 , 谷人旭
, 谷人旭华东师范大学城市与区域科学学院,上海 200241
The geography of knowledge complexity and its influence in Chinese cities
ZHANGYiou, GURenxu通讯作者:
收稿日期:2017-11-29
修回日期:2018-06-1
网络出版日期:2018-08-15
版权声明:2018《地理学报》编辑部本文是开放获取期刊文献,在以下情况下可以自由使用:学术研究、学术交流、科研教学等,但不允许用于商业目的.
作者简介:
-->
展开
摘要
关键词:
Abstract
Keywords:
-->0
PDF (3647KB)元数据多维度评价相关文章收藏文章
本文引用格式导出EndNoteRisBibtex收藏本文-->
1 引言
知识生产和扩散的非均质性是区域增长差异的关键因素[1,2]。Romer认为技术进步是经济增长的内生变量[3],而知识是生产投入的关键因素之一。随着全球商品市场的不断融合,其在资本市场竞争中的核心地位也愈发显著[4]。尽管大量理论研究开始揭示学习型区域或知识型经济是如何产生的,但较少关注区域内的知识特性,其重要原因之一是缺乏对知识和技术的精确测度[5]。最近的研究致力于掌握不同区域知识的本质差异,Kogler等利用专利数据测度不同技术间的差异,并提供国家和本地知识格局及其演化的可视化表达[6];Boschma等通过技术遗弃模式的多样性来探究空间结构指导知识发展的本地路径[7]。虽然专利数量提供了表征企业和地区知识创新的指标,但竞争优势的另一重要维度,即知识的不可模仿性仍旧难以实证。近年来,越来越多的研究认为,一些知识比其他知识更加难以被发展或复制,知识的复杂性是其难以模仿的根本原因,对许多企业和工业化区域而言,竞争优势取决于大量的复杂和隐性知识[8,9],不同知识结构的复杂性影响其潜在的独占性和价值[10,11]。然而,已有技术进步相关的实证文献只提供简单的知识投入—产出系数关系而未估算知识的特性,即将所有知识视为同质的。少量文献虽对尖端和突破性专利的空间分布加以描述[12],并提供了一种测度个人专利复杂性的方法[13],但迄今为止,学界尚未掌握区域知识库复杂性的有效测度方法。Rigby等新近研究突破性地提出了知识复杂性指数(Knowledge Complex Index, KCI)的概念,揭示了某一城市生产的知识是否能在其他城市轻易地生产,或其是否足够成熟以至于只能在少部分中心城市发明;并认为知识复杂性越高,其空间粘性越强,越利于区域获取竞争优势[14]。在全球化迅速发展的今天,低复杂度知识的发展越来越自由,并不会为获取竞争优势提供稳定的基础。因此,城市如何提高其生产知识的复杂性是一个重要问题。
根据上述研究,本文对知识复杂性的测度基于这样的判断:一些知识比其他知识更加难以被发展或复制。只有少数城市和区域有能力生产复杂性知识,而且这些城市通常是经济增长的关键节点。知识的复杂性是区域获得竞争优势的重要指标。就其本质而言,这一概念侧重于知识的不可模仿性,揭示了某一区域生产的知识是否能在其他区域轻易地生产,或它是否足够成熟以至于只能在少部分中心区域生产。若很少有其他区域能够模仿其生产的知识,则该区域就拥有复杂的知识构成及竞争优势[10]。值得注意的是,知识复杂性指数并不仅是指隐性知识或新知识子集的多样性,而是用来反映不同区域生产不同类型知识的难度,既包含知识丰度的概念,也需测度某一技术知识是否拥有相对优势,是涵盖知识丰度与知识质量的综合概念,对区域获取竞争优势起到了重要作用。
综上,哪一区域拥有那些复杂、隐性、难以获取的知识?知识的复杂性又应如何测度?十分值得关注。Fleming等利用USPTO数据中整合不同技术领域知识的困难程度来测度个体专利复杂性,并提供了基于知识复杂性的创新模型[15]。Hidalgo等认为不同的国家发展不同的核心竞争力,而集聚更大能量的区域能生产出更加专业化的产品。这些复杂的产品只在少数经济体中生产,这正是这些经济体保持长期竞争优势的基础,并基于国家经济体的产品多样性和空间范围,发展了一个产品和区域复杂性的不同测度方法[10]。专利数据可为技术变革和经济增长提供最全面的测度指标[16]。虽然部分****对滥用专利数据提出批判,但大多数****仍然认为专利是表征区域创新的可靠指标,并借此证明区域知识基础与经济增长之间的正向联系[17]。因此,本文首先基于国家知识产权局的14349355条的专利数据和Hidalgo等的双峰网络模型[10],计算1986-2015年中国城市的知识复杂性,刻画其空间分异及演化特征,进而利用2000年和2010年的专利转移数据探索知识复杂性对知识流动的地理格局影响。
2 研究方法与数据来源
关于知识复杂性的核心分析方法是城市技术知识网络,它将城市与城市发展的技术知识联系在一起,构成双峰结构网络[18],并只显示不同类型主体间(即城市与技术)的联系。参考相关研究[10],尝试运用城市技术网络结构揭示城市生产复杂技术知识的能力(图1)。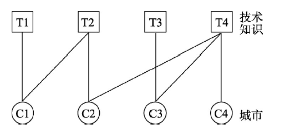 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图1城市—技术网络模型
-->Fig. 1The (two-node) city-tech network
-->
城市与技术之间的联系,是城市中发明者在特定技术领域中发展的新知识。专利数据提供不同技术领域在不同时空中的精确知识生产信息,这是双模网络构建的关键投入。由于专利申请日到公开日需要18个月,2015年12月之后的数据并不完全,因此本文提取数据的截止日期为2015年12月。由于中国第一个注册专利出现于1986年,为建构城市技术知识网络,选取1986-2015年中国知识产权局的专利数据,国外和港澳台地区的联合申请专利不在讨论范围。由于本文关注新知识生产的时间,因此利用申请年份来表征个人专利。在研究过程中发现,每个(授权)专利隶属于一个或多个不同的技术类,反映了新知识创造的技术特点。到2012年末,中国知识产权局划分了122类主要的专利① (资料来源:http://www.sipo.gov.cn/)。按照专利的主分类号进行划分,未将单个专利划分到不同的技术类别中,以确保每个专利具有相同的权重。专利数据还通过查阅发明人的地址提供知识生产场所的信息,本文只考虑专利的主要发明人居住在中国的数据。对合作研究而言,发明人基本集中在同一城市。综上,本文建立了一个n×k的双模矩阵代表技术知识生产的地理格局。网络结果包括n = 293个地级市和k = 122个技术类别。在n×k的矩阵中,每一个元素Xc,i代表c城市在i领域产生的专利数量(c =1,…, n;i =1,…, k)。将所拥有的专利数据划分为1986-1995年、1996-2005年和2006-2015年3个不同的阶段,在每一个阶段中构建城市—知识网络,以明确知识复杂性生产的时空演化过程。
Hidalgo等认为,越复杂的经济体越能够生产独特的产品。复杂经济结构的国家拥有竞争优势,而能被其他人广泛模仿和遍在性的产品越多,其经济复杂性就越低[10]。基于此,本文分析了城市技术知识网络结构,若很少有其他城市能够模仿其生产的知识,则该城市就拥有复杂技术构成。为建构知识复杂性指数,也仅考虑生产特定技术的重要城市。也就是说,用以计算知识复杂性指数(KCI)的城市技术知识网络是那些在专利活动中拥有相对技术优势(RTA)的技术分级。中国城市技术知识网络是一个n×k的双模矩阵M =(Mc,i)。Mc,i表示城市c在技术知识i中是否拥有相对技术优势。在时间t中,如果技术i占城市c所有技术组合的比例高于技术i占中国所有技术组合的比例,那么某城市c在技术知识i便拥有相对技术优势。数学表达式:要想使
KCI包含城市多样性和技术遍在性。这两个变量与城市技术知识网络中所有节点的度数中心性有关。城市的度数中心性(Kc,0)表示某个城市拥有相对技术优势的技术数量:
同样,技术的度数中心性(Ki,0)表示应用某项技术时拥有相对技术优势的城市数量:
Hidalgo等对城市和技术知识复杂性的测度可被经过n次迭代的多样性和遍在性的整合指标所表示[10],表达式为:
为进一步解释该方法,经过第二次迭代,在公式(3)中当n = 1时,Kc,i表示拥有相对技术优势的城市c的技术遍在性的平均值。同样,公式(4)中的Ki,1表示对技术i拥有相对技术优势的城市的平均多样性。在下一次迭代中,n = 2,Kc,2表示城市的平均多样性,Ki,2表示对技术i拥有相对技术优势的城市的平均遍在性。对公式(3)KCIcities的每次迭代都会产生对某城市的知识复杂性的细粒度估计,对公式(4)KCItech的每次迭代都会产生对某技术的知识复杂性的细粒度估计。尽管本方法的高阶迭代测度会变得越来越难,但可提供城市和技术的知识复杂指数(KCI)越来越精准的测度,噪声和尺度影响将被消除。当城市和技术的排名变得稳定时,迭代停止。在本文中,二元的n×k双模矩阵M是本方法的主要输入值。先对矩阵M进行行标准化,再对其转置矩阵MT进行行标准化。B = M×MT是对称矩阵,拥有与网络中城市数量相同的行和列(293)。矩阵B主对角线上的元素代表技术的平均遍在性。矩阵B的第二个特征向量代表每个城市的KCI。若D = MT×M,则矩阵D拥有122个行和列,与城市技术知识网络中技术子类的数量相同,那么矩阵D的第二个特征向量代表每个技术的KCI。
3 中国知识复杂性指数的空间特征
3.1 中国城市知识复杂性的整体分布及变化趋势
为研究中国城市技术知识网络的结构,依照Hidalgo等研究分析城市的技术多样性与这些技术的平均遍在性之间的关系[10]。图2展示了2006-2015年间中国城市技术多样性Kc,0与技术的平均遍在性Kc,1之间的关系。Kc,0的数值高表明城市生产更具根植性和非遍在性的技术。两个指标之间的负相关关系,表明拥有多样性技术结构的城市倾向于生产更加排斥或根植性的技术。通过绘制多样性的平均值(纵线)和平均遍在性的平均值(横线),可将散点图分为4块。在左下象限,发现在少数技术领域拥有RTA的城市,其技术是非遍在的。这些城市包括深圳、珠海、惠州等地,他们生产了一些最复杂的新技术。在左上象限,发现在少数技术领域拥有RTA的城市,其技术是相对遍在性的。在右下象限,规模更大、更多样化的城市(诸如北京、上海、广州、杭州等)生产遍在性较低的技术,右上象限的城市生产相对遍在性的技术。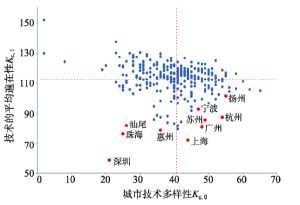 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图22006-2015年中国城市多样性和技术的平均遍在性
-->Fig. 2City diversity and average ubiquity of technologies produced in 2006-2015
-->
知识异质性作为创新地理学的前沿问题,近年来受到广泛关注。应用专利数据,将其总量和复杂性指数加以比较,有助于明确知识异质性的研究价值。表1列出了2006-2015年中国知识复杂性前10名的城市和其专利数量的排序。可看出KCI指数较高的城市通常也是专利数量较多的城市。实际上,通过史匹曼等级相关系数(Spearman rank correlation)发现,所有293个地级市的KCI和专利数量之间显著相关。但这一关系在进一步的排序中会失效。比如,沈阳在专利数量中排第25,KCI指数只列第147位,这说明沈阳市生产的知识能被其他城市轻易生产,中国东北部和中西部,以及在改革开放初期着重发展重工业的资源型城市都呈现类似情况(比如,贵阳市的KCI指数排名比专利数量排名落后了85位,大庆市落后了99位,东营市落后了212位)。还有一些城市KCI指数排名比专利数量排名高,比如惠州、珠海等城市,说明其生产更加复杂的专利。这一结果与Rigby的研究相吻合[14],即虽然知识质量和数量整体并重,但将知识视为同质的做法仍会出现偏差[19],因此对于知识复杂性的着重研究有助于明确中国的知识生产格局。
Tab. 1
表1
表12006-2015年中国城市知识复杂性指数排序
Tab. 1Knowledge complexity index of Chinese cities in 2006-2015
| 城市 | KCI | KCI排序 | 专利数量排序 | 城市 | KCI | KCI排序 | 专利数量排序 |
|---|---|---|---|---|---|---|---|
| 深圳市 | 100 | 1 | 3 | 武汉市 | 93 | 9 | 15 |
| 北京市 | 97 | 2 | 1 | 厦门市 | 92 | 10 | 13 |
| 上海市 | 97 | 3 | 2 | 沈阳市 | 65 | 147 | 25 |
| 广州市 | 96 | 4 | 5 | 贵阳市 | 69 | 136 | 51 |
| 成都市 | 95 | 5 | 8 | 东营市 | 32 | 274 | 58 |
| 杭州市 | 94 | 6 | 6 | 大庆市 | 58 | 180 | 81 |
| 苏州市 | 93 | 7 | 4 | 惠州市 | 85 | 12 | 50 |
| 南京市 | 93 | 8 | 10 | 珠海市 | 84 | 13 | 42 |
新窗口打开
通过上述多样性和技术遍在性平均值的计算和排序,可初步观察到中国知识生产空间格局的现象,且发现这一现象不能简单地用专利数量数据加以表征。但是,这些指标只表征了城市技术知识网络的整体格局的一小部分。由于城市会接纳新技术抛弃旧技术,利用演化视角探索中国城市技术知识网络的知识复杂性随时间的变化,更有利于获取全部信息。据此利用此前提到的方法,对比描绘1986-1995年和2006-2015年两个时间段中国293个地级市的知识结构复杂性(图3)。
 显示原图|下载原图ZIP|生成PPT
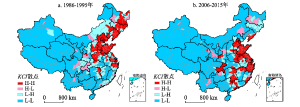
显示原图|下载原图ZIP|生成PPT图31986-1995年与2006-2015年中国城市KCI指数的空间格局对比
注:绘图所用的KCI数据均已标准化
-->Fig. 3Technological knowledge complexity in Chinese cities between 1986-1995 (a) and 2006-2015 (b)
-->
由图3可看出,1986-2015的30年中,中国城市KCI得分的空间分布明显集聚、且有“南下”趋势。1986-1995年间,受国家经济发展战略导向的影响,中国城市知识复杂性在东北老工业基地和环渤海地区等以重工业为主的资源型城市得分较高(KCI > 80),且中西部的一些省会或区域性中心城市,如成都、重庆、郑州、西安、武汉、长沙和兰州等的得分也均高于60。重化工业的快速发展带动了东北以及中西部一些资源型地区的整体开发。而2006-2015年中国KCI得分较高的城市主要分布在东部沿海地区,受多样化的产业结构和丰富的人力资本影响[20],这种格局与已有的研究结论[21]一致。以北京为中心的京津地区、以上海为中心的长三角地区和以深圳为中心的珠三角地区成为吸引创新活动的高地。得分较高的城市逐渐由东北、华北地区向三大都市圈转移,热点区域“南下”趋势明显。
为进一步明确中国城市知识复杂性的演化趋势,图4展示了中国城市知识复杂性在1986-1995年阶段到2006-2015年阶段的演变(图4a中的KCI指数已标准化)。从图4b可看出,高于45°平均线的城市不断改进其知识技术结构,而一些低于45°线的城市则经历了KCI指数的衰退。事实证明,大多数城市集聚在45°线附近,其KCI指数并未发生显著变化。这些数据表明某一城市的知识发展遵循现存知识和技术的重组累积过程,并进一步证明已有研究所指出的技术结构演化的空间格局的强路径依赖效应[22]。
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图41986-1995年至2006-2015年中国城市KCI变化
-->Fig. 4Changes in KCI in Chinese cities between 1986-1995 and 2006-2015
-->
3.2 中国城市知识复杂性的空间集聚特征
从图3和图4可看出,中国KCI得分的空间集聚态势明显,但为分析中国城市尺度KCI的空间格局尚需考察城际知识溢出的相互关联,而传统的统计分析往往忽视了空间数据属性值所隐含的空间依赖性[22,23]。随着GIS的发展,空间数据分析引起广泛关注,解决空间数据的方法日趋完善。ESDA(探索性空间数据分析)的全局和局部空间自相关方法越来越被认为是度量事物或现象之间空间关联或者依赖程度的有效方式[24]。其目的在于用空间统计的观点检验一个空间模式是否显著,进而对所研究的空间过程作深入的了解。其中,全局空间自相关表明事物或现象在总体空间上的平均关联程度;而局部空间自相关则进一步揭示事物或现象在局部空间位置上的关联程度及其分布格局。因此首先计算了1986-1995年和2006-2015年共20年的全局空间自相关系数(表2),以明确中国城市知识复杂性的空间集聚特征。结果显示,中国地级市层面历年KCI指数的Moran's I值均在1%的显著性水平下通过检验且不断上升,表明知识复杂性在中国地级市层面的空间相关性日益提升,呈现显著的集聚分布和自我强化的发展态势,这一现象与已有的中国区域创新发展的空间态势结论相符[22]。同时,这一现象也间接证明了本文的核心观点,即知识不可视为同质的,知识复杂度越高,其空间粘性越强,并难以在其他区域被复制。在此基础上,本文也对中国城市知识复杂性进行了局部空间自相关分析,以进一步明确KCI指数的空间分布态势。Tab. 2
表2
表21986-1995年和2006-2015年中国城市知识复杂性的Moran's I值
Tab. 2Moran's I of KCI in Chinese cities from 1986 to 2015
| 年份 | KCI | 年份 | KCI | ||
|---|---|---|---|---|---|
| Moran's I | Z | Moran's I | Z | ||
| 1986 | 0.263*** | 19.82 | 2006 | 0.257*** | 19.15 |
| 1987 | 0.266*** | 19.83 | 2007 | 0.260*** | 19.17 |
| 1988 | 0.274*** | 19.90 | 2008 | 0.262*** | 19.23 |
| 1989 | 0.277*** | 19.93 | 2009 | 0.268*** | 19.25 |
| 1990 | 0.281*** | 19.97 | 2010 | 0.272*** | 19.36 |
| 1991 | 0.285*** | 20.07 | 2011 | 0.279*** | 19.38 |
| 1992 | 0.286*** | 20.07 | 2012 | 0.279*** | 19.42 |
| 1993 | 0.287*** | 20.08 | 2013 | 0.282*** | 19.47 |
| 1994 | 0.287*** | 20.10 | 2014 | 0.283*** | 19.63 |
| 1995 | 0.291*** | 20.12 | 2015 | 0.285*** | 19.64 |
新窗口打开
图5~图7分别为中国地级市KCI指数散点图、集聚分布图和显著性分布图。结果显示,1986-1995年间,H-H型关联空间主要分布在以重工业和资源开发为主的东北地区和环渤海地区,这与当时的国家经济政策密切相关;H-L型关联空间在中部地区以及与中部相邻接的陕西、重庆、四川等区域虽偶有出现,但仅分散于成都、重庆、郑州、西安等区域中心城市,这些城市相对于周围城市具有较高的创新能力水平,但难以带动周边地区创新能力的提高,且不具有统计意义上的显著性。L-H型关联空间零散分布于东、中部少数城市,包括廊坊、嘉兴、泰州和莱芜等地,说明这些城市自身创新水平较差,受周围城市的影响较小。L-L型关联模式则大范围分布在经济相对落后的西部地区。至2006-2015年阶段,H-H型关联空间的分布呈明显的“南下”趋势,主要集中于长三角、环渤海和珠三角地区,由于这些区域中城市本身的知识生产能力较强,且核心城市周边相邻城市的创新水平也较高,因此成为了中国的“高效型”创新区域。值得注意的是,长三角地区的高高集聚区明显,说明该地区创新溢出的效应明显,空间联系较为紧密;H-L型关联空间的数量有所缩减,呈零散分布状态。由于东北老工业基地的衰落,部分省会城市(如哈尔滨)和原资源型城市呈现出高低型空间态势,成都、兰州等中西部中心城市的高低集聚特征仍十分明显。L-H型关联空间数量有所减少,如泰州,廊坊等地,说明随着时间推进,周围城市的创新带动效应有所增强,使得这些城市知识复杂性差距有所缩减。L-L型关联空间仍广泛分布于中西部城市,由于该类型城市的知识生产能力属于国内较低水平,且与周围城市的差异较小,因此呈连片团状分布,在中国西部形成了一片创新洼地。
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图51986-1995年与2006-2015年中国城市KCI散点图
-->Fig. 5Prefecture level of KCI scatter plot based on Moran's I in Chinese cities between 1986-1995 (a) and 2006-2015 (b)
-->
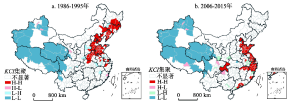 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图61986-1995年与2006-2015年中国城市KCI集聚分布
-->Fig. 6Prefecture level of KCI cluster profile based on Moran's I in Chinese cities between 1986-1995 (a) and 2006-2015 (b)
-->
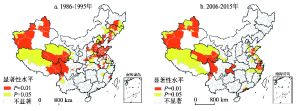 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图71986-1995年与2006-2015年中国城市KCI显著性分布
-->Fig. 7Prefecture-level of KCI significance based on Moran's I in 1986-1995 (a) and 2006-2015 (b)
-->
总之,中国城市知识复杂性的地域特征显著,具体表现为KCI得分较高的地区相对地趋于和KCI得分较高的区域临近,KCI得分较低的地区相对地趋于和KCI得分较低的地区相邻的空间结构。随着时间的不断推移,空间自相关和集聚特征不断强化,在一定程度上证明了区域知识溢出的空间局限性。
4 中国城市知识复杂性的影响分析
以上讨论凸显了中国城市知识复杂性的空间分布不均匀和动态变化过程。这也支持了经济地理学的核心观点:根植于工人、企业和特定区域情境之中的复杂性知识很难转移,只有少数作为经济增长关键节点的城市或区域有能力生产复杂性知识[8]。且知识复杂度越高,其空间粘性越强,难以在其他区域被创造或复制。因此,本文认为知识复杂性是使得知识产生空间粘性的因素之一,并在此部分遵循Sorenson的研究,探索知识复杂性对知识流动的影响。利用专利转移数据探讨知识复杂性如何影响其流动。虽然知识在经济主体之间的流动有多种渠道,专利转移数据无法全部衡量,但专利转移数据仍能代表不同地区之间创新能力差异的调整情况[25]。Hagedoorn等研究也表明,专利转移是衡量知识流动的重要方法[26]。表3是利用专利转移数据探究知识复杂性和知识流动的结果。受制于数据的可获得性,基于2000年和2010年所有的中国专利申请数据,将这两组专利分别与随后的2001-2005年和2011-2015年的专利相联系,即2000年与2001-2005年相联系,2010年与2011-2015年相联系,主要考虑到一个5年的窗口足以捕捉大多数专利转移信息。2000年国家知识产权局共授权49691项有效专利,其中1137项专利发生了专利权转让,且有1126次专利转让发生在2001-2005年间,这些转移专利组成了2000年专利转移的焦点专利组。因此,2000年就有包含1126项专利转移的观测组以及包含48554项未转移专利的控制组,这一过程也同样适用于2010年。本文将专利转移数据作为知识流动的表征指标,建立如下模型:
式中:Transfer = 1表示专利i被转移,反之为0。本模型包含指标焦点专利i转移前所在城市的知识复杂性,由于复杂性知识十分重要且难以测度,对β1不做特定预期;Distance为距离指标,若专利转移前后位于同一城市则Distance = 0,反之为1。本文认为地理距离越近,越容易转移(β2 < 0)。另一重要指标是复杂性和地理距离的乘积项。β3 = 0表示地理距离对复杂知识的流动无影响。根据此前对复杂知识地理空间的讨论和描述,在此假设两者存在负相关,即复杂知识难以转移。其中的协变量包括实验组中专利转移前后的年数。并利用线性概率模型(LPM)和Logit模型进行计算。表3表明两者结果类似。本文利用Firth逻辑回归模型进行进一步检验,发现结果与表3相同。
Tab. 3
表3
表3专利转移与知识复杂性的回归分析
Tab. 3Estimation results of knowledge complexity and knowledge flow based on Linear Probability Model
| 自变量 | 模型1(LPM) | 模型2(LPM) | 模型3(LPM) | 模型4(logit) |
|---|---|---|---|---|
| Knowledge Complexity | -- | 0.00004*** | 0.00127*** | 0.0114*** |
| Distance | -0.1069*** | -0.1072*** | -0.0179*** | -0.5279*** |
| Complexity×Distance | -- | -- | -0.00132*** | -0.0122*** |
| Time lag | 0.0102*** | 0.0113*** | 0.0112*** | 0.2524*** |
| 常数项 | 0.0806*** | 0.0806*** | 0.0806*** | -2.7667*** |
| R2 | 0.4542 | 0.4542 | 0.4543 | 0.3876 |
新窗口打开
在表3所有模型中,由于自变量恒定不变,因此LPM模型中的常数项(constant)反映知识流动的预期可能性,截距与因变量的平均值相等(β0 = 0.0806)。模型1展示了一个基础模型。包含地理距离和时间滞后项。与设想的一样,地理距离的相关性呈显著负相关,时间滞后呈显著正相关。模型2加入知识复杂性,其影响是显著正相关,但经济影响接近于0。事实上,知识复杂性增加10倍,知识流动可能性增加0.4%。模型3加入知识复杂性和地理距离的交互项,以探索不同复杂性知识转移的可能性如何随着距离变化而变化。结果表明,当潜在发明者不在焦点专利所在的城市时,焦点专利(知识复杂性强)被转移的可能性降低。这一结果进一步证明本文“距离限制复杂知识扩散”的论断。在此模型中,知识复杂性的相关系数表明当专利转移前后处于同一城市时,知识复杂性才有所影响。如结果所示,影响呈显著正相关的,但经济影响比之前的模型更强。即知识复杂性增加10倍,知识流动可能性增加12%;而处于不同城市时,复杂性的增加不会增加转移的可能性。这些结果表明地理邻近在复杂知识扩散中扮演重要角色,也进一步显示出复杂知识生产的空间不均衡分布的重要意义。
5 结论
随着创新驱动发展战略的实施,知识对于各城市竞争优势的获取变得日益重要。以往的研究利用专利数据探讨了城市技术创新能力的空间结构及演化特征,但大多将专利视为同质,即假设所有专利在提高区域经济竞争优势方面具有相同的技术潜力。最近研究利用专利数据测量不同类别专利之间的技术关联,发现不同国家和地区间的知识核心有所不同,因此并不是所有的专利都持有相同的价值。本文首先探讨了复杂知识在经济地理学中的作用,并利用双模网络模型和空间相关系数描述了中国城市知识复杂性的空间分布及演化特征,最后利用线性概率模型(LPM)证明了复杂知识的空间粘性。研究发现,中国城市的知识复杂性地域特征显著。首先表现为全局上的地理集聚特征和地带间的巨大差异。整体而言,知识复杂性在地级空间尺度上呈2个主要的空间集群,即东部沿海的H-H型集群和西部内陆的L-L型集群。从知识复杂性的演化方面来说,许多城市的排序存在相当大的稳定性。1986-2015年间,东部H-H型集群在考察期内由东北、华北地区逐渐向山东半岛、长三角和珠三角地区转移,知识复杂性在东北地区普遍衰退,在三大都市圈普遍增加;而西部L-L型集群的空间发展相对稳定。尤其在2006-2015年10年间,知识复杂性得分较高的城市主要集聚在沿海地区和内陆少数区域性中心城市,以北京、上海和深圳为中心的区域是中国知识生产的热点区。
第二个发现是,知识复杂性的增强会导致地理流动性的减弱。知识复杂度越高,其空间粘性越强,难以在其他区域被复制。通过专利转移数据可说明,低复杂度、程序化的知识更容易移动。在全球化迅速推进的时代,低复杂度知识的发展越来越自由,并不会为获取竞争优势提供稳定的基础。为此,鼓励区域在已有知识领域建立新的比较优势显得尤为重要。知识复杂性的应用为该框架的建立引入了一个新的层面。创新政策不仅要支持潜在专业领域的发展,还应鼓励相关地区开发比其现有产品更复杂的技术。这需要增加研究和教育经费,或在特定的科学和技术领域增加战略投资。从长远来看,将区域知识结构从低复杂度转化为高复杂度将有助于地区重塑自身优势,提升技术水平,并使它们摆脱孱弱的全球竞争局势。
虽然本文证明了区域的知识复杂性提高有利于竞争优势的获取,但城市或区域如何提高其知识核心的复杂性仍是一个重要问题。因此,后续研究中将深入探索知识复杂性的影响因素,为城市或区域发展提供更有针对性的对策建议。
The authors have declared that no competing interests exist.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}