传统的模糊ART只将模糊相似度作为分类的依据,没有考虑状态变量的物理含义,在智能决策应用中存在分类不合理的问题.本文提出在模糊ART的共振条件中加入分类的边长约束的改进,以使得分类所覆盖的各状态变量的范围得到限制,分类更为合理.
将模糊ART与强化学习算法结合[5, 11, 12]可完成智能决策所需的状态分类和学习决策规则的任务.强化学习通过与环境交互得到的反馈进行调整,以获得更好的行为.Q学习是强化学习的一种,通过与“状态-动作对”相关联的Q值来调整行为.本文将改进的模糊ART与Q学习算法结合,给出了约束边长FART-Q智能决策网络结构.
本文对约束边长FART-Q智能决策网络进行了仿真实验,验证了改进算法的效果.
1 模糊自适应共振理论1.1 模糊ART神经网络1.1.1 模糊运算与模糊子集在模糊理论[7]中,对n维向量a和b,模糊与运算(∧)定义为
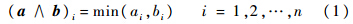
若a和b满足
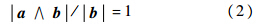
则称b是a的模糊子集,其中,x=
 xi.由模糊与运算的定义可知,a∧b/b∈[0, 1],此比值大小代表b是 a的模糊子集的程度.
xi.由模糊与运算的定义可知,a∧b/b∈[0, 1],此比值大小代表b是 a的模糊子集的程度.1.1.2 模糊ART分类算法模糊ART是一种对连续数值向量进行自适应聚类的分类算法.图 1所示为模糊ART的神经网络结构.
 |
| 图 1 模糊ART网络Fig. 1 Fuzzy ART network |
| 图选项 |
网络由输入层F1和输出层F2组成.输入层有L=2M个神经元,接收输入向量:
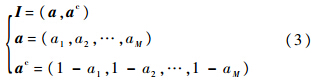
其中,am∈[0, 1];ac是a的补.对输入向量采用互补编码,可有效防止分类数激增[7].输出层有N个神经元,输出分类结果.每个输出层神经元连接有一个权值向量:
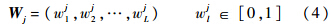
模糊ART分类算法步骤如下:
1) 初始化神经网络,N=0.向输出层添加第1个神经元,N=1,且对所有l=1,2,…,L,令w1l=1.
2) 输入待分类向量I,对输出层的每个神经元,计算选择函数:
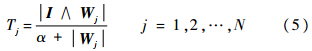
其中α是值很小的正常数.
3) 对选择函数最大的神经元J,验证共振条件:
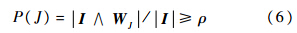
其中ρ∈[0, 1]为警戒值.若满足共振条件,进入下一步;否则将TJ置为0,重复步骤3),直至满足共振条件.
4) 对神经元进行学习:
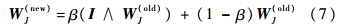
其中β∈[0, 1]为学习率,若β=1则称为快速学习.
5) 输出分类结果:
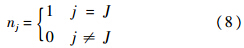
6) 若J=N,则向输出层新增加一个神经元(N:=N+1),且对所有l=1,2,…,L,令wNl=1.
最后一个输出层神经元的所有权值都为1,确保了共振条件一定能够满足.
可见,模糊ART网络是依据输入向量与权值向量间的“模糊相似度”来进行分类的.这里,模糊相似度由WJ是I的模糊子集的程度以及I是WJ的模糊子集的程度共同决定.
1.2 约束边长的模糊ART某些情况下,两个模糊相似度较高的输入向量所代表的物理含义并非相似,甚至相差很大.
在智能决策应用中,待分类的状态向量往往是由多个物理含义不同的变量,经归一化处理后组合而成的.例如,智能小车的目标方向需要用角度等变量描述[13].以目标方向角 φ 为例,其取值范围通常为(-π,π].对φ进行归一化,有
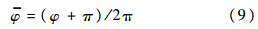
则x∈(0,1],可作为模糊ART分类网络输入向量中的一维.
考察如下两个输入向量,M=2,设其中的第1维为x的值:
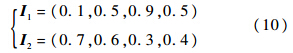
设网络参数α=0.1,β=1,ρ=0.5,当I1输入到全新的网络中时,分类结果为第1类,且有
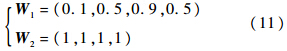
当I2输入到网络中时,T1≈0.619,T2≈0.488,T1>T2,故J=1.又
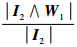 =0.65>0.5满足共振条件,故分类结果仍为第1类,且有
=0.65>0.5满足共振条件,故分类结果仍为第1类,且有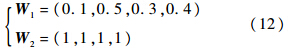
I1中,x=0.1,即φ=-0.8π;I2中,x=0.7,即φ=0.4π.
两种情况下,目标分别处在左后方和右前方,态势相差甚远.如果将这两种态势分为一类,会对后续的决策造成非常不利的影响.
文献[7]指出,模糊ART网络中的任一输出层神经元j均满足如下条件:
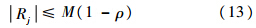
其中,Rj为神经元j所代表的分类区域,|Rj|=
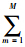 |(1-wjM+m)-wjm|为该区域所有边长的和.
|(1-wjM+m)-wjm|为该区域所有边长的和.当M=2时,设输入I=(a,ac),相应地可将权值向量写为Wj=(uj,vcj),uj,vj均为二维向量.令uj,vj分别代表二维平面中的一个点.前例中W1=(0.1,0.5,0.3,0.4),则u1=(0.1,0.5),v1=(0.7,0.6),R1即为图 2中的长方形区域.
 |
| 图 2 W1所代表的分类区域Fig. 2 Category area covered by W1 |
| 图选项 |
定义输出层神经元j所代表的分类区域的第m个边长为Sjm=(1-wjM+m)-wjm,则式(13)可重写为
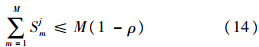
式(12)中W1所表示的分类1的第1个边长S11=(1-0.3)-0.1=0.6 ,该分类覆盖 x∈[0.1,0.7]的范围.
为解决模糊ART网络分类边长可能过大的问题,对原分类算法步骤3)中的共振条件进行加强,得到新的步骤3):
对选择函数最大的神经元J,若满足式(16),且J<N,则对Wj′=I∧Wj求边长向量Sj′=(Sj′1,Sj′2,…,Sj′M),定义边长约束向量:
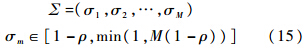
若对所有m=1,2,…,M,都有

则满足共振条件.否则将TJ置为0,重复步骤3),直至满足共振条件.
当∑=(1,1,…,1)时,式(16)恒成立,算法退化为传统的模糊ART.
1.3 边长约束的优点边长约束引入了如下两方面优点:
1) 如1.2节所述,能够避免分类的某个边长过大导致的分类不合理的问题.
2) 对大量输入进行分类时,能够减少分类数量.由式(14)可知,模糊ART限制了分类区域的边长总和.可定义分类区域的体积:

由平均值不等式,结合式(14)可得
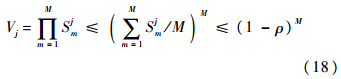
当且仅当 Sj1=Sj2=…=SjM=
Sjm/M时第1个等号成立.而边长约束使得所有边长的大小更接近相等,每个分类区域的体积更大,所以分类数会减少.2 约束边长FART-Q智能决策网络智能决策问题中,通过模糊ART网络可对智能体当前所处的态势进行分类,获得智能体面对环境的状态si,i=1,2,…,N.该状态下相应可选择的动作为aj∈A={a1,a2,…,aP},P为可选的动作个数.对应预期的回报为Q(si,aj)∈[0, 1].Q值可用如下迭代方法[14, 15]求得:
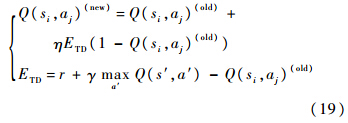
其中,η∈[0, 1]是学习参数;ETD是时域差分值;r是执行动作a带来的回报;γ∈[0, 1]是折扣参数; maxa′ Q(s′,a′) 是下一状态s′下的最大估计回报.初始时,所有的Q值均设为0.5.
将Q学习与模糊ART结合,可用于智能决策.约束边长FART-Q智能决策网络如图 3所示,模糊ART网络输出状态分类si,选取使得Q值最大的动作aK,即
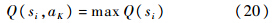
 |
| 图 3 约束边长FART-Q智能决策网络结构Fig. 3 Structure of intelligent decision-making network with bounded FART-Q |
| 图选项 |
执行选取的动作aK后,获得新的态势输入I′,经模糊ART网络分类后得到下一状态s′.将s′和动作aK获取的回报r反馈,则Q值按式(19)迭代更新.
约束边长FART-Q智能决策网络中输出层神经元可用如下数据结构实现:
struct Action_Q
{
int action_index;//动作编号
double Q_value;//Q值
};
class CCategory
{
int category_id;//分类编号
CVector weight;//权值向量
vector
};
约束边长FART-Q智能决策网络的决策步骤如下:
1) 将从传感器等渠道获取的态势信息进行归一化预处理,生成分类输入向量I.
2) 将I输入到模糊ART网络中进行分类,得到分类结果si,并通过学习调整模糊ART网络.
3) 通过状态si的动作-Q值对选取Q值最大的动作aK并执行.
4) 获得执行完aK后的态势输入I′,经模糊ART网络分类后得到下一状态s′,获得执行aK的回报r,并将s′和r反馈给动作-Q值对,通过式(19)学习Q值.
3 智能决策仿真实验3.1 雷区导航实验简介雷区导航(minefield navigation)[13]仿真实验如图 4所示,在尺寸为16×16的正方形网格区域中,随机放置有10个地雷,自动小车放置在一个随机的起点上,小车的任务是一定的步数内,在不碰到障碍(地雷或雷区的边界)的情况下,穿越雷区到达随机选定的终点.每个回合开始前,随机产生上述地雷、起点和终点;回合过程中,地雷和终点的位置不变;当小车到达终点(成功)或碰到障碍(失败),或者超过30步(超时)时,一个回合结束.
 |
| 图 4 雷区导航实验Fig. 4 Minefield navigation experiment |
| 图选项 |
自动小车每一步都执行“探测、移动、学习”的过程.
1) 探测:车的左、左前、前、右前、右5个方向上各有一个传感器,可以探测相应方向上障碍的距离di(i=1,2,…,5);另有一个传感器可以感知终点的相对方向b(1×5),b的每一维代表一个方向,如图 5所示,若终点在相应方向范围内,则这一方向上的值为1,其他方向上值为0.
 |
| 图 5 探测目标相对方向的范围Fig. 5 Destination’s direction scopes relative to the vehicle |
| 图选项 |
2) 移动:小车每次可以向车的左、左前、前、右前、右5个方向移动1格.
3) 学习:每移动1步后,小车可获得相应的回报r(见表 1),Q学习算法根据回报对执行的动作效果进行学习.若移动后,小车离终点更近,则r=0.8,否则r=0.2;若移动后小车到达终点,r=1.0,若碰到障碍,则r=0.
表 1 每步移动后的回报Table 1 Reward of each step
| 移动后结果 | 离终点更近 | 离终点没有更近 | 成功 | 失败 |
| 回报r | 0.8 | 0.2 | 1.0 | 0 |
表选项
令a=(d1,d2,d3,d4,d5,b1,b2,b3,b4,b5),则可将I=(a,ac)作为模糊ART网络的输入,利用第2节所述的约束边长FART-Q决策网络进行动作决策.
3.2 实验结果与分析实验运行的环境为:Intel Core2 P8400,2.26 GHz CPU;2.0 GB内存;32位Windows 7操作系统.
实验分3组进行:第1组和第2组使用传统的模糊ART,即分类边长∑=(1,1,…,1),警戒值ρ分别为0.5和0.8;第3组使用约束边长的模糊ART,分类边长∑=(0.5,0.5,…,0.5),警戒值ρ与第2组相同.表 2所示为每组实验使用的约束边长FART-Q决策网络参数.
表 2 实验中使用的参数Table 2 Parameters used in each test group
| 组号 | α | β | ρ | ∑ | η | γ |
| 第1组 | 0.1 | 1.0 | 0.5 | (1,1,…,1) | 0.5 | 0.1 |
| 第2组 | 0.1 | 1.0 | 0.8 | (1,1,…,1) | 0.5 | 0.1 |
| 第3组 | 0.1 | 1.0 | 0.8 | (0.5,0.5,…,0.5) | 0.5 | 0.1 |
表选项
由于每回合都随机生成起点、终点以及10个地雷,实验结果有一定随机性,故每组实验重复进行10次,每次实验中,小车先清空并初始化约束边长FART-Q网络,然后完成3 000回合的雷区导航任务.
对各组10次实验的统计数据求平均值,3组实验的平均成功率曲线如图 6所示.
 |
| 图 6 3组实验的平均成功率比较Fig. 6 Comparison of average success rate among three test groups |
| 图选项 |
可见,初始时,由于决策网络中均没有知识,成功率都很低.随着回合数增加,网络通过不断学习,知识越来越多,成功率也越来越高.实验数据显示,使用约束边长的模糊ART的第3组实验成功率最高,500回合时成功率就上升到85.6%,1 000回合后成功率一直保持在90%以上.
各组实验3 000回合后的统计数据平均值如表 3所示.
表 3 各组实验的统计数据平均值Table 3 Mean values of statistical results from each test group
| 组号 | 总时间/ms | 总移动步数 | 每步平均时间/ms | 3 000回合后分类数 | 3 000回合成功率/% |
| 第1组 | 10 957.3 | 29 557.5 | 0.367 | 22.7 | 64.37 |
| 第2组 | 49 994.1 | 28 864.4 | 1.732 | 186.6 | 89.24 |
| 第3组 | 30 250.9 | 24 126.1 | 1.253 | 124.1 | 95.26 |
表选项
由前两组实验统计数据可见,在未加入模糊ART分类中的边长约束时,ρ值大的情况下获得的分类数明显更多,分类更细,成功率也明显更高;同时,更多的分类数也导致每次决策的计算时间更长.
由后两组实验统计数据可知,ρ值相同的情况下,加入模糊ART分类的边长约束后,分类数减少33.5%,每次决策的计算时间减小27.7%;而同时,成功率上升了近6%.
加入分类边长的约束使得分类更合理,决策的成功率更高,且使分类数减少,提高了决策速度.
4 结 论1) 本文提出了约束边长的模糊ART算法,并将其与Q学习结合构建了约束边长FART-Q智能决策网络.
2) 经3组雷区导航仿真实验验证,该网络可快速进行智能决策.实验中,输入向量维数为20(M=10),在分类数达到120以上的情况下,每步决策平均用时为1~2 ms;
3) 与传统的模糊ART相比,约束边长的模糊ART能够使分类更为合理,既能提高决策的成功率,又可以减小决策的运算时间.
参考文献
| [1] | 祝世虎,董朝阳,张金鹏,等.基于神经网络与专家系统的智能决策支持系统[J].电光与控制,2006,13(1):8-11.Zhu S H,Dong C Y,Zhang J P,et al.An intelligent decision-making system based on neural networks and expert system[J].Electronics Optics and Control,2006,13(1):8-11(in Chinese). |
| Cited By in Cnki (26) | |
| [2] | 魏强,周德云.基于专家系统的无人战斗机智能决策系统[J].火力与指挥控制,2007,32(2):5-7.Wei Q,Zhou D Y.Research on UCAV' s intelligent decision-making system based on expert system[J].Fire Control and Command Control,2007,32(2):5-7(in Chinese). |
| Cited By in Cnki (12) | |
| [3] | 马耀飞,龚光红,彭晓源.基于强化学习的航空兵认知行为模型[J].北京航空航天大学学报,2010,36(4):379-383.Ma Y F,Gong G H,Peng X Y.Cognition behavior model for air combat based on reinforcement learning[J].Journal of Beijing University of Aeronautics and Astronautics,2010,36(4):379-383(in Chinese). |
| Cited By in Cnki (3) | Click to display the text | |
| [4] | 杨兴,朱大奇,桑庆兵.专家系统研究现状与展望[J].计算机应用研究,2007,24(5):4-9.Yang X,Zhu D Q,Sang Q B.Research and prospect of expert system[J].Application Research of Computers,2007,24(5):4-9(in Chinese). |
| Cited By in Cnki (136) | Click to display the text | |
| [5] | Ueda H,Naraki T,Hanada N,et al.Fuzzy Q-learning with the modified fuzzy ART neural network[J].Web Intelligence and Agent Systems,2007,5(3):331-341. |
| Click to display the text | |
| [6] | 彭小萍.自适应共振理论原理与应用研究[D].北京:北京化工大学,2012.Peng X P.The study on adaptive resonance theory principles and applications[D].Beijing:Beijing University of Chemical Technology,2012(in Chinese). |
| Cited By in Cnki | |
| [7] | Carpenter G A,Grossberg S,Rosen D B.Fuzzy ART:fast stable learning and categorization of analog patterns by an adaptive resonance system[J].Neural Networks,1991,4(6):759-771. |
| Click to display the text | |
| [8] | Hsieh S,Su C L,Liaw J.Fuzzy ART for the document clustering by using evolutionary computation[J].WSEAS Transactions on Computers,2010,9(9):1032-1041. |
| Click to display the text | |
| [9] | Song X H,Hopke P K,Bruns M A,et al.A fuzzy adaptive resonance theory-supervised predictive mapping neural network applied to the classification of multivariate chemical data[J].Chemometrics and Intelligent Laboratory Systems,1998,41(2):161-170. |
| Click to display the text | |
| [10] | Li Y Y,Parker L E.Classification with missing data in a wireless sensor network[C]//Southeastcon,2008.Piscataway,NJ:IEEE,2008:533-538. |
| Click to display the text | |
| [11] | Ediriweera D D,Marshall I W.Advances in computational algorithms and data analysis[M].Netherlands:Springer,2009:293-304. |
| [12] | Araujo R.Prune-able fuzzy ART neural architecture for robot map learning and navigation in dynamic environments[J].Neural Networks,IEEE Transactions on Neural Networks,2006,17(5):1235-1249. |
| Click to display the text | |
| [13] | Tan A H.FALCON:a fusion architecture for learning,cognition and navigation[C]//2004 IEEE International Joint Conference on Neural Networks.Piscataway,NJ:IEEE,2004,4:3297-3302. |
| Click to display the text | |
| [14] | Teng T H,Tan A H.Knowledge-based exploration for reinforcement learning in self-organizing neural networks[C]//Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology,Volume 02.Washington,D C:IEEE Computer Society,2012:332-339. |
| Click to display the text | |
| [15] | Teng T H,Tan A H,Teow L N.Adaptive computer-generated forces for simulator-based training[J].Expert Systems with Applications,2013,40(18):7341-7353 |
| Click to display the text |
