以深度神经网络(DNN)为代表的人工智能(AI)处理大多都是计算密集型和存储密集型的计算任务。然而,传统CPU计算平台在处理这类工作任务时正面临越来越多的困难。可重构计算(RC)可以在硬件中执行计算以提高处理能力,同时还可以保留软件解决方案中的大部分灵活性。基于可重构计算模型和原理的集成电路芯片设计已经成为满足人工智能应用中计算的加速性能、吞吐量目标以及功耗、能效要求的有效手段。
《半导体学报》组织了一期“面向高能效人工智能计算的可重构芯片技术”专刊,并邀请中国科学院电子学研究所杨海钢研究员、上海科技大学信息科学与技术学院哈亚军教授、复旦大学微电子学院王伶俐教授、香港科技大学电子和计算机工程系张薇副教授和美国莱斯大学电气与计算机工程系林映嫣助理教授共同担任特约编辑。该专刊已于2020年第2期正式出版并可在线阅读,欢迎关注。
本专刊包含了来自九个优秀团队的研究成果。第一篇综述文章讨论了动态可重构计算的发展趋势;第二篇综述文章展望了面向未来人工智能应用的FPGA设计挑战;第三篇文章则对神经网络加速器的软硬件结构进行了综述。其余的研究工作分别涉及粗粒度数据流重构的神经网络加速方法;基于H-树的均匀PE阵列设计重构机制;基于FPGA的批处理级并行的DNN高效训练实现;低比特位宽的高性能DNN设计;基于时间复用互连的FPGA路由算法;基于CNN的动态电压和频率标度目标检测的能量效率优化方法。
我们衷心希望本专刊能为该领域的研究提供有价值的参考和研究视角,激励更多的研究者探索这一新兴领域。
欢迎阅读!引用!

. Semicond. Volume 41, Number 2, February 2020
1.动态可重构计算的体系结构、挑战与应用
近些年来,芯片的能量效率(性能/功耗)已成为比性能更重要的衡量指标,即计算架构在追求高性能的同时需要严格控制功耗。在许多应用场合中,CPU、DSP等通用处理器往往达不到能效要求。ASIC实现方式虽然能量效率很高,但缺乏灵活性,不能满足多种应用的需求。此外,随着集成电路工艺进步到22 nm以下,芯片生产的NRE费用高得难以承受,小批量的专用电路将难以收回成本,迫切需要使用可编程或可重构的通用计算架构来代替。目前较为成熟的可重构芯片FPGA,由于采用了细粒度结构和静态重构方式,存在面积效率低、功耗大、配置数据量大、重构时间长等缺点。
以CGRA(Coarse-Grained Reconfigurable Array)为代表的动态可重构计算架构具有软硬件双可编程的特性,恰好能够满足上述需求。其将时域计算与空域计算相结合(如图1所示),在实现接近ASIC的高性能的同时兼具可编程性和灵活性。与通用处理器相比,其具有高能效的优势。CGRA采用了与应用相匹配的计算粒度和结构,与FPGA相比,在面积效率、能量效率、重构时间等方面具有很大优势。因此,动态可重构计算得到了学术界和工业界的广泛关注。但由于结构不统一、编程和编译工具不成熟等原因,目前并未被广泛使用。
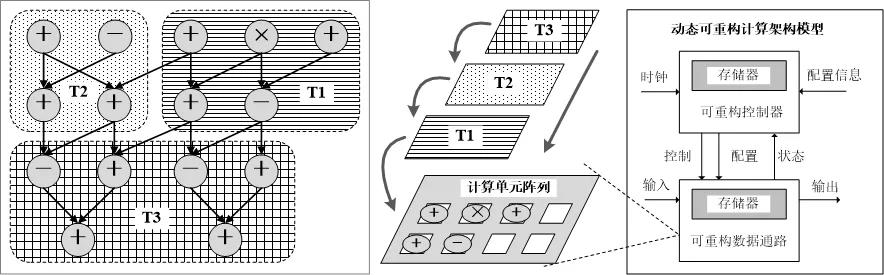
图1. 时域与空域结合的计算架构
与以往关于可重构计算的文章主要讨论FPGA不同,清华大学微电子研究所刘雷波教授等集中讨论了以CGRA为代表的动态可重构计算技术,涉及架构、技术挑战和应用,具体内容包括:体系架构模型和硬件组成(可重构控制器、可重构数据通路、配置信息),编译器框架及编译关键技术(代码变换及优化、任务时域划分、内部存储器管理、配置信息优化等),尚存在的主要技术挑战(时域-空域协同映射、控制密集型任务的并行化方法、配置信息优化组织、配置信息动态加载等)和可能的解决办法,以及未来主要的应用方向(神经网络、密码处理、多媒体应用、信号处理等)。
动态可重构计算技术虽然尚不成熟,但其已经在许多计算密集和数据密集的应用中体现出了兼具高能效和灵活性的明显优势。相信随着技术的不断成熟,动态可重构计算必将得到更广泛地应用,并在主流计算架构中发挥重要作用。
Architecture, challenges and applications of dynamic reconfigurable computing
Yanan Lu, Leibo Liu, Jianfeng Zhu, Shouyi Yin, Shaojun Wei
J. Semicond. 2020, 41(2): 021401
doi: 10.1088/1674-4926/41/2/021401
Full Text
2.AI时代的FPGA芯片设计调查
自2012年AlexNet赢得ImageNet比赛以来,人工智能,更具体地说是DNN(Deep Neural Network),在计算机视觉、语音识别、语言翻译、计算机游戏等领域取得了许多突破。许多高科技公司,如亚马逊、百度、Facebook、谷歌等,都声称自己是“人工智能公司”。我们可以相信未来是一个人工智能时代。
GPU在DNN模型的训练阶段得到了广泛的应用,因为它提供了浮点精度和并行计算能力,同时也具有良好的生态系统。在DNN模型的推理阶段,GPU的功耗是边缘设备所不能容忍的。FPGA可以重新配置以实现最新的DNN模型,并且比GPU具有更低的功耗。这就是微软在云服务中使用FPGA的原因。ASIC可以获得较高的性能,但它具有较高的NRE成本和和较长的上市时间,这也是不可接受的。可重构性、可定制的数据流和数据宽度、低功耗和实时性,使得FPGA成为加速CNN的诱人平台。
复旦大学微电子学院集成电路与系统国家重点实验室来金梅教授等调查了一系列用于人工智能的FPGA芯片设计。但CNN加速器的性能受FPGA的计算和存储资源的限制。虽然在目前的FPGA上可以运用各种提桥来提高推理加速器的性能,但最直接最有效的方法是重新设计FPGA芯片。为了满足不断发展的DNN需求,学术界和FPGA厂商对FPGA芯片的模块或体系结构进行了大量的更新和重新设计。
对于DSP模块,一种设计是支持低精度运算,如9位或4位乘法。DSP的另一种设计是支持浮点乘法累加(MACs),保证了DNN的高精度需求。对于ALM(Adaptive Logic Module)模块,一种设计是支持低精度MAC,ALM的三个修改包括额外的进位链、增加片上MAC操作密度的4位加法器和影子乘法器。ALM或CLB(可配置逻辑块)的另一个设计是支持BNN(二值化神经网络),BNN是DNN的超低精度版本。对于能够存储DNN的权值和激活的存储模块,FPGA厂商提出了三种类型的存储器:嵌入式存储器、封装内的高带宽存储器(HBM)和片外存储器接口(DDR4/5)。
其他的设计改进包括新的架构和专门的人工智能引擎。Xilinx 7 nm的ACAP是第一个自适应计算加速平台,见图1(a)。它的人工智能引擎可以提供高达8倍的计算密度。2019年6月18日,Xilinx宣布,已供货ACAP平台的Versal AI Core系列和Versal Prime系列芯片。在2019年8月29日,英特尔已经开始出货首款10 nm Agilex FPGAs,见图1(b)。10 nm的Intel AgileX与Intel自己的CPU协同工作,提高了计算性能,减少延迟,提高了从边缘设备到网络到云端设备的数据处理能力。
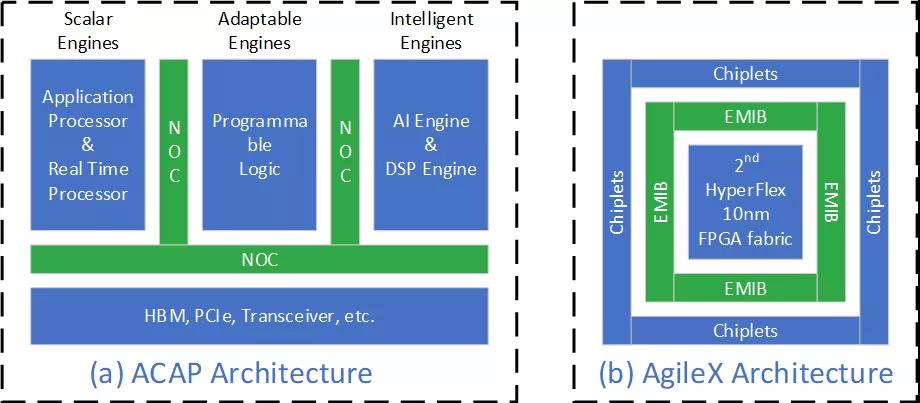
图1:Xilinx和Intel公司最新的FPGA架构
随着人工智能的不断发展,学术界和FPGA厂商将不断地更新FPGA的模块和架构,提高FPGA计算、存储和通信的性能,以满足AI不断变化的新要求。
A survey of FPGA design for AI era
Zhengjie Li, Yufan Zhang, Jian Wang, Jinmei Lai
J. Semicond. 2020, 41(2): 021402
doi: 10.1088/1674-4926/41/2/021402
Full Text
3.软件发展环境下神经网络加速器的调研
近年来,随着人工智能应用的爆发增长,神经网络算法作为其中的核心算法,已经广泛部署在云端服务器与终端设备。神经网络加速器已经成为学术界、工业界的研究热点。而神经网络的模型结构与算法的多样化发展,以及神经网络加速器硬件架构的各异性,对神经网络的软件编程也提出了一系列的挑战。
中国科学院计算技术研究所支天博士等从神经网络算法的发展与演变开始,介绍了一些经典的网络模型结构;从协同算法设计硬件,引出神经网络加速器的硬件架构设计,包括有使用低位宽计算、稀疏、压缩、流水线结构等;之后又介绍了神经网络的软件编程系统,从领域特定语言到神经网络框架,以及软件栈的编译优化方面做了回顾。最后阐述了未来神经网络加速器的发展趋势,需要软硬件的协同配合,共同迭代前进。
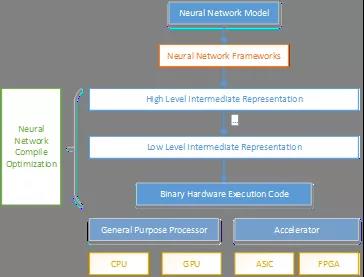
图1. 神经网络编程系统的层次示意图
A survey of neural network accelerator with software development environments
Jin Song, Xuemeng Wang, Zhipeng Zhao, Wei Li, Tian Zhi
J. Semicond. 2020, 41(2): 021403
doi: 10.1088/1674-4926/41/2/021403
Full Text
4.面向混合型紧凑神经网络的粗粒度数据流重构技术及处理器实现
现主流神经网络处理器架构主要针对卷积神经网络进行运算加速,其在数据流处理过程中运用细粒度数据复用技术降低数据存取功耗,该类技术如权重稳定(weight stationary),输出稳定(output stationary)等。然而,随着人工智能应用的发展,近年来神经网络结构快速演进,出现了一系列重要的基本算子,例如紧凑型卷积网络中的点卷积(point-wise convolution)和深度卷积(depth-wise convolution)、残差(shortcut)、长短期记忆层(LSTM)、深度强化学习网络中的状态动作层(state-action)等。多样化网络算子为加速器体系结构设计提出了更高的要求,而传统的细粒度数据复用技术本身并未考虑多样化算子在数据流动性方面的差异。
中国科学院深圳先进技术研究院王铮博士等基于对多样化网络算子数据、计算、存储特性的分析,引入粗粒度数据流重构技术,实现在同一计算架构中对各类网络算子的支持,大幅度复用硬件资源。运用本文所提出思路,设计团队对处理器原型进行了基于65 nm UMC CMOS工艺进行流片。芯片实测功耗在100 MHz主频下仅7.51 mW,功能动态重构时间仅200 ns。
人工神经网络不同基本算子从数据流动特性上均具备各自特有机制,可重构架构根据各层算子计算特性动态重构数据流动方案、计算节点功能与存储功能。通过对神经网络中各基本算子的定性分析,并展示于表1中。不同算子在数据流,运算,存储,激活函数等方面均有较大差别。
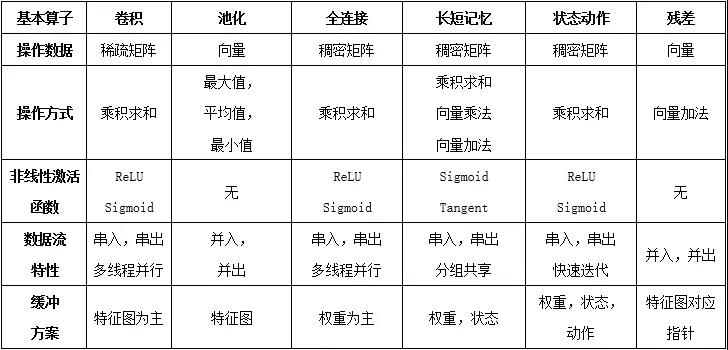
表1 神经网络中基本算子数据、计算、存储特性
图1所示处理器在卷积、池化、全连接、残差、记忆网络、强化学习网络层间进行功能动态改变的实例图。本设计通过指令集复用同一组硬件模块,实现不同核心算子的功能,达到降低额外面积开销,提高资源利用率的目标。
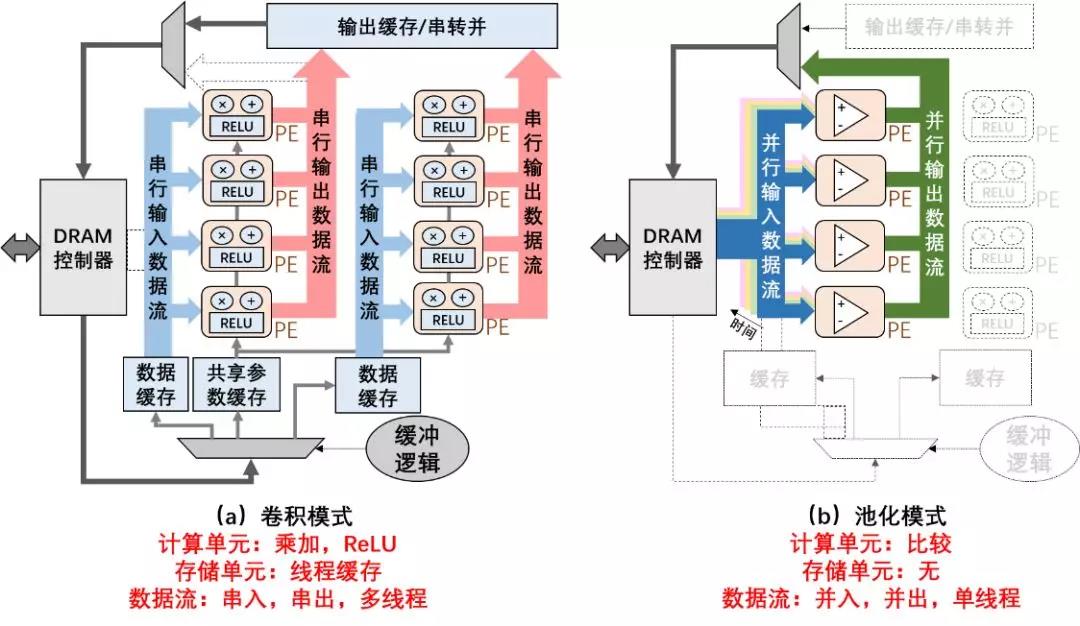
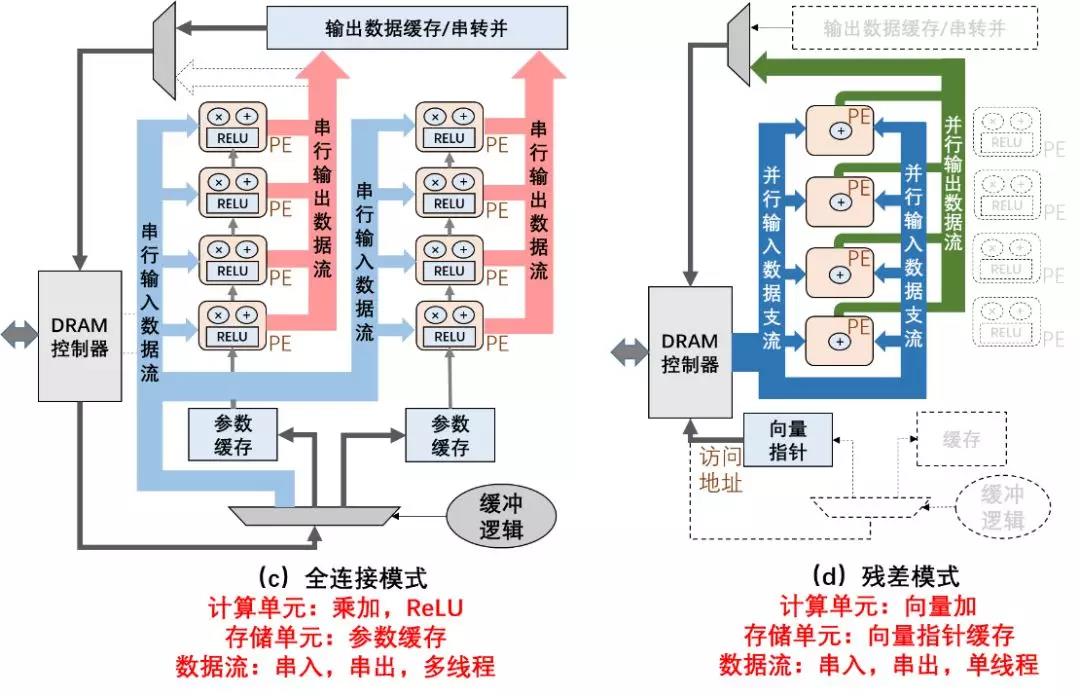
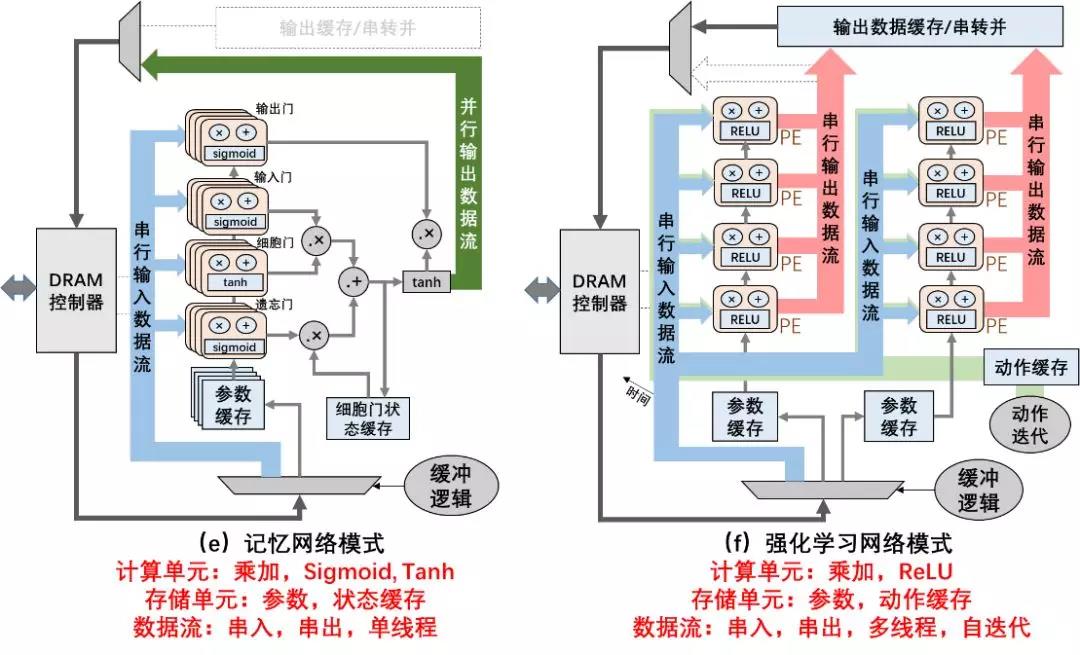
图1 粗粒度神经网络数据流重构方案
基于本文设计思路的处理器采用全数字电路设计与实现,于2018年基于UMC 65 nm工艺流片。该芯片具备16个动态功能可重构神经元,在100 ns时间内重构卷积、池化、全连接网络层,面积3.24 mm2,功耗仅7.51 mW,支持多层大规模混合神经网络的动态部署,并具备完整软件开发工具链,兼容Keras神经网络编程框架。其芯片、测试环境及物理指标如图2所示。

图2 65nm数字可重构人工智能处理器架构,电路实现与物理指标
基于该流片芯片的设计思路,团队将可重构处理器在Xilinx Kintex-7 FPGA模组上进行部署,其支持256个计算节点部署,达到60 MHz主频,可动态重构传统卷积、点卷积、深度卷积、池化、LSTM、状态动作、全连接等网络层。为下一步大规模架构的ASIC设计与流片打下坚实基础。
现有智能处理器功耗在100 mW到10 W区域,其在对能量要求苛刻的场景中使用受限。而MCU等低功耗处理器在解决人工智能运算中无法达到所需的计算能力。本文所设计处理器通过粗粒度资源复用技术,实现7.51 mW的低功耗智能处理器,其达到426GOPS/W的能效比,并具备较强的端到端神经网络编程能力。低功耗智能芯片可以广泛应用于物联网、可穿戴、海洋、航空等领域的智能应用,具备广泛的应用前景。
团队在后续研究中着力挖掘神经网络应用中数据特征,进行数据特征驱动的处理器设计方法,从而从源头上降低所需计算量,以便进一步提高能效比。在智能芯片设计方法方面,团队着力探索计算与存储的配合方案,大幅度利用DRAM有效带宽,引入智能化数据缓冲机制,实现计算与存储的高度协同化。
Accelerating hybrid and compact neural networks targeting perception and control domains with coarse-grained dataflow reconfiguration
Zheng Wang, Libing Zhou, Wenting Xie, Weiguang Chen, Jinyuan Su, Wenxuan Chen, Anhua Du, Shanliao Li, Minglan Liang, Yuejin Lin, Wei Zhao, Yanze Wu, Tianfu Sun, Wenqi Fang, Zhibin Yu
J. Semicond. 2020, 41(2): 022401
doi: 10.1088/1674-4926/41/2/022401
Full Text
5.基于H树的可重构同质PE阵列重构机制
为了适应特定应用中各种算法对不同性能和能效的需求,可重构体系结构已成为学术界和工业界的一种有效方法。但是,由于配置信息更新缓慢和灵活性不足,现有的体系结构存在性能瓶颈。
西安科技大学通信与信息工程学院蒋林教授等提出了一种基于H树的重构机制(HRM),其在PE阵列中采用类霍夫曼编码和掩码的寻址方法,寻找目的PE并完成配置信息的下发。提出的HRM可以在一个时钟周期内以单播,组播和广播模式将配置信息传输到特定的PE,并根据当前配置关闭不必要的PE。该配置网络可实现配置信息实时下发,完成阵列快速重构,对可重构芯片的发展具有一定的参考意义。
图1
HRM: H-tree based reconfiguration mechanism in reconfigurable homogeneous PE array
Junyong Deng, Lin Jiang, Yun Zhu, Xiaoyan Xie, Xinchuang Liu, Feilong He, Shuang Song, L. K. John
J. Semicond. 2020, 41(2): 022402
doi: 10.1088/1674-4926/41/2/022402
Full Text
6.基于FPGA的批处理级并行性实现高效的深度神经网络训练
近年来,深度神经网络(DNN)在图像分类,对象检测和语义分割等多种苛刻应用中取得了令人瞩目的成就。但是,在片上资源有限的嵌入式系统当中,实现深度神经网络应用尤其需要开发实时和低功耗硬件加速器。为此,因此各种硬件设备(包括FPGA和ASIC)被用于实现嵌入式深度神经网络应用。其中FPGA由于其具高可重构性,出色的能源效率和低延迟处理能力,使得其在加速快速发展的深层神经网络硬件加速中受到越来越多的欢迎。
但是,目前大多数FPGA硬件加速器是被应用在加速深度神经网络的推理,他们采用低精度神经网络模型来加速推理过程,而这些模型则是用高精度浮点数格式训练在GPU或CPU上。这样一来,由于深度神经网络使用不同的精度格式进行训练和推理,由此带来的精度损失需要进一步的微调才能弥补。这样分离的训练/推理过程使现有的FPGA加速器难以被广泛运用在同时需要训练/推理的应用中,例如,需要在线学习或持续学习的系统。
为了解决这些问题,复旦大学专用集成电路与系统国家重点实验室罗成博士等通过引入面向批处理的数据模式(我们称为通道高度-宽度-批处理(CHWB)模式),为深度神经网络训练提出了一种新颖的FPGA架构。CHWB模式在相邻的存储器地址处分配不同批次的训练样本,这使并行数据传输和处理可以在一个周期内完成。我们的架构可以在单个FPGA中支持整个训练过程,并通过批处理级并行性对其进行加速。
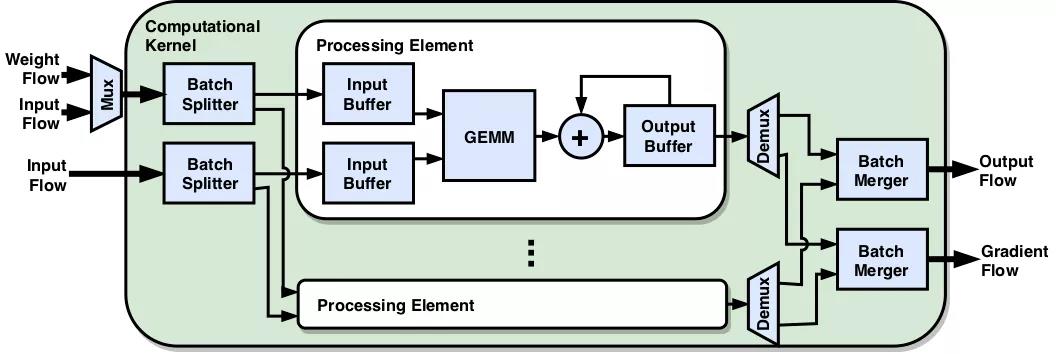
总而言之,本文探索了使用CPU,GPU和FPGA平台进行低精度培训的利弊。开发了一种新颖的FPGA框架,以在具有8位整数的低精度格式的单个FPGA上支持DNN训练。目标是确定在速度和功耗方面,低精度培训中是否可以利用FPGA提供的细粒度可定制性和灵活性来胜过尖端GPU。
Towards efficient deep neural network training by FPGA-based batch-level parallelism
Cheng Luo, Man-Kit Sit, Hongxiang Fan, Shuanglong Liu, Wayne Luk, Ce Guo
J. Semicond. 2020, 41(2): 022403
doi: 10.1088/1674-4926/41/2/022403
Full Text
7.面向深层神经网络的高性能低比特宽训练
深度卷积神经网络(DCNN)被公认为传统计算机视觉(CV)任务(尤其是图像分类)的成功解决方案。但是,这种令人满意的性能通常是以消耗大量计算资源为代价的,这主要是由于昂贵的浮点运算。尽管已经有大量工作致力于面向推理阶段的高效能低位宽CNN加速器,但很少有将CNN训练也纳入硬件加速器的研究,而这却是必要的,因为预训练的参数并不总是可获得的。
在这项工作中,香港科技大学电子与计算机工程系张薇副教授等首先实现了一个完全量化的CNN框架,该框架可以在有限的位宽下执行训练和推理。本文提到,即使使用8位动态定点数(DFP)数据格式,也可以保留CNN浮点数模型的高性能。文中进一步通过HLS实现了一个简单的FPGA原型。结果表明,该设计有助于显著减少硬件资源的使用。
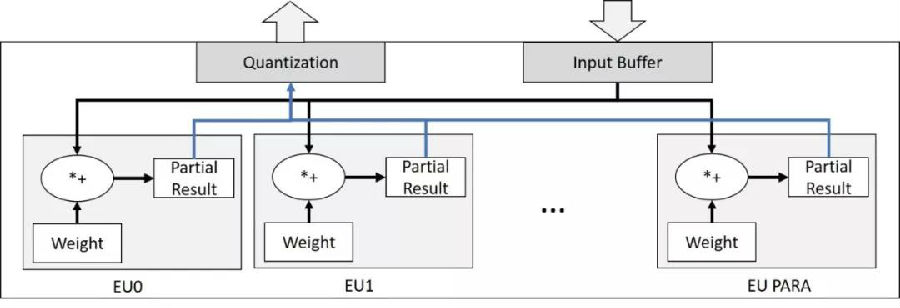
可以预见,在不久的将来,深度学习技术将在许多方面改变我们的日常生活。为了促进其普及,将需要大量的嵌入式系统解决方案,因为它们具有高能效并且可以部署在边缘设备上。我们期望这项工作可以为在这种物联网设备中部署CNN奠定基础。
Towards high performance low bitwidth training for deep neural networks
Chunyou Su, Sheng Zhou, Liang Feng, Wei Zhang
J. Semicond. 2020, 41(2): 022404
doi: 10.1088/1674-4926/41/2/022404
Full Text
8.一种时间复用互连的FPGA路由算法
随着数字电路规模的不断扩大,使用FPGA对电子电路进行仿真的困难也在与日俱增。通过对很多相关文献进行调研发现,FPGA的布线资源匮乏是限制其进行更大规模电路仿真的关键因素,对布线资源的节约使用已经成为对大型电路进行布局布线过程中需要考虑的一个环节。上海科技大学信息科学与技术学院哈亚军教授等设计了一种具有时分复用功能的开关,考虑到每条导线被占用的时间实际上是十分有限的,我们通过对布线器进行修改,加入了时分复用的功能。
通过对每个信号通过每条线的时间进行详细统计,本文将在不同时钟周期被不同信号占据的多条导线合并起来,以减少导线的利用率。通过对本文的设计想法进行编程以及实验,在几乎不牺牲最大电路延迟的基础上实现了百分之二十以上的导线占用率的减少。降低了布线资源的限制对FPGA布局布线成功率的影响。按照设想,这样的设计可以减少布线资源在FPGA布局布线中的需求,并且可以以相同规模的FPGA,实现更加复杂和强大的数字电路。在现在这样一个电子电路规模不断膨胀的时代,能够以更加经济且行之有效的办法实现更强更大的电路,想必是符合时代发展的潮流的。
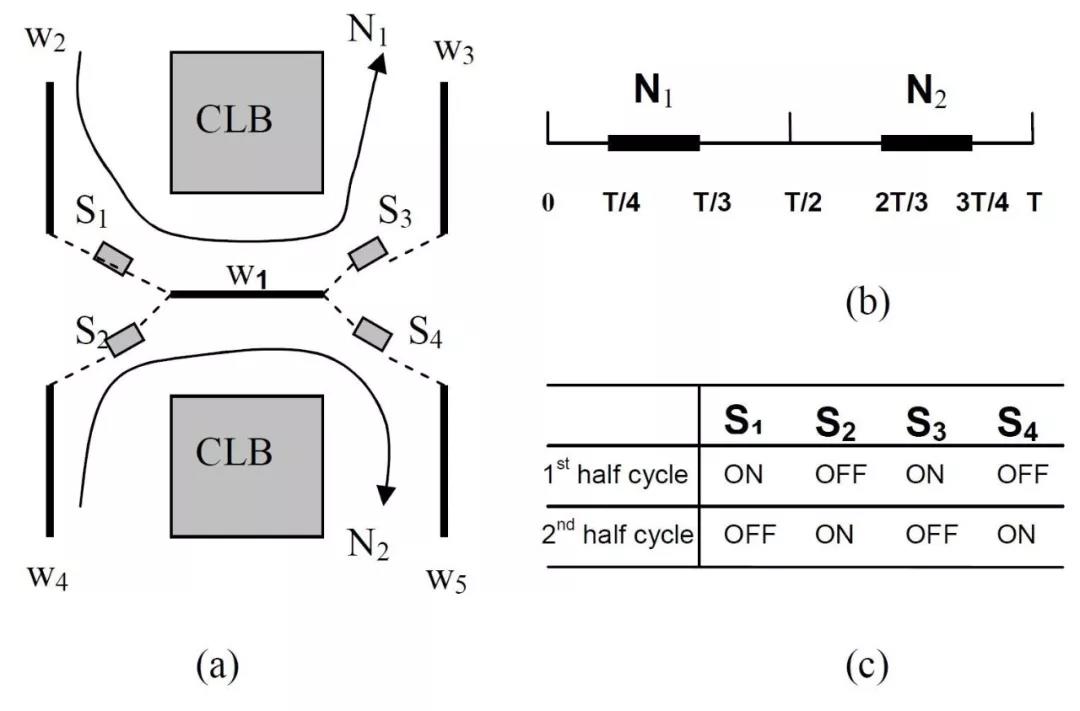
A routing algorithm for FPGAs with time-multiplexed interconnects
Ruiqi Luo, Xiaolei Chen, Yajun Ha
J. Semicond. 2020, 41(2): 022405
doi: 10.1088/1674-4926/41/2/022405
Full Text
9.动态电压和频率标度CNN目标检测的能效优化
上海科技大学信息科学与技术学院哈亚军教授等优化了基于FPGA平台实现目标探测的能效。图片最上方是一台无人机,下方是一个自动驾驶场景。这两个应用场景都会用到目标探测技术,同时对计算平台的能效有较高要求。
一方面,在FPGA上加速卷积神经网络(CNN)要求在边缘计算场景中不断提高能效。另一方面,与其他常见的数字算法不同,CNN即使在有限的定时误差下也能保持其高鲁棒性。通过利用这一独特功能,我们提出使用动态电压和频率调整(DVFS)进一步优化CNN的能效。首先,我们在FPGA上开发了DVFS框架。其次,我们将DVFS应用于SkyNet,这是一个针对对象检测的先进神经网络。第三,我们从性能,功率,能效和准确性方面分析了DVFS对CNN的影响。与最新技术相比,实验结果表明,我们的能效提高了38%,而准确性没有任何损失。结果还表明,如果允许精度降低0.11%,我们的能效可提高47%。我们的工作将为近似计算和能源优化等方向提供思路。
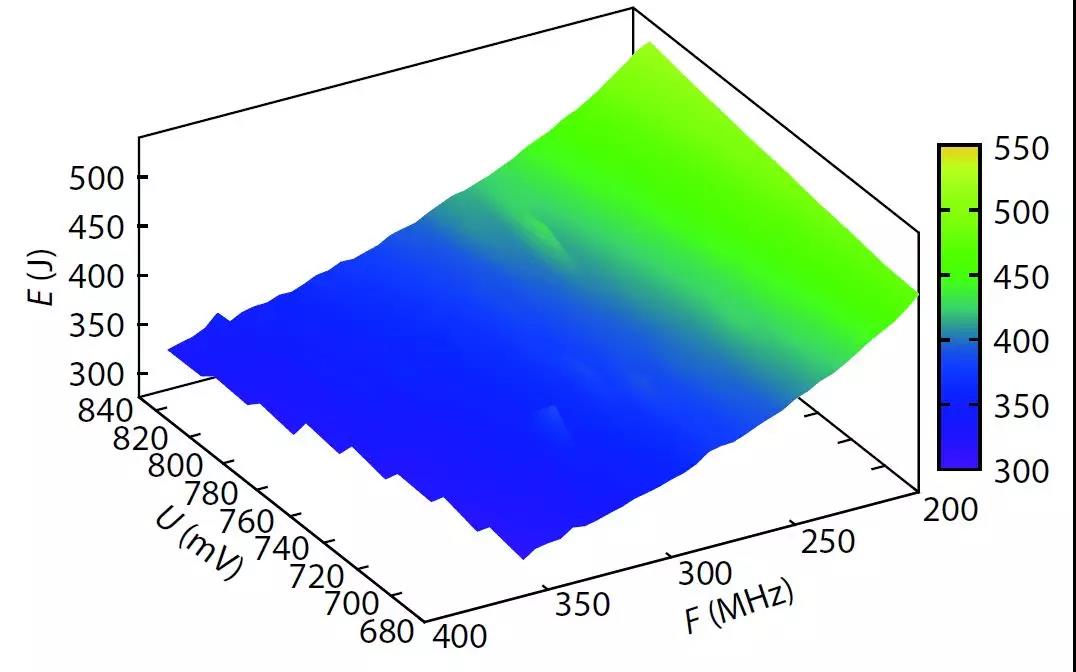
Optimizing energy efficiency of CNN-based object detection with dynamic voltage and frequency scaling
Weixiong Jiang, Heng Yu, Jiale Zhang, Jiaxuan Wu, Shaobo Luo, Yajun Ha
J. Semicond. 2020, 41(2): 022406
doi: 10.1088/1674-4926/41/2/022406
Full Text
(来源:半导体学报2020年第2期--面向高能效人工智能计算的可重构芯片技术专刊)
