
 , 王照乙
, 王照乙 东北大学 理学院,辽宁 沈阳 110819
收稿日期:2022-05-22
基金项目:国家重点研发计划项目(2020YFB1710003)。
作者简介:张雪峰(1966-),男,辽宁辽阳人,东北大学副教授。
摘要:汽车自动变道需要在保证不发生碰撞的情况下,以尽可能快的速度行驶,规则性地控制不仅对意外情况不具有鲁棒性,而且不能对间隔车道的情况做出反应.针对这些问题,提出了一种基于双决斗深度Q网络(dueling double deep Q-network, D3QN)强化学习模型的自动换道决策模型,该算法对车联网反馈的环境车信息处理之后,通过策略得到动作,执行动作后根据奖励函数对神经网络进行训练,最后通过训练的网络以及强化学习来实现自动换道策略.利用Python搭建的三车道环境以及车辆仿真软件CarMaker进行仿真实验,得到了很好的控制效果,结果验证了本文算法的可行性和有效性.
关键词:车道变换自动驾驶强化学习深度学习深度强化学习
Automatic Lane Change Decision Model Based on Dueling Double Deep Q-network
ZHANG Xue-feng
, WANG Zhao-yi School of Sciences, Northeastern University, Shenyang 110819, China
Corresponding author: ZHANG Xue-feng, E-mail: zhangxuefeng@mail.neu.edu.cn.
Abstract: Automatic lane change of vehicles requires driving at the fastest possible speed while ensuring no collision situations. However, regular control is not robust enough to handle unexpected situations or respond to lane separation. To solve these problems, an automatic lane change decision model based on dueling double deep Q-network(D3QN) reinforcement learning model is proposed. The algorithm processes the environmental vehicle information fed back by the internet of vehicles, and then obtains actions through strategies. After the actions are executed, the neural network is trained according to given reward function, and finally the automatic lane change strategy is realized through the trained network and reinforcement learning. The three-lane environment built by Python and the vehicle simulation software CarMaker are used to carry out simulation experiments. The results show that the algorithm proposed has a good control effect, making it feasible and effective.
Key words: lane changedriverless vehiclesreinforcement learningdeep learningdeep reinforcement leaning
自动换道技术在智能驾驶中是重要的环节.近年来,随着环保观念的深入人心,新能源的使用逐渐增多.其中,新能源汽车作为新能源领域的关键技术,科技感、智能驾驶一直以来都是汽车生产商们努力实现的目标.5G的兴起以及应用促进了车联网的发展,使得实现目标变得更为可能.
已有的自动换道决策相关研究主要是基于规则和基于机器学习的模型.基于规则的模型中,自车(算法控制的智能车)通过环境车(环境中其他车)的位置、速度等特征来计算可变车道的优先性、必要性以及可行性来做出变道决策.这种模型的代表为Gipps[1]换道模型及许多改进和拓展,如杨达等[2]在车联网情况下,以Gipps安全驾驶模型为基础,充分考虑下层安全条件判断模型对最优车道序列的影响,获得了安全可行的最优目标车道.基于机器学习的模型则是通过大量的驾驶员换道作业数据,来进行是否换道、换哪条道的监督学习.其中,Hou等[3]的随机森林算法和自适应增强算法(Adaboost)和Liu等[4]的支持向量机(SVM)决策模型都取得了较好的换道效果. 此类模型相较于规则模型来说,精度虽然高,但所需数据量很大,特征与标签都很多,难以处理.
从2015年开始Deepmind公司使用深度强化学习使得智能体在Atari游戏领域达到了人类水平[5],强化学习开始飞速发展以及广泛应用.强化学习已经应用在许多领域,如王建平等[6]使用强化学习对机器人机械臂的精准控制.赖建辉[7]和舒凌洲等[8]将强化学习应用到交通信号控制领域且取得了很好的效果.孟琭等[9]使用深度Q网络(deep Q-network,DQN)算法与目标检测算法结合在射击游戏领域也取得了很好的效果.
在汽车自动跟随驾驶领域,You等[10]在高速公路驾驶场景中采用Q-learning方法进行车辆加速、制动、超车和转弯等决策.Zhang等[11]使用双深度Q网络(double deep Q-network,DDQN)来控制车速,其中控制动作包括加速、减速和保持.在自动换道领域,Hoel等[12]在汽车的速度控制与换道领域使用了DQN,要注意网络的输入或使用所有环境车的信息,或使用卷积神经网络提取的特征,维度很高.Wang等[13]使用深度确定性策略梯度(deep deterministic policy gradient,DDPG)连续控制车辆,相对离散控制来说,难以训练并且鲁棒性较差.
本文基于以上研究,介绍双决斗深度Q网络(dueling double deep Q-network, D3QN)相较于其他深度强化学习算法的优势,讨论了特征复杂度以及奖励函数的设定,用D3QN对车联网环境观测范围内得到的车流信息和是否换道进行建模.将自车看作智能体,对智能体获得的车联网信息进行处理,得到了一个既有效又不冗余的特征;其次根据实际情况来设定奖励函数,充分考虑速度与换道的奖励平衡;最后通过仿真实验来验证算法的有效性以及优势.
1 准备知识强化学习可以根据不同的标准分为不同的类别,如根据智能体的学习方法可以分为在线学习(on-policy)和离线学习(off-policy),根据策略的学习方法可以分为基于值的(value-based)和基于策略梯度的(policy gradient-based).本文使用的是基于值的离线学习算法Q-learning以及它的变体.
1.1 Q-learning和DQN强化学习解决的是序列决策问题,通常由五元组(S, A, R, P, γ)表示.智能体在时间t接收一个来自环境的状态st=(x1, x2, …, xn)∈S,返回一个动作at∈A,其中n为状态的特征数量.环境执行动作at后,以P(st, at)的转移概率返回一个时间t+1的状态st+1和奖励rt+1(rt+1∈R),传送给智能体,流程如图 1所示.
图 1(Fig. 1)
 | 图 1 强化学习流程Fig.1 Flowchart of reinforcement learning |
基于值的强化学习算法,会计算出每个状态和动作的Q值,对于随机策略π,定义为[14]
 | (1) |
如果使用Q-learning来估计最优动作值,那么Q值就会被式(2)更新为
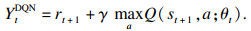 | (2) |
DQN实际上就是用多层神经网络来拟合Qπ(s, a),其中神经网络的参数就是式(2)中的θt.
为了便于神经网络的训练,DQN使用了两个小技巧,即目标网络(target network)和经验重放(experience replay)[5].目标网络的参数为θt-,它不被训练更新,而是每过τ步从在线网络复制而来,每过τ步,θt-=θt.Q值的更新也转变为
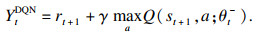 | (3) |
 | (4) |
图 2(Fig. 2)
 | 图 2 DQN流程Fig.2 Flowchart of DQN |
1.2 DDQN标准的Q-learning和DQN算法中存在着一个问题,最大化算子在选择和评估时都使用相同的值,这会使得智能体更倾向于选择被高估的动作,结果高估了估计值.为了缓解这一现象,DDQN解耦了选择和估计这两个行为[15],即
 | (5) |
1.3 D3QN算法1.3.1 D3QN算法的原理引入状态值函数Vπ和动作优势函数Aπ[16]:
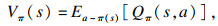 | (6) |
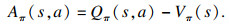 | (7) |
1.3.2 D3QN的网络架构D3QN创造性地采用了一个包含函数Q, V, A的网络架构:
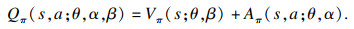 | (8) |
图 3(Fig. 3)
 | 图 3 D3QN网络架构Fig.3 Network architecture of D3QN |
为了确保Qπ(s, a; θ, α, β)是真实Q值的估计,需要同时确保状态值函数网络和优势函数网络的输出分别对应状态值和动作优势,因此对式(8)作以下改变:
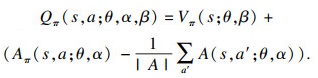 | (9) |
通过D3QN网络架构可以明显看到,每返回一个Yt,不仅该动作对应的优势函数的参数α会被更新,整体状态值函数的β都会被更新,如图 4a所示,而DQN只会更新该动作的Q值,如图 4b所示.
图 4(Fig. 4)
 | 图 4 DQN和D3QN比较Fig.4 Comparison of DQN and D3QN (a)—D3QN的一步更新;(b)—DQN的一步更新. |
2 基于D3QN的换道决策模型对强化学习算法所需要的状态空间、动作空间和奖励函数等作了详细介绍,并给出最终的换道决策算法.其中,状态空间只考虑各个车道自车前面的第一辆环境车的相对车道、相对位置和相对速度,保证环境信息不丢失且足够精炼.奖励函数不仅对严重错误给予惩罚,也设立了一个奖励函数,能够保持速度的同时,尽可能做到避免换道,保证车辆行驶的舒适性.
2.1 状态空间本文算法的状态空间并不像其他深度强化学习算法处理端到端自动驾驶那样,使用自车所获得的图像;也不像其他车联网自动驾驶那样,使用所有车辆的相对位置和相对速度[11].因为这两种特征不仅维度很多而且包含着冗余的特征.
智能体的状态空间如图 5a所示,考虑三辆车的相对车道、相对位置和相对速度,共9个特征.如果某一车道没有车,算法会人为地设立一个相对距离很远、速度很大的车,如图 5b所示,图底部的数字指车道.
图 5(Fig. 5)
 | 图 5 状态空间Fig.5 State space (a)—所有车道均有车;(b)—部分车道没有车. |
相对车道其实就是(-2, -1, 0, 1, 2)中的一个数,但这对保持汽车不出界是必要的.
2.2 动作空间动作空间如表 1所示,本文同时考虑了变道以及变速的可能性,这对于设置奖励函数提供了参考.
表 1(Table 1)
| 表 1 动作空间 Table 1 Action space |
2.3 奖励函数执行动作之后,智能体会从环境中获得一个奖励,这是对智能体做出动作的评估,还会对下一次控制决策产生影响.毫无疑问,奖励函数是强化学习中最重要的一环,如何设置奖励直接影响到算法是否有效、速度快慢等. 首先设置对于自动驾驶来说严重错误的奖励函数,如表 2所示.
表 2(Table 2)
| 表 2 奖励设置 Table 2 Reward setting |
汽车换道时的舒适度主要体现在换道时间、纵向加速度、横向加速度以及风险,这4个因素与舒适度成反比[17].由于动作空间是离散的,本文将换道时间和横向加速度封装成一个换道动作,因此避免鲁莽驾驶、减少换道次数会一定程度上提高舒适度.
奖励函数的主要作用是自车尽可能快且安全地行驶.在纵向加速度方面,权衡了舒适度与通行时间的关系后,选择提高通行时间的优先级.同样给不安全的行为以很大的惩罚,提高了风险方面的舒适度.奖励函数如式(10)所示.
 | (10) |
图 6(Fig. 6)
 | 图 6 奖励函数Fig.6 Reward function |
2.4 环境车辆本文将环境车辆的驾驶模式设置为智能驾驶员模型(intelligent diver model, IDM)[18].IDM环境车的加速度是由与前车的速度差和与前车的位置差所决定的.具体形式为
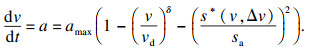 | (11) |
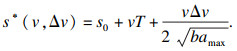 | (12) |
 | (13) |
此时环境车速度经过Δt时间后,为
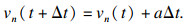 |
环境车的位置如式(14)所示:
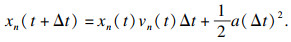 | (14) |
2.6 优先经验回放池在原始的经验回放池中,每次训练会均匀地抽取一批样本,这种经验回放池认为所有的样本重要程度都相等.但是在实际训练中,显然不同的样本对训练的重要程度都是不同的.Schaul等[19]使用TD误差来衡量样本的重要程度,TD误差的绝对值越大,证明智能体可以从这个样本中学习到更多知识,也就会赋予样本更大的权重.TD误差δ定义为
 | (15) |
 | (16) |
2.7 算法车联网会获得周边所有汽车的信息,在此需要先对获得的信息按2.1节处理,再添加至经验回放池M.其次,执行动作之后,会对动作a以及下一个状态s′,根据式(8)返回一个奖励.
基于D3QN的自动换道决策算法如下:
输入:优先经验回放池M,批度B,预训练步数p,学习率α,折扣因子γ,总训练步数T,更新频率β. 初始化在线网络参数θ,目标网络θ-,环境s,训练步数i=0.
????????While i < T do
????????根据ε-greedy策略选取动作a
????????执行动作a,得到奖励r和下一个状态s′
????????将(s, a, r, s′)添加到优先经验回放池M
????????s=s′,i=i+1
????????If |M|>B and i>P
????????????从经验回放池M中随机抽取B的经验
????????????使用经验更新在线网络的参数θ
????????????If i%β=0
????????????????更新目标网络θ-=θ
????????????End if
????????End if
算法流程图如图 7所示.
图 7(Fig. 7)
 | 图 7 算法流程图Fig.7 Flowchart of algorithm |
3 仿真实验本文用Python搭建了一个3个车道、6个环境车的仿真环境,如图 8和图 9所示,其中


图 8(Fig. 8)
 | 图 8 Python仿真示例一Fig.8 Python simulation example one (a)—速度10 m/s,奖励-16;(b)—速度13 m/s,奖励-27;(c)—速度31 m/s,奖励-11;(d)—速度34 m/s,奖励82. |
图 9(Fig. 9)
 | 图 9 Python仿真示例二Fig.9 Python simulation example two (a)—速度10 m/s,奖励-16;(b)—速度16 m/s,奖励-22;(c)—速度22 m/s,奖励-20;(d)—速度34 m/s,奖励106. |
自车首先获取所有的环境车信息,之后对信息采用2.1节所示的方式进行处理,得到一个9维的特征.在训练以及测试时都使用这9维特征,即五元组中的S.将这些特征按照2.5节所示的策略得到一个动作A,之后智能体执行动作A,得到奖励R和下一时刻状态S′.算法使用(s, a, r, s′)更新神经网络的参数,如2.7节算法所示.
在图 8中,自车起始于第三车道,由于距离前车太近,所以换到中间车道行驶.在距离前车太近时,自车评估左右车道的前车车速和相对距离,换到第三车道,完成行驶.
在图 9中,自车起始于第一车道,距离本车道前车过近,换到中间车道行驶,自车评估左右车道的前车车速和相对距离,换到第三车道,完成行驶.
在图 8和图 9中都可以明显看到,自车在快接触到前车时会及时变道,同时会选择一条能够使自己更快运行的道路.在本车道可以安全驾驶时,汽车也会保持直行,不会鲁莽变道.从输出也可以看到,汽车持续加速直到保持在最快速度.
为了验证仿真环境构建的合理性和参数训练的准确性,本文使用了车联网仿真环境CarMaker,它能够提供环境车的车道、距离和速度.将这些特征处理之后,用Python环境训练得来的参数作出决策.需要注意的是,在实际仿真中,用到的计算仅仅是矩阵相乘,所以不用担心太过复杂的运算导致算力不够而处理不了即时路况.
在CarMaker中,自车会获得所有环境车的相对车道、位置和速度. 同样地处理为9个特征之后,只需用特征与神经网络的参数简单地进行矩阵相乘,得到各个动作的Q值,在仿真环境中,智能体只选择Q值最大的动作,即贪婪系数ε=0.
图 10和图 11为CarMaker仿真环境的两个示例,其中方格中的车为自车,其余车为环境车.本文截取出了汽车换道时的帧, 可以看到,自车在检测或接近本车道的环境车时,会主动变道.Python训练出来的参数也可以很好地应用到该环境,鲁棒性很强.
图 10(Fig. 10)
 | 图 10 CarMaker仿真示例一Fig.10 CarMaker simulation example one |
图 11(Fig. 11)
 | 图 11 CarMaker仿真示例二Fig.11 CarMaker simulation example two |
同时本文给出了算法的超参数,如表 3所示.
表 3(Table 3)
| 表 3 超参数 Table 3 Hyper-parameters |
本文还对DDQN,D3QN和SVM换道模型做了对比实验,如表 4所示.其中9info代表特征,如第2节所介绍的处理之后的9个特征;default表示智能体接受所有环境车的信息,即7个车,21个特征;SVM的核函数为高斯核,训练数据为Next Generation Simulation(NGSIM)中的880个换道样本和1 030个车道保持样本.
表 4(Table 4)
| 表 4 四种算法的消融实验 Table 4 Ablation experiment of four kinds of algorithms | ||||||||||||||||||||||||||||||
图 12可视化了智能体的每训练65次的平均奖励,可以看出D3QN相较于对比方法而言,不仅能够获得更高的奖励且更稳定,还能够在仿真环境中拥有更高的平均完成次数(见表 4).由于SVM没有明显的学习过程以及并没有在仿真环境中训练,在此不做可视化处理.
图 12(Fig. 12)
 | 图 12 DDQN与D3QN对比Fig.12 Comparison of DDQN and D3QN |
4 结语本文提出了一种基于D3QN的自动换道算法,解决了输入特征冗余问题,并且设置了一个能够平衡换道与变速的奖励函数.在Python以及CarMaker两种环境进行仿真实验,结果表明,D3QN能够有效地处理自动驾驶的变道和变速问题.同时本文进行了消融实验,展示了处理后的特征相较于默认特征、D3QN相较于DDQN以及强化学习相较于传统机器学习的优势.
通过优化奖励以及设置更复杂的路况,可以使得算法更具有鲁棒性,同时也可以将其他环境车处理成智能体,以便于更进一步的博弈,最终可以解决实际问题.
参考文献
| [1] | Gipps P G. A model for the structure of lane-changing decisions[J]. Transportation Research Part B: Methodological, 1986, 20(5): 403-414. DOI:10.1016/0191-2615(86)90012-3 |
| [2] | 杨达, 吕蒙, 戴力源, 等. 车联网环境下自动驾驶车辆车道选择决策模型[J]. 中国公路学报, 2022, 35(4): 243-255. (Yang Da, Lyu Meng, Dai Li-yuan, et al. Decision-making model for lane selection of automated vehicles in connected vehicle environment[J]. China Journal of Highway and Transport, 2022, 35(4): 243-255.) |
| [3] | Hou Y, Edara P, Sun C. Situation assessment and decision making for lane change assistanceusing ensemble learning methods[J]. Expert Systems with Application, 2015, 42(8): 3875-3882. DOI:10.1016/j.eswa.2015.01.029 |
| [4] | Liu Y G, Wang X, Li L, et al. A novel lane change decision-making model of autonomous vehicle based on support vector machine[J]. IEEE Access, 2019, 7: 26543-26550. DOI:10.1109/ACCESS.2019.2900416 |
| [5] | Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. DOI:10.1038/nature14236 |
| [6] | 王建平, 王刚, 毛晓彬, 等. 基于深度强化学习的二连杆机械臂运动控制方法[J]. 计算机应用, 2021, 41(6): 1799-1804. (Wang Jian-ping, Wang Gang, Mao Xiao-bin, et al. Motion control method of two-link manipulator based on deep reinforcement learning[J]. Journal of Computer Applications, 2021, 41(6): 1799-1804.) |
| [7] | 赖建辉. 基于D3QN的交通信号控制策略[J]. 计算机科学, 2019, 46(sup2): 117-121. (Lai Jian-hui. Traffic signal control based on double deep Q-learning network with dueling architecture[J]. Computer Science, 2019, 46(sup2): 117-121.) |
| [8] | 舒凌洲, 吴佳, 王晨. 基于深度强化学习的城市交通信号控制算法[J]. 计算机应用, 2019, 39(5): 1495-1499. (Shu Ling-zhou, Wu Jia, Wang Chen. Urban traffic signal control based on deep reinforcement learning[J]. Journal of Computer Applications, 2019, 39(5): 1495-1499.) |
| [9] | 孟琭, 沈凝, 祁殷俏, 等. 基于强化学习的三维游戏控制算法[J]. 东北大学学报(自然科学版), 2021, 42(4): 478-483. (Meng Lu, Shen Ning, Qi Yin-qiao, et al. Control algorithm of three-dimensional game based on reinforcement learning[J]. Journal of Northeastern University(Natural Science), 2021, 42(4): 478-483.) |
| [10] | You C, Lu J, Filev D, et al. Highway traffic modeling and decision making for autonomous vehicle using reinforcement learning[C]// 2018 IEEE Intelligent Vehicles Symposium(Ⅳ). Paris: IEEE, 2018: 1227-1232. |
| [11] | Zhang Y, Sun P, Yin Y H, et al. Human-like autonomous vehicle speed control by deep reinforcement learning with double Q-learning[C]// 2018 IEEE Intelligent Vehicles Symposium(Ⅳ). Paris: IEEE, 2018: 1251-1256. |
| [12] | Hoel C J, Wolff K, Laine L. Automated speed and lane change decision making using deep reinforcement learning[C]//2018 21st International Conference on Intelligent Transportation Systems(ITSC). Maui: IEEE, 2018: 2148-2155. |
| [13] | Wang P, Li H, Chan C Y. Continuous control for automated lane change behavior based on deep deterministic policy gradient algorithm[C]// 2019 IEEE Intelligent Vehicles Symposium(Ⅳ). Paris: IEEE, 2019: 1454-1460. |
| [14] | Sutton R, Barto A. Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 1998. |
| [15] | Van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2016: 2094-2110. |
| [16] | Wang Z Y, Schaul T, Hessel M, et al. Dueling network architectures for deep reinforcement learning[C]//International Conference on Machine Learning. New York: PMLR, 2016: 1995-2003. |
| [17] | 李诗成. 考虑乘员个性化舒适性的自动驾驶汽车轨迹规划算法研究[D]. 广州: 华南理工大学, 2021. (Li Shi-cheng. Research on autonomous vehicle trajectory planning algorithm considering the personalized comfort of occupants[D]. Guangzhou: South China University of Technology, 2021. ) |
| [18] | Treiber M, Hennecke A, Helbing D. Congested traffic states in empirical observations and microscopic simulations[J]. Physical Review E, 2000, 62: 1805-1824. |
| [19] | Schaul T, Quan J, Antonoglou I, et al. Prioritized experience replay[J]. arXiv Preprint arXiv, 1511.05952, 2015. |
