此次专题讲座从数据建模,机器学习与数据挖掘三个角度展开。自动化学院秦曾昌副教授首先介绍了基于数据建模的含义和数据建模的基本思路。所谓数据建模,其基本思路是:首先在假设(hypothesis)的空间中搜索不同的映射关系;然后利用最大似然估计等方法和提供的数据估计相关的参数,从中选出最佳的拟合关系。在实际应用过程中,常常会出现高数据维度的情况,数据建模在高维模型中会显著增大时间代价,因此要考虑利用PCA、SVD等方法将高维空间向低维空间映射。除了数据的维度,数据也可能会有不同类型(types):例如binary,nominal,order等。秦曾昌总结道,“首先要考虑数据的量纲和单位,然后考虑数据的维度,之后再建立数据与要解决的问题之间的关联”。建立好数据与目标之间的关系后,要判断是否为机器学习问题:可以分为有监督学习(对标签进行预测或分类等)、无监督学习(对于概率密度的估计等)、基于优化的问题、降维问题等。确定好问题的类型后,再选择合适的工具解决相关问题。最后,秦曾昌告诉同学们,数学建模没有所谓的正确与否,关键在于对问题的深入理解。
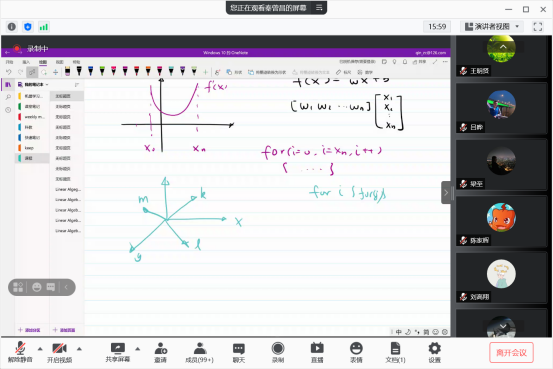
在场的老师与学生通过此次报告对基于数据的建模有了更深的认识和理解。
报告的最后,在场的老师和学生就数据建模领域相关问题与秦曾昌展开讨论,面对大家提出的有关算法和科研等方面的问题,秦曾昌都给与了耐心的解答。
(审核:王少萍)
编辑:贾爱平
