

东北大学秦皇岛分校 控制工程学院,河北 秦皇岛 066000
收稿日期:2022-05-17
基金项目:河北省教育厅科学技术研究资助项目(BJ2021099)。
作者简介:黄传奇(1998-), 男, 山东菏泽人, 东北大学硕士研究生;
吴朝霞(1969-), 女, 浙江嘉兴人, 东北大学教授。
摘要:针对烧结混合料水分预测的问题,引入了基于叠加泛化集成的建模方法,提出了Robust Scaler-Rank Gauss (RS-RG) 混合算法对输入叠加模型的数据进行处理,进而建立了基于叠加泛化集成的烧结混合料水分预测轻量梯度提升机-随机森林-极端梯度提升机(LGBM-RF-XGB)混合模型,可以在烧结料混合前预知水分值.LGBM-RF-XGB叠加模型的内部机制是先从LGBM和RF模型生成元数据,再使用XGB模型计算最终预测.结合烧结现场数据,将提出的叠加模型与多个基准模型进行了对比仿真实验.结果表明,所提出叠加模型的精度和误差均优于用于对比的基准模型,满足烧结工艺要求,可以用于实际生产中的烧结混合料水分提前预测,为加水量自动控制提供理论依据.
关键词:烧结混合料水分轻量梯度提升机(LGBM)随机森林(RF)极端梯度提升机(XGB)RS-RG数据处理
A Stacked Generalization Ensemble-based Hybrid LGBM-RF-XGB Model for Sintering Moisture Prediction
HUANG Chuan-qi, REN Yu-qian, WU Zhao-xia
College of Control Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066000, China
Corresponding author: WU Zhao-xia, E-mail: ysuwzx@126.com.
Abstract: In order to predict the moisture of the mixture, a modeling method based on stacked generalization ensemble is introduced, and a Robust Scaler-Rank Gauss (RS-RG) hybrid algorithm is proposed to process the data input to the stacking model, and then the LGBM-RF-XGB hybrid model is established for sintered mixture moisture prediction based on stacked generalization ensemble, which can predict the moisture value before sinter mixture mixing. The internal mechanism of the LGBM-RF-XGB overlay model consists of generating metadata from the LGBM and RF models to calculate the final prediction using the XGB model. The proposed stacking model was simulated in comparison with several reference models by combining the sintering site data. The results show that the accuracy and error of the proposed stacking model are better than those of the reference models used for comparison, which meets the sintering process requirements. The proposed algorithm can be used for advance prediction of sinter mix moisture in actual production and provides a theoretical basis for automatic control of water addition.
Key words: moisture of sintering mixture (MSM)light gradient boosting machine (LGBM)random forest (RF)extreme gradient boosting machine (XGB)RS-RG data processing
钢铁工业中烧结是将铁矿石、熔剂和燃料按一定比例混合,然后在烧结机上加入适量的水和烧结矿[1].铁矿石烧结一般包括配料、混合、点火、破碎、冷却、筛分六个步骤,其中混合部分包括一次混合和二次混合,如果混合料水分不在适宜范围内,将严重影响后序步骤正常进行,严重降低生产效益.在实际工业生产中,往往会在第一次混合前就加入了足够的水,在二次混合时,加入水蒸气补充少量水分,同时预热物料,强化烧结过程.因此,只要精确预测第一次混合后的水分值,就能提前控制加水量,进而使一混后的混合料水分值控制在适宜的范围内,提高生产效率.
近年来,人们对烧结过程进行了大量研究[2-4].文献[2]提出了一种利用神经网络进行水分控制的模型,用于在线识别两个难以测量的参数.文献[3]通过神经网络PID控制器一定程度上解决了水分控制中存在的滞后问题.文献[4]通过引入非线性递归神经网络(NARX),一定程度上解决了水分控制中存在的多变量、非线性的问题.然而,这些方法存在着一些主要缺陷,包括模型可解释性的丧失,以及有限的泛化能力.
集成方法由于易于实现而被广泛用于预测应用中[5-8].文献[5]将支持向量机(SVM) 叠加泛化模型引入石油工业改进了储层特征的预测.文献[6]提出了一种叠加泛化LGBM-XGB-MLP集成模型用于短期负荷预测.文献[7]将基于叠加的集成模型用于犯罪预测.文献[8]提出了一种基于二次分解、PSR和IMVO-ELM的短期风速预测混合模型.以上研究结果均证明叠加模型的性能优于单基准模型.
本文首次探索了一种在LGBM,RF和XGB三种集成模型之间的叠加泛化方法,即叠加LGBM-RF-XGB混合模型,用于烧结水分预测.通过查阅文献,并没有任何烧结水分预测工作涉及这种体系结构.本文的主要贡献如下:
1) 提出了一种新的叠加LGBM-RF-XGB模型,以提高整体回归性能.并且采用Bagging[9](RF) 和Boosting[9](LGBM,XGB) 两种类型的集成模型,均衡方差和偏差,克服了树模型易过拟合的缺陷.使用元数据增强了其训练性能,以产生更高质量的预测结果.
2) 探索开发了一种新的烧结混合料水分预测技术.现有的研究大都采用不易解释的神经网络模型(如BP神经网络和NARX等)或者一些单一的回归性能差的模型(如SVM等).然而,在先前研究中,在一个框架中混合多种不同类型的集成模型并没有得到重视.
3) 以前的研究主要集中在调节模型参数,来提高模型性能.本文引入了一种适合烧结水分数据的标准化方法,很大程度上提高了模型的精度.
4) 使用工厂实时监控的真实数据对所提出的技术进行了评估.为了证明所提出的叠加LGBM-RF-XGB模型的高性能,进行了6个基准模型的对比研究.
1 RS-RG数据处理算法1.1 Robust Scaler (RS) 算法由于烧结水分数据中具有大量异常值,用RS算法处理后可以控制异常值的影响,进而提高模型的精度和泛化性能.RS算法使用对异常值具有鲁棒性的统计数据来缩放特征.这个缩放器移除中位数,并根据分位数范围(默认为IQR:四分位数范围)来缩放数据.通过计算训练集中样本的相关统计信息,对每个特征分别进行定心和缩放.存储中位数和四分位间距,以便变换方法在新的数据上使用.RS算法的计算方法如下:
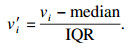 | (1) |
1.2 Rank Gauss (RG) 算法由于大部分烧结水分数据变量的值都集中在一个小范围内,聚集性程度高并且不符合正态分布,不利于机器学习模型的训练.RG算法可以将数据值的排序状态保存下来,这样就可以将聚集信息分散,并且可以将数据转换为高斯分布.
RG算法是一种变量处理方法.RG算法第一步是去分配一个线性等分向量给排序的特征从0到1,然后应用误差函数的反函数(Erfinv函数)去使变量符合高斯分布,最后减去均值.其中误差函数(error function) 定义为
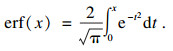 | (2) |
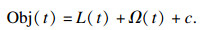 | (3) |
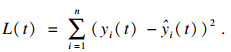 | (4) |
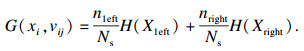 | (5) |
 | (6) |
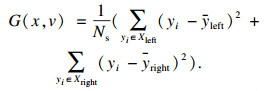 | (7) |
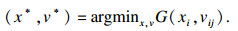 | (8) |
2.3 XGB模型XGB模型是预测问题中最常用的算法之一.XGB包含一个决策树集合,以构建强大的回归器.这种大规模的机器学习方法易于自动应用多线程并行,以加快执行时间[15].与GBDT模型不同的是,XGB采用损失函数的二阶泰勒展开.另外,代表树深度和叶节点权重的正则化项是XGB目标函数的一部分.因此,降低了模型的方差,使模型更加简单且有助于防止过拟合.为了降低模型的复杂度,提出了一种基于层次的Level-wise决策树增长算法.XGB和LGBM有着共同形式的目标函数.XGB模型的损失函数为[15]
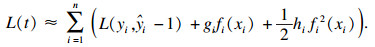 | (9) |
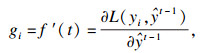 | (10) |
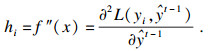 | (11) |
图 1(Fig. 1)
 | 图 1 叠加泛化方法的图形表示Fig.1 Graphical representation of the stacked generalization method |
详细的烧结水分预测模型如图 2所示.模型可以分为4个阶段,即特征工程、对象确定、训练和预测以及评估阶段.在特征工程阶段,将烧结数据进行清洗、特征选择以及根据烧结专业知识构建新的特征等.在对象确定阶段,确定模型的输入输出,进而将数据划分为训练集和测试集.在训练和预测阶段,LGBM和RF在叠加方法的Level 0层进行训练,为XGB元学习模型提供元数据输入,进而训练XGB模型.评估阶段使用点预测评估、误差对比等可视化图形分析预测系统的性能.
图 2(Fig. 2)
 | 图 2 叠加LGBM-RF-XGB方法的流程图Fig.2 Flowchart of the stacked LGBM-RF-XGB method |
3 实验仿真与分析讨论3.1 数据预处理为了对烧结混合料水分值进行预测,建立水分预测模型,需要将每一种物料的配料量、混合料加水量以及水分测量值等相关实验数据进行采集.
数据已预先在2021年3月从某炼铁厂烧结分厂烧结机混合料工艺现场采集完毕,每5 s进行一次采样,采集近三天的数据,共采集了51 759个样本.此配料车间有19个物料配料仓,每一个仓沿着传送带一线排开.物料量、水分测量值的数据见表 1.
表 1(Table 1)
| 表 1 物料量和水分测量记录 Table 1 Material quantity and measured moisture recording |
对于从现场采集完的“脏”数据不能立即用为模型训练的样本,而应该进行数据探索性分析后,进行数据预处理.
数据的预处理有如下几个步骤:
1) 数据延时校正.在配料阶段,各料仓与一次混合机的距离不同,即各种物料到达一混的时间不同,因此在同一个时间点上测得的每种物料的质量不属于同一次加水过程,需要对数据进行对齐处理以保证得到的每一组数据是同一次加水过程.
2) 删除异常值.样本中存在变量值小于零的点,将这样不符合实际的样本删除.由于RS算法对于异常值具有鲁棒性,并未进行其他异常值删除.
3) 特征合并.将相同料的仓进行合并,如将1#,2#,3#和4#料仓进行合并,得到混匀矿总和特征.
4) 数据标准化.采用本文提出的RS-RG数据处理算法进行烧结数据标准化.
3.2 模型性能评估标准在本文中,为了评估阶段的完整性和可靠性,评估标准采用了分数评估、点预测评估和误差评估三种方法.分数评估方法中使用的分数指标包括即决定系数(R2)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE) 以及最大误差(ME).使用Scikit-learn计算误差度量[17],其参数方程如下:
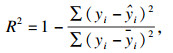 | (12) |
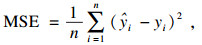 | (13) |
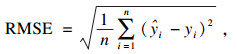 | (14) |
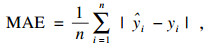 | (15) |
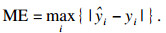 | (16) |
3.3 仿真结果对比分析对模型进行性能评估.此模型采用Python编程语言实现.模型设计中包含了Scikit-learn,lightGBM,XGBoost和mlxtend等Python软件包,其中mlxtend软件包用来构建叠加泛化.为了评估所提出的叠加方法和数据处理算法的有效性,将其与单个模型和未进行RS-RG处理训练的模型进行了比较,特别是XGB,LGBM和RF.另外也将常用的BPNN和SVM模型加入了对比.将数据预处理后的数据90%作为训练集用于训练各个模型,剩余的10%作为测试集用于最终评估模型的性能,其中训练集有45 138组数据,测试集有5 016组数据.表 2显示了各个模型的误差度量结果,图 3进行了可视化结果.其中Stacking代表提出的叠加模型,No Stacking代表未进行RS-RG训练的叠加模型.
表 2(Table 2)
| 表 2 叠加方法及单模型误差度量值 Table 2 Stacked method and single-model error metric values |
图 3(Fig. 3)
 | 图 3 误差度量值对比Fig.3 Comparison of error measures |
由表 2和图 3可以看出,所提叠加模型的RMSE(0.165),MSE(0.027),MAE(0.128)和ME(0.628) 均取得了最小值,R2(0.851) 也取得了最大值,并且相对于未进行RS-RG数据处理训练的模型精度提高了近20%,表明所提出的叠加模型均优于用于对比的基准模型,并且提出的RS-RG烧结数据处理算法有效性也得到了证明.如图 4所示,测量值代表烧结水分测量值,其他曲线代表各个模型的预测值,可以看到叠加模型(Stacking) 的预测值更接近测量值.
图 4(Fig. 4)
 | 图 4 水分测量值和模型预测值Fig.4 Moisture measured values and model predicted values |
图 5显示了各个模型的预测值和测量值的差值,即模型误差,可以看到叠加模型的误差相对稳定并且差值接近零值,常用的SVM和BPNN模型的误差波动最大,RF, LGBM和XGB模型次之.可以看出,叠加集成学习模型结合了各个模型的优点,克服了单个模型预测精度低的局限性.因此,可以推断,所提出的叠加技术完全适合烧结水分预测.
图 5(Fig. 5)
 | 图 5 模型预测值和测量值的误差Fig.5 Error between model predictions and measurements |
4 结语本文说明了叠加泛化方法预测计算模型在烧结水分控制过程中的应用.该模型通过结合三种单一方法,即轻量梯度提升机(LGBM)、随机森林(RF)、极端梯度提升机(XGB)模型,引入了烧结数据处理算法,提高了单一模型的准确性.使用烧结现场的真实数据所做的实验仿真证明了叠加LGBM-RF-XGB模型的有效性.接下来的研究将进一步验证模型,并将烧结加水算法与预测模型相结合,实现对实际水分控制过程的实时最优加水控制.
参考文献
| [1] | Loo C E, Wong D J. Fundamental insights into the sintering behaviour of goethitic ore blends[J]. ISIJ International, 2005, 45(4): 459-468. DOI:10.2355/isijinternational.45.459 |
| [2] | Min W, Xu C, She J, et al. Neural-network-based integrated model for predicting burn-through point in lead-zinc sintering process[J]. Journal of Process Control, 2012, 22(5): 925-934. DOI:10.1016/j.jprocont.2012.03.007 |
| [3] | Giri B K, Roy G G. Mathematical modelling of iron ore sintering process using genetic algorithm[J]. Ironmaking & Steelmaking, 2012, 39(1): 59-66. |
| [4] | Jiang Y, Yang N, Yao Q, et al. Real-time moisture control in sintering process using offline-online NARX neural networks[J]. Neurocomputing, 2020, 396: 209-215. DOI:10.1016/j.neucom.2018.07.099 |
| [5] | Anifowose F, Labadin J, Abdulraheem A. Improving the prediction of petroleum reservoir characterization with a stacked generalization ensemble model of support vector machines[J]. Applied Soft Computing, 2015, 26: 483-496. DOI:10.1016/j.asoc.2014.10.017 |
| [6] | Massaoudi M, Refaat S S, Chihi I, et al. A novel stacked generalization ensemble-based hybrid LGBM-XGB-MLP model for short-term load forecasting[J]. Energy, 2021, 214: 118874. DOI:10.1016/j.energy.2020.118874 |
| [7] | Kshatri S S, Singh D, Narain B, et al. An empirical analysis of machine learning algorithms for crime prediction using stacked generalization: an ensemble approach[J]. IEEE Access, 2021, 9: 67488-67500. DOI:10.1109/ACCESS.2021.3075140 |
| [8] | Xia X, Wang X. A novel hybrid model for short-term wind speed forecasting based on twice decomposition, PSR, and IMVO-ELM[J]. Complexity, 2022, 2022: 1-21. |
| [9] | Dietterich T G. An experimental comparison of three methods for constructing ensembles of decision trees: bagging, boosting, and randomization[J]. Machine Learning, 2000, 40(2): 139-157. DOI:10.1023/A:1007607513941 |
| [10] | Ke G L, Meng Q, Finley T, et al. Light GBM: a highly efficient gradient boosting decision tree[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, 2017: 3149-3157. |
| [11] | Ju Y, Sun G, Chen Q, et al. A model combining convolutional neural network and LightGBM algorithm for ultra-short-term wind power forecasting[J]. IEEE Access, 2019, 7: 28309-28318. DOI:10.1109/ACCESS.2019.2901920 |
| [12] | Breiman L. Random forests[J]. Machine Learning, 2001, 45: 5-32. DOI:10.1023/A:1010933404324 |
| [13] | Louppe G. Understanding random forests: from theory to practice[EB/OL]. [2014-07-28]. https://arXivpreprintarXiv:1407.7502. |
| [14] | Criminisi A. Decision forests: a unified framework for classification, regression, density estimation, manifold learning and semi-supervised learning[J]. Foundations & Trends in Computer Graphics & Vision, 2011, 7(2/3): 81-227. |
| [15] | Chen T Q, Guestrin C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, 2016: 785-794. |
| [16] | Wolpert D H. Stacked generalization[J]. Neural Networks, 2017, 5(2): 241-259. |
| [17] | Varoquaux G, Buitinck L, Louppe G, et al. Scikit-learn: machine learning without learning the machinery[J]. GetMobile: Mobile Computing and Communications, 2015, 19(1): 29-33. DOI:10.1145/2786984.2786995 |
