HTML
--> --> -->The success of these deep learning methods is partially owed to their effectiveness in extracting the latent representation from regular Euclidean data (i.e., image, text, speech). Presently, there is an increasing number of demands for effectively analyzing non-Euclidean data with irregular and complex structures. Proposed methods construct this data as graph-structured data and exploit the deep learning to learn their representation. For example, in e-commerce and social media platforms, the graph-based learning system exploits interactions between users and products to make highly accurate recommendations [14,15]. In chemistry, the molecules are modeled as graphs to explore and identify their chemical properties [16]. In the high-energy physics field, researchers need to analyze a large amount of irregular signals. Consequently, studies seek to improve the analysis efficiency with graph neural networks (GNNs). Impressive progress has been achieved, including improvement of the neutrino detecting efficiency on the IceCube [17], exploring SUSY particles [18], and recognizing jet pileup structures [19] on the LHC.
Precise measurement of the cosmic-ray (CR) spectrum and its components at the PeV scale is essential to probe the CR origin, acceleration, and propagation mechanisms, as well as to explore new physics. A spectral break at ~ 4 PeV, referred to as the CR knee, was discovered 60 years ago [20]; however, its origin remains a mystery. Precise localization of the knees of different chemical compositions is key to explore the hidden physics. Current explanations of the CR knee can be classified into two categories with different mechanisms, including the mass-dependent knee and rigidity-dependent knee models [21], where models with the rigidity-dependent knee are often considered to originate from the acceleration limit and the galactic leakage mechanism, and many of these models with a mass-dependent knee are associated with new physics. This new physics involves exploring a new interaction channel and dark matter, as summarized in Ref. [21]. Although extensive efforts were made aiming at resolving this issue, the experimental measurements exhibit large discrepancies between each other [22ЈC25].
The Large High Altitude Air Shower Observatory (LHAASO) performs next-generation CR experiments [26], which aim to precisely measure the CR spectrum along with light groups from 10 TeV to EeV and survey the northern hemisphere to identify gamma-ray sources with a high sensitivity of 1% Crab units. The observatory is located at a high altitude (4410 m a.s.l.) in the Daocheng site, Sichuan Province, China. It consists of an EAS array (KM2A) covering 1.3 km2 area, a 78000 m2 closed packed water Cherenkov detector array (WCDA), and 12 wide-field Cherenkov/fluorescence telescopes (WFCTA). The LHAASO-KM2A occupies most of the area and is composed of two sub-arrays, including a 1.3 km2 array of 5195 electromagnetic particle detectors (ED) and the overlapping 1
The layout of each component of LHAASO is illustrated in Fig. 1, where the red and blue points represent KM2A-ED and KM2A-MD detectors, respectively. The ED detectors are divided into two parts, the central part with 4901 detectors and an out-skirt ring with 294 detectors to discriminate showers with their core located within the central area from the outside ones. An ED unit consists of four plastic scintillation tiles (100 ЁС 25 ЁС 1 cm3 each) covered by 5 mm thick lead plates to absorb the low-energy charged particles in showers and convert the shower photons into electron-positron pairs. The MD array plays the key role in discriminating the gamma-rays from the CR nuclei background, and it offers important information for classifying CR groups. An MD unit has an area of 36 m2, buried by the overburden soil with 2.5 m height for shielding the electromagnetic components in showers. It is designed as a Cherenkov detector underneath the soil, to collect the Cherenkov light induced by muon parts when they penetrate the water tank.
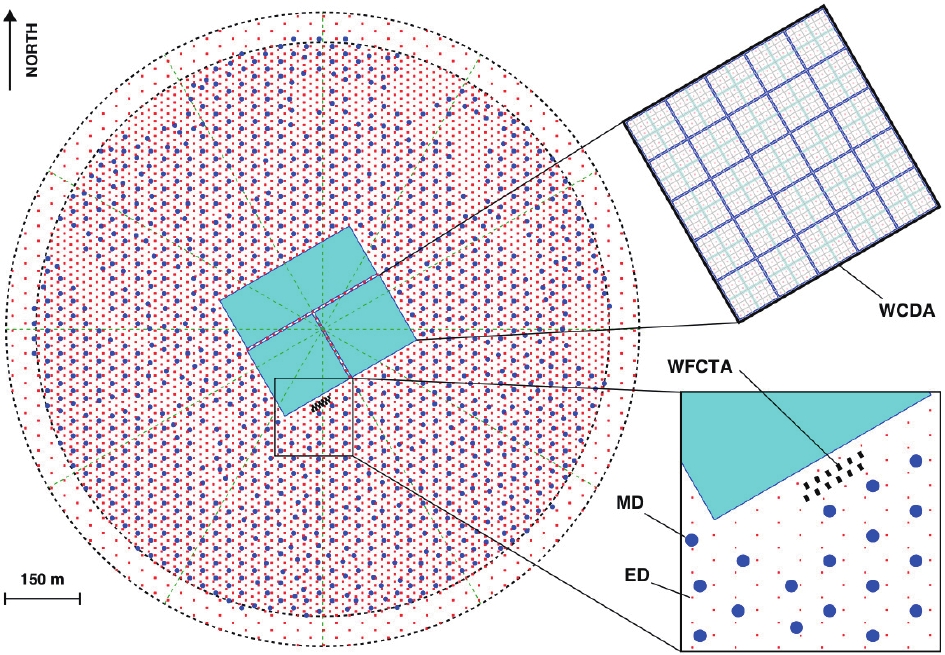 Figure1. (color online) Layout of LHAASO experiment. Insets show details of one pond of WCDA, and EDs (red points) and MDs (blue points) of KM2A. WFCTA, located at WCDA edge, are also shown.
Figure1. (color online) Layout of LHAASO experiment. Insets show details of one pond of WCDA, and EDs (red points) and MDs (blue points) of KM2A. WFCTA, located at WCDA edge, are also shown.Several studies addressed the component discrimination of the LHAASO hybrid detection using both expertise features [27] and machine learning methods [28]. These hybrid detection methods utilize the effective information offered by entire LHAASO arrays. Although they exhibit a remarkable performance, their statistics are limited due to the poor operation time and aperture. Under the merit of the large area, full duty cycle, and excellent
$ \begin{array}{*{20}{l}}{p + p}&{ \to N + N + {n_1}{\pi ^ \pm } + {n_2}{\pi ^0}}\\{{\pi ^0}}&{ \to 2\gamma }\\{{\pi ^ + }}&{ \to {\mu ^ + } + {\nu _\mu }\;({\rm charge\;conjugate},\;c.c.)}\\{{\mu ^ + }}&{ \to {e^ + } + {{\bar \nu }_\mu } + {\nu _e}\;(c.c.)}\end{array}$  |
The task of classifying CR primary groups relies on the electromagnetic and muon parts of the EAS. In the first-order approximation [30], a primary CR nucleus with mass A and energy E can be regarded as a swarm of A independent nucleons generating A superimposed proton-induced hadron cascades with energy
Because the LHAASO-KM2A array can discriminate the electron and muon parts in the shower by ED and MD arrays, we formulate the ratio of collected signals from the MD and ED
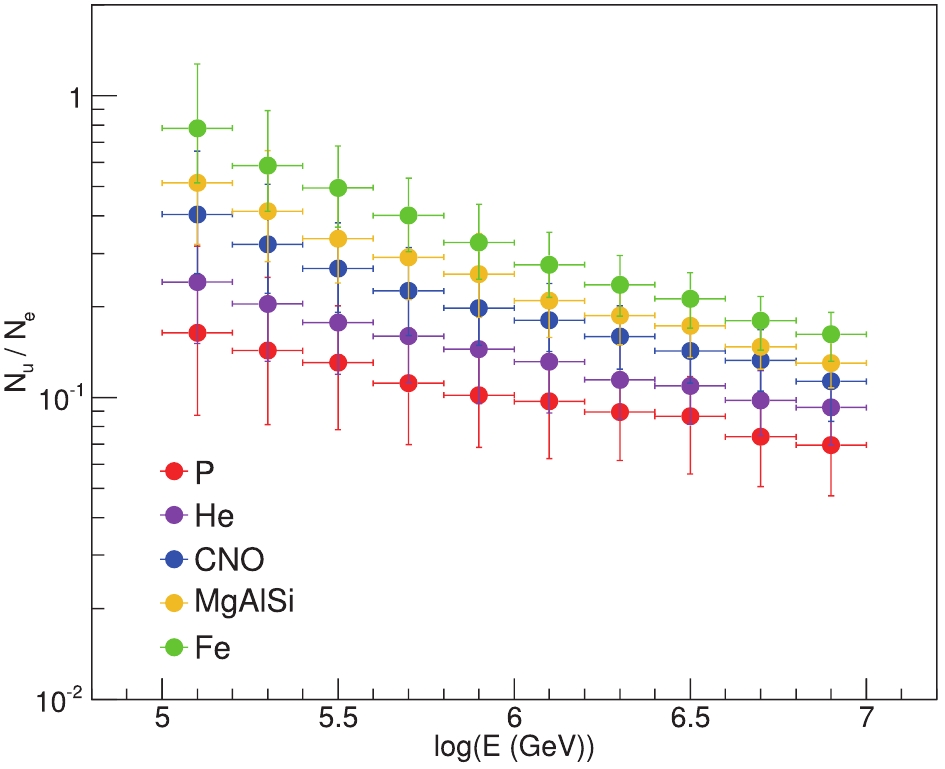 Figure2. (color online) Distribution of
Figure2. (color online) Distribution of 3.1.Graph neural network overview
GNN architectures are specialized to effectively analyze graph-structured data. Many of them adopt the concept from convolution networks and design their graph convolution operations. In comparison with different graph convolution schemes, most GNN models are classified into two categories, including the spectral and spatial domains [31]. The spectral methods are formulated based on the graph signal processing theory [32,33], where the graph convolution is interpreted as filtering the graph signal on a set of weighted Fourier basis functions. Spatial methods explicitly aggregate the information from the neighbor through the weighted edges.Suppose an undirected, connected, weighted graph is denoted as
$ \begin{array}{l} x * G \ g_{\theta} = U g_{\theta} U^T x , \end{array} $  | (1) |
Bruna et al. [34] proposed the first spectral convolution neural network (spectral CNN), with the spectral filter
The spatial-based graph convolution is defined based on the node's spatial relations. Following the idea of "correlation with template", the graph convolution relies on employing the local system at each node to extract the patches. Masci et al. [37] introduced the geodesic CNN (GCNN) framework, which generalizes the CNN into the non-Euclidean manifolds. Boscaini et al. [38] considered it as the anisotropic diffusion process. Monti et al. [39] generalized those spatial-domain networks and proposed mixture model networks (MoNet), a generic framework deep learning in the non-Euclidean domains. In this framework, a spatial convolution layer is given by a template-matching procedure as
$ \begin{array}{l} (f * g)(x) = \displaystyle\sum\limits^{J}_{j = 1} g_j D_j(x) f . \end{array} $  | (2) |
$ \begin{array}{l} D_j(x)f = \displaystyle\sum\limits_{y \in N(x)} \omega_j(u(x,y))f(y), j = 1, \cdots, J \ , \end{array} $  | (3) |
The definition of the patch operator associates MoNet with other spatial-based graph convolutional models through the choice of the pseudo coordinate
$ \begin{array}{l} \omega_j(u) = \exp \left(-\frac12 (u - \mu_j)^T \Sigma^{-1}_j (u - \mu_j)\right), \end{array} $  | (4) |
Spectral-based methods have their mathematical foundations in the graph signal processing; however, high computational costs are involved in calculating the Fourier transform. Spatial-based methods are intuitive by directly aggregating information from the neighbors, and they have the potential to handle large graphs. In contrast, as the Laplacian-based representation is required for spectral convolution, a learned model cannot be applied on another different graph, while the spatial-based convolution can be shared across different locations and structures. Because the CR EAS event changes its location, direction, and energy, the spatial-domain method is suitable to analyze the LHAASO-KM2A experiment.
2
3.2.Graph neural network on LHAASO-KM2A
LHAASO-KM2A detectors can record the arrival time and photoelectron amplitude of shower secondary particles. The distribution of detector photonelectrons with respect to the distance from the shower core roughly obeys the NKG function [40,41] with the most dense region located at the shower core, while the distribution of arrival times can be parameterized as a plane perpendicular to the direction of the shower. Accordingly, we perform the data preprocessing procedure by reconstructing the event to locate the shower core position ( $ \begin{array}{l} {d}T_i = T_i - \dfrac{{{ r}_i} \cdot {{ r}_0}}{c \lVert {{ r}_0} \rVert} - T_0 ,\end{array} $  | (5) |
The ED and MD detectors are constructed as independent, weighted, and undirected dense graphs, with each node containing a three-dimensional vector
 Figure3. (color online) Graph-structured LHAASO-KM2A detectors activated by a 500-TeV EAS event, where red dots represent EDs, and blue dots represent MDs. Dot size depicts logarithmic scale of recorded photoelectrons.
Figure3. (color online) Graph-structured LHAASO-KM2A detectors activated by a 500-TeV EAS event, where red dots represent EDs, and blue dots represent MDs. Dot size depicts logarithmic scale of recorded photoelectrons. Figure4. (color online) Relations among three-dimensional vectors. Left panel:
Figure4. (color online) Relations among three-dimensional vectors. Left panel: $ \begin{array}{l} d_{ij} = {\rm e}^{- \frac12 (\lVert x_i - x_j \rVert - \mu_t)^2 / \sigma_t^2} , \end{array} $  | (6) |
$ \begin{array}{l} a_{ij} = \frac{d_{ij}}{\displaystyle\sum\limits_{k \in N} d_{ik}}. \end{array} $  | (7) |
Before implementing the graph convolution layers, we extract the higher-dimensional features from the input vectors through the learnable function, as shown in Eq. (8), where the
$ \begin{array}{l} x^{(0)} = {\rm ReLu}(W^{(0)} v + b^{(0)}). \end{array} $  | (8) |
$ \begin{array}{l} G{\rm Conv}(x^{(t)}) = W^{(t)} [ x^{(t)}, A x^{(t)} ] + b^{(t)}, \end{array} $  | (9) |
$ \begin{array}{l} {x^{(t+1)} = \begin{cases} {\rm ReLu}(G{\rm Conv}(x^{(t)})), & t+1 < T \\ G{\rm Conv}(x^{(t)}), & t+1 = T \end{cases}} \end{array} $  | (10) |
$ \begin{aligned} x_i^{\rm (pool)} = \frac1N \sum\limits_{n \in N} x_{ni}^{(T)}. \end{aligned} $  | (11) |
$ \begin{array}{l} y = {\rm sigmoid}( W^{\rm (pool)} x^{\rm (pool)} + b^{\rm (pool)} ) , \end{array} $  | (12) |
We construct the GNNs for ED and MD independently, and fuse their outputs through the linear layer in Eq. (12) with the
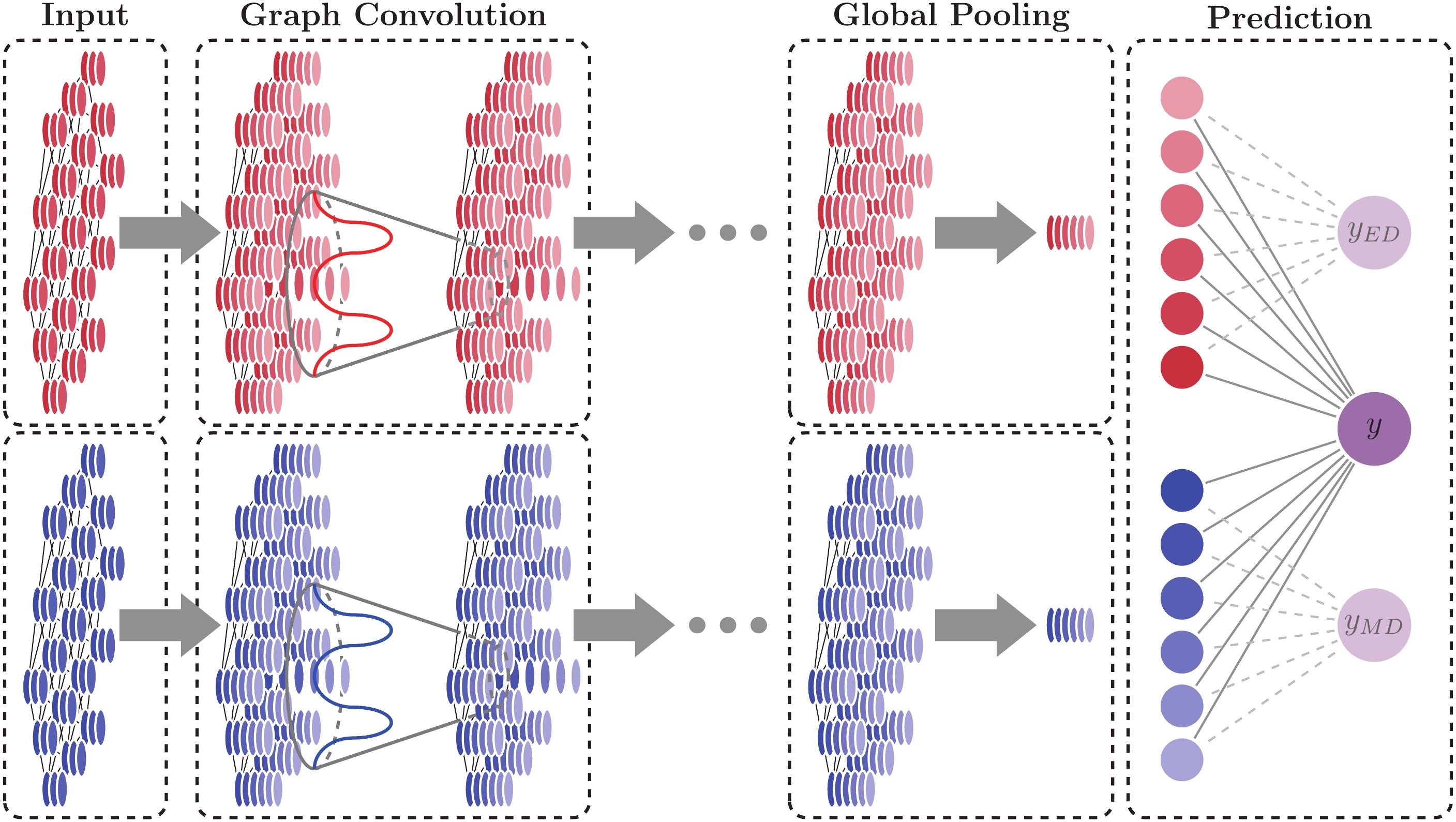 Figure5. (color online) KM2A GNN model. Upper red network represents GNN ED model, and lower blue network represents GNN MD model. Right-most rectangle contains the fusion operation of the two models (GNN ED+MD) and their independent outputs.
Figure5. (color online) KM2A GNN model. Upper red network represents GNN ED model, and lower blue network represents GNN MD model. Right-most rectangle contains the fusion operation of the two models (GNN ED+MD) and their independent outputs.After reconstruction of the simulated events [26], we further select events according to their reconstructed locations and directions. The reconstructed shower core spread inside the KM2A array within the distance 200 ~ 500 m from the array center is selected. We ignore the inner circular area (within 200 m) to suppress the disturbance from the WCDA for the KM2A reconstruction. Further, the reconstructed zenith angle below
| data set | P | L | |||
| signal | background | signal | background | ||
| train | 14635 | 14595 | 24358 | 23733 | |
| test | 2875 | 2831 | 4754 | 4713 | |
| evaluation | 24921 | 22994 | 24921 | 22994 | |
Table1.Number of signal and background events for each dataset.
To train the GNN models, we employ supervised learning techniques with the mean square error (MSE) as the loss function. For each training epoch, the loss is calculated on the test dataset to avoid overfitting. The Adam [45] optimizer is used to optimize the model parameters based on adaptive estimation of low-order moments. The training procedure includes two steps, (i) two independent trainings for the GNN ED and MD models with the learning rate 0.001, and (ii) a subsequent fine-tuning procedure fuses the ED and MD model together with the learning rate 0.0001. It runs over a total of 80 epochs with the model already converged. All code is written in Python using the open-source deep learning framework PyTorch with GPU acceleration. For each model training, four identical candidates with different randomized weights are trained, and the one with the best performance is selected for further processing, which helps suppress the local optimization.
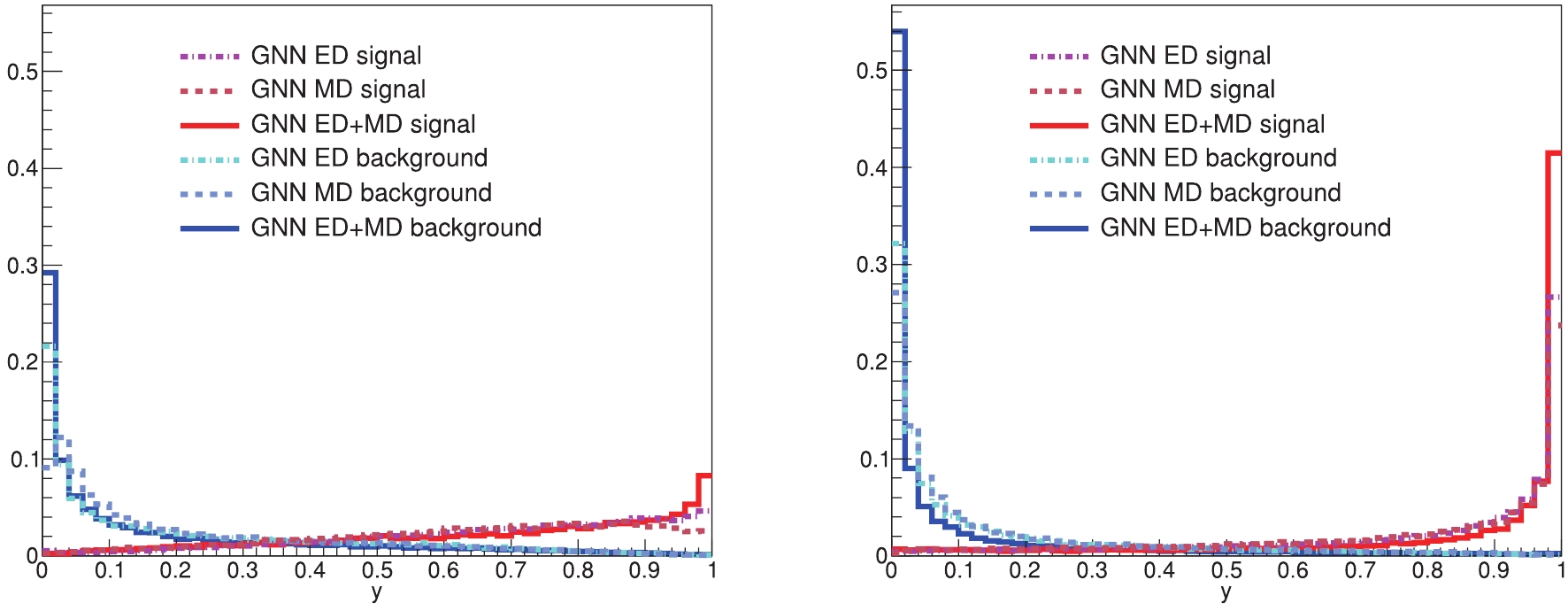 Figure6. (color online) Distribution of output scores from each model for P task (left) and L task (right).
Figure6. (color online) Distribution of output scores from each model for P task (left) and L task (right). Figure7. (color online) ROC curves from each model for P task (left) and L task (right).
Figure7. (color online) ROC curves from each model for P task (left) and L task (right).To reduce the sensitivity to noise due the limited size of the data set and to quantitatively evaluate the model performance, we use the area under the ROC curves (AUC) as a measure of the model performance. We further split the dataset into a sequence of energy bins for comparison of the performance across the entire energy range. We split the energy range withing one order of magnitude into five uniform bins in logarithmic coordinates. The selected events are weighted according to the Horandel model [46] to mimic the actual spectrum for the subsequent analysis. We calculate the AUC values of the models at each bin and plot them in Fig. 8. The results confirm the conclusions announced above. Furthermore, they also show that the fused GNN model outperforms the physics baseline for all energies. We average the AUCs values and list them in Table 2. The fused GNN model achieves the highest score with 0.878 for the P task, and 0.959 for the L task. The AUC score of the L task consistently exceeds the P task by a considerable amount, which is about 0.068 in the physics baseline and rises up to 0.081 in the fused GNN model. Because the nuclear numbers of the Proton and Helium are close, it is difficult to discriminate the Proton from the Helium background.
| P | L | |
| baseline | 0.836 | 0.904 |
| GNN MD | 0.847 | 0.93 |
| GNN ED | 0.861 | 0.936 |
| GNN ED+MD | 0.878 | 0.959 |
Table2.Average AUC scores.
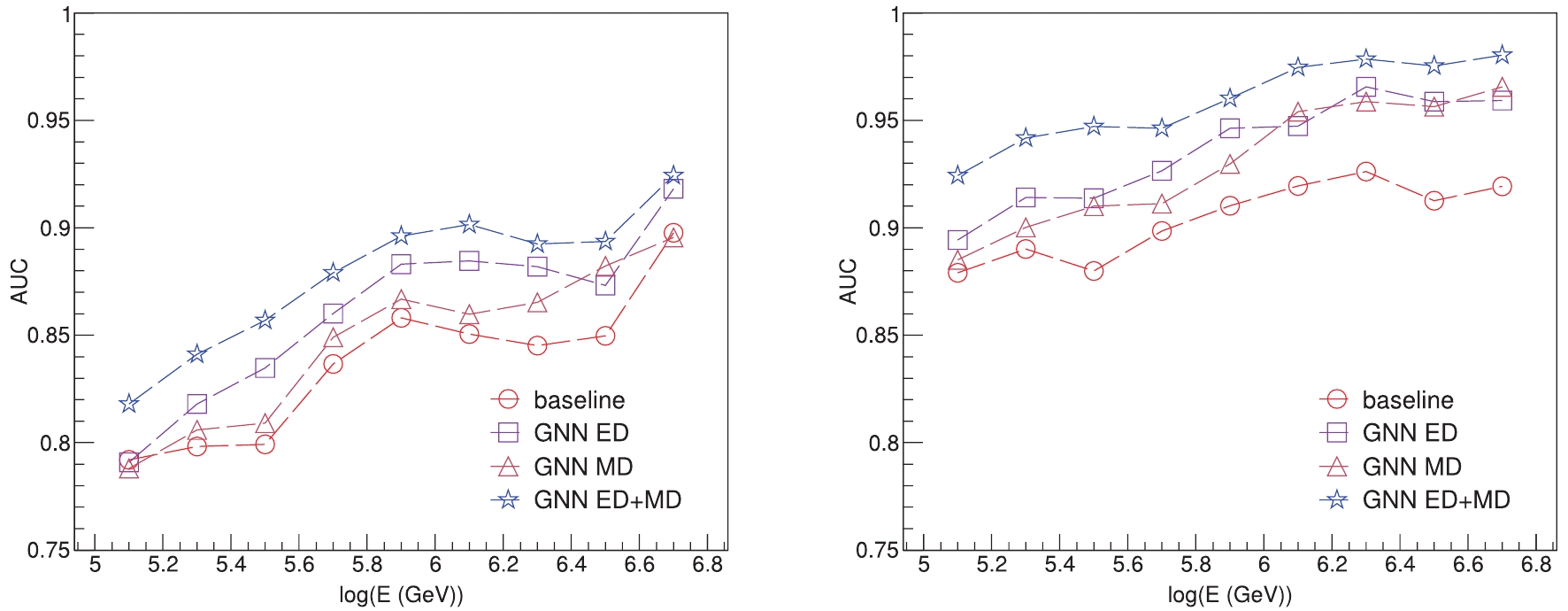 Figure8. (color online) AUC values across energy range from 100 TeV to 10 PeV from each model for P task (left) and L task (right).
Figure8. (color online) AUC values across energy range from 100 TeV to 10 PeV from each model for P task (left) and L task (right).With regard to the real measurement, the significant quantity extracted from the ROC curves is the purity, which is a criterion for subtracting background contamination [22]. The derived purities are shown in Table 3, which are under the same selection efficiency as the LHAASO hybrid detection methods [27,28], for comparison. Results demonstrate that the GNN method yields state-of-art performance among KM2A-only methods and performs comparably to the hybrid detection except for a slight deficiency in the P task. The hybrid detections, including making handcrafted features [27] and the gradient boosted decision tree (GBDT) [28], employ latent representations from WCDA, KM2A, and WFCTA in the LHAASO experiments under stricter selection criteria. This achieves high performance, but causes loss of significant statistics. We also show the apertures of KM2A-only and hybrid detection methods in Table 3. Aperture results are derived from the selection criteria. The KM2A-only methods can achieve an aperture 87ЁС larger than hybrid detections. Considering the WFCTA's strict observation condition with only ~ 10% duty cycle [27], the total statistics of the KM2A are expected to be the on the order of 870ЁС larger than the hybrid detection. We illustrate the expected observation with a one-day operation of the KM2A on the proton- and light-group spectra in Fig. 9, where the rigidity- and mass-dependent knee models are adopted from Refs. [21,47]. As demonstrated in Refs. [21,48], the spectral blur from the measurement maintains the spectral slope and knee position. Hence, the input spectra are adopted as the observation in Fig. 9, with emphasis on the statistical error bars.
| Purity (%) (+stat.+sys.) | Aperture (  | ||||
| P | L | P | L | ||
| handcraft (hybrid) [27] | ~90 | ~95 | ~1.5e3 | ~4e3 | |
| GBDT (hybrid) [28] | ~90 | ~97 | ~3.6e3 | ~7.2e3 | |
| baseline (KM2A) | 73.4ЁР2.5ЁР2.4 | 93.20.9ЁР1.1 | 3.2e5ЁР1.3e3ЁР1.0e4 | 6.3e5ЁР2.7e3ЁР7.6e3 | |
| CNN (KM2A) | 75.4ЁР2.5ЁР2.4 | 93.3ЁР0.9ЁР1.1 | 3.2e5ЁР1.3e3ЁР1.0e4 | 6.3e5ЁР2.7e3ЁР7.6e3 | |
| GNN MD (KM2A) | 77.1ЁР2.3ЁР2.5 | 95.9ЁР0.6ЁР1.2 | 3.2e5ЁР1.3e3ЁР1.0e4 | 6.3e5ЁР2.7e3ЁР7.6e3 | |
| GNN ED (KM2A) | 82.8ЁР1.9ЁР2.6 | 96.6ЁР0.6ЁР1.2 | 3.2e5ЁР1.3e3ЁР1.0e4 | 6.3e5ЁР2.7e3ЁР7.6e3 | |
| GNN ED+MD (KM2A) | 84 ЁР1.9ЁР2.7 | 98.2ЁР0.4ЁР1.2 | 3.2e5ЁР1.3e3ЁР1.0e4 | 6.3e5 ЁР2.7e3ЁР7.6e3 | |
Table3.Signal purity and aperture results of each model in LHAASO experiment
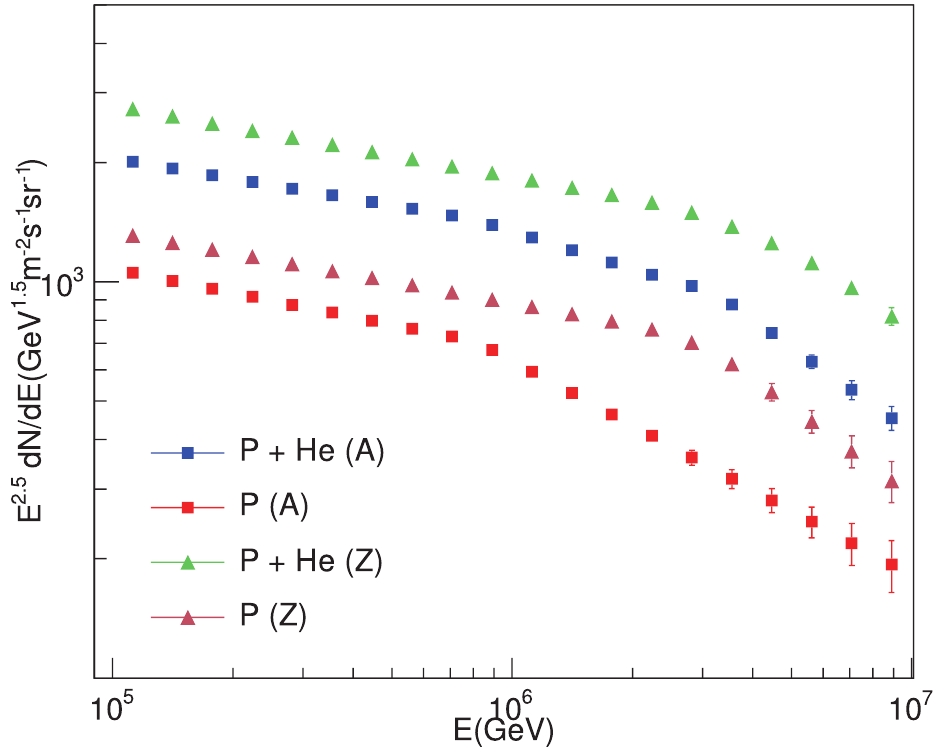 Figure9. (color online) Expectation on proton- and light-group spectra measured by LHAASO-KM2A with one-day observation. Triangular markers represent spectra predicted by one of the rigidity-dependent knee models (Z) [47], and square markers represent spectra predicted by one of the mass-dependent knee models (A) [21].
Figure9. (color online) Expectation on proton- and light-group spectra measured by LHAASO-KM2A with one-day observation. Triangular markers represent spectra predicted by one of the rigidity-dependent knee models (Z) [47], and square markers represent spectra predicted by one of the mass-dependent knee models (A) [21].We further construct a simple CNN model for comparison with the GNN model. The entire ED and MD arrays are rescaled into regular grids, with
To evaluate systematic errors, we further consider the influences from two aspects. The first contribution is the hadronic model, selected for generating the Monte Carlo simulation data. From the reasearch on the LHAASO-KM2A prototype array, this difference between the hadronic models (QGSJETII and EPOS) is roughly 5% with regard to the secondary particles [49]. Hence, we choose a variance of 5% on the recorded
We thank the LHAASO Collaboration for their support on this project.
