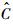 ��.
��. 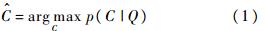
�������C���Ӿ��ȷֲ�,����ݱ�Ҷ˹��ʽ,��������ʵȼ��������Ȼ����.ʽ(1)���Ը�дΪ
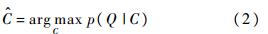
ͼ��Q�����������ӷֱ��Ϊd1,d2,��,dn,����di���϶���ͬ�ֲ�,��
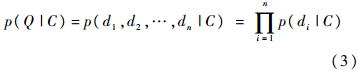
��ʽ(3)ȡ��������(��������1),�����������:
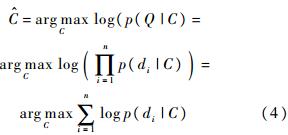
p(di|C)����ͨ��Parzen���˺������й���:
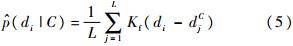
ʽ��,d1C,d2C,��,dLCΪ���C������ѵ��ͼ���е�����������,LΪ���������ӵĸ���;KfΪ��˹�˺���,��ֵ�Ǹ����Һ�Ϊ1����ʽ(6)��ʾ.����L��������,�����ij߶Ȳ�������С,
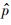 (di|C)��������p(di|C)����ʵ�ֲ�.
(di|C)��������p(di|C)����ʵ�ֲ�. 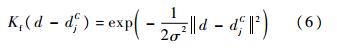
������������ʵ����ر�Ҷ˹��������Ҫ����ÿ������d�����C�еĸ��ʷֲ�,��Ȼ���Բ���Parzen�����й���,���Ǵ�ÿ��ͼ������ȡ�ľֲ�����������,�ر���Ϊ�˻�ø��ߵ�ȷ��,��Ҫ�����ܶ��djC�����C������ͼ��ľֲ�����,������Ҫ����d��djC֮��ľ���,����㷨��ʱ�临�ӶȽϸ�.���������ֲ�������,�����ռ��д��������ܸߵ�������Թ���,���C�ڸ�ͼ��ֲ������ķֲ��������.�������d��djC֮����������,ʽ(5)�д�Kf(di��djC)���ǿ��Ժ��Ե�,��С������(����d�����㹻������һ����)����������.���,ֻ�����Kf(di��djC)ǰK�d�����C�е�K���������,ʽ(5)��дΪ
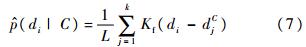
ԭʼNBNN�㷨��ȡKΪ1,���Լ���ͼ���е����������C��Ѱ������������ڷ������,ʵ��ȡ�ò����ķ�������. 3 ���ر�Ҷ˹K���ڷ���NBNN�㷨����Ч���������ܺ�,���Ҳ���Ҫ����ѵ��ѧϰ�Ĺ���,�����˲���ѧϰ�ȴ������������.���㷨�����ٶȽ���������������ڽ��з���ʶ��,�ⷽ��������BoVWģ���е�Ӳ��ֵ���뷽ʽ,����ȡ���˲����ķ���Ч��,��û�г����������������������Ϣ.���NBNN�㷨��ԭ��������ֵ�����˼��,�������һ�����ر�Ҷ˹K���ڷ����㷨��ΪNBKNN�㷨,���������������������K������Ϣ��ȥ��������Ϣ�Է������ܵ�Ӱ��,�㷨����FLANN[21]��������K����,����˸�ά�������ڵ������ٶ�.��������ͼ��Q�Լ�ѵ��ͼ���,����ͼ��Q�������C����������RC����ʽ��ʾ,����C��ʾ����C���������:
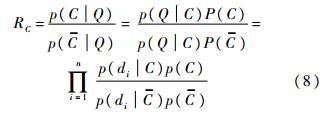
��ʽ(8)ȡ���������
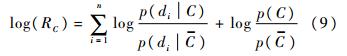
ʽ(9)��ͼ��Q�����C����������ת��Ϊͼ���оֲ����������C����������,��˷�����߿��Ա�ʾΪ
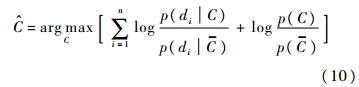
�������C��������ʷ��Ӿ��ȷֲ�,��ʽ(10)��
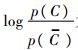 Ϊ����ֵ,���ڷ�����κι���,����������ձ�ʾΪ
Ϊ����ֵ,���ڷ�����κι���,����������ձ�ʾΪ 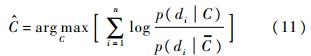
ʽ�У�p(di C)��exp(��||di��NNC(di)||2)��p(di C)�����ڼ���ͼ���оֲ�����di�����C�е�����ھ��룻p(di C)������di��C�е�����ھ���,di��C�е�����ڳ�Ϊ�ν��ڣ�NNC��ʾ����ͼ���оֲ�����di�����C�е������.������յķ�����߿���Ϊ�ɸ��ֲ������������ܵ�����������,NBNN���ò���ͼ����ÿ������������ڸ������ĺ������,��ǰ�������֪,�˹��̲�����Ҫ��ÿ�������������ĺ������;�ر�������[16]ָ������֮��ľ��볬��һ����Χʱ,ŷʽ���벻����Ч�ط�Ӧ���������ʵ����,��˿�����Ϊ�����Զ��Χ�ڵ�����������������ʵĸ���Ӱ�첻��,���Ժ��Բ���.���ڴ�,����ѡ�����������ڵ�K���ڸ������ĺ������,Ϊ�˼��ٱ�����Ϣ�Է������ܵ�Ӱ��,���õ�K+1������ڹ��Ʊ�����Ϣ�ĸ����ܶ�.ԭʼNBNN�㷨��ʱ�临�Ӷ�ΪO(NQNClog(NTrNT)),����NTr��ʾÿ�����ѵ��ͼ�����Ŀ,NC��ʾѵ��ͼ���е������Ŀ,NQ��NT�ֱ��ʾ����ͼ���ѵ��ͼ���е�������Ŀ,�����ڶ�������кܴ�һ���ֱ�����ͼ���еı�����Ϣ��������Ϣ,��Ȼ��Щ�������ڷ���û����ʵ���Ե�����,��ȴ�ںܴ�̶���Ӱ�����㷨�������ٶ�.���IJ�������ѡ��ķ�ʽ�Ӳ���ͼ��ѵ��ͼ����ѡ���������ܸߵ��������ڷ���ʶ��,һ����������㷨�������ٶ�,��һ����������㷨���ڴ濪��,Ϊ��Ӧ���ڹ�ģ�����ͼ������ṩ�˿���.�㷨����������ͳ�Ʒֲ����ʶ��������������Բ���������ѡ��,���㹫ʽ������ʾ:

ʽ��,ui��ʾ�����ľ�ֵ;��i��ʾ�����ķ���.ͨ��ʵ�鷢��,Fi��һ���̶��϶�������������������,����ֵԽ�߱�����������������Խ��,����ֵԽ���������������Խ��.�����������,��������Ŀ���NBKNN�㷨��������Ϊ:1) ��ȡ����ͼ����C��ѵ��ͼ���еľֲ�����,�ֱ��Ϊdi��Q��dCi.2) ����ʽ(12)�������ͼ���ѵ��ͼ����������Fiֵ,����ǰM�����Fiֵ��Ӧ������,���в���ͼ���е�ǰM��������ΪdM.3) ��ÿ��dM�����C��������K����,�ֱ��Ϊ{N1C,N2C,��,NCK},���������������������ڲ��������ֵUC.4) ����dM�������K-1���ڵľ���֮��,�Լ���K���ڼ�UC�ľ���,�ֱ��Ϊ

5) ��ÿ��dM�ڸ����C�м���TC,TC=D1��D2��D3,���յķ������Ϊ:
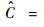
 4 ʵ��������� 4.1 ʵ������Ϊ����֤���������㷨����Ч��,ѡ����Caltech-101ͼ����Caltech-256ͼ����н��з���ʶ��ʵ��,����Caltech-101ͼ��������101�����͵�ͼ��,�綯��Ҿߡ���������������,ÿ��ͼ�����31~800��ͼ��.Caltech-256ͼ��������256�����͵�ͼ��,ÿ���������80��ͼ��.�����Caltech-101ͼ���,Caltech-256ͼ�����߸�����.ʵ���ȡͼ����������е�һ��������,��ͼ���е�ÿ��ͼ���������Ϊѵ��ͼ�Ͳ���ͼ��.�����ѧϰ�ķ������ͬ,�Dz������ķ����㷨û��ѧϰ�Ĺ���,��˲���Ҫѵ������ѵ��������,����Ϊ�˱��ڱȽ������,��ʹ��ѵ��������ʾ��������ǩ�IJο�ͼ��,ʹ�ò���ͼ���ʾ����ͼ��.���IJ��ó���SIFT������ʾͼ��,��ȡ������ͼ����СΪ16��16,����Ϊ8,ʵ������������ͼ��ij��Ϳ�������300����.�ر��,���IJ���FLANN���н��ƽ�������,ʵ�����������KD-tree�ĸ���Ϊ5. 4.2 Caltech-101ͼ����ʵ���� 4.2.1 ���ڸ���K�Է������ܵ�Ӱ�����Ⱥ������ڸ���K�Է������ܵ�Ӱ��,ʵ���в���ͼ����ѵ��ͼ���û�о�������ѡ�����.ʵ������ͼ 1��ʾ,��Kȡ1ʱ(�����DZ�����Ϣ��Ӱ��)�����㷨�˻�ΪԭʼNBNN�㷨,ͼ�������ȷ��Ϊ62.32%.��Kȡ10ʱ,�㷨ȡ�������ŷ�������,ͼ�������ȷ�ʴﵽ65.18%,��ԭʼNBNN�㷨����ȷ�������2.86%.�����ԭʼNBNN�㷨,���㷨�ڷ�������г��������������K������Ϣ����ȥ���˱�����Ϣ�Է����Ӱ��,��˷������ܽ���.��ʵ���������Է��ֵ�K����Խ�С�ķ�Χ(5~20)��ȡֵʱ,�㷨�������ԽϺõķ���Ч��.Kֵ��С,ͼ��ķ������ܽϲKֵ����,�������ܲ�û�����������,����һ���̶����������㷨�ĸ�����.������[16]�����LLC��,������ڸ���KΪ5ʱȡ�����Ч��,����ʵ�����������һ����,�ں���ʵ����ȡK=10.
4 ʵ��������� 4.1 ʵ������Ϊ����֤���������㷨����Ч��,ѡ����Caltech-101ͼ����Caltech-256ͼ����н��з���ʶ��ʵ��,����Caltech-101ͼ��������101�����͵�ͼ��,�綯��Ҿߡ���������������,ÿ��ͼ�����31~800��ͼ��.Caltech-256ͼ��������256�����͵�ͼ��,ÿ���������80��ͼ��.�����Caltech-101ͼ���,Caltech-256ͼ�����߸�����.ʵ���ȡͼ����������е�һ��������,��ͼ���е�ÿ��ͼ���������Ϊѵ��ͼ�Ͳ���ͼ��.�����ѧϰ�ķ������ͬ,�Dz������ķ����㷨û��ѧϰ�Ĺ���,��˲���Ҫѵ������ѵ��������,����Ϊ�˱��ڱȽ������,��ʹ��ѵ��������ʾ��������ǩ�IJο�ͼ��,ʹ�ò���ͼ���ʾ����ͼ��.���IJ��ó���SIFT������ʾͼ��,��ȡ������ͼ����СΪ16��16,����Ϊ8,ʵ������������ͼ��ij��Ϳ�������300����.�ر��,���IJ���FLANN���н��ƽ�������,ʵ�����������KD-tree�ĸ���Ϊ5. 4.2 Caltech-101ͼ����ʵ���� 4.2.1 ���ڸ���K�Է������ܵ�Ӱ�����Ⱥ������ڸ���K�Է������ܵ�Ӱ��,ʵ���в���ͼ����ѵ��ͼ���û�о�������ѡ�����.ʵ������ͼ 1��ʾ,��Kȡ1ʱ(�����DZ�����Ϣ��Ӱ��)�����㷨�˻�ΪԭʼNBNN�㷨,ͼ�������ȷ��Ϊ62.32%.��Kȡ10ʱ,�㷨ȡ�������ŷ�������,ͼ�������ȷ�ʴﵽ65.18%,��ԭʼNBNN�㷨����ȷ�������2.86%.�����ԭʼNBNN�㷨,���㷨�ڷ�������г��������������K������Ϣ����ȥ���˱�����Ϣ�Է����Ӱ��,��˷������ܽ���.��ʵ���������Է��ֵ�K����Խ�С�ķ�Χ(5~20)��ȡֵʱ,�㷨�������ԽϺõķ���Ч��.Kֵ��С,ͼ��ķ������ܽϲKֵ����,�������ܲ�û�����������,����һ���̶����������㷨�ĸ�����.������[16]�����LLC��,������ڸ���KΪ5ʱȡ�����Ч��,����ʵ�����������һ����,�ں���ʵ����ȡK=10.  |
| ͼ 1 ���ڸ���K�Է������ܵ�Ӱ��Fig. 1 Influence of number of nearest neighbors K for classification performance |
| ͼѡ�� |
�� 1�����˱����㷨������һЩ�����㷨�ĶԱȽ��,�ӱ��п��Կ���,�ڸ��ַDz������ķ����㷨�б����㷨����SPM-NN,GB-NN[8],GB Vote NN[22],SVM-KNN[18]�Լ�NBNN1�㷨,NBNN1��ʾ����ʹ��SIFT������ԭʼNBNN�㷨;���㷨�������ܵ���Local NBNN ��NBNN5[9],NBNN5����ʹ����SIFT����������,���һ���������ȡ���ɫ����״�Լ�������������,����ܹ����ḻ������³���ر�ʾͼ����Ϣ;Local NBNN�㷨ѡ��ֲ������������ڷ������.��Ȼ�����㷨��ȡ�ķ������ܽϸ�,��Ҳ���������ٶȽ������ڴ濪���������;�� 1�к�4���㷨�ǻ��ڲ����������㷨��ʵ����,�㷨������ѧϰ�Ĺ���.��ʵ�������Կ���,�����㷨����SPM[5],LLC[16],NBNN-Kernel[10],���������ܵ���SCSPM[6]��LSC[7],LSC���þֲ�����ֵ�����˼��,����˼���뱾���㷨����,��������˸��������Ϣ,��һ���̶��ϱ��������������е���Ϣ��ʧ,���SVM�������㷨ȡ���˽�Ϊ����ķ���Ч��.��Ȼ�����㷨�ķ������ܵ���ScSPM��LSC,�����㷨����Ҫѵ��ѧϰ�Ĺ���,������ѧϰ������������������.�� 1 ��ͬ�㷨��Caltech-101�еķ�����ȷ�ʱȽ� Table 1 Classification accuracy comparison on Caltech-101 of different algorithms
| �����㷨 | ��ȷ��/% | �Ƿ���Ҫ����ѧϰ |
| SPM-NN | 42.10��0.81 | �� |
| GB-NN | 45.20��0.96 | �� |
| GB Vote-NN | 52.00��0.75 | �� |
| SVM-KNN | 59.10��0.56 | �� |
| NBNN1 | 62.30��2.53 | �� |
| NBNN5 | 72.80��0.39 | �� |
| Local NBNN | 66.10��1.10 | �� |
| NBKNN | 65.18��1.72 | �� |
| NBNN-Kernel | 61.30��0.20 | �� |
| SPM | 62.50��0.90 | �� |
| ScSPM | 67.00��0.45 | �� |
| LLC | 65.13��0.39 | �� |
| LSC | 68.37��0.62 | �� |
��ѡ��
4.2.2 �������ر�Ҷ˹K���ڵĿ��ٷ����㷨ԭʼNBNN�㷨�����ٶ���,����[9]������Caltech-101ͼ����е�ѵ����������Ϊ30ʱ,����NBNN�㷨��ÿ��ͼ����з����ƽ��ʱ��ԼΪ140�Bs,��ÿ�����ͼ�����Ϊ15ʱ,ͼ������1�B530��ͼ��(��102��),������ͼ����з�������ʱ��ԼΪ59�Bh.��������ʵ���ж�ÿ��ͼ����з����ƽ��ʱ��ԼΪ41�Bs,ʵ��ʹ��һ̨Core(TM)CPU 3.1�BGHz,8�BGB�ڴ�ļ����. �Բ���ͼ���е�ÿ��������ѵ��ͼ��������������ڲ�����I2C����ռ�����㷨��Ҫ������ʱ��,Ϊ�˽�һ������㷨�������ٶȲ����ٽ��������е��ڴ濪��,���IJ�������ѡ��ķ�ʽ�ֱ���ٲ���ͼ��ѵ��ͼ������ͬʱ���ٶ����е�������Ŀ�������Է������ܵ�Ӱ��. ���ձ����㷨�������ͼ���ѵ��ͼ���и�������Fiֵ���Ӵ�С����,�ֱ�������ͼ���ѵ��ͼ����ǰ90%,80%,��,10%���������ڷ������.NBNN��Ҫ��˼��֮һ�Dz���I2C���������ʽ,�����Ҫ��ȡѵ��ͼ����ÿ��ͼ�������,��������ͼ��������ں�Ϊһ�������ٽ�������ѡ��.ʵ������ͼ 2��ͼ 3��ʾ,����ͼ 2�����˲�ͬ�����ͼ���ƽ��������ȷ��,ͼ 3������Ӧ�����ͼ���ƽ������ʱ��,���в�������ͼ��������ȡ��ʱ��.��ʵ�������Կ���,���Ų���ͼ���ѵ��ͼ���������ļ���,ͼ��ķ�����ȷ�ʾ����ֲ�ͬ�̶ȵ��½�,�������ٶ�Խ��Խ��.��ѡ�����ͼ��90%��80%���������ڷ������ʱ,ͼ�������ȷ�ʷֱ�Ϊ63.75%��62.34%,ƽ������ʱ��ֱ�Ϊ38.52�Bs��37.26�Bs;ѡ��ѵ��ͼ��90%��80%������ʱ,ͼ�������ȷ�ʷֱ�Ϊ64.14%��62.82%,ƽ������ʱ��ֱ�Ϊ37.19�Bs�� 33.41�Bs.���������ڱ�֤ͼ�������ȷ�ʵ�����£���Ч�ؽ����˷���ʱ��,������ԭʼNBNN�㷨,�ر��Ƿ����ٶ����˺ܴ�����.
 |
| ͼ 2 Caltech-101������ѡ��Է�����ȷ�ʵ�Ӱ��Fig. 2 Influence of feature selection for classification accuracy in Caltech-101 |
| ͼѡ�� |
 |
| ͼ 3 Caltech-101������ѡ��Է���ʱ���Ӱ��Fig. 3 Influence of feature selection for classification time in Caltech-101 |
| ͼѡ�� |
��ͼ 2�ɿ���������ͼ���ѵ��ͼ�ֱ�ѡ����ͬ������Ŀ�ٷֱ�ʱ,ǰ������õķ�����ȷ�ʾ�С�ں���,���ҵ�����ͼ���ѵ��ͼ���е�������Ŀ��100%���͵�10%ʱ,���ٲ���ͼ��������Ŀ������ͼ�������ȷ�ʵ��½�����ѵ��ͼ�������������ȷ�ʵ��½�,�ɴ˿ɼ����ڻ���NBNN˼���ͼ�������,���ٲ���ͼ���е������Է�����ȷ��Ӱ��ϴ�;��ͼ 3�ɷ��ּ���ѵ��ͼ���е������Է���ʱ��Ӱ��ϴ�,����ѵ��ͼ����������Ŀ�ļ���,�㷨�������ٶ�Խ��Խ��,��Ҫԭ���Ǽ��ٸ���ѵ��ͼ��(��ʵ���й�102��)�е�������Ŀ�ܴ�̶��ϼ�����FLANN�������Ĵ���ʱ�估�����������ʱ��.���Ϸֱ�ͨ������ѡ��ķ�ʽ��Ч�ؼ����˲���ͼ��ѵ��ͼ���е������ܶȲ������˶Է������ܵ�Ӱ��.ͨ��ʵ������֪,����NBNN˼���ͼ������㷨Ӧ�þ����ܵر�������ͼ���е�������Ϣ,��Ȼ����ͼ���а����˴����������ܽϵ͵�����,���������������϶�,�������ǿ���һ������ʱ��Ȼ���н�ǿ����������;������ѵ��ͼ���е�����,Ӧ�����ܵ�ȥ����Щ��Ϣ���ٵ������Լ�������[23].��������ʵ�����,Ϊ�˽�һ������㷨�������ٶȺͼ����㷨���ڴ濪��,����ͬʱ�ڲ���ͼ���ѵ��ͼ���н�������ѡ��.Ϊ�˱�֤�㷨�ķ�����ȷ��,�ֱ�ѡ���ڲ���ͼ��90%��80%�����������,����ѵ��ͼ���е�������Ŀ���Ƚ�ͼ��ķ�����ȷ�ʺͷ���ʱ��.Ϊ�˱�ʾ����,��ԭʼ����ͼ����ѵ��ͼ��������Ŀ�ֱ�ΪNQ��NT,��������ѡ��֮���������Ŀ�ֱ�ΪFQ��FT.ͼ 4��ͼ 5�ֱ��������������µ�ʵ����,���Կ�����ѵ��ͼ�����ͬ�������ѡ�����ͼ��90%���������ڷ�����Ի�ýϸߵķ�����ȷ��,��������ٶ��Ե��ں���,�������۷�����һ��.��FQ=90%NQ��FT=90%NTʱ,ͼ�������ȷ��Ϊ62.98%,����ʱ��Ϊ36.04�Bs,������ȷ����Ȼ�Ե���NBKNN�㷨,��������ٶȸ��첢����������NBNN�㷨.��FQ=90%NQ��FT=80%NT��FQ=80%NQ��FT=90%NTʱͼ�������ȷ�ʷֱ�Ϊ62.02%��61.77%,����ʱ��ֱ�Ϊ32.53�Bs��34.94�Bs,��Ȼ���������Ե���ԭʼNBNN�㷨,���Ƿ����ٶ���������ԭʼ�㷨.���ѡ����ʵķ�ʽͬʱ�Բ���ͼ���ѵ��ͼ���в�������ƽ�������ȷ�ʺͷ���ʱ��֮���ì��,������ڷ���������ʵ�ʴ��ģͼ�����������.
 |
| ͼ 4 Caltech-101��FQ=90%NQ��FQ=80%NQʱ����ѵ��ͼ��������Ŀ�Է�����ȷ�ʵ�Ӱ��Fig. 4 Influence of reducing feature numbers of training sets while FQ=90%NQ and FQ=80%NQ for classification accuracy in Caltech-101 |
| ͼѡ�� |
 |
| ͼ 5 Caltech-101��FQ=90%NQ��FQ=80%NQʱ����ѵ��ͼ��������Ŀ�Է���ʱ���Ӱ��Fig. 5 Influence of reducing feature numbers of training sets while FQ=90%NQ and FQ=80%NQ for classification time in Caltech-101 |
| ͼѡ�� |
4.3 Caltech-256ͼ����ʵ����Ϊ�˽�һ����֤�㷨����Ч��,������Caltech-256ͼ����Ͻ��з���ʵ��.�ڷ�������зֱ��ÿ��ͼ�������ѡȡ15��ͼ����Ϊѵ��ͼ��Ͳ���ͼ��,ÿ��ʵ��ֱ�ִ��5��,ʵ����Ϊ���ݼ����������ͼ���ƽ��������ȷ��.��ǰ��ʵ��������һ��,��ѡȡ����ڸ���KΪ10ʱ�㷨ȡ�ñȽ�����ķ�����ȷ��,����ʵ����K��ֵ��ȡ10.�� 2�����˱����㷨������һЩ�����㷨��Caltech-256ͼ����ϵĽ��.�� 2 ��ͬ�㷨��Caltech-256�з�����ȷ�ʱȽ�Table 2 Classification accuracy comparison on Caltech-256 of different algorithms
| �����㷨 | ��ȷ��/% | �Ƿ���Ҫ����ѧϰ |
| NBNN | 30.50��2.80 | �� |
| NBKNN | 33.40��2.61 | �� |
| Local NBNN | 33.50��0.90 | �� |
| KSPM | 23.34��0.42 | �� |
| ScSPM | 27.73��0.51 | �� |
| LLC | 34.36��0.32 | �� |
��ѡ��
��ʵ�������Կ��������㷨ȡ�õķ�����ȷ�ʱ�ԭʼNBNN�㷨����˽�3%,��Local NBNN�㷨ȡ�õķ�����ȷ���൱.�ӱ� 2�����Կ���,�Dz����������㷨��Caltech-256ͼ�������ȡ�õ�ʶ����ȷ���ձ����ڻ���ѧϰ���̷����㷨,��Ҫԭ����Caltech-256ͼ�������˸��������ͼ��,ͼ�����ݸ��ӷḻ,����ͼ�����ڲ���������,�仯���߶�����,�ڻ���ѧϰ���̵ķ����㷨��,ѵ����ѧϰ���������ײ�������ϵ�����,���������㷨���ֵ�ѧϰ����������ȹ��̴�����һ�����������,�Ӷ�Ӱ�������յķ�����ȷ��.�Թ�ģ�����Caltech-256ͼ�����з�������ʱ�����,�����ڽ���������ռ���˴������ڴ�ռ�,������־����������˻���NBNN˼��ķ������ʵ�ʴ��ģ�����еȹ�ģͼ����е�Ӧ��.���ñ�������Ŀ���NBKNN�㷨�ֱ�������ͼ���ѵ��ͼ���и�������Fiֵ���Ӵ�С����,�ֱ�������ͼ���ѵ��ͼ��ǰ90%,80%,��,10%���������ڷ������.ʵ������ͼ 6��ͼ 7��ʾ,����ͼ 6�����˲�ͬ�����ͼ���ƽ��������ȷ��,ͼ 7������Ӧ�����ͼ���ƽ������ʱ��.��ʵ�������Կ������ٲ���ͼ���е������Է�����ȷ��Ӱ��ϴ�,����ѵ��ͼ���е������Է���ʱ��Ӱ��ϴ�,����ǰ��ʵ����������һ��.
 |
| ͼ 6 Caltech-256������ѡ��Է�����ȷ�ʵ�Ӱ��Fig. 6 Influence of feature selection for classification accuracy in Caltech-256 |
| ͼѡ�� |
 |
| ͼ 7 Caltech-256������ѡ��Է���ʱ���Ӱ��Fig. 7 Influence of feature selection for classification time in Caltech-256 |
| ͼѡ�� |
Ϊ�˽�һ������㷨�������ٶȺͼ����㷨���ڴ濪��,����ͬʱ�ڲ���ͼ���ѵ��ͼ���н�������ѡ��.Ϊ�˱�֤�㷨�ķ�����ȷ��,�ֱ�ѡ���ڲ���ͼ��90%��80%�����������,����ѵ��ͼ���е�������Ŀ���Ƚ�ͼ��ķ�����ȷ�ʺͷ���ʱ��,ʵ������ͼ 8��ͼ 9��ʾ.��FQ=90%NQ,FT=90%NTʱ,ͼ�������ȷ��Ϊ32.21%,����ʱ��Ϊ92.21�Bs,������ȷ��������ٶ���������NBNN�㷨.��FQ=90%NQ��FT=80%NT��FQ=80%NQ,FT=90%NTʱͼ�������ȷ�ʷֱ�Ϊ31.28%��30.59%,����ʱ��ֱ�Ϊ83.71�Bs��88.20�Bs,����������NBNN�㷨��ӽ�,���Ƿ����ٶ���������ԭʼ�㷨.
 |
| ͼ 8 Caltech-256��FQ=90%NQ��FQ=80%NQʱ����ѵ��ͼ��������Ŀ�Է�����ȷ�ʵ�Ӱ��Fig. 8 Influence of reducing feature numbers of training sets while FQ=90%NQ and FQ=80%NQ for classification accuracy in Caltech-256 |
| ͼѡ�� |
 |
| ͼ 9 Caltech-256��FQ=90%NQ��FQ=80%NQʱ����ѵ��ͼ��������Ŀ�Է���ʱ���Ӱ��Fig. 9 Influence of reducing feature numbers of training sets while FQ=90%NQ and FQ=80%NQ for classification time in Caltech-256 |
| ͼѡ�� |
5 �� �۱����ڷ������ر�Ҷ˹�����㷨�Ļ�����,���K����ԭ�����һ���µ�ͼ������㷨,��ʵ����֤����:1) ����K����(K=10)���ڷ�����߲�ȥ��������Ϣ�Է�����ȷ�ʵ�Ӱ��,�����ԭʼNBNN�㷨�ķ�����ȷ��; 2) ���NBKNN�����㷨,�ȽϷֱ��ڲ���ͼ���ѵ��ͼ���ϲ�������ѡ��ķ�ʽ�������ڷ�����ߵ�������Ŀ�Է������ܵ�Ӱ��,���ٲ���ͼ���������Ŀ�Է�����ȷ��Ӱ��ϴ�,������ѵ��ͼ��������Ŀ�Է���ʱ��Ӱ��ϴ�. 3) ��NBKNN�����㷨��ѡ�����ͼ��90%��������ѵ��ͼ��80%���������ڷ������,ȡ������ԭʼNBNN�����㷨����ķ�����ȷ��,����ԭʼNBNN�㷨���˽�5��,ƽ���˷�����ȷ�������ʱ��֮���ì��,Ϊ����ڷ�����Ӧ����ʵ���ṩ�˿���.��������ڵ�ͼ������㷨�����BoVWģ�͵�ͼ������㷨������ȱ��,��ν�϶���֮����ŵ��ڴ����ݱ�����ѧϰ����Ч���������ķ���ģ���DZ��ĺ����������ص�.
�����
| [1] | Hong R, Wang M,Gao Y,et al.Image annotation by multiple-instance learning with discriminative feature mapping and selection[J].IEEE Trans System,Man and Cybernetics Part:B,2014,44(5): 669-680. |
| Click to display the text | |
| [2] | Hong R, Tang J,Tan H,et al.Beyond search:event driven summarization for web videos[J].ACM Trans on Multimedia Computing,Communications,and Applications,2011,7(4):35-53. |
| Click to display the text | |
| [3] | Sivic J, Zisserman A.Video google:a text retrieval approach to object matching in videos[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2003:1470-1477. |
| Click to display the text | |
| [4] | Yang J, Jiang Y G,Hauptmann A G,et al.Evaluating bag-of-visual-words representations in scene classification[C]//Proceedings of the International Workshop on Workshop on Multimedia Information Retrieval.New York:ACM,2007:197-206. |
| [5] | Lazebnik S, Schmid C,Ponce J.Beyond bags of features:spatial pyramid matching for recognizing natural scene categories[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2006,2:2169-2178. |
| Click to display the text | |
| [6] | Yang J, Yu K,Gong Y,et al.Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2009:1794-1801. |
| Click to display the text | |
| [7] | Liu L, Wang L,Liu X.In defense of soft-assignment coding[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2011:2486-2493. |
| Click to display the text | |
| [8] | Varma M, Ray D.Learning the discriminative power-invariance trade-off[C]//Proceedings of the IEEE 11th International Conference on Computer Vision.Piscataway,NJ:IEEE,2007:1-8. |
| Click to display the text | |
| [9] | Boiman O, Shechtman E,Irani M.In defense of nearest-neighbor based image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2008:1-8. |
| Click to display the text | |
| [10] | Tuytelaars T, Fritz M,Saenko K,et al.The NBNN kernel[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2011:1824-1831. |
| Click to display the text | |
| [11] | Wang Z, Feng J,Yan S,et al.Linear distance coding for image classification[J].IEEE Transactions on Image Processing,2013,22(2):537-548. |
| Click to display the text | |
| [12] | McCann S, Lowe D G.Local naive bayes nearest neighbor for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2012:3650-3656. |
| Click to display the text | |
| [13] | Yang X, Zhang T,Xu C.Locality discriminative coding for image classification[C]//Proceedings of the Fifth International Conference on Internet Multimedia Computing and Service.New York:ACM,2013:52-55. |
| Click to display the text | |
| [14] | Tommasi T, Caputo B.Frustratingly easy nbnn domain adaptation[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2013:897-904. |
| Click to display the text | |
| [15] | Wang Z, Hu Y,Chia L T.Improved learning of I2C distance and accelerating the neighborhood search for image classification[J].Pattern Recognition,2011, 44(10):2384-2394. |
| Click to display the text | |
| [16] | Wang J, Yang J,Yu K,et al.Locality-constrained linear coding for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2010:3360-3367. |
| Click to display the text | |
| [17] | Tuytelaars T, Schmid C.Vector quantizing feature space with a regular lattice[C]//Proceedings of the IEEE 11th International Conference on Computer Vision.Piscataway,NJ:IEEE,2007: 1-8. |
| Click to display the text | |
| [18] | Zhang H, Berg A C,Maire M,et al.SVM-KNN:discriminative nearest neighbor classification for visual category recognition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2006,2:2126-2136. |
| Click to display the text | |
| [19] | Zhang H, Berg A C,Maire M,et al.SVM-KNN:discriminative nearest neighbor classification for visual category recognition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2006,2:2126-2136. |
| Click to display the text | |
| [20] | Rematas K, Fritz M,Tuytelaars T.The pooled NBNN kernel:beyond image-to-class and image-to-image[C]//Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics).Heidelberg:Springer Verlag,2013:176-189. |
| Click to display the text | |
| [21] | Muja M, Lowe D G.Fast approximate nearest neighbors with automatic algorithm configuration[C]//International Conference on Computer Vision Theory and Applications.Piscataway,NJ:IEEE,2009:331-340. |
| Click to display the text | |
| [22] | Berg A C, Malik J.Shape matching and object recognition[M].Berlin Heidelberg:Springer,2006. |
| [23] | Hong R, Pan J,Hao S,et al.Image quality assessment based on matching pursuit[J].Information Sciences,2014,273:196-211. |
| Click to display the text |
