摘要/Abstract
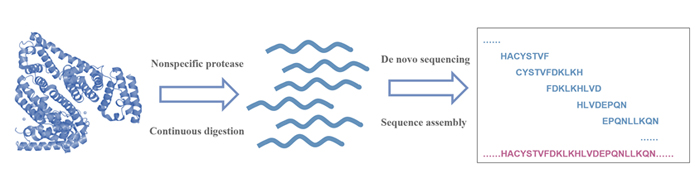
对蛋白质全序列进行测定, 有助于分析蛋白质的结构, 揭示蛋白质的生物学功能. 针对目前基于质谱的蛋白质测序流程中使用特异性蛋白酶酶解产生的肽段种类少、重叠度低、序列拼接困难等问题, 发展了一种基于非特异性蛋白酶连续酶解的蛋白质全序列测定方法. 构建了连续酶解装置, 并使用多种非特异性蛋白酶对蛋白质进行连续酶解. 利用非特异性蛋白酶酶解位点的非特异性、不同的酶解时间以及不同种类蛋白酶酶解产生肽段的互补性, 提高蛋白质酶解肽段的种类和重叠度, 并发展了蛋白质序列拼接算法对液相色谱质谱联用(LC-MS/MS)和从头测序获得的肽段序列进行拼接. 将此方法应用于牛血清白蛋白和单克隆抗体赫赛汀的全序列测定, 在不考虑亮氨酸和异亮氨酸的情况下, 对牛血清白蛋白和赫赛汀轻链的测序准确度达到100%, 赫赛汀重链的测序准确度为99.7%.
关键词: 非特异性蛋白酶, 连续酶解, 序列拼接, 全序列测定
Determining the complete sequence of the protein is helpful to analyze the structure of the protein and reveal the biological function of the protein. In traditional “bottom-up” proteomic strategy, database searching is used to identify sequences of peptides and proteins analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS). It is impossible to identify proteins with unknown sequences through database searching, so de novo sequencing is essential for protein characterization. To increase the accuracy and coverage of protein sequencing, a de novo protein sequencing method based on continuous digestion using various non-specific proteases has been developed. A continuous digestion device was constructed, and a variety of non-specific proteases were used to continuously digest the protein. Taking advantage of the non-specific cleavage sites of non-specific proteases, the complementarity of peptides produced at different time and by different kinds of proteases, the type and overlapping degree of digested peptides were improved. The sequence coverage of peptides after continuous digestion by each protease can reach 100%. Finally, a sequence assembly algorithm was developed to assemble the peptides obtained by de novo sequencing. At first, the candidate peptide sequences were splitted into sequence tags which contain 7 amino acids, and then the most frequently occurring sequence tag was chosen as the seed sequence. Afterwards, the seed sequence was automatically or manually extended to the N-terminal end and C-terminal end respectively according to the scores of sequence tags. Finally, the complete protein sequence was successfully assembled. The developed method was applied to the de novo sequencing of bovine serum albumin (BSA) and monoclonal antibody Herceptin. Excluding leucine and isoleucine, full-length de novo sequencing was achieved with 100% accuracy for BSA and Herceptin light chain. Accuracy of the sequenced Herceptin heavy chain was 99.7%. The de novo sequencing strategy based on continuous digestion of proteins using non-specific proteases can be applied to de novo sequencing of proteins with unknown sequences or quality control of monoclonal antibody drugs.
Key words: non-specific protease, continuous digestion, sequence assembly, full-length sequencing
PDF全文下载地址:
点我下载PDF
