
 , 闫俊伟1, 张力1,2
, 闫俊伟1, 张力1,2 1. 东北大学 航空动力装备振动及控制教育部重点实验室(B类), 辽宁 沈阳 110819;
2. 东北大学秦皇岛分校 控制工程学院, 河北 秦皇岛 066004
收稿日期:2022-08-25
基金项目:国防基础科研项目(JCKY2018110C012); 国家自然科学基金资助项目(51905082)。
作者简介:郝博(1963-), 男, 辽宁沈阳人, 东北大学教授, 博士生导师。
摘要:在智能工业生产中的复杂环境下进行手势识别人机交互, 手势特征受到局部遮挡、强光照、远距离小目标的影响, 导致目标检测识别过程中识别出的手势特征减少, 甚至分类错误.在复杂环境下提高手势识别精准度成为人机交互任务中亟需解决的问题. 本文提出一种具有创新性的Gan-St-YOLOv5模型, 在YOLOv5的基础上生成对抗网络(generative adversarial network, GAN)和Swin Transformer模块, 融入SENet通道注意力机制, 使用Confluence检测框选取算法, 增强模型检测的准确度. 为了验证模型的优越性, 与YOLOv5模型进行对比, 得出Gan-St-YOLOv5在完全可见测试集上mAP_0.5高达96.1 %, 在强光照测试集上mAP_0.5高达92.3 %, 在部分遮挡测试集上mAP_0.5高达86.6 %, 在远距离小目标测试集上准确度高达96.4 %, 均优于YOLOv5目标检测算法, 以较小的效率损失取得了较高精度.
关键词:Gan-St-YOLOv5手势识别局部遮挡强光照远距离小目标
Gesture Recognition in the Complex Environment Based on Gan-St-YOLOv5
HAO Bo1,2, YIN Xing-chao1
, YAN Jun-wei1, ZHANG Li1,2 1. Key Laboratory of Vibration and Control of Aero-Propulsion System of Ministry of Education, Northeastern University, Shenyang 110819, China;
2. School of Control Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
Corresponding author: YIN Xing-chao, E-mail: dayin0206@163.com.
Abstract: During the human-computer interaction of gesture recognition in the complex environment of intelligent industrial production, gesture features are affected by local occlusion, strong illumination and small distant targets, leading to the reduction of gesture features recognized in the process of target detection and recognition, and even classification errors. Given that improving the accuracy of gesture recognition in the complex environment has become an urgent problem to be solved in human-computer interaction tasks, an innovative Gan-St-YOLOv5 model is proposed. On the basis of YOLOv5, GAN and Swin Transformer modules are integrated into SENet channel attention mechanism, and Confluence detection box selection algorithm is used to enhance the accuracy of model detection. In order to verify the superiority of the model, the YOLOv5 model is used for comparison and it is concluded that the mAP_0.5 of Gan-St-YOLOv5 is up to 96.1 % on the fully visible test set, as high as 92.3 % in the intense illumination test set, as high as 86.6 % in the partial occlusion test set, and as high as 96.4 % in the remote small target test set, all of which are superior to the YOLOv5 target detection algorithm and achieve higher accuracy with less efficiency loss.
Key words: Gan-St-YOLOv5gesture recognitionlocal occlusionstrong illuminationremote small target
随智能工业领域的现代化、信息化、网络化发展, 在智能人机交互体系中轻便地传递信息显得尤为重要, 手势识别作为一种人与人之间的交互方式, 具有高效性、自然性、多维性, 通过手势传递信息, 计算机通过图像识别接收信息, 使人和计算机之间的信息传递近似于人与人之间实时的沟通交流, 提高了工业的交互效率.
近年来, 随图像识别算法不断更新迭代, 使人机交互中运用先进图像识别技术的手势识别取得了突破性进展, 精确度、准确度作为手势识别进行人机交互的标准直接影响了人机交互的效率, 在工业生产中, 人机交互的环境可能非常复杂, 其中可能存在遮挡、强光照、远距离小目标等复杂情况, 因此, 想要提高手势识别的精准度和准确度, 需要提高算法在复杂情况下对特征的识别能力.
汤寓麟等[1]提出了YOLOv5结构的DETR-YOLO轻量化模型, 该模型加入了多尺度特征复融合模型, 融入通道注意力机制SENet, 采用加权融合框策略, 强化对重要通道特征的敏感性, 提高了小目标检测能力.安珊等[2]提出一种用于被遮挡特征学习的生成对抗网络模型, 所提模型在PASCAL VOC 2007和KITTI数据集上的所有类标签的平均精确率(mean average precision, mAP)指标均有不同程度上的提高.蔡旻等[3]提出了一种基于条件随机场(conditional random field, CRF)和隐马尔科夫模型(hidden Markov model, HMM)的混合模型的手势识别方法, 通过手势试验验证了HMM建模能力和CRF判别能力的混合模型方法的有效性和准确性, 并对不同的可变性来源具有鲁棒性.Tan等[4]提出了一种融合空间金字塔池(spatial pyramid pooling, SPP)的卷积神经网络(convolutional neural networks-spatial pyramid pooling, CNN-SPP), 使用CNN-SPP进行手势识别, 提供不同大小的输入, SPP可以生成固定长度的特征, 实证结果表明, CNN-SPP优于其他深度学习驱动的实例.Sarma等[5]提出了一种通过两级分割过程和双跟踪系统获得的孤立轨迹手势的手部运动轨迹的方法, 可以消除手势视频中光照变化和遮挡对手势识别的影响. Manmode等[6]提出了一种通过建立肤色模型和基于Haar的AdaBoost分类器自适应增强分类器实现手势的分割和逐帧分析方法, 在常见手势的识别中准确率达98.3 %.
针对智能工业生产中的遮挡、强光照、远距离小目标等复杂环境导致手势识别的手势特征损失进而造成分类失败, 提出了拥有特征恢复和全局感知能力的Gan-St-YOLOv5模型.该模型生成对抗网络(generative adversarial network, GAN), 并结合Swin Transformer和YOLOv5, 通过GAN对特征损失的图片进行重构[7-11], 将重构图片输入到Swin Transformer和YOLOv5结合的模型中进行目标检测, 加入了SENet注意力机制及Confluence检测框选取算法, 提高了特征损失目标、小目标的检测能力和检测框的精准度与准确度, 通过本文模型与YOLOv5对比分析,结果验证了本文在目标检测中的可行性.
1 Gan-St-YOLOv5模型设计Gan-St-YOLOv5由输入图片、Backbone、Neck、Output四个部分组成, 如图 1所示.
图 1(Fig. 1)
 | 图 1 Gan-St-YOLOv5模型Fig.1 Gan-St-YOLOv5 model |
1.1 GAN模块GAN生成对抗网络, 包括Encoder编码器、Deconder解码器及中间层3个部分, 如图 2所示.在Encoder部分, 共有3个卷积层、3个RN-B层, 通过学习被遮挡目标和无遮挡目标之间的区别, 将被遮挡目标的特征进行重构.在中间层, 共有8层残差块(residual block, RB), 每个RB包含2个Dilaconv层和2个RN-L层, 其作用是在不降低特征维度的同时, 起到增加感受野及恢复特征的作用.在Decoder部分, 共有3个卷积层、2个RN-L层, 用于判别输入目标来自于Encoder中被遮挡目标特征重构出来的还原图来自于无遮挡手势目标.Decoder部分的输出为符合检验标准的遮挡还原图片.
图 2(Fig. 2)
 | 图 2 GAN修复模型Fig.2 GAN repair model |
如图 3所示,两种RN层: 基本RN-B层和可学习RN-L层.如图 3a所示, RN-B层首先根据区域掩码将每个通道输入特征分成两个区域:未损坏区域、损坏区域.给定Input feature和Region Mask, 分别对两个区域归一化(regional normalization, RN).二进制区域掩模是从原始修复掩模获得的.对于每个通道、每个区域的仿射变换均有两组可学习的参数β,γ, 然后执行仿射变换.如图 3b所示, RN-L层首先利用输入要素的空间关系来学习检测潜在的损坏区域, 使用最大值池化和平均池化将得到的两个特征图拼接在一起,使用Sigmoid函数,利用特征本身的空间关系得到一个空间响应图. 通过阈值筛选得到二进制区域掩码, 本文采用的阈值为0.8. 通过空间响应图卷积得到两组放射变换需要的参数β,γ, 可得到参数输出区域归一化后的特征重构图片.
图 3(Fig. 3)
 | 图 3 两种RN层的结构图Fig.3 Structure diagram of two RN layers (a)—RN-B层;(b)—RN-L层. |
两种RN层均使用了空间区域归一化.RN与传统的GAN对抗生成网络采用的特征归一化(feature normalization, FN)方法相比, RN避免了均值和方差的偏移.具体如式(1)~式(5)所示.
将目标图像分成K个区域:
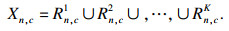 | (1) |
对每一个区域进行区域归一化处理, 得出区域归一化后的像素值:
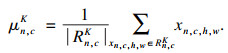 | (2) |
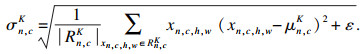 | (3) |
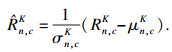 | (4) |
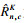
将空间区域归一化后的K个区域图片合并起来:
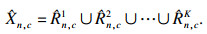 | (5) |
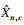
1.2 Swin Transformer模块Swin Transformer模块如图 4所示.
图 4(Fig. 4)
 | 图 4 Swin Transformer模块结构图Fig.4 Swin Transformer module structure diagram |
本文模型共有8层Swin Transformer模块, 每一层由两个连续的Transformer模块组成.在第一个Transformer层中, 通过归一化处理, 经窗口自注意力机制(window self-attention mechanism,WSM)进行特征学习, 输出的图像还需再进行一次层归一化(layer normalizaiton,LN), 经过多层感知(multi-layer perceptron, MLP)选取最合适的权值和偏置, 实现特征转换、信息重组、特征提取.将处理后的特征信息送入第二个Transformer层, 两层Transformer层的不同点在于第二层将第一层的窗口多头注意力(window multi-head self-attention,W-MSA)层换成了滑移窗口多头自注意力(shift window multi-head self-attention, SW-MSA)层.W-MSA层是将图片分成多个窗口, 然后在各个窗口内进行计算, 大大减少了计算量, 但它不具备全局感知能力,从而无法获取窗口之间的特征关系.改进后的SW-MSA层使用了滑动窗口技术, 通过把自注意力计算限制为不重叠的局部窗口, 相对于图像大小具有线性计算复杂性, 对图像进行滑窗, 通过带有步长的滑窗降低分辨率,该技术允许进行跨窗口计算, 使其具有全局感知能力.Swin Transformer模块如式(6)~ 式(9)所示:
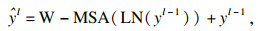 | (6) |
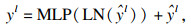 | (7) |
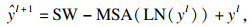 | (8) |
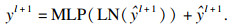 | (9) |
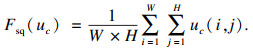 | (10) |
 | 图 5 SENet结构图Fig.5 SENet structure diagram |
式中:W,H为特征图的宽和高;ui(j, k)为第i个以(j, k) 为通道位置的元素。
Excitation是使用2个全连接来实现第一个全连接把通道数从C个压缩成了C/r个用来降低计算量, 后接整流线性激活函数.第二个全连接再让通道数恢复回C个通道数, 后接Sigmoid激活函数, r为压缩比例, 本文采用的降维比例r=16.对每个通道的重要性进行预测, 得到不同通道的重要性大小后再作用到之前的特征图的对应通道上, 获取所有特征图的权重值, 从而让神经网络重点关注那些权重大的特征图, 将不重要的特征减弱, 最终, 空间上所有点信息均会平均成了一个数值, 使用最终的Scale对整个通道进行作用, 从而让提取的特征指向性更强.
1.4 Confluence检测框选取算法传统的目标检测算法在选择最优的预测框时使用非极大值抑制(non-maximum suppression, NMS), NMS虽然可以有效去除单一目标的大部分冗余预测框, 但NMS仅从交并比这一个标准对预测框进行选取, 不具备较好的定位精度, 其在最高得分边界框与另一个较低得分边界框相比不是最优的情况, NMS返回次优边界框.采用Confluence及曼哈顿距离和置信度共同权衡的方式选取最优边界框, 曼哈顿距离MH是两个点之间垂直和水平距离的总和.u=(x1, y1)与v=(x2, y2)之间的MH为
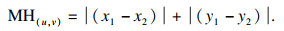 | (11) |
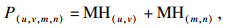 | (12) |
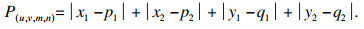 | (13) |
 | 图 6 Confluence示意图Fig.6 Confluence schematic diagram |
WP(u, v, m, n)是在曼哈顿距离的基础上加入置信度倒数作为加权数:
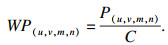 | (14) |
由式(14)可知, WP(u, v, m, n)随曼哈顿值P(u, v, m, n)的增加而增大, 随置信度C增大而减小.通过曼哈顿值和置信度的共同平衡, 当选取一个WP(u, v, m, n)较小的预选框时, 可以很好地在预选框的定位精度和置信度之间权衡, 避免选取次优预选框.
2 试验与分析2.1 数据集与预处理本文使用自制手势数据集, 如图 7所示, 共采集5种手势, 各1 200张, 共6 000张图片.在该数据集的5种手势图片中, 每种手势各取出700张作为训练集、各取300张作为验证集、各取出200张作为测试集.将测试集划分为4类:分别为完全可见测试集、部分遮挡测试集、强光照测试集、远距离小目标测试集.完全可见测试集为不进行任何处理的原测试集, 部分遮挡测试集在原测试集的目标真实标签内进行随机遮挡, 遮挡大小设置为(w/5, h/5), 其中w,h分别为目标真实标签的宽、高, 强光照测试集为强烈光照下采集的5种类型的手势各200张图片, 远距离小目标测试集为使用手势目标尺寸小于32×32像素的5种手势图片, 每种手势各200张.
图 7(Fig. 7)
 | 图 7 5种手势示意图Fig.7 Schematic of the five gestures (a)—手势1;(b)—手势2;(c)—手势3; (d)—手势4;(e)—手势5. |
如图 8所示, 数据集中手势图像主要集中在图片的中央位置, 且大多数为中小尺寸的手势目标, 符合实际状况下的人机交互情况.
图 8(Fig. 8)
 | 图 8 数据集目标分布和尺寸情况Fig.8 Data set target distribution and size (a)—数据集目标分布;(b)—尺寸. |
2.2 试验设置与网络训练试验使用的CPU为Intel(R) Core(TM) i7-12700KF@5.0GHz; GPU为2块NVIDIA GeForce RTX 3080Ti, 并行内存24GB.
模型训练包括两部分:分别为使用GAN的图像还原部分和以YOLOv5为基础框架加入Swin Transformer模块的目标检测部分[12-15].
在图像还原部分中, 使用自制手势数据集进行随机遮挡操作后, 训练对抗生成网络GAN, 分别对其中的Encoder,Decoder及中间层3个部分进行设置.Encoder和中间层采用ReLU作为激活函数, 学习率设置成0.000 1, 使用Adam梯度下降法, Decoder在前几层采用ReLU作为激活函数, 在最后一层使用Tanh作为激活函数, 学习率设置成0.001, 使用随机梯度下降法(stochastic gradient descent, SGD), 随机遮挡手势数据集对GAN进行80 000次迭代.
在目标检测部分中, 使用自制手势数据集训练本文模型, 使用自适应矩估计梯度下降法、固定步长衰减策略进行训练, 初始学习率设置为0.000 1, 训练步数设置为1 200步, 并根据计算机的实际配置设置batch size批次大小为32.采用mixup、图像平移、图像高斯噪点、图像镜像、图像颜色变换、图像模糊处理等数据增强操作, 提高了训练效率和模型的泛化性[16-17].
基于自制手势识别数据集和以上试验配置, 如图 9所示, 对比了YOLOv5和本文模型分别在强光照测试集和遮挡测试集上的训练结果.两种模型分别在强光照、部分遮挡两种测试集下的4种损失情况, 4种损失情况的损失值逐渐下降并趋于稳定.可以看出YOLOv5模型在强光照和部分遮挡的情况下, 损失值下降缓慢, 损失较大.原因是强光照、部分遮挡减少了手部特征, 不利于YOLOv5的目标检测, 本文模型使用GAN对手部特征进行还原, 使用了Swin Transformer和SENet自注意力机制, 增强对检测目标的全局感知能力, 全面捕捉目标的细小特征.本文模型的置信度损失和位置损失最小, 且迅速下降并提前收敛[18-19].
图 9(Fig. 9)
 | 图 9 两种模型的损失值对比Fig.9 Comparison of loss values between two models (a)—置信度的损失值;(b)—位置的损失值. |
本文模型虽然没有设置强光照数据集进行训练, 但由于强光照下手势目标和部分遮挡的手势目标都是相当于去除手部的一些特征.本文模型可以对特征损失的图片进行重构特征, 所以对强光照测试集中的手势目标识别同样有效, 且效果要好于YOLOv5.
由图 10可知,两种模型分别在强光照、部分遮挡测试集下的4种情况下的mAP_0.5:0.95值.由图 10a可知,本文模型在强光照、部分遮挡测试集上的mAP_0.5:0.95值分别达到了0.67,0.64;在YOLOv5上的mAP_0.5:0.95值达到了0.46,0.43;在两种测试集中本文模型的mAP值均高于YOLOv5模型, 且本文模型在650步就已经收敛. 由图 10b可知,本文模型的mAP_0.5值分别达到了0.93,0.88;在YOLOv5的mAP_0.5值分别为0.66,0.59, 在两种数据集中mAP均高于YOLOv5模型.本文模型在训练速度和效率方面远高于YOLOv5模型.
图 10(Fig. 10)
 | 图 10 两种模型mAP值对比Fig.10 Comparison of mAP values between two models (a)—mAP_0.5:0.95; (b)—mAP_0.5. |
为评价模型对远距离小尺寸手势目标的分类检测能力, 采用混淆矩阵的方式进行分类.使用远距离小目标测试集进行分类测试, 根据得出的最终分类结果可得出以下判别: 得出正确判断的真正例记录为TP、得出错误判断的假正例记录为FP、检测结果为背景的假负例记录为FN.根据FP,TP,FN绘制远距离小尺寸手势目标的混淆矩阵, 如图 11所示.
图 11(Fig. 11)
 | 图 11 两种模型测试结果对比分析Fig.11 Comparative analysis of the test results of two models (a)—Gan-St-YOLOv5;(b)—YOLOv5. |
由图 11可知, 本文模型在远距离小目标测试集中的准确度达到了96.4 %, YOLOv5准确度为77.9 %.本文模型精确度高于YOLOv5模型.由于远距离手势目标在图像中占比较小, 识别出来的手势特征置信度较低, 识别起来有一定难度.Gan-St-YOLOv5的全局感知能力可以让其更好地捕捉这些远距离小目标手势的特征并进行精准分类.
2.3 检测效果与性能评估图 12为第5,第11,第17,第23,第31层卷积中的池化特征图, 从图中可以看出初始层正在学习识别形状和边缘等低级特征.在随后的图层中, 网络会尝试接触越来越多的模糊图案, 如手部纹路、手势变化、肤色等特征.从开始的全局手势特征到后来的部分手势特征, 最终模型根据不同的池化特征图进行分类, 不同的池化特征将会导致模型得出不同的分类结果, 输入图片的特征变化可以反映在每一层的特征图上, 池化特征上细微的变化都会对分类结果造成影响.
图 12(Fig. 12)
 | 图 12 卷积层中池化特征变化图Fig.12 Diagram of pooling characteristics in the convolution layer |
部分遮挡特征的学习效果如图 13所示,图 13a为输入到本文模型中的部分遮挡的手势图片.图 13b~图 13d为部分遮挡、完全可见、恢复后的部分遮挡池化特征.其中, 矩形框为进行部分遮挡位置的特征, 不同亮度代表不同的特征值, 展示了模型在自制数据集上对部分遮挡特征的还原前后的池化层学习效果.池化特征的变化也反映了输入图像的特征变化, 完全可见池化特征接近于恢复后的部分遮挡池化特征, 证明GAN生成对抗网络对被遮挡部分的特征有很高的重构能力.
图 13(Fig. 13)
 | 图 13 部分遮挡特征的学习效果Fig.13 Learning effect of partial occlusion features (a)—部分遮挡的图片;(b)—部分遮挡池化特征;(c)—完全可见池化特征;(d)—恢复后的部分遮挡池化特征. |
加入SENet后的可视化热力图如图 14所示,在可视化热力图中,图像中区域越偏黑表示该区域的权重值越大.模型会重点考虑权重大的区域, 减弱权重小的区域的影响, 可以看出加入了SENet通道注意力机制后, 高权重区域集中在手指、关节等部位, 这些部位具有高识别度, 易于作出对手势类型的判断.
图 14(Fig. 14)
 | 图 14 加入SENet前后可视化热力图对比Fig.14 Visual thermal map comparison before and after adding SENet (a)—加入SENet后的可视化热力图;(b)—未加入SENet的可视化热力图. |
对训练完成后模型的检测性能进行总体评估, 将YOLOv5和本文模型在测试集上进行检测, 使用mAP_0.5,mAP_0.5:0.95和每秒检测帧数作为检测指标, 评估模型检测精度和效率; 2种模型在完全可见测试集、部分测试集、强光照测试集上具体的检测量化结果如表 1所示.
表 1(Table 1)
| 表 1 2种目标检测模型在3种测试集上的检测结果对比 Table 1 Comparison of detection results of two target detection models on three test sets |
本文模型在所有测试集上的mAP均高于YOLOv5, 但其在进行目标检测时的帧数均低于YOLOv5.本文模型以少量运行速度作为代价取得了较好的精准度.
上文测试了完全可见、强光照、部分遮挡测试集的检测性能, 为探究本文模型在强光照、部分遮挡时的检测性能, 对完全可见、强光照、部分遮挡的混合测试集进行测试.在混合测试集中, 创建多组不同比例的混合测试集.其中, 每一组的强光照、部分遮挡手势图片占比分别以5 % 的比例进行增长.测试集其余部分为完全可见的手势图片, 分别进行训练, 求取不同混合测试集的mAP值.如图 15所示, 测试结果表明在强光照测试集图片数达到15 %, 遮挡测试集图片数达到10 %.混合测试集的mAP_0.5:0.95值最大达到了65.9 %, 仅次于完全无遮挡测试集下mAP_0.5:0.95的66.1 %.强光照测试集和遮挡测试集图片均在30 % 以内时, 混合测试集的mAP_0.5:0.95值高于60 %, 证明本文模型在面对强光照和部分遮挡共同干扰的情况下, 仍然具备较高的精确度.
图 15(Fig. 15)
 | 图 15 两种目标检测模型在混合测试集中的检测结果Fig.15 Detection results of the two target detection models in the mixed test set |
为验证GAN和SENet等策略的有效性,同样以mAP_0.5/ % 值和帧数为评估指标,采用控制变量法对比分析各个策略对模型检测性能的影响,实验结果如表 2所示.
表 2(Table 2)
| 表 2 不同搭配的检测效果对比 Table 2 Comparison of detection effect of different collocation |
由组别1和组别2可知, SENet自注意力机制的加入, 使mAP值提高了3.3 %, 证明SENet有利于模型对特征的学习,帧数下降了9帧, 说明新加入的模型结构加大了模型的计算时间,由组别1和组别3可知, Swin Transformer的融入, 使mAP值提高了6.9 %.由组别1和组别4可知, 两种模块的共同作用使mAP提高了13.7 %, 说明两种模型叠加在一起对本文模型精准度有很大提高.
为了测试模型对远距离小目标手势的检测效果, 使用工厂车间实际工况下实时采集的5种远距离小目标手势各200张, 测试本文模型, 得到模型的混淆矩阵.通过混淆矩阵计算准确率(ACC)、精准度(Precision)、召回率(Recall)和F1值等模型综合评价指标.针对本文自建特征数据集, ACC用于衡量两种模型对远距离小目标识别的总体精度; Precision和Recall用于权衡模型对于各手势类型的预测精度; 使用F1值综合评价模型的预测精度, F1值越大说明模型预测精度越高.各个评价指标的计算过程如式(15)~式(18)所示:
 | (15) |
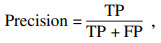 | (16) |
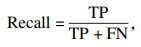 | (17) |
 | (18) |
图 16(Fig. 16)
 | 图 16 远距离小目标手势的检测效果Fig.16 Detection effect of remote small target gesture |
为了进一步验证预测模型的检测性能, 混淆矩阵结果计算出手势识别下的精准度、召回率和F1值等性能评价指标,结果如表 3所示.
表 3(Table 3)
| 表 3 远距离小目标在预测模型中的性能评价表 Table 3 Performance evaluation table of long-range small target in prediction model |
由表 3可知,5种手势的精准度都很高, 且模型对于手势1~手势5的F1值大于0.94, 证明本文模型对5种手势的预测效果均具有很高的精确度.
3 结论1) 采用以YOLOv5为基础框架加入了GAN和Swin Transformer模块的Gan-St-YOLOv5模型, 融入SENet通道注意力机制, 使用Confluence检测框选取算法, 提升了模型的检测效果. 在完全可见测试集上mAP_0.5高达96.1 %, 在部分遮挡测试集上mAP_0.5达到了86.6 %, 在强光照测试集上mAP_0.5达到了92.3 %, 在远距离小目标测试集上准确度达到了96.4 %, 在实际工况下远距离小目标检测的准确度为93.5 %, 两者差距较小, 说明模型具有较好的泛化性.
2) 本文模型虽然损失了一定的YOLOv5原有检测速度, 但在部分遮挡、强光照、远距离小目标下的识别精确度、准确度远远高于YOLOv5模型.
参考文献
| [1] | 汤寓麟, 李厚朴, 张卫东, 等. 侧扫声纳检测沉船目标的轻量化DETR-YOLO法[J/OL]. 系统工程与电子技术. [2022-04-06]. http://kns.cnki.net/kcms/detail/11.2422.TN.20211224.1538.010.html. (Tang Yu-lin, Li Hou-pu, Zhang Wei-dong, et al. A lightweight DETR-YOLO method for detecting shipwreck targets with side-scan sonar[J/OL]. Systems Engineering and Electronics. [2022-04-06]. http://kns.cnki.net/kcms/detail/11.2422.TN.20211224.1538.010.html. ) |
| [2] | 安珊, 林树宽, 乔建忠, 等. 基于生成对抗网络学习被遮挡特征的目标检测方法[J]. 控制与决策, 2021, 36(5): 1199-1205. (An Shan, Lin Shu-kuan, Qiao Jian-zhong, et al. Object detection method based on generated adversarial network learning obscured feature[J]. Control and Decision, 2021, 36(5): 1199-1205.) |
| [3] | 蔡旻, 高涵文, 李华一, 等. 基于CRF和HMM混合模型的手势识别方法[J]. 计算机应用与软件, 2021, 38(11): 162-166. (Cai Min, Gao Han-wen, Li Hua-yi, et al. Gesture recognition method based on hybrid model CRF and HMM[J]. Computer Applications and Software, 2021, 38(11): 162-166. DOI:10.3969/j.issn.1000-386x.2021.11.025) |
| [4] | Tan Y S, Lim K M, Tee C, et al. Convolutional neural network with spatial pyramid pooling for hand gesture recognition[J]. Neural Computing and Applications, 2021, 33(10): 5339-5351. DOI:10.1007/s00521-020-05337-0 |
| [5] | Sarma D, Bhuyan M K. Hand detection by two-level segmentation with double-tracking and gesture recognition using deep-features[J]. Sensing and Imaging, 2022, 23(1): 1-29. DOI:10.1007/s11220-021-00371-1 |
| [6] | Manmode P, Saha R, Amnerkar M N. Real-time hand gesture recognition[J]. International Journal of Scientific Research in Computer Science Engineering and Information Technology, 2021, 35(9): 618-624. |
| [7] | Yu T, Guo Z, Jin X, et al. Region normalization for image inpainting[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Chongqing, 2020: 12733-12740. |
| [8] | Shepley A, Falzon G, Kwan P. Confluence: a robust non-IoU alternative to non-maxima suppression in object detection[J]. ArXiv Preprint ArXiv. https://blog.csdn.net/chrisitian666/article/details/111759945. |
| [9] | Liu Z, Lin Y, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, 2021: 10012-10022. |
| [10] | Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 2011-2023. |
| [11] | 刘邵凡. 基于对抗学习的多域自适应目标检测方法研究[D]. 合肥: 合肥工业大学, 2021. (Liu Shao-fan. Multiple domain adaptive target detection based on against learning method research[D]. Hefei: Hefei University of Technology, 2021. ) |
| [12] | 王德兴, 王越, 袁红春. 基于Inception-Residual和生成对抗网络的水下图像增强[J]. 液晶与显示, 2021, 36(11): 1474-1485. (Wang De-xing, Wang Yue, Yuan Hong-chun. Underwater image enhancement based on inception-residual and generated antagonistic network[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(11): 1474-1485. DOI:10.37188/CJLCD.2021-0058) |
| [13] | 万晓丹. 基于对抗网络与卷积神经网络的目标检测方法[J]. 计算机应用与软件, 2021, 38(1): 192-196. (Wan Xiao-dan. Object detection method based on adversarial network and convolutional neural network[J]. Computer Applications and Software, 2021, 38(1): 192-196. DOI:10.3969/j.issn.1000-386x.2021.01.032) |
| [14] | 孙强, 李一全, 于占江, 等. Inception-ViT模型的微型铣刀磨损状态预测研究[J]. 工具技术, 2022, 56(1): 13-21. (Sun Qiang, Li Yi-quan, Yu Zhan-jiang, et al. Research on micro milling cutter wear state prediction based on Inception-ViT model[J]. Journal of Tool Technology, 2022, 56(1): 13-21.) |
| [15] | 苏晋鹏. 基于超特征金字塔与对抗学习的目标检测算法研究[D]. 南京: 南京邮电大学, 2019. (Su Jin-peng. Based on the characteristics of super pyramid and confrontation study target detection algorithm research[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2019. ) |
| [16] | 任仲乐. 基于数据驱动的遥感目标检测与地物分类[D]. 西安: 西安电子科技大学, 2020. (Ren Zhong-le. Remote sensing target detection based on data driven and feature classification[D]. Xi'an: Xi'an University of Electronic Science and Technology, 2020. ) |
| [17] | 杨潇宇, 汪西莉. 结合多尺度注意力和边缘监督的遥感图像建筑物分割模型[J]. 激光与光电子学进展, 2022, 59(22): 335-344. (Yang Xiao-yu, Wang Xi-li. Building segmentation model of remote sensing image combining multi-scale attention and edge supervision[J]. Laser & Optoelectronics Progress, 2022, 59(22): 335-344.) |
| [18] | 康健, 王智睿, 祝若鑫, 等. 基于监督对比学习正则化的高分辨率SAR图像建筑物提取方法[J]. 雷达学报, 2022, 11(1): 157-167. (Kang Jian, Wang Zhi-rui, Zhu Ruo-xin, et al. Building extraction method of high resolution SAR image based on supervised contrast learning regularization[J]. Chinese Journal of Radar, 2022, 11(1): 157-167.) |
| [19] | 舒朗. 基于强化学习的目标检测算法研究[D]. 杭州: 杭州电子科技大学, 2018. (Shu Lang. Research on object detection algorithm based on reinforcement learning[D]. Hangzhou: Hangzhou Dianzi University, 2018. ) |
