中科院地质与地球物理研究所田恒次博士后与合作导师杨蔚研究员以及美国华盛顿大学滕方振教授、陈欣阳博士,中国地质科学院地质研究所侯增谦院士、宋玉财研究员,东华理工大学田世洪研究员等联合对西藏羌塘北部的多彩玛和那日尼亚两套火山岩开展了Sr-Nd-Mg-Li同位素和锆石U-Pb年龄研究。结果表明,多彩玛高钾钙碱性粗安岩形成于35 Ma左右,富集稀土元素和大离子亲石元素,具有低的δ26Mg(-0.41‰~-0.33‰)和δ7Li(+1.0‰~+2.6‰)值。结合其高的87Sr/86Sr(i)(0.7066~0.7067)和低εNd (t)(-1.96~-1.61)特征,多彩玛粗安岩最有可能来源于受含碳酸盐岩沉积物来源熔体交代的岩石圈地幔(图1)。模型计算表明其源区加入的沉积物量<10%。相比之下,同期的那日尼亚埃达克质粗面岩(38Ma)具有高的δ26Mg(-0.13‰~-0.02‰)和δ7Li(+3.3‰~+5.4‰)值,以及高Pb/Ce和Ba/La比值,这最有可能来源于受洋壳来源流体交代的加厚下地壳(图1)。根据研究区多彩玛和那日尼亚的时空关系以及熔流体交代的特征,我们认为青藏高原中部在晚始新世仍存在洋壳残余板片,这一结果不同于前人认为洋壳已经消亡的观点。洋壳残留板片的存在,表明松潘-甘孜俯冲板片俯冲速率要比之前认为的低。这一最新研究支持最近的利用孢粉、植物化石等记录来推断青藏高原隆升高度的研究,认为青藏高原中部在始新世的隆升高度比之前认为的低。
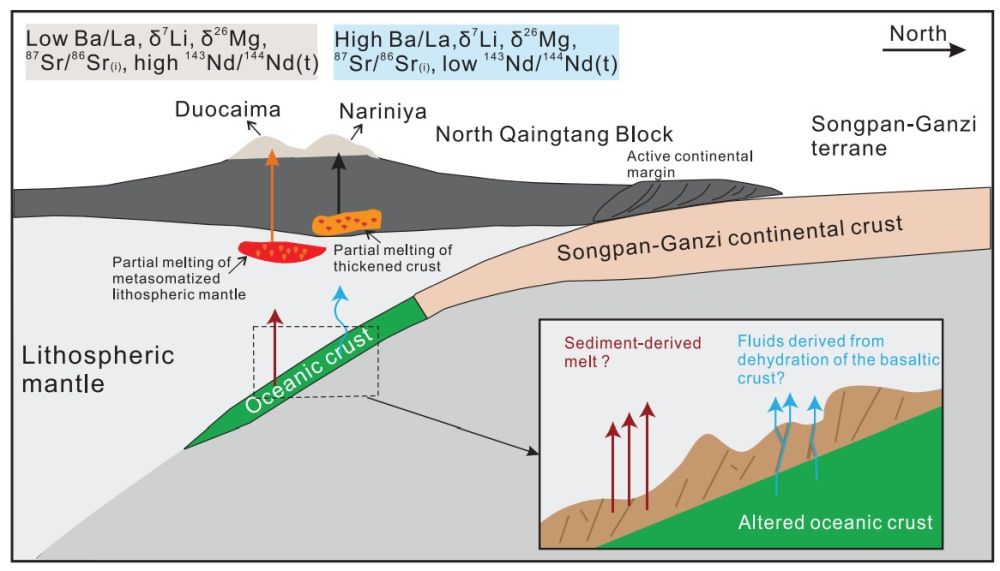
图1 青藏高原北部晚始新世洋壳俯冲示意图以及本文研究那日尼亚和多彩玛火山岩所在位置
研究成果发表于国际权威学术期刊JGR-Solid Earth。(Tian Heng-Ci*, Teng Fang-Zhen, Hou Zeng-Qian, Tian Shi-Hong*, Yang Wei, Chen Xin-Yang, Song Yu-Cai. Magnesium and lithium isotopic evidence for a remnant oceanic slab beneath central Tibet[J]. Journal of Geophysical Research: Solid Earth, 2020, 125(1): e2019JB018197. DOI: 10.1029/2019JB018197)(原文链接)。该成果受国家自然科学基金委、国家留学基金委和中国地质科学院项目资助。
