随着机器学习数据量和模型规模的扩大以及其应用场景的扩展(例如联邦学习),机器学习系统逐步以分布式的方式来部署和实现,尤其是在数据中心或多租户多训练工作同步进行的私有集群场景。研究指出,部分训练工作的网络传输时长占训练时间的比例愈来愈高,甚至已经成为瓶颈,制约着分布式学习系统的整体效率。与此同时,通过对分布式学习训练的研究,文章作者注意到分布式训练的网络传输部分有着可以优化的流量模式,再通过与可编程网络的共同设计,提出了ATP系统。
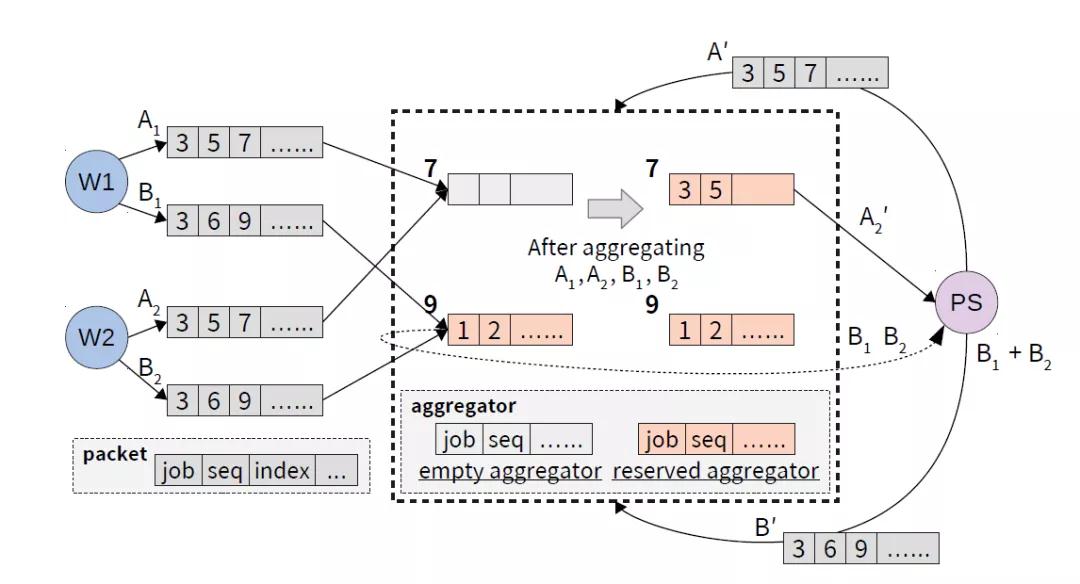
ATP聚合过程图示
ATP是一套面向于多租户多机架场景的机器学习训练加速协议,利用可编程交换机技术对分布式训练的网络传输部分进行聚合优化,建立了一套由终端主机网络协议栈和可编程交换机共同交互组成的高速分布式训练协议,在网络中提供尽力服务(best-effort)及资源动态分配(dynamic)的聚合语义,并考虑了多租户场景下的竞争策略,重新设计了丢包恢复和拥塞控制算法。实验表明,ATP协议在各个不同的模型中效能超越了现时主流通用的分布式框架,并在竞争严重的多租户场景下维持了十分良好的效能。
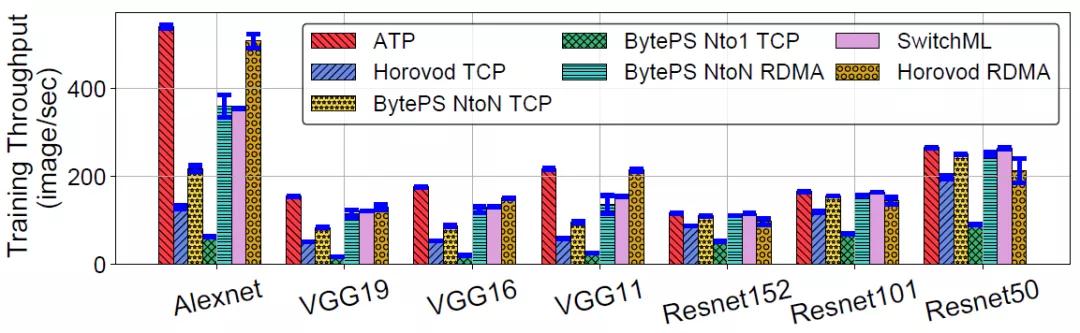
ATP与不同体系结构的训练效果的对比
此项工作由吴文斐研究组与威斯康星大学麦迪逊分校阿迪蒂亚·阿克拉教授(Aditya Akella)研究组合作完成。刘俊林为论文第一作者,吴文斐为通讯作者。

吴文斐研究组
网络系统设计与实现(NSDI)是USENIX旗下的旗舰会议之一,也是计算机网络系统领域的顶级会议。NSDI侧重于网络系统的设计与实现,享负盛名的大数据系统Spark就发表在2012年的NSDI大会上,并取得当年的最佳论文奖。本届NSDI大会共收到369篇投稿论文,并最终接收59篇,接收率为16%,每届NSDI大会都会评选出1篇最佳论文。
论文链接:
https://www.usenix.org/conference/nsdi21/presentation/lao
供稿:交叉信息院
编辑:李华山
审核:李晨晖
2021年04月16日 08:12:09
