HTML
--> --> -->As far as neutrinos are concerned, at present there are known to be three neutrinos of different flavours, to which the three charged leptons correspond. The existence of the three light neutrino species has been known since the time of LEP. The central value for the effective number of light neutrinos,
$ \begin{pmatrix}{ { \big| {\nu^{(f)}_{\alpha}} \big\rangle}} \\ {\big| {\widetilde\nu^{(f)}_{\beta}} \big\rangle}\end{pmatrix} = \begin{pmatrix} {{ {\rm{U_{PMNS}}} }} & V_{lh} \\ V_{hl} & V_{hh} \end{pmatrix} \begin{pmatrix}{{\big| {\nu^{(m)}_{\alpha}} \big\rangle} } \\ {\big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}\end{pmatrix} \equiv U \begin{pmatrix} {{ {\big| {\nu^{(m)}_{\alpha}} \big\rangle} }} \\{ \big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}\end{pmatrix}\;. $  | (1) |
$\big| {\nu _\alpha ^{(f)}} \big\rangle = \sum\limits_{i = 1}^3 {\underbrace {{{\left( {{{\rm{U}}_{{\rm{PMNS}}}}} \right)}_{\alpha i}}\big| {\nu _i^{(m)}} \big\rangle }_{{\rm{SM}}\;{\rm{part}}}} + \sum\limits_{j = 1}^{{n_R}} {\underbrace {{{\left( {{V_{lh}}} \right)}_{\alpha j}}\big| {\tilde \nu _j^{(m)}} \big\rangle }_{{\rm{BSM}}\;{\rm{part}}}} \;.$  | (2) |
There is a natural explanation of the above structure of
To get physical masses, in the seesaw mechanism, the unitary matrix U in Eq. (1) is used to diagonalize the general neutrino mass matrix
$ M_{SS} = \left( \begin{array}{cc} M_L & M_{D} \\ M_{D}^T & M_{R} \end{array} \right) , $  | (3) |
$ U^{T}M_{SS}U \simeq {\rm diag}(M_{\rm light}, M_{\rm heavy}). $  | (4) |
$|m_D|\ll |m_R| , $  | (5) |
$\begin{array}{l} M_{\rm light} \simeq -M_{D}M_{R}^{-1}M_{D}^{T}, \end{array} $  | (6) |
$ \begin{array}{l} M_{\rm heavy} \simeq M_{R}. \end{array} $  | (7) |
A large scale of
This mechanism was proposed for the first time by Minkowski in 1977 [12]. It originates from the idea of a Grand Unified Theory in which heavy neutrino mass states are present. Such neutrinos are supposed to be sterile, i.e. they are insensitive with respect to the weak interaction. In Ref. [12] a model based on
Nowadays there is a plethora of seesaw models. With neutrino masses ranging from zero to the GUT scale, mass mechanisms introduce different neutrino states [18]. Apart from Dirac or Majorana types, there are pseudo-Dirac (or quasi-Dirac) [19], schizophrenic [20], or vanilla [21] neutrinos, among others. Popular seesaw mechanisms give a possible dynamical explanation for why known active neutrino states are so light. They appear to be of Majorana type (recently a dynamical explanation for Dirac light neutrinos has been proposed [22]). Seesaw type-I models have been worked out in Refs. [12,14,23,24], type-II in Ref. [25], and type-III in Ref. [26]. A hybrid mechanism is also possible [27]. For the inverse seesaw model, see Refs. [28,29]. Some recent and interesting work on seesaw mechanisms which also touch on cosmological and lepton flavor violation issues can be found in Refs. [30-40].
In the present work, we extend the approach defined in our previous works [41,42], where neutrino mixing matrices were considered from the point of view of matrix analysis, to the case of seesaw scenarios. In Ref. [41] we argued that singular values of mixing matrices and contractions applied to interval mixing matrices determine possible BSM effects in oscillation parameters and can be used to define the physical neutrino mixing space. In addition, a procedure of matrix dilation makes it possible to find BSM extensions based on experimental data given for PMNS mixing matrices. In this way, we are closer to understand a long-standing puzzle in neutrino physics, namely if and what kind of extensions with extra neutrino states are possible, beyond the three known light neutrinos mixing picture. Using these techniques, new stringent limits for the light-heavy neutrino mixings in the 3+1 scenario (three active, light neutrinos plus one extra sterile neutrino state) have been obtained [42].
In what follows, we discuss a second part of the neutrino puzzle, focusing on the neutrino mass matrices and trying to figure out how much information the rigid structure of mass matrices characteristic of seesaw mechanisms provides about the neutrino mass spectrum. In a similar spirit, a perturbation theory was used in Ref. [43] to prove that in the seesaw type I scenario we cannot get the fourth light neutrino. This proof was based on a standard seesaw assumption that elements of the heavy neutrino sector represented conventionally by the Majorana mass matrix
$ A = \left( \begin{array}{cc} 100 & -95 \\ -95 & 90 \end{array} \right) $  | (8) |
The structure of the paper is as follows. In the next section we will discuss different ways in which seesaw models can be realized. In Section III the main results are obtained for the neutrino mass spectrum. In a scenario with two sterile neutrinos, analytic entrywise bounds for heavy neutrinos are presented. A higher dimensional situation is discussed using inverse eigenvalue methods for the positive definite matrices only. Also, an alternative proof to Ref. [43] is given, showing that for the seesaw mass matrix with hierarchical block-structured submatrices there are only 3 light neutrino states. In addition, it is shown how large splits among heavy neutrino states can occur. In Section IV we discuss an angle between subspaces of the eigenvalues which connects masses and mixings. In the last section, we conclude our work and present possible directions for further studies of the neutrino mass and mixing matrices. The work is supported by an Appendix where details are given of the matrix theory needed for refining studies of the mass matrix structures.
A.Standard seesaw mechanisms
Oscillation experiments have established that neutrinos are not massless [45,46], and we already know that at least two of the three known neutrinos are massive. This calls for the introduction of massive right-handed neutrino states to the matter content of the theory. Then, similarly to the quark sector where right-handed quark fields are present, right-handed neutrino fields $ {\cal{L}}_{D} = - \bar{\nu}_{L}M_{D}\nu_{R} + {\rm h.c.}, $  | (9) |
$ \nu^{{\cal{C}}} = {\cal{C}}\bar{\nu}^{T} = \nu , $  | (10) |
$ {\cal{L}}_{M} = -\frac{1}{2}\overline{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}}+ {\rm h.c.} $  | (11) |
In the same way
$\begin{aligned}[b] {\cal{L}}_{D+M} = &- \bar{\nu}_{L}M_{D}\nu_{R} -\frac{1}{2} \bar{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}} \\&-\frac{1}{2} \overline{(\nu_{R})^{{\cal{C}}}}M_{R}\nu_{R} + {\rm h.c.} . \end{aligned}$  | (12) |
$ {\cal{L}}_{D+M} = -\frac{1}{2}\bar{n}_{L}M_{D+M}n_{L}^{{\cal{C}}} + {\rm h.c.}, $  | (13) |
The Dirac-Majorana mass term (13) underlies a seesaw mechanism of the neutrino mass generation which tries to explain the small masses of known neutrinos by assuming large masses of sterile neutrinos.
Here we discuss in more detail what has been mentioned in the Introduction. First, we assume that the left-handed Majorana mass term
$ M_{L} \simeq 0, \;M_{D} \sim {\rm EW-}{\rm scale} \ll M_R \sim {\rm GUT-}{\rm scale}, $  | (14) |
Hence, we get the
Kanaya [50] and independently Schechter and Valle [51] showed that it is possible to block diagonalize the seesaw mass matrix, up to the terms of the order
$ \left( \begin{array}{ll} 1 - \dfrac{1}{2}M_{D}^\dagger (M_{R}M_{R}^\dagger )^{-1}M_{D} & (M_{R}^{-1}M_{D})^\dagger \\ -M_{R}^{-1}M_{D} & 1 -\dfrac{1}{2}M_{R}^{-1}M_{D}M_{D}^\dagger (M_{R}^\dagger )^{-1} \end{array} \right). $  | (15) |
$ {\cal{L}}_{\rm eff} = - \frac{1}{\Lambda} \sum_{l',l} y_{l'l}(\Psi_{l'L}^{T}\sigma_{2} \Phi){\cal{C}}^{-1}(\Phi^{T} \sigma_{2} \Psi_{lL}) + {\rm h.c.}, $  | (16) |
$ {\cal{L}}_{\rm eff} \to {\cal{L}}_{L} = -\frac{1}{2} \bar{\nu}_{L}{\cal{M}}_{L}(\nu_{L})^{{\cal{C}}} + {\rm h.c.} $  | (17) |
$ {\cal{M}}_{L} = \frac{y {v^{2}}}{\Lambda}. $  | (18) |
1. Seesaw Type-I (canonical seesaw).
In this case, we add right-handed neutrino fields
$ \begin{aligned}[b]& {\cal{M}}_{L}\to M_{\rm light} \simeq -M_{D}^{T}M_{R}^{-1}M_{D}, \\& \vert { {m}}_{D} \vert \ll \vert { m}_{R} \vert. \end{aligned}$  | (19) |
2. Seesaw Type-II [24, 25].
Instead of
$ {\cal{M}}_{L}\to M_{\rm light} \simeq \frac{\mu {v^{2}}}{M_{\Delta}^{2}}, \quad \vert \mu \vert \sim \vert m_{\Delta} \vert, \ \vert v \vert \ll \vert m_{\Delta} \vert, $  | (20) |
3. Seesaw Type-III [26].
In the last case we complement SM with a fermion triplet
$ {\cal{M}}_{L}\to M_{\rm light} \simeq -y^{T}M_{\Sigma}^{-1}y v^{2}, \quad \vert y \vert \ll \vert m_{\Sigma} \vert, $  | (21) |
2
B.Extended seesaw mass matrices
Now we focus on seesaw extensions connected with extra fermion fields, which is a wide area of studies. In most of them, besides the right-handed neutrino fields $ \begin{aligned}[b] {\cal{L}}_{\rm ESS} =& - \bar{\nu}_{L}M_{D}\nu_{R} - \bar{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}} - \overline{(\nu_{R})^{{\cal{C}}}}M_{R}\nu_{R} \\ &- \bar{\nu}_{L}M_{1} S_{R} - \overline{(\nu_{R})^{{\cal{C}}}}M_{2}S_{R} \\&- \overline{(S_{R})^{{\cal{C}}}}M_{3} S_{R} + {\rm h.c.}, \end{aligned} $  | (22) |
$ {\cal{L}}_{\rm ESS} = -\bar{N}_{L}M_{\rm ESS}N_{L}^{{\cal{C}}} + {\rm h.c.} $  | (23) |
$ M_{\rm ESS} = \left( \begin{array}{ccc} M_{L} & M_{D} & M_{1} \\ M_{D}^{T} & M_{R} & M_{2} \\ M_{1}^{T} & M_{2}^{T} & M_{3} \end{array} \right). $  | (24) |
$ \begin{array}{l}{M_{\rm ISS}} \!=\! \left( {\begin{array}{*{20}{c}}0&{{M_D}}&0\\{M_D^T}&0&{{M_2}}\\0&{M_2^T}&{{M_3}}\end{array}} \right),\;\;\;\;\;{M_{\rm LSS}}\! =\! \left( {\begin{array}{*{20}{c}}0&{{M_D}}&{{M_1}}\\{M_D^T}&0&{{M_2}}\\{M_1^T}&{M_2^T}&0\end{array}} \right)\\{\rm{ where }}:\quad \left| {{m_3}} \right| \ll \left| {{m_D}} \right| \ll \left| {{m_2}} \right|,\;\;\;\;\;\;\;\;\;\;\;\;\;\;\left| {{m_D}} \right|\sim \left| {{m_1}} \right| \ll \left| {{m_2}} \right|.\end{array}$  | (25) |
$ \begin{aligned}[b]& {\rm ISS}: \\& {\cal{M}}_{D} = \left( M_{D}, 0 \right), \quad {\cal{M}}_{R} = \left( \begin{array}{cc} 0 & M_{2} \\ M_{2}^{T} & M_{3} \end{array} \right), \end{aligned} $  | (26) |
$ \begin{aligned}[b]& {\rm LSS}: \\&{\cal{M}}_{D} = \left( M_{D}, M_{1} \right), \quad {\cal{M}}_{R} = \left( \begin{array}{cc} 0 & M_{2} \\ M_{2}^{T} & 0 \end{array} \right). \end{aligned} $  | (27) |
Using Eqs. (4) and (15), we get the following formula for the light neutrino sector in the
$ M_{\rm light} = M_{D}M_{2}^{-1}M_{3}(M_{2}^{-1})^{T}M_{D}^{T}. $  | (28) |
Similarly, in the
$ M_{\rm light} = - M_{D}M_{2}^{-1}M_{1} - M_{1}^{T}(M_{2}^{-1})^{T}M_{D}^{T} . $  | (29) |
We can see that despite differences in the structure of linear, inverse and type-I seesaw scenarios, the corresponding mass matrices can be expressed uniformly by one general matrix,
$ {\cal{M}} = \left( \begin{array}{cc} 0 & {\cal{M}}_{D} \\ {\cal{M}}_{D}^{T} & {\cal{M}}_{R} \end{array} \right), $  | (30) |
The structure of the seesaw mass matrix (30) with the assumption (31) is the starting point for analysis of the general properties of the eigenvalues and eigenvectors which arise.
$ \begin{aligned}[b]{\cal M} = &\left( {\begin{array}{*{20}{c}}0&{{{\cal M}_D}}\\{{\cal M}_D^T}&{{{\cal M}_R}}\end{array}} \right) = \left( {\begin{array}{*{20}{c}}0&0\\0&{{{\cal M}_R}}\end{array}} \right) + \left( {\begin{array}{*{20}{c}}0&{{{\cal M}_D}}\\{{\cal M}_D^T}&0\end{array}} \right)\\ \equiv & {\hat{{\cal{M}}}_R} + {\hat{{\cal{M}}}_D}.\end{aligned}$  | (32) |
Proposition III.1. In the CP-invariant seesaw scenario with
Proof. In the seesaw model, we assume two well-separated scales of elements of the mass matrix (31). Let us split the mass matrix
$ \vert \lambda_{i}({\cal{M}})- \lambda_{i}(\hat{{\cal{M}}}_{R}) \vert \leqslant \rho(\hat{{\cal{M}}}_{D}). $  | (33) |
$ \begin{array}{l} \rho(\hat{{\cal{M}}}_{D}) \leqslant \Vert \hat{{\cal{M}}}_{D} \Vert_{2} = \Vert {\cal{M}}_{D} \Vert_{2} \leqslant \Vert {\cal{M}}_{D} \Vert_{F}, \end{array} $  | (34) |
On the other hand, we know that matrix
$ \vert \lambda_{i}({\cal{M}})- 0 \vert \leqslant \rho(\hat{{\cal{M}}}_{D}) \quad {\rm for} \quad \lambda_{i}(\hat{{\cal{M}}}_{R}) = 0. $  | (36) |
Now, let us assume that
Thus, in the CP-invariant seesaw scenario with
As the matrix
The above discussion relies on the eigenvalues of mass matrices. However, eigenvalues are not good quantities for general neutrino mass scenarios with complex symmetric matrices. Such matrices can have complex eigenvalues, and moreover, they are not always diagonalizable by the unitary similarity transformation. Instead, singular values are useful, since due to the Autonne-Takagi theorem (Theorem B5), we can always find a unitary transformation which will diagonalize the complex seesaw mass matrix. Thus, the above result can be generalized to the complex seesaw scenario with the use of the analog of Weyl's inequalities for singular values.
Corollary 1. In the seesaw scenario with
Proof. For singular values, we have the analog of Weyl's inequalities,
$ \vert \sigma_{i}({\cal{M}}) -\sigma_{i}(\hat{{\cal{M}}}_{R})\vert \leqslant \sigma_{1}(\hat{{\cal{M}}}_{D}) = \Vert \hat{{\cal{M}}}_{D} \Vert_{2}, $  | (38) |
One of the main seesaw mechanism assumptions is that besides the three light neutrinos, all additional neutrinos should be very massive. The masses of heavy neutrinos are dominated by the spectrum of the
$ \sigma_{n}(A) \geqslant \vert {\rm det}\, A \vert \left( \frac{n-1}{\Vert A \Vert_{F}^{2}} \right)^{\textstyle\frac{n-1}{2}} \geqslant X, $  | (39) |
$ \begin{aligned}[b] Y_1 = \frac{a_{11} a_{12}^2}{a_{11}^2-X^2}, \quad Y_2 = \sqrt{\frac{a_{11}^4 X^2+2 a_{11}^2 a_{12}^2 X^2-a_{11}^2 X^4+a_{12}^4 X^2-2 a_{12}^2 X^4}{\left(a_{11}^2-X^2\right)^2}}, \end{aligned} $  | (40) |
$ \begin{aligned}[b] Y_3 = \frac{-a_{11}^2 X^2+a_{12}^4-2 a_{12}^2 X^2}{2 a_{11} a_{12}^2},\quad Y_4 = \sqrt{\sqrt{X^4-a_{11}^2 X^2}-a_{11}^2+X^2}, \end{aligned} $  | (41) |
$ \begin{aligned}[b] a_{12},a_{22} \in \mathbb{R} \land & \Bigg\{ \bigg( a_{11}>X\land X>0\land a_{22}\geqslant Y_1+Y_2\bigg)\lor \bigg( a_{11}>X\land X>0\land a_{22}\leqslant Y_1-Y_2\bigg)\lor \\ &\bigg( X>0\land a_{22}\geqslant Y_1+Y_2\land a_{11}<-X\bigg)\lor \bigg(X>0\land a_{11}<-X\land a_{22}\leqslant Y_1-Y_2\bigg)\lor \\ &\bigg( -X = a_{11}\land a_{12}>0\land X>0\land a_{22}\geqslant Y_3 \bigg)\lor \bigg( -X = a_{11}\land X>0\land a_{22}\geqslant Y_3 \land a_{12}<0\bigg)\lor \\ &\bigg( X = a_{11}\land a_{12}>0\land X>0\land a_{22}\leqslant Y_3 \bigg)\lor \bigg( X = a_{11}\land X>0\land a_{12}<0\land a_{22}\leqslant Y_3 \bigg)\lor \\ &\bigg(-Y_4 = a_{12}\land Y_1-Y_2 = a_{22}\land X>0\land a_{11}<X\land -X<a_{11} \bigg)\lor \\ &\bigg( Y_4 = a_{12}\land Y_1-Y_2 = a_{22}\land X>0\land a_{11}<X\land -X<a_{11} \bigg)\lor \\ &\bigg( a_{12}>Y_4\land X>0\land a_{11}<X\land -X<a_{11}\land a_{22}\leqslant Y_1+Y_2\land Y_1-Y_2\leqslant a_{22}\bigg)\lor \\ &\bigg( X>0\land a_{11}<X\land a_{12}<-Y_4\land -X<a_{11}\land a_{22}\leqslant Y_1+Y_2\land Y_1-Y_2\leqslant a_{22}\bigg) \bigg\}. \end{aligned} $  | (42) |
Theorem III.1. (Schur-Horn) Let
$ \sum\limits_{i = 1}^{k} d_{i} \leqslant \sum\limits_{i = 1}^{k} \lambda_{i} \quad k = 1,\cdots,n \;\; {{and}}\;\; \sum\limits_{i = 1}^{n} d_{i} = \sum\limits_{i = 1}^{n} \lambda_{i}. $  | (43) |
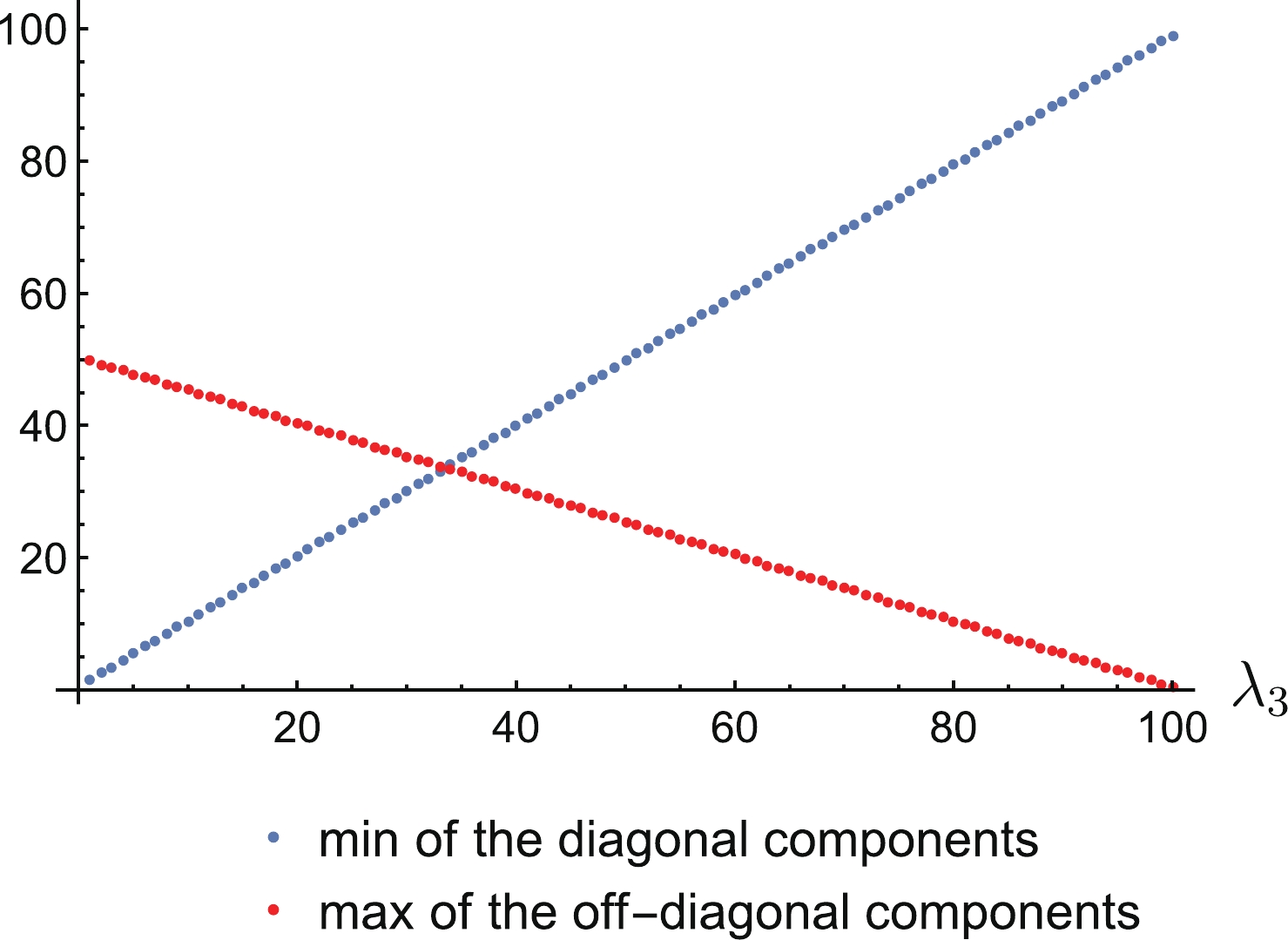 Figure1. (color online) An illustration of the Schur-Horn theorem for the non-negative definite matrix. Two eigenvalues have been set up to
Figure1. (color online) An illustration of the Schur-Horn theorem for the non-negative definite matrix. Two eigenvalues have been set up to To bypass the requirement of non-negative definiteness and CP conservation, we can invoke singular values once again. As in the eigenvalue case, singular values can also be used to reconstruct a matrix via a procedure known as the inverse singular value problem [83,84]. However, we currently have at our disposal only theorems which connect eigenvalues and singular values (Weyl-Horn theorem [85,86]) or singular values and diagonal elements (Sing-Thompson theorem [87,88]). Thus, we miss the symmetry of the matrix and further work is needed to combine all these components.
$ \begin{aligned}[b]& (1,0,0,0,0,0,\cdots,0)^{T},\\& (0,1,0,0,0,0,\cdots,0)^{T}, \\ & (0,0,1,0,0,0,\cdots,0)^{T}. \end{aligned} $  | (44) |
 Figure2. (color online) The behavior of the
Figure2. (color online) The behavior of the $ \Vert \sin\Theta(V_{L},V_{L}^{'}) \Vert \leqslant \frac{1}{\delta} \Vert {\cal{M}} - \hat{{\cal{M}}}_{R} \Vert = \frac{1}{\delta} \Vert {\cal{M}}_{D} \Vert, $  | (45) |
● If the separation between light and heavy neutrinos is pronounced, as in the seesaw case, then the subspace spanned by light neutrinos is almost parallel to the 3-dimensional Euclidean space. However, when these two spectra approach each other not much information can be retrieved from Theorem C2.
● Even if the
Our work is based on matrix theory, which is a vast and rich field. We would like to outline a few potential directions related to neutrino physics for further studies:
● Gershgorin circles provide alternative inclusive entrywise bounds for eigenvalues. They can be applied to models with a diagonally dominant mass matrix to get insight into the mass spectrum.
● Symmetric gauge functions are strictly connected to the unitary invariant norms. We use unitary invariant norms in our study of the mixing matrices [41,42,92]. The symmetric gauge functions can provide a new perspective into the mixing analysis.
● The characteristic polynomial with real roots discussed in this work is a particular example of hyperbolic polynomials. This gives the opportunity to study eigenvalue problems from a more general point of view.
● Semidefinite programming (SDP) does not come directly from matrix theory. However, this area of mathematical programming is based on positive-definite matrices. SDP can be used to better understand the region of physically admissible mixing matrices [41,93].
2
A.Matrix norms
Let us begin with consideration the matrix "size" problem. A set of all matrices of a given dimension along with matrix addition and matrix multiplication creates a vector space. Thus, it is natural to consider a size of vectors or a distance between two points of this space. This can be done by introducing a function called the norm.Definition 1 A norm for a real or complex vector space V is a function
$ \tag{A1} \begin{aligned}[b] & \Vert A \Vert \geqslant 0 \ {\rm and} \ \Vert A \Vert = 0 \Leftrightarrow A = 0, \\& \Vert \alpha A \Vert = \vert \alpha\, \vert \Vert A \Vert, \\& \Vert A+B \Vert \leqslant \Vert A \Vert + \Vert B \Vert. \end{aligned} $  |
Definition 2 A matrix norm is a function
$ \tag{A2} \begin{aligned}[b] &\Vert A \Vert \geqslant 0 \ {\rm and} \ \Vert A \Vert = 0 \Leftrightarrow A = 0, \\& \Vert \alpha A \Vert = \vert \alpha \vert\, \Vert A \Vert, \\ &\Vert A+B \Vert \leqslant \Vert A \Vert + \Vert B \Vert, \\& \Vert A B \Vert \leqslant \Vert A \Vert\, \Vert B \Vert. \end{aligned} $  |
$\tag{A3} \Vert A \Vert_{\star} = \max_{\Vert x \Vert_{\star} = 1}\Vert Ax \Vert_{\star}, $  |
● Spectral norm:
● Frobenius norm:
● Maximum absolute column sum norm:
● Maximum absolute row sum norm:
2
B.Eigenvalues and singular values
Neutrinos with definite masses are obtained through a unitary transformation which brings the mass matrix into diagonal form. In a general seesaw scenario where diagonalization is done by the congruence transformation (4), masses are given by singular values. However, if we restrict attention to the CP-invariant case, diagonalization goes through the similarity transformation, and the quantities corresponding to neutrino masses are eigenvalues. We will present a theorem concerning both of these quantities, starting with the notion of a spectral radius.Definition 3. Let
All matrix norms and the spectral radius are connected by the following theorem.
Theorem B1. Let A be an
$ \tag{B1} \rho(A)\leqslant \Vert A \Vert. $  |
Using this theorem we can arrange the eigenvalues of a given Hermitian matrix
$\tag{B2} \lambda_{1} \geqslant \cdots \geqslant \lambda_{n}, $  |
Theorem B3. (Spectral theorem for Hermitian matri-ces)
A matrix
There exists an equivalent decomposition theorem for singular values.
Theorem B4. (Singular value decomposition)
Let
Autonne and Takagi [97,98] gave us a criterion based on singular values, which characterizes the class of symmetric matrices.
Theorem B5. (Autonne-Takagi)
Let
Since there are matrices for which both sets of eigenvalues and of singular values are well defined, the question naturally arises of how these quantities are connected. The following theorem provides the basic relation between these numbers.
Theorem B6. Let
$\tag{B3} \begin{aligned}[b]& \vert \lambda_{1}(A)\cdots\lambda_{k}(A) \vert \leqslant \sigma_{1}(A)\cdots\sigma_{k}(A)\; {for}\; k = 1,\cdots,n \end{aligned} $  |
Using the above definitions and basic theorems, a theorem which bounds eigenvalues of the sum of two matrices can be formulated. In the general case, we can say almost nothing about eigenvalues of the sum of matrices. However, for Hermitian matrices, the situation is more accessible and we have a set of helpful relations. We will present only the main result provided by Weyl [99]; however, it can be extended to more specific cases.
Theorem B7. (Weyl's inequalities)
Let A and B be
$ \tag{B4} \begin{aligned}[b]& \lambda_{j}(A+B) \leqslant \lambda_{i}(A) + \lambda_{j-i+1}(B) ~{for}~ i \leqslant j \\& \lambda_{j}(A+B) \geqslant \lambda_{i}(A) + \lambda_{j-i+n}(B) ~{for}~ i \geqslant j \end{aligned} $  |
$\tag{B5} \vert \lambda_{j}(A+B)-\lambda_{j}(A)\vert \leqslant \rho(B). $  |
As singular values are defined as square roots of the Hermitian matrix
Theorem B8. (Weyl's inequality for singular values)
Let A and B be a
$\tag{B6} \sigma_{j}(A+B) \leqslant \sigma_{i}(A) + \sigma_{j-i+1}(B) ~{for}~ i \leqslant j . $  |
2
C.Eigenspace
The behavior of eigenvectors of a matrix A under a perturbation is much more complicated than that of the eigenvalues. However, in the case of subspaces spanned by eigenvectors there are theorems allowing quantitative prediction of their perturbation. Estimation of the difference between perturbated and unperturbed eigenspaces can be done with the help of orthogonal projections, as the following example shows. Let S be an eigenspace of A spanned by some of its eigenvectors and let $\tag{C1} A = E_{0}A_{0}E_{0}^\dagger +E_{1}A_{1}E_{1}^\dagger , $  |
$\tag{C2} \hat{A} = F_{0}\Lambda_{0}F_{0}^\dagger +F_{1}\Lambda_{1}F_{1}^\dagger . $  |
$\tag{C3} \begin{aligned}[b] \Vert x-\hat{x} \Vert =& \Vert E_{0}\alpha - F_{0}F_{0}^\dagger E_{0}\alpha \Vert = \Vert (I - F_{0}F_{0}^\dagger )E_{0} \alpha \Vert \\ =& \Vert F_{1}F_{1}^\dagger E_{0}\alpha \Vert = \Vert F_{1}^\dagger E_{0}\alpha \Vert. \end{aligned}$  |
Before we move to the main perturbation theorem, let us state the auxiliary theorem which highlights geometric aspects of the relation between subspaces [100].
Theorem C1. Let
$\tag{C4} QX_{1}U_{1}=\left(\begin{array}{c}I \\0 \\0\end{array}\right),$  |
$\tag{C5}QY_{1}V_{1}=\left(\begin{array}{c}C \\S \\0\end{array}\right) , $  |
The relation between matrices C and S resembles the relation between trigonometric functions. This allows us to define angles between subspaces.
Definition 4. Let
$\tag{C6} \Theta({\cal{E}}, {\cal{F}}) = \arcsin S. $  |
Moreover, using the matrix norm we can define the gap between two subspaces.
Definition 5. Let
$\tag{C7} \Vert E-F \Vert = \Vert E^{\perp}F \Vert = \Vert \sin \Theta \Vert . $  |
Theorem C2. Let A and B be Hermitian operators, and let
$ \tag{C8} ||| EF^{\perp}||| \leqslant \frac{1}{\delta} |||E(A-B)F^{\perp}||| \leqslant \frac{1}{\delta} |||A-B|||, $  |
$\tag{C9} \delta = {\rm dist} (\sigma(A),\sigma(B)) = \min \lbrace | \lambda - \mu |: \lambda \in \sigma(A), \mu \in \sigma(B) \rbrace. $  |
