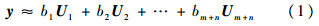
其中,b=[b1,b2,…,bm+n]T∈R(m+n)×1,为线性表示的系数.b是弱稀疏的,利用这一特征通过L2范数最小化进行求解,其中λ为约束参数.
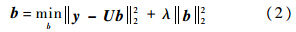
L2范数约束项的作用有2个:①它使解b具有一定的稀疏度,但是L2范数的稀疏度远低于L1范数的稀疏度.②它使得最小化的解更加稳定.L2范数最小化很容易求解,令||UTb-y||22+λ||b||22的导数为0,即
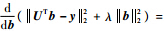
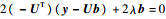 ,可得出:
,可得出: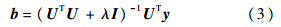
其中I∈Rd×d,是一个单位矩阵,用来确保UTU+λI的可逆性.令P=(UTU+λI)-1UT,很显然,P是独立于y的,所以对于通过粒子滤波得到的候选样本只需要计算一次P.如果把所有的候选样本看作一个向量集Y,则所有候选样本的表观系数可以一次性求得:

假设一个候选样本在前景模板上有比较小的重构误差就代表该候选样本有可能是目标,在背景模板上有比较小的重构误差就代表这个候选样本有可能是背景,在此基础上根据候选样本在前景模板和背景模板上的重构误差的差异来构造候选样本的置信值:
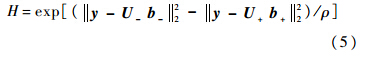
其中ρ是一个很小的固定的常数,用来权衡判别分类器的重要性.1.2 基于L2范数最小化的生成式模型本文在考虑图像块的位置信息和遮挡因素的基础上,提出了一种生成式模型.对于所有的候选样本利用分块的方法形成N个图像块,如图 1所示.本文在实验部分将每个图像块变成一个向量Yi∈Rd×1,表示图像块的大小.利用L2范数最小化来求解每个图像块的系数向量:
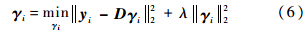
其中,D∈Rp×q,为通过k均值聚类的方法得到的字典;q为聚类中心的个数;P为聚类中心的维数.聚类的图像块是在第一帧中通过与yi相同的方法得到的,其中q个聚类中心表示最具有代表性的图像块.把所有的系数向量γi串联在一起得到γ:
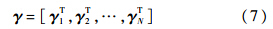
其中,γ∈R(q×N)×1,为一个候选样本的系数向量.通过这种串联方式,系数向量就包含了图像块的空间信息.
 |
| 图 1 利用分块得到的图像块Fig. 1 Image blocks by the sliding window |
| 图选项 |
对于遮挡问题,被遮挡的图像块会影响系数向量的比较,因为遮挡部分和模板之间存在很大的差异,这会使得误差大于候选样本本身的误差,所以本文通过设定一个阈值来判断图像块是否被遮挡.当重构误差比较大时,认为该图像块被遮挡,把这个图像块的权重设为0;当重构误差比较小时,认为图像块没有被遮挡,把这个图像块的权重设为1.通过去除被遮挡的图像块,只对有价值的目标块比较系数向量,可以避免错误的跟踪结果.这可以通过下式来描述:
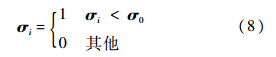
其中,σi=||yi-Dγi||22表示图像块yi的重构误差;σ0是一个阈值.加权之后的系数向量为

其中,σ为系数向量中每个元素的权重,根据σi的值将第i个系数向量的所有元素的权重全部设为0或1.通过比较候选样本系数向量和模板系数向量的相似性,得出置信值G:
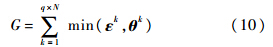
其中,ε,θ分别为候选样本和模板归一化到(0,1]的系数向量;G为候选样本和模板的相似度,其中初始时模板的系数向量是在第一帧中通过和候选样本系数向量一样的方法求得.1.3 联合模型在粒子滤波的框架下,本文融合判别式模型和生成式模型构造了一个新的联合模型,用乘法机制得到一个新的似然函数表达式:

这一似然函数既能够区分前景和背景,也能够处理目标遮挡问题.将本节的表观模型和后文的运动模型结合起来,得到了一个高效、鲁棒的跟踪器.2 基于L2范数最小化的跟踪算法目标跟踪问题可以看成是运动目标的状态推断问题.在贝叶斯理论的框架下,利用状态的先验概率和观测量,构造状态的后验概率密度:
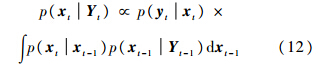
其中,p(xt | xt-1)为目标在连续帧之间的运动模型;p(yt | xt)为在xt状态下对观测量yt进行估计的观测模型.通过最大化后验概率得到此时的目标运动状态:
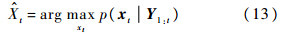
2.1 目标运动模型运动模型是用来描述目标在连续帧之间的运动状态的改变,本文采用帧间的几何变换的Xt=(αt,βt,θt,st,εt,
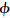 t)来近似表示t时刻目标的运动状态,其中αt,βt,θt,st,εt,t分别表示α方向的平移、β方向的平移、旋转角、尺度变化、宽高比和斜切角.根据随机游走模型来描述目标的运动状态,即当前时刻的目标运动状态以上一时刻的状态为中心呈多元正态分布:
t)来近似表示t时刻目标的运动状态,其中αt,βt,θt,st,εt,t分别表示α方向的平移、β方向的平移、旋转角、尺度变化、宽高比和斜切角.根据随机游走模型来描述目标的运动状态,即当前时刻的目标运动状态以上一时刻的状态为中心呈多元正态分布: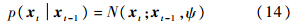
其中,ψ为一个对角阵,对角线上元素分别是σx2,σy2,σθ2,σs2,σε2,σ
2,为各仿射参数的方差.这组参数是在当前帧中获得的一组候选样本.2.2 目标观测模型观测模型的目的则是从运动模型得到的大量候选样本中找到要跟踪的目标.给定粒子xti,当前时刻的观测量yti,结合基于L2范数最小化的目标表观模型,可以得到观测似然函数:
2.3 模型更新策略在跟踪过程中,目标的表观不断发生变化,所以适时地更新判别式模型中的正负模板是非常必要的.本文每隔若干帧更新正模板和负模板,更新的图像是当前跟踪结果附近的区域,正负模板的获得方法和2.1节中的方法一样.这样得到的模板使得判别式模型具有很强的适应性和辨别度.对于生成式模型中的模板的系数向量,按照下式进行更新:
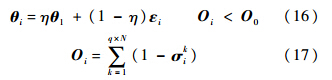
其中,η为更新率;θ1为第一帧的系数向量;εi为最新一帧得到的系数向量.当遮挡程度Oi小于设定的阈值O0时,进行更新,反之则不进行更新.这种更新机制考虑了遮挡的同时又更新了目标的表观模型,跟踪器能够适应新的环境和新的目标状态.总体流程如图 2所示.
 |
| 图 2 总体流程图Fig. 2 Overall flow chart |
| 图选项 |
3 实验结果与分析本文提出的跟踪方法采用Matlab进行了实现,并且与Frag[20],VTD[21],IVT[9],MIL[7]这4种经典的算法以及L2RLS[19]跟踪算法进行了比较,在8个具有挑战性的测试序列[1, 22]中对比实验,并作了定性和定量的分析.实验过程中,判别式模型中正负模板的个数分别设置为70和250;式(2)和式(6)中的λ分别设置为0.001和0.005;式(6)中字典D行数和列数分别设置为25和40;式(8)中的阈值σ0设置为0.03;式(16)中的更新率η和阈值O0分别设为0.9和0.8.3.1 定性评估第1个测试序列cardark如图 3(a)所示,存在着前景背景的对比度低、较大的光照变化等干扰,同时目标相对于整个图像的尺寸是比较小的.Frag跟踪器一直不稳定,在跟踪过程中出现了不同程度的漂移,这是因为Frag跟踪器基于局部信息,没有维持全局信息.因此,当目标尺度很小且分辨率很低时,很难进行跟踪.MIL算法在跟踪开始没多久就开始发生漂移直至跟踪失败.在260帧之前,IVT算法、VTD算法、L2RLS算法和本文算法都能够跟踪到目标,但之后IVT跟踪结果的矩形框不断变大,无法对准目标,L2RLS算法和VTD算法很快就丢失了目标.本文算法在整个图像序列中都能够比较好地进行跟踪,是因为基于判别式模型的跟踪器能够很好地区分前景和背景,再通过更新机制获得最新的正负样本构成正负样本集,这有助于在变化着的凌乱的场景中区分出前景和背景.第2个测试序列mhyang如图 3(b)所示,存在着光照变化、运动模糊并伴随着尺度变化等干扰.MIL算法由于没有考虑尺度变化,跟踪结果在第369帧时就开始发生漂移.在第420帧受到光照干扰时,L2RLS算法的跟踪框越来越小,逐渐丢失目标.VTD算法在整个序列中的跟踪结果不够稳定,有时出现漂移但后来又会跟踪上目标.IVT算法能够比较好地跟踪到目标,因为子空间的方法对光照和小姿态的变化具有很好的鲁棒性.本文的跟踪器能够在对比度比较低的情况下保持良好的跟踪性能,这要归功于本文的判决模型具有有利于区分前景和背景的特征.
 |
| 图 3 不同算法在不同测试序列上的跟踪结果Fig. 3 Tracking results with different algorithms on different videos |
| 图选项 |
第3个测试序列crossing如图 3(c)所示,存在着部分遮挡、运动模糊和背景复杂等干扰,给跟踪带来了困难.IVT算法和L2RLS算法在第47帧时跟踪框开始缩小直至跟踪失败.Frag算法和VTD算法在跟踪几十帧以后开始丢失目标.MIL跟踪器在测试序列中能够跟踪到目标,但是跟踪的精度没有本文的跟踪器高.本文的算法能够成功地对目标进行跟踪,主要原因是本文的判决模型具有判别力特征,该特征能够将目标从背景中区分开,即使在目标模糊的状态下,也能够准确定位到目标.第4个测试序列jogging-2如图 3(d)所示,奔跑中的目标经历了非刚性的形变、严重遮挡和运动模糊等干扰.除了本文的跟踪器和L2RLS跟踪器,其他跟踪器在第49帧之后由于严重的遮挡丢失了目标.随着跟踪的不断进行,L2RLS跟踪器表现得不稳定,出现了短暂的漂移现象.本文的算法在整个图像序列中都能够较好地进行跟踪,是因为基于判别式模型的跟踪器可以通过遮挡处理机制估计可能被遮挡的图像块,形成一个鲁棒的只含没有遮挡的图像块的系数向量,从而避免了遮挡的影响,再通过更新机制获得最新的正负样本集,这有助于在变化着的场景中区分出前景和背景.第5个测试序列freeman3如图 3(e)所示,目标的快速移动引起了遮挡、尺度变化和旋转等干扰.MIL算法无法处理尺度变化和旋转问题,在跟踪的前几帧就丢失了目标.在第300帧时,Frag跟踪器不能克服跟踪目标头部大角度旋转导致的严重遮挡,跟踪失败,IVT算法、VTD算法和L2RLS算法也开始发生漂移,目标框越来越小直至完全丢失目标.本文的跟踪算法由于将背景候选赋予比较小的权重,所以当目标旋转时,跟踪结果不会漂移到背景中,且本文的跟踪器能够自适应地调整跟踪框的大小,在整个序列中稳定地跟踪到目标.第6个测试序列singer2如图 3(f)所示,存在着光照变化、尺度变化、遮挡、非刚性变形、运动模糊和背景混杂等诸多干扰.除了本文的跟踪器和VTD跟踪器,其他跟踪器在第56帧之后都丢失了目标.这是因为对于大部分基于模板的跟踪器而言,简单地利用跟踪结果更新模板集通常会导致漂移.本文的跟踪器能够在整个视频中保持良好的跟踪性能,这要归功于本文的跟踪器在基于维持全局特征模板的基础上,运用判决模型从凌乱的背景中区分出前景.第7个测试序列emilio如图 3(g)所示,目标移动过程中存在着尺度变化,光照变化和旋转等干扰.MIL算法不能处理尺度变化和旋转问题,很快丢失了目标.在第142帧时,IVT算法、VTD算法和L2RLS算法开始发生漂移直至完全丢失目标.本文的跟踪器能够自适应地调整跟踪框的大小,在整个序列中稳定地跟踪到目标.第8个测试序列toni如图 3(h)所示,存在尺度变化和旋转等干扰.MIL算法无法旋转问题,在跟踪的前几帧就丢失了目标.在第224帧时,Frag跟踪器由于不能克服跟踪目标头部大角度旋转导致的严重遮挡跟踪失败,IVT算法、VTD算法和L2RLS算法也发生漂移.而本文的跟踪算法在目标旋转时,跟踪结果不会漂移到背景中,在整个序列都能跟踪到目标.3.2定量评估为了进一步分析本文算法的性能,分别在前6个视频序列上绘制了中心点误差曲线和重叠率曲线.中心点位置误差是指某帧跟踪结果的中心位置与该帧目标的标准中心位置之间的误差;重叠率的计算方法是overlap rate=area(Rt ∩ Rg)/area(Rt ∪ Rg),其中,Rt为某帧跟踪框覆盖的区域;Rg为该帧目标所在的真实区域.针对不同测试视频的跟踪误差曲线结果对比和重叠率曲线结果对比如图 4和图 5所示,从中可见,本节提出的基于L2范数的联合模型的目标跟踪算法比其他算法具有更加鲁棒的跟踪效果.
 |
| 图 4 针对不同的测试视频的跟踪误差曲线结果对比Fig. 4 Tracking error curve result according to different test videos |
| 图选项 |
 |
| 图 5 针对不同的测试视频的重叠率曲线结果对比Fig. 5 Overlap rate curve result according to different test videos |
| 图选项 |
4 结 论在大量的实验序列中,本文算法与4种先进的跟踪算法以及L2正则化的跟踪算法作比较,得出以下结论:①本文算法融合了基于全局模板的判别分类器和基于局部描述子的生成式模型,具有较强的鲁棒性.②本文采用的遮挡处理机制能够有效地处理遮挡.③本文的模型更新机制使模型具有适应性和辨别性.
参考文献
| [1] | Wu Y, Lim J,Yang M H.Online object tracking:a benchmark[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington,DC:IEEE Computer Society,2013:2411-2418. |
| Click to display the text | |
| [2] | 邵文坤,黄爱民, 韦庆.目标跟踪方法综述[J].影像技术,2006(1):17-20. Shao W K,Huang A M,Wei Q.Target tracking method review[J].Image Technology,2006(1):17-20(in Chinese). |
| Cited By in Cnki (121) | |
| [3] | Zhong W, Lu H,Yang M H.Robust object tracking via sparsity-based collaborative model[C]//Proc IEEE Comput Soc Conf Comput Vision Pattern Recognition.Washington,DC:IEEE Computer Society,2012:1838-1845. |
| Click to display the text | |
| [4] | 沈丁成,薛彦兵, 张桦,等.一种鲁棒的基于在线boosting目标跟踪算法研究[J].光电子·激光,2013,24(11):30. Shen D C,Xue Y B,Zhang H,et al.A robust online boosting target tracking algorithm based on the research[J].Journal of Photoelectron·Laser,2013,24(11):30(in Chinese). |
| Cited By in Cnki (4) | |
| [5] | Grabner H, Grabner M,Bischof H.Real-time tracking via on-line boosting[C]//BMVC 2006-Proceedings of the British Machine Vision Conference 2006.Edinburgh:British Machine Vision Association,2006:47-56. |
| Click to display the text | |
| [6] | 张颖颖,王红娟, 黄义定.基于在线多实例学习的跟踪研究[J].南阳师范学院学报,2012,10(12):35-37. Zhang Y Y,Wang H J,Huang Y D.Based on multiple instance learning online tracking study[J].Journal of Nanyang Normal University,2012,10(12):35-37(in Chinese). |
| Cited By in Cnki (1) | |
| [7] | Babenko B, Belongie S,Yang M H.Visual tracking with online multiple instance learning[C]//2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Computer Society,2009:983-990. |
| Click to display the text | |
| [8] | Avidan S. Ensemble tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(2):261-271. |
| Click to display the text | |
| [9] | Ross D, Lim J,Lin R S,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1):125-141. |
| Click to display the text | |
| [10] | 齐飞,罗予频, 胡东成.基于均值漂移的视觉目标跟踪方法综述[J].计算机工程,2007,33(21):24-27. Qi F,Luo Y P,Hu D C.Visual target tracking method based on mean shift review[J].Computer Engineering,2007,33(21):24-27(in Chinese). |
| Cited By in Cnki (43) | |
| [11] | Black M,Jepson A. Eigentracking:robust maching and tracking of articulated objects using a view based representation[J].International Journal of Computer Vision,1998,26(1):63-84. |
| Click to display the text | |
| [12] | Yang A Y, Sastry S S,Ganesh A,et al.Fast 1 -minimization algorithms and an application in robust face recognition:a review[C]//Image Processing.Hong Kong:IEEE,2010:1849-1852. |
| [13] | Wright J, Yang A Y,Ganesh A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227. |
| Click to display the text | |
| [14] | Mei X, Ling H.Robust visual tracking using L1 minimization[C]//Computer Vision.Anchorage,Alaska:IEEE,2009:1436-1443. |
| Click to display the text | |
| [15] | Mei X, Ling H,Wu Y,et al.Minimum error bounded efficientl1 tracker with occlusion detection[C]//Computer Vision and Pattern Recognition.Colorado Springs:IEEE,2011:1257-1264. |
| Click to display the text | |
| [16] | Bao C L, Wu Y,Ling H,et al.Real time robust l1 tracker using accelerated proximal gradient approach[C]//Proc IEEE Comput Soc Conf Comput Vision Pattern Recognition.Washington,DC:IEEE Computer Society,2012:1830-1837. |
| Click to display the text | |
| [17] | Zhang T Z, Ghanem B,Liu S,et al.Robust visual tracking via multi-task sparse learning[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington,DC:IEEE Computer Society,2012:2042-2049. |
| Click to display the text | |
| [18] | Zhang D, Yang M,Feng X.Sparse representation or collaborative representation:which helps face recognition?[C]//Computer Vision,2011:471-478. |
| Click to display the text | |
| [19] | Xiao Z Y, Lu H,Wang D.Object tracking with L2-RLS[C]//Proceedings-International Conference on Pattern Recognition.Piscataway,NJ:Institute of Electrical and Electronics Engineers Inc,2012:1351-1354. |
| Click to display the text | |
| [20] | Adam A, Rivlin E,Shimshoni I.Robust fragments-based tracking using the integral histogram[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York:Electronics Engineers Computer Society,2006:798-805. |
| Click to display the text | |
| [21] | Kwon J, Lee K M.Visual tracking decomposition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Computer Society,2010:1269-1276. |
| Click to display the text | |
| [22] | Maggio E, Cavallaro A.Hybrid particle filter and mean shift tracker with adaptive transition model[C]//ICASSP,IEEE International Conference on Acoustics,Speech and Signal Processing-Proceedings.Philadelphia,PA:Institute of Electrical and Electronics Engineers Inc,2005:221-224. |
| Click to display the text |
