processing/ machine learning/ middle-class industries/ contamination enterprise identification/ improved naive Bayesian model.
下载: 导出CSV 表2不同行业分类预测算法性能比较 Table2.Performance comparison of the different industry category prediction algorithms
算法类型
P
R
F1
随机森林
0.28
0.28
0.28
XGBoost
0.31
0.29
0.30
朴素贝叶斯
0.35
0.36
0.35
算法类型
P
R
F1
随机森林
0.28
0.28
0.28
XGBoost
0.31
0.29
0.30
朴素贝叶斯
0.35
0.36
0.35
下载: 导出CSV 表3不同有语义词汇库构建方法引起的朴素贝叶斯算法性能比较 Table3.Performance comparison of the naive Bayesian algorithm by different sematic database construction methods
有语义词汇库构建方法
P
R
F1
企业名称
0.35
0.38
0.36
企业名称+经营范围
0.58
0.61
0.59
有语义词汇库构建方法
P
R
F1
企业名称
0.35
0.38
0.36
企业名称+经营范围
0.58
0.61
0.59
下载: 导出CSV 表4改进型朴素贝叶斯模型的预测结果 Table4.Prediction results of the improved naive Bayesian algorithm
FAZIO M, CELESTI A, PULIAFITO A, et al. Big data storage in the cloud for smart environment monitoring[J]. Procedia Computer Science, 2015, 52: 500-506. doi: 10.1016/j.procs.2015.05.023
HENGL T, DE JESUS J M, HEUVELINK G B M, et al. SoilGrids250m: Global gridded soil information based on machine learning[J]. Plos One, 2017, 12(2): 1-40.
WANG D S, LIU J Z, ZHU A X, et al. Automatic extraction and structuration of soil-environment relationship information from soil survey reports[J]. Journal of Integrative Agriculture, 2019, 18(2): 328-339. doi: 10.1016/S2095-3119(18)62071-4
[12]
CHEN S, LIANG Z, WEBSTER R, et al. A high-resolution map of soil pH in China made by hybrid modelling of sparse soil data and environmental covariates and its implications for pollution[J]. Science of the Total Environment, 2019, 655: 273-283. doi: 10.1016/j.scitotenv.2018.11.230
[13]
JIA X, HU B, MARCHANT B P, et al. A methodological framework for identifying potential sources of soil heavy metal pollution based on machine learning: A case study in the Yangtze Delta, China[J]. Environmental Pollution, 2019, 250: 601-609. doi: 10.1016/j.envpol.2019.04.047
[14]
NASFI R, AMAYRI M, BOUGUILA N. A novel approach for modeling positive vectors with inverted Dirichlet-based hidden Markov models[J]. Knowledge-Based Systems, 2020, 192: 1-17.
[15]
ARPAIA P, CESARO U, CHADLI M, et al. Fault detection on fluid machinery using Hidden Markov Models[J]. Measurement, 2020, 151: 1-7.
1.Chinese Academy for Environmental Planning, Beijing 100012, China 2.School of Water Resources and Environment, China University of Geosciences (Beijing), Beijing 100083, China Received Date: 2020-07-11 Accepted Date: 2020-10-26 Available Online: 2020-11-11 Keywords:soil contamination/ natural language processing/ machine learning/ middle-class industries/ contamination enterprise identification/ improved naive Bayesian model Abstract:Aiming at the problems of low accuracy, inadequate scientific basis, bad wholeness and the difficulty in data sharing of soil contamination identification, a typical city in South China was selected as the research area. Based on the natural language processing and machine learning, an improved naive Bayesian model was constructed by the weights of hot words from an abstract and then utilized to predict the middle-class industries and identify the relevant contamination enterprises from point of interest (POI) data with a big data platform. The results showed that the performance of the naive Bayesian aggregation was better than that of random forest and XGBoost aggregations; the precision, recall and F1 values of the naive Bayesian aggregation were improved by 0.23, 0.23 and 0.23 after the semantic vocabulary database was constructed by enterprise name and business scope; the naive Bayesian model that constructed under the weight of 1.27 and smoothing parameter α value of 1.10 could be used for the prediction of the middle-class industries with the precision, recall and F1 value of 0.63, 0.62 and 0.63, respectively, and 1774 suspected soil contamination enterprises affiliated to 26 industry categories were identified in the research area. Therefore, the improved naive Bayesian model with the good precision and recall values can be effectively used to predict the suspected contamination enterprises, and provides the theoretical bases and design parameters for site contamination identification and risk management.
全文HTML
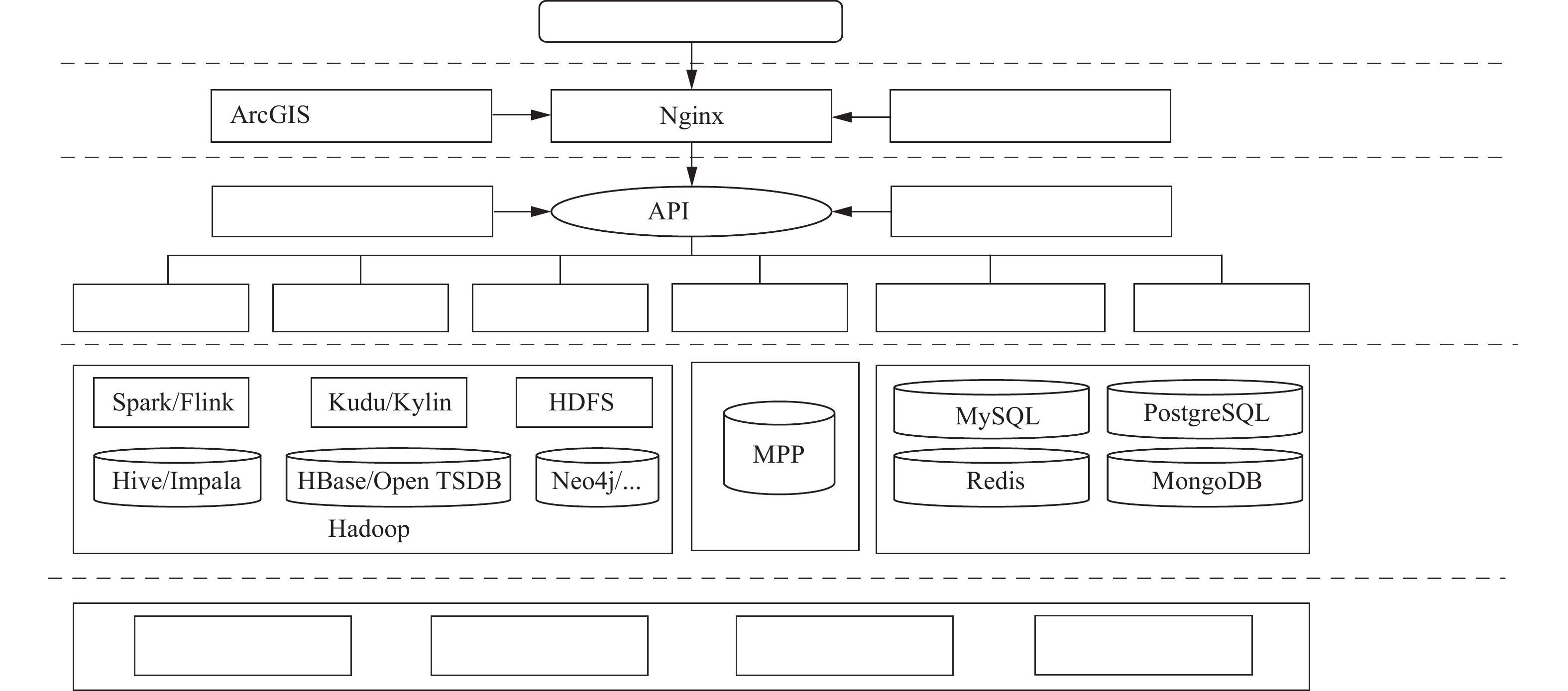
--> --> --> 近年来,场地土壤污染问题越来越受到公众和社会的关注[1-2]。我国在汲取国外近40年治理经验的基础上,提出了“预防为主,保护优先,风险管控”的场地土壤污染防治策略,初步形成了包括法律、法规、导则、指南和规章在内的一整套相对较为完善的场地土壤风险管控体系。尽管如此,我国场地土壤污染风险管理依然处于刚刚起步阶段,尤其是土壤污染底数不清。目前,主要采用现场踏勘、人员访谈、资料分析并结合日常监管等方式进行疑似污染场地识别,但是,这些传统方式的精准性不高、科学性不足、全面性不够,工作效率较低。 近年来,大数据在生态环境保护领域的研究与应用得到了快速发展[3-10],特别是利用大数据开展土壤污染风险识别与风险管控的研究越来越受到研究者的关注[11-13]。针对非结构化调查报告,利用自然语言处理,自动提取和生成结构化土壤污染信息,实现土壤数据分析已见报道[11]。有****基于第二次土地调查数据,结合高程、地貌、土地类型等17个环境协变量数据,利用随机森林、极端梯度提升等,绘制了高精度的全国土壤pH空间分布地图,并推测了土壤重金属环境容量[12]。值得一提的是,JIA等[13]考虑到政府部门间存在数据孤岛、数据共享难度大等问题,以长江三角洲地区为研究区,基于兴趣点(Point Of Interest)的非结构化文本数据,利用多项式朴素贝叶斯算法,识别了疑似土壤污染企业,对场地调查评估、风险管控等环境管理提供了良好的决策支撑作用。但是,该研究仅能识别《国民经济行业分类》(GB/T 4754-2017)中大类行业企业,利用企业名称构建有语义词汇库,且未构建无语义词汇库[13]。识别中类甚至小类行业以提高预测精度、增加有语义词汇库库容以克服朴素贝叶斯算法的过度拟合和零概率现象、构建无语义词汇库以降低维数和提高运算速度等已成为疑似土壤污染企业识别中迫切需要解决的问题。 鉴于此,本研究以南方某地级市为研究区,借助大数据平台,基于自然语言处理和机器学习,尝试利用改进型朴素贝叶斯算法,预测POI数据中企业所属中类行业类别,识别疑似土壤污染企业,以期为场地污染识别与风险管控实践提供理论依据和设计参数。
 下载:
下载:  点击查看大图
点击查看大图