

太原理工大学 信息与计算机学院,山西 太原 030024
收稿日期:2022-06-17
基金项目:山西省自然科学基金资助项目(201901D111096); 山西省研究生教育创新项目(2021Y300)。
作者简介:孙颖(1981-),女,山西太原人,太原理工大学副教授;
张雪英(1964-),女,河北石家庄人,太原理工大学教授。
摘要:针对语音情感识别过程中特征不充分的问题,提出了约束式双通道模型,从全局和局部两方面充分挖掘特征所包含的情感信息,从而提高情感识别率.通道1是针对语音特征的全局信息,通过改进门控循环单元,构建了BAGRU(bidirectional attention gate recurrent unit)模型,提高了语音特征之间的相关性;通道2是针对语音特征的局部信息,卷积神经网络与对抗训练结合,避免了局部信息相互干扰.通过双通道融合模型,根据通道特征重要程度生成不同权重,同时引入正交约束,解决了融合时产生特征冗余的问题.研究结果表明,在IEMOCAP和EMO-DB情感语料库上分别达到了62.83% 和82.19% 的识别精度,表现出了良好性能.
关键词:语音情感识别门控循环单元卷积神经网络正交约束
Speech Emotion Recognition Based on Constrained Bi-channel Model
SUN Ying, LI Ze, ZHANG Xue-ying
College of Information and Computer, Taiyuan University of Technology, Taiyuan 030024, China
Corresponding author: ZHANG Xue-ying, E-mail: zhangxueying@tyut.edu.cn.
Abstract: To address the problem of insufficient speech features in speech emotion recognition, a constrained bi-channel model is proposed to fully exploit the emotional information contained in speech features from both global and local aspects, thereby improving the emotion recognition rate. In channel 1, the gated recurrent unit(GRU) was introduced and improved to capture the global information of speech features, and a BAGRU (bidirectional attention gate recurrent unit) model was constructed to improve the correlation between speech features. In channel 2, a convolutional neural network was employed to capture the local information of speech features and adversarial training was added to avoid mutual interference of local information. The bi-channel fusion model automatically generates different weights on the importance of channel features, and the orthogonal constraint is introduced to address the problem of feature redundancy in the bi-channel fusion. Experimental results show that the proposed model achieves recognition accuracies of 62.83% and 82.19% on two common emotional corpus, namely IEMOCAP and EMO-DB. The constrained bi-channel model has better performance in speech emotion recognition tasks.
Key words: speech emotion recognitiongated recurrent unit(GRU)convolutional neural networkorthogonal constraint
语音作为人类日常交流过程中的重要载体,是一种应用最广泛、最直接的表达和感知情感的方式,在情感表达的过程中发挥至关重要的作用[1].与传统的语音情感识别方式相比,深度学习具有能够检测到复杂结构和特征等优势,其处理顺序任务的卓越能力得到业界认可[2-3].焦亚萌等[4]将VGGNet(visival geometry group network)与多头注意力机制相结合,有效提高语音情感算法的准确率.Xie等[5]将注意力机制与长短时记忆(long short term memory,LSTM)网络相结合,有效区分不同语音帧的情感饱和度.郑艳等[6]将一维卷积神经网络(convolutional neural networks,CNN)与门控循环单元(gated recurrent unit, GRU)相结合,提出了CGRU模型,有效缓解了模型过拟合问题.但是,人类在日常生活中识别情感通常是结合语音上下文信息和局部信息分析,以往的情感识别仅对语音特征的局部或全局特征进行了研究,容易造成情感误判.
针对以上问题,本文提出了约束式双通道模型,从全局和局部两方面对语音特征进行学习,充分利用语音特征信息进行情感识别.通道1是将双向门控循环单元(bidirectional gate recurrent unit, BGRU)[7]与双向注意力门控循环单元(bidirectional attention gate recurrent unit,BAGRU)模型相结合,构建BGRU-BAGRU特征学习通道,从全局角度进行分析,增加特征之间的相关性.通道2是CNN与对抗训练结合,构建对抗式CNN的语音特征学习通道,深度挖掘局部特征,防止潜在特征空间相互干扰.双通道融合是对不同通道的情感特征学习通道自动生成相关权重,并引入正交约束,使双通道的特征空间在融合过程中,实现内在分离,消除冗余特征,从而保证了有用特征的高效利用.
1 约束式双通道模型约束式双通道模型是通过通道1和通道2分别从全局和局部学习语音特征,然后经过双通道融合模型实现特征融合,进行情感识别.基于约束式双通道模型的语音情感识别框图如图 1所示.
图 1(Fig. 1)
 | 图 1 约束式双通道模型的语音情感识别Fig.1 Speech emotion recognition based on constrained bi-channel model |
由图 1可知,模型主要由3部分组成:通道1是基于BGRU-BAGRU的语音特征学习通道,BGRU负责对语音信号的正向和反向特征进行解码,BAGRU利用解码特征,在前向和后向特征中增加注意力机制[8],充分考虑了语音信号的全局特征;通道2是基于对抗式CNN的语音特征学习通道,专注于捕捉语音特征的局部信息,挖掘被忽略的细节特征;双通道融合是独立计算双通道得分,决定其特征向量在情感识别中的权重,加入正交约束项是为了避免融合过程中特征冗余的产生.
1.1 基于BGRU-BAGRU的语音特征学习通道GRU的记忆单元在工作过程中,可以保留一定时间长度的信息记忆,而且在训练过程中,内部梯度不会受到不利因素干扰.基于GRU进行改进的BGRU-BAGRU的语音特征学习通道(通道1)如图 2所示.
图 2(Fig. 2)
 | 图 2 BGRU-BAGRU的语音特征学习通道Fig.2 Speech feature learning channel based on BGRU-BAGRU |
由图 2可知,基于BGRU-BAGRU的语音特征学习通道由两部分组成,首先是BGRU的解码,使用BGRU对语音信号的正向和反向特征进行解码;然后是BAGRU,经过双向注意力机制的编码,很好地判断包含情感和没有包含情感的特征,将输出结果连接,保证语音特征的全面学习.
BAGRU模型是将注意力机制引入到模型中,对不同情感强度赋予不同的权重,而且注重语音帧之间的相关性.输入BAGRU中的正向特征通过3次一维卷积操作,得到不同的特征映射矩阵Q∈Rn×t×d, K∈Rn×t×d,V∈Rn×t×d,n是样本个数,t是时间步长,d是语音数据的维度.将Q,K和V的最后一个维度进行分割,分别为 Q′∈Rn×t×i×d′,K′∈Rn×t×i×d′,V′∈Rn×t×i×d′,其中,i是多头的数目,i×d′=d,然后计算权重W为
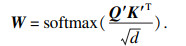 | (1) |
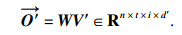 | (2) |
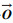
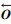
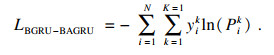 | (3) |
1.2 基于对抗式CNN的语音特征学习通道2014年提出了生成对抗网络(generative adversarial network,GAN)[9].GAN分为两部分,分别为生成模型和判别模型.生成模型通过生成器生成样本,用于学习生成分布,将其与真实数据分布进行匹配.判别模型学习判断样本是来自真实数据分布还是学习生成数据分布,这是一个最大最小问题,可以通过风险函数进行优化,风险函数为
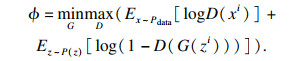 | (4) |
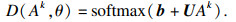 | (5) |
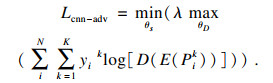 | (6) |
1.3 双通道融合双通道融合模型如图 3所示.
图 3(Fig. 3)
 | 图 3 双通道融合模型Fig.3 Bi-channel fusion model |
由图 3可知,v1和v2分别是语音特征经过通道1和通道2后的向量.为了将双通道特征有效地结合在一起,将v1和v2作为输入,然后通过2个神经网络独立计算双通道得分,
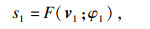 | (7) |
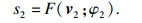 | (8) |
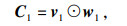 | (9) |
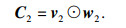 | (10) |
 | (11) |
2 实验2.1 语料库本实验选用IEMOCAP语料库[10]中的对话数据库和EMO-DB语料库,从2种语料库中选用了愤怒、高兴、悲伤和中立4种情感进行识别.IEMOCAP对话数据集中记录了5组对话,对话数据集不同情感句子的数量如表 1所示.
表 1(Table 1)
| 表 1 对话数据集情感句子数量 Table 1 Number of emotional sentences in dialog dataset |
由表 1可知:中立情感句子数量最多,高兴情感句子数量最少.EMO-DB语料库是由10位演员模拟得到的,该数据库的语音录制要求演员通过回忆自身经历完成情感表达,语音情感真实度高、使用度较广.
语音的特征提取是对原始语音信号进行分帧处理,帧长200 ms,帧移为100 ms,计算每帧的声学特征,包括过零率、能量、能量熵、频谱中心、谱熵、频谱通量、频谱滚降点、频谱延展度、色度向量、MFCC共34维语音特征.
2.2 实验方案及评价指标实验选择与说话人无关的训练策略,IEMOCAP数据集采用5折交叉验证的方式,EMO-DB数据集采用10折交叉验证的方式.为了减少模型的过拟合现象,提高模型的尺度不变性,处理6种方案输出特征时,采用了层归一化(layer normalization, LN)[11].LN的归一化项仅取决于当前时间步对层的求和输入,在所有时间步中,仅1组权重和偏置参数共享,保证了对于每个训练特征平移和缩放不变,加快了神经网络训练.
为验证所提出的约束式双通道模型的有效性,设置了6组实验:实验1采用了2层BGRU,即基于BGRU模型的语音情感识别;实验2是基于BGRU-BAGRU模型的情感识别;实验3是基于CNN模型的语音情感识别;实验4是基于对抗式CNN模型的语音情感识别;实验5是将双通道输入特征v1和v2串联融合,即基于双通道模型的语音情感识别;实验6是基于约束式双通道模型的语音情感识别.
实验中所用的评价指标包括加权准确率(weight accuracy,WA)和未加权准确率(unweight accuracy,UA),计算公式为
 | (12) |
 | (13) |
表 2(Table 2)
| 表 2 模型有效性验证实验结果 Table 2 Experimental results of model validation ? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
由表 2可见:与BGRU相比较,BGRU-BAGRU由于结合了双向注意力机制,各项评价指标更有助于语音情感识别率的提高.对抗式CNN与CNN比较发现对抗训练有助于语音情感识别.BGRU与CNN相比,各项评价指标较高,表明语音全局特征更有助于识别情感信息.约束式双通道各项评价指标优于双通道,表明相比于将双通道特征直接连接,通过自动生成各通道的权重,有效特征在语音情感识别中可以发挥更大的作用,正交约束项的加入,避免了双通道在直接串联融合过程中产生冗余,对语音情感识别的准确率产生积极影响.约束式双通道在所有网络模型中各项评价指标均是最高的,由此验证模型的有效性.
6组实验在IEMOCAP上的混淆矩阵如图 4所示.由图 4可见:悲伤在每组实验中的识别率均保持在70% 左右,表明悲伤情感更易区分.BGRU和BGRU-BAGRU的混淆矩阵图比较发现,BAGRU通过注意力机制,可以降低愤怒与中立的混淆比例,BGRU-BAGRU的高兴情感识别率下降,表明注意力机制在训练时,容易和中立情绪发生混淆.通过CNN的混淆矩阵看出,高兴识别率最低,而且高兴在识别中与愤怒、中立混淆比例较大,而对抗式CNN的混淆矩阵中高兴大部分是与中立发生混淆,原因是高兴与愤怒在局部特征具有高相似性,都属于高激活度情感,通过加入对抗训练,有利于识别出高激活度中的不同情感.比较CNN与对抗式CNN的愤怒识别发现,对抗训练的加入增大了愤怒与中立的混淆程度.双通道与约束式双通道的混淆矩阵比较发现,约束式双通道在生气情感识别中表现最为突出.实验中混淆矩阵中愤怒、高兴和悲伤3种情感大概率会被错误地归类为中立,有两方面的原因:一方面是中立为低激活度和低效价度情感,处于情感维度空间的中心,其他情感更容易被识别为中立;另一方面是中立情感数据量大,因此更容易误判为中立情感.悲伤在各种实验中的识别率都是最高,由此可推断出悲伤情感相比于其他情感,更容易识别.
图 4(Fig. 4)
 | 图 4 IEMOCAP实验结果的混淆矩阵Fig.4 Confusion matrix of experimental results of IEMOCAP (a)—BGRU;(b)—BGRU-BAGRU;(c)—CNN;(d)—对抗式CNN;(e)—双通道;(f)—约束式双通道. |
2.4 模型比较在EMO-DB数据集的34维特征上,本文模型与文献[4-6]的模型进行比较,模型比较结果如表 3所示.
表 3(Table 3)
| 表 3 模型比较结果 Table 3 Results of model comparison ? | ||||||||||||||||||||||||||||||||||||||||||||||||||
由表 3可知:本文的WA和UA都是最高的.本文与文献[4-5]相比,加入了局部特征学习模型,更加全面地实现了语音情感特征学习,文献[4]将经过一维卷积的特征输入到GRU当中,虽然也进行了局部特征与全局特征学习的处理,但是将模型简单地串联容易忽略前期的全局和后期的局部特征.文献[5]中的LSTM与GRU相比,GRU具有参数相对简单,而且更容易收敛的良好特性.文献[6]的MS-VGGNet模型的WA和UA均是最低,是因为VGGNet更适合处理图像数据.由此可以表明,在处理语音特征不充分的情况下,本文所提出的约束式双通道模型性能更加优良.
2.5 正交约束有效性的验证为了验证正交约束的有效性,在IEMOCAP语料库上设置了3组实验:实验1将图 3中的C1和C2串联融合在一起,即直接串联;实验2是约束式双通道学习的语音情感识别模型;实验3将正交约束项换成最大平均差异(maximum mean discrepancy,MMD)[12],即MMD双通道,损失函数为
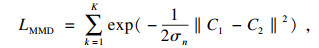 | (14) |
表 4(Table 4)
| 表 4 实验方案结果 Table 4 Experimental scheme results ? | ||||||||||||||||||||||||||||||||||||||||||
由表 4可知:约束式双通道与直接串联、MMD双通道相比较,WA和UA都有所提高,由此可证明约束项对模型识别率的提高有着重要作用,MMD双通道中MMD度量2个通道特征分布之间的相似性,虽然有一定作用,但效果不如正交约束.
3 结语本文针对特征不充分问题,提出了约束式双通道学习模型,从全局和局部两方面将特征相融合,更大程度上保留了语音情感的特征.在通道1中通过BAGRU中的注意力模块,增强了语音特征的相关性.在通道2中通过对抗网络,充分挖掘了语音的细节特征.双通道特征融合过程中自动生成通道权重,并且加入了约束项,在一定程度上减少了双通道模型所造成的特征冗余.实验证明,约束式双通道模型在IEMOCAP和EMO-DB语料库上识别率达到62.83% 和82.19%,由此可证明约束式双通道模型可以显著提高语音情感识别效果.
参考文献
| [1] | Issa D, Demirci M F, Yazici A. Speech emotion recognition with deep convolutional neural networks[J]. Biomedical Signal Processing and Control, 2020, 59: 101894. DOI:10.1016/j.bspc.2020.101894 |
| [2] | 段俊毅, 赵建峰. 基于CNN的时频域语音情感识别的分析与对比[J]. 内蒙古师范大学学报(自然科学汉文版), 2021, 50(6): 526-532. (Duan Jun-yi, Zhao Jian-feng. Analysis and comparison of speech emotion recognition in time-frequency domain based on CNN[J]. Journal of Inner Mongolia Normal University(Natural Science Edition), 2021, 50(6): 526-532.) |
| [3] | Tzinis E, Potamianos A. Segment-based speech emotion recognition using recurrent neural networks[C]//2017 Seventh International Conference on Affective Computing and Intelligent Interaction(ACⅡ). New York: IEEE, 2017: 190-195. |
| [4] | 焦亚萌, 周成智, 李文萍, 等. 融合多头注意力的VGGNet语音情感识别研究[J]. 国外电子测量技术, 2022, 41(1): 63-69. (Jiao Ya-meng, Zhou Cheng-zhi, Li Wen-ping, et al. Study on voice emotional recognition with multi-headed attention in VGGNet[J]. Foreigh Electronic Measurement Technology, 2022, 41(1): 63-69.) |
| [5] | Xie Y, Liang R Y, Liang Z L, et al. Speech emotion classification using attention-based LSTM[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(11): 1675-1685. DOI:10.1109/TASLP.2019.2925934 |
| [6] | 郑艳, 陈家楠, 吴凡, 等. 基于CGRU模型的语音情感识别研究与实现[J]. 东北大学学报(自然科学版), 2020, 41(12): 1680-1685. (Zheng Yan, Chen Jia-nan, Wu Fan, et al. Research and implementation of speech emotion recognition based on CGRU model[J]. Journal of Northeastern University(Natural Science), 2020, 41(12): 1680-1685.) |
| [7] | Petridis S, Stafylakis T, Ma P C, et al. End-to-end audiovisual speech recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP). New York: IEEE, 2018: 6548-6552. |
| [8] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: Curran Associates, 2017: 6000-6010. |
| [9] | Creswell A, White T, Dumoulin V, et al. Generative adversarial networks: an overview[J]. IEEE Signal Processing Magazine, 2018, 35(1): 53-65. DOI:10.1109/MSP.2017.2765202 |
| [10] | Busso C, Bulut M, Lee C C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42(4): 335-359. |
| [11] | Xiong R B, Yang Y C, He D, et al. On layer normalization in the transformer architecture[EB/OL]. (2020-06-09)[2021-11-26]. https://arxiv.org/abs/2002.04745. |
| [12] | Bousmalis K, Trigeorgis G, SilbermannI N, et al. Domain separation networks[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 343-351. |
