
 , ХФ·еУн, іВиЙ
, ХФ·еУн, іВиЙ ¶«ұұҙуС§ »ъЖчИЛҝЖС§Ул№ӨіМС§ФәЈ¬БЙДю ЙтСф 110169
КХёеИХЖЪЈә2022-03-15
»щҪрПоДҝЈә№ъјТЧФИ»ҝЖС§»щҪрЧКЦъПоДҝ(U20A20197); БЙДюКЎЦШөгСР·ўјЖ»®ПоДҝ(2020JH2/10100040)ЎЈ
ЧчХЯјтҪйЈәҪӘСо(1982-), ДР, БЙДюЙтСфИЛ, ¶«ұұҙуС§ёұҪМКЪЎЈ
ХӘТӘЈәОӘМбёЯ¶аОпМеЧҘИЎјмІвНшВзөДЧҘИЎјмІвЧјИ·ВКЈ¬МбіцТ»ЦЦ»щУЪёДҪшCascade R-CNNДЈРНөД»ъРөұЫЧҘИЎјмІвЛг·Ё.КЧПИЈ¬ТэИлResNeXtҪб№№ДЬ№»ФЪІ»јУҙуНшВзЙијЖДС¶ИөДЗ°МбПВМбёЯБЛДЈРНөДЧјИ·ВКЈ»ТэИлҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝйТФҪвҫц·ЦұжВКҪПөНөДОКМвЈ»ҪУЧЕ¶ФЧҘИЎҝт»Ш№й·ЦЦ§әНҪЗ¶И·ЦАа·ЦЦ§ТФ·ЦЦО·Ҫ·ЁҪшРРУЕ»Ҝ.ЖдҙОЈ¬Хл¶Ф¶аОпМеЧҘИЎКэҫЭјҜИұ·ҰөДОКМвЈ¬№№ҪЁ¶аДҝұкЧҘИЎКэҫЭјҜ(multi-object grasping datasetЈ¬MOGD)Ј¬УРР§өША©ідБЛ¶аОпМеЧҘИЎјмІвКэҫЭјҜ.Чоә󣬻щУЪёДҪшCascade R-CNNДЈРНЙијЖЧҘИЎјмІвНшВзЈ¬КөСйҪб№ыұнГчЈ¬ёДҪшәуөДЛг·ЁР§ВКёьёЯЈ¬PI-Cascade R-CNNКөСйЧјИ·ВКОӘ93%Ј¬ҪПCascade R-CNNМбЙэ1.5ёц°Щ·Цөг.
№ШјьҙКЈәЧҘИЎјмІвҝХ¶ҙҫн»эCascade R-CNN¶аОпМејмІв»ъЖчИЛЧҘИЎ
Research on Robotic Grasping Detection Based on Improved Cascade R-CNN Model
JIANG Yang
, ZHAO Feng-yu, CHEN Xiao School of Robotics & Engineering, Northeastern University, Shenyang 110169, China
Corresponding author: JIANG Yang, E-mail: beyond821015@163.com.
Abstract: In order to improve the grasping detection accuracy of the multi-object grasping detection network, a robotic arm grasping detection algorithm based on the improved Cascade R-CNN model is proposed. Firstly, the introduction of the ResNeXt structure can improve the accuracy of the model without increasing the difficulty of network design. The atrous spatial pyramid pooling module is introduced to solve the problem of low resolution. Then, the grasping box regression branch and the angle classification branch are optimized by the divide and conquer method. Secondly, aiming at the lack of multi-object grasping datasets, a multi-object grasping dataset (MOGD) is constructed, which effectively expands the multi-object grasping detection dataset. Finally, a grasping detection network is designed based on the improved Cascade R-CNN model. The experimental results show that the improved algorithm is more efficient. The experimental accuracy of the PI-Cascade R-CNN is 93 %, which is 1.5 percentage higher than that of the Cascade R-CNN.
Key words: grasping detectionatrous convolutionCascade R-CNNmulti-object detectionrobotic grasping
»щУЪКУҫхөД»ъЖчИЛЧҘИЎјјКхТСҫӯіЙОӘөұЗ°»ъЖчИЛРРТөСРҫҝөДЦШөг·ҪПтЈ¬№г·әУҰУГУЪЧ°ЕдЎў·ЦјрәНВл¶вөИУҰУГіЎҫ°.ЧҘИЎјмІвКЗЦёНЁ№эКУҫхҙ«ёРЖч»сИЎРЕПўЈ¬ҫ«И·ЎўҝмЛЩөШјмІвіцДҝұкОпМеөДЧҘИЎҝтРЕПўЈ¬И»әу»ъЖчИЛНЁ№эЧҘИЎҝтХТөҪЧҘИЎөДЦРРДО»ЦГАҙЧҘИЎДҝұкОпМе.
»¬¶Ҝҙ°ҝЪјмІв·ЁіЈУГУЪәтСЎЗшУтөДЙъіЙ[1-3].ЖдҫЯМеІЩЧчКЗК№УГ»¬¶Ҝҙ°ҝЪ·Ҫ·ЁҙУ1·щНјПсЦРМбИЎ¶аёцНјПсҝйЈ¬И»әуТАҙОКдИлЙо¶ИЙсҫӯНшВзАҙФӨІвГҝёцНјПсҝйөДЧҘИЎЧЛМ¬.ЧоәуЈ¬СЎИЎјмІвЦГРЕ¶ИЧоёЯөДФӨІвЧҘИЎО»ЧЛАҙНкіЙЧҘИЎјмІв[4].
УГУЪёРЦӘ»ъЖчИЛЧҘИЎ»·ҫіөДҙ«ёРЖчНЁіЈКЗRGBПа»ъЈ¬Жд№ШјьИООсКЗ»сИЎ»·ҫіөД¶юО¬НјПсРЕПўЈ¬И»әуНЁ№эЧҘИЎјмІвЛг·Ё·ЦОцјЖЛгөГіц»·ҫіДҝұкФЪНјПсҝХјдЦРөДЧҘИЎРЕПўЈ¬ІўҪ«НјПсҝХјдЦРөДЧҘИЎО»ЦГУіЙдөҪ»ъРөұЫПВөДХжКөЧшұкЦРЈ¬УЙУЪәуРшЧҘИЎ№эіМКЗ·сіЙ№ҰИЎҫцУЪҙЛІҪЦиЦРјЖЛгіцөДЧшұкЈ¬ТтҙЛХвТ»ІҪКЗЦҙРРЧҘИЎИООсөД№ШјьІҪЦи.ЧоәуЈ¬Ҫ«јЖЛгіцөДХжКөЧшұкЧӘ»»ОӘ»ъЖчИЛКЦұЫД©¶ЛјРЧҰөДО»ЦГәНЧЛМ¬Ј¬ТФөЦҙпДҝұкЧҘИЎО»ЦГНкіЙ»ъЖчИЛЧҘИЎ№ӨЧч[5-9].ЙПКцОДПЧ¶аКЗ»щУЪҝөДО¶ыКэҫЭјҜҪшРРөҘДҝұкЧҘИЎјмІв.ОДПЧ[10-11]өДСРҫҝТІҙу¶ајҜЦРУЪөҘДҝұкНјПсЧҘИЎО»ЧЛФӨІвЈ¬Иұ·Ұ¶Ф¶аДҝұкіЎҫ°өДҝјВЗ.
ОДПЧ[12-16]СРҫҝБЛ№ШУЪЙо¶ИС§П°ЛщҫЯұёөДЧФЦчС§П°НјПсМШХчөДДЬБҰ.ОДПЧ[17-19]ЦчТӘКЗ№ШУЪДҝұкјмІв·ҪГжөДСРҫҝЈ¬¶јИЎөГБЛРн¶аН»іціЙ№ы.LenzөИ[1]ҪшРРБЛТ»По№ӨЧчБҝҫЮҙуөДЙо¶ИЧҘИЎјмІв№ӨЧчЈәҪ«ЙъіЙөДРн¶аҙуРЎЎўО»ЦГәН·ҪО»І»Н¬өДҫШРОәтСЎКдИлөҪҫн»эЙсҫӯНшВзЦРҪшРР·ЦАаЖА№АЈ¬ИЎЖдЦРөГ·ЦЧоёЯөДәтСЎЧчОӘЧоЦХЧҘИЎјмІвҪб№ы.И»¶шЖдИұөгФЪУЪЈ¬К№УГИзҙЛ¶аөДНјПсҝйАҙФӨІвЧҘИЎЧЛКЖөД»¬¶Ҝҙ°ҝЪјмІв·ЁКЗ·ЗіЈәДКұ.ОӘБЛМбёЯЧҘИЎјмІвЛЩ¶ИЈ¬RedmonәНAngelovaІЙУГБЛТ»ЦЦК№НјПсТ»ҙОРФНЁ№эНшВзөДөҘј¶»Ш№й·Ҫ·ЁАҙЦұҪУФӨІвЧҘИЎ°ьО§әР[20].
ParkөИ[21]МбіцБЛТ»ЦЦНшВзЈ¬КЧПИНшВз¶ФҫЯУРТ»¶ЁО»ЦГәН·ҪПтөДНјПсҝйҪшРРІГјфЈ¬И»әуЛНИлЧҘИЎ·ЦАаЖчҪшРРЧҘИЎҝЙРЕ¶ИЕР¶П.ЧоәуЈ¬АыУГЧоҙујҜәПСЎФсЧојСЧҘИЎЧЛКЖ.AsifөИ[22]ІЙУГДҝұкјмІв·Ҫ·ЁФӨІвДҝұк¶ФПуөДО»ЧЛЈ¬Ҫш¶ш№АјЖіцГҝёцНјПсЦРОпМеөДЧҘИЎЧЛМ¬.ХвР©№ӨЧчҝЙТФФӨІвФУВТіЎҫ°ЦРОпМеөДЧЛМ¬.
1 Cascade R-CNN»щУЪЙо¶ИС§П°өДДҝұкјмІвЛг·ЁіЈ·ЦОӘТ»ҪЧ¶ОЛг·ЁәН¶юҪЧ¶ОЛг·ЁЈ¬ҙжФЪ3ЦЦҙъұнРФөДҫн»эЙсҫӯНшВзөДДҝұкјмІвЛг·ЁЈ¬·ЦұрКЗR-CNN[17]Ј¬Fast R-CNN[18]әНFaster R-CNN[19].Fast R-CNN[18]Ҫ«МбИЎДҝұкөД·Ҫ·ЁМж»»іЙНшВзСөБ·АҙМбИЎЈ¬јмІвЛЩ¶ИұИЦ®З°ҙу·щМбЙэ.
Faster R-CNNЦРК№УГIoU(intersection over union)гРЦөЗш·ЦІ»Н¬өДanchorАҙЙъіЙProposalЈ¬Т»°гИЎ0.5Зш·ЦЗ°ҫ°әНұіҫ°Ј¬Из№ыIoUгРЦөСЎИЎҪПёЯЈ¬»бөјЦВДЈРН№эДвәПЈ¬ІўЗТІЙУГөҘТ»гРЦөЈ¬ТІ»біцПЦІ»ЖҘЕдөДОКМвЈ¬гРЦөФҪёЯЈ¬ёГОКМвФҪГчПФЈ»ФЪІ»Н¬өДIoUгРЦөМфСЎProposalКұЈ¬ФҪҪУҪьёГгРЦөөДProposalФЪ»Ш№йЦ®әуЖдIoUгРЦөФҪҙуЈ¬јҙProposalөДЦКБҝ»бФҪёЯ.
ј¶БӘКҪНшВзCascade R-CNNДЬҪвҫцјмІвЖчІ»ДЬЧјИ·өШҪ«јмІвҝтУлДҝұкОпМеЖҘЕдЈ¬өјЦВВ©јм»тОујмЈ¬ҙУ¶шҪөөНјмІвҪб№ыөДЧјИ·ВКөДОКМв[23]Ј¬УЙFaster R-CNNөЪТ»ҪЧ¶ОRPN(region proposal network)МṩөНЦКБҝProposalёшПВТ»Іг»Ш№йНшВзЈ¬УЙУЪIoUЖХұйҪПРЎЈ¬ЛщТФІЙУГөНгРЦөёь·ыәПProposalөД·ЦІјЈ¬·ў»УёГҪЧ¶ОДЈРНөДРФДЬЈ¬МṩёЯЦКБҝөДProposalёшПВТ»ҪЧ¶ОЈ¬Cascade R-CNN¶ФГҝёцҪЧ¶ОөДIoUҪшРРУЕ»Ҝ[23].ёГ·Ҫ·ЁТІПФЦшјхЙЩБЛјЖЛгКұјдЈ¬МбёЯБЛјмІвҫ«¶И.ҝјВЗөҪХвР©УЕөгЈ¬ұҫОДҪ«Cascade R-CNNЧчОӘЧҘИЎјмІвөД»щұҫНшВзҝтјЬ.
Хл¶Ф»ъЖчИЛ¶аОпМеЧҘИЎјмІвСРҫҝОКМвЈ¬СЎУГCascade R-CNNОӘ»щҙЎНшВзҝтјЬЈ¬Cascade R-CNNКЗНЁУГДҝұкјмІвЦРұнПЦҪПәГөДТ»ЦЦј¶БӘНшВзЈ¬ЖдМШөгКЗЛЩ¶ИҝмЎўјмІвҫ«¶ИёЯ.ө«КЗЦұҪУК№УГCascade R-CNNұҫЙнөДҝтјЬСөБ·ЧҘИЎКэҫЭјҜІ»ДЬөГөҪәЬәГөДјмІвР§№ыЈ¬ЖдФӯТтЦчТӘ°ьАЁЈә
1) өұЗ°№«ҝӘөД¶аДҝұкЧҘИЎКэҫЭјҜҪПЙЩЈ¬јҙИұЙЩСйЦӨ»ъЖчИЛ¶аОпМеЧҘИЎјмІвөДКэҫЭјҜ.
2) Cascade R-CNNЦРөДД¬ИПі¬ІОКэКЗХл¶ФНЁУГДҝұкјмІвЙијЖөДЈ¬ІўІ»АыУЪЧҘИЎҝтјмІв.
3) Cascade R-CNNөДЦчёЙНшВзІЙУГResNetЈ¬ө«КЗҪшРРЧҘИЎҝтФӨІвРиТӘҪПёЯөДДЈРНЧјИ·ВК.ЛдИ»К№УГResNetНшВзҝЙТФНЁ№эјУЙо»тХЯјУҝнНшВзАҙМбёЯДЈРНөДЧјИ·ВКЈ¬ө«КЗХвСщ»бФміЙНшВзІОКэөДКэБҝФцјУЈ¬ТІ»бФміЙНшВзјЖЛгіЙұҫФцјУ.
4) УЙУЪCascade R-CNNјмІвЖчІҝ·ЦОӘИ«Б¬ҪУІгЈ¬И«Б¬ҪУІгФЪЙсҫӯНшВзЦРЖрөДКЗ·ЦАаЖчөДЧчУГЈ¬ө«КЗ¶Ф»Ш№йЖрІ»өҪәЬәГөД°пЦъ.Cascade R-CNNОӘј¶БӘНшВзЈ¬өұIoUгРЦөОӘ0.5~0.7өДҝтҪшИлөЪИэҪЧ¶ОКұЈ¬»бұ»өұЧчёәСщұҫ(әНұіҫ°ҝтТ»Н¬)ҙҰАнЈ¬ДЗГҙХвР©ҝтөД·ЦКэ»бұ»ҙтөНЈ¬ХвҫНФміЙөЪТ»ҪЧ¶ОәНөЪИэҪЧ¶ОҙҰАнҪб№ыІъЙъҪПҙуІоТмЈ¬іцПЦХэСщұҫРЕПўИұК§ОКМв.
5) УЙУЪЧҘИЎКэҫЭјҜЦРҙжФЪТ»Р©ҪПРЎОпМеЈ¬Cascade R-CNNІ»ДЬВъЧгҪПРЎОпМеөДК¶ұрЈ¬РиТӘУРЧг№»өДёРКЬТ°АҙёІёЗөҪДҝұкОпМе.
Хл¶ФЙПКцОКМвЈ¬ұҫОДөД№ӨЧчДЪИЭИзПВЈә
1) КЧПИ№№ҪЁТ»ёцУЙ32Аа¶ФПуЧйіЙөД¶аДҝұкЧҘИЎКэҫЭјҜ(multi-object grasping datasetЈ¬MOGD), ҪвҫцөұЗ°¶аОпМеЧҘИЎКэҫЭјҜҪПОӘИұ·ҰөДОКМвЈ¬ІўұгУЪ¶Ф¶аДҝұкЧҘИЎјмІвДЈРНҪшРРЖА№А.
2) өчХыФӯКјCascade R-CNNөДКдИліЯҙзЎўёчјмІвІгјмІвөДөчҪЪТФј°ЧҘИЎҝтөДЙъіЙЈ¬К№өГCascade R-CNNёьәГөШУҰУГУЪЧҘИЎјмІв.
3) ТэИлResNeXtҪб№№Ј¬К№НшВзФЪІ»ФцјУІОКэёҙФУ¶ИөДЗ°МбПВАҙМбёЯЧјИ·ВК.
4) Ҫ«ҪЗ¶И·ЦАа·ЦЦ§ТФј°ЧҘИЎҝт»Ш№й·ЦЦ§·ЦЦОКөПЦЈ¬И«Б¬ҪУІгёьККәПУҰУГУЪҪЗ¶И·ЦАаЈ¬ҫн»эІгёьККәПУГУЪЧҘИЎҝт»Ш№йИООс.ІўУГјҜіЙ№ІПнАҙҪвҫцөЪИэҪЧ¶ОIoUгРЦөСЎФсІ»ҫщәвіцПЦөДёәСщұҫОКМвЈ¬ТФМбёЯCascade R-CNNөДЧҘИЎјмІвЧјИ·ВК.
5) јУИлҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»Ҝ(atrous spatial pyramid poolingЈ¬ASPP)ДЈҝйАҙҪвҫц·ЦұжВКөНөДОКМвЈ¬ТФұгМбИЎ¶аіЯ¶ИРЕПў.
ёщҫЭЙПКц№ӨЧчДЪИЭЈ¬¶аОпМеЧҘИЎПөНіЧЬМеҝтјЬИзНј 1ЛщКҫЈ¬°ьАЁКөСйЖҪМЁҙоҪЁЎўЧҘИЎјмІвЎўНшВзөДЛг·ЁУЕ»ҜИэІҝ·Ц.КөСйЖҪМЁ°ьАЁЖҪМЁҙоҪЁЎўКЦСЫұк¶ЁТФј°ЖҪМЁЧҘИЎКөПЦЈ»ЧҘИЎјмІв°ьә¬КэҫЭјҜЦЖЧчЎўКэҫЭФӨҙҰАнәННшВзЛг·ЁУЕ»Ҝ.
Нј 1(Fig. 1)
 | Нј 1 ЧҘИЎПөНіЧЬМеҝтјЬFig.1 Overall framework of grabbing system |
2 PI-Cascade R-CNNДЈРН2.1 PI-Cascade R-CNNЧҘИЎјмІвНшВзЙијЖұҫОДХл¶Ф¶аОпМеЧҘИЎјмІвМбіцТ»ЦЦёДҪшCascade R-CNNөДЧҘИЎјмІвДЈРНЈ¬Ҫ«ёГДЈРНіЖОӘPI-Cascade R-CNNЈ¬ёГДЈРНөДНшВзҪб№№ИзНј 2ЛщКҫ.ФЪCascade R-CNNДҝұкјмІвЛг·Ё»щҙЎЙПЈ¬ұҫОДКЧПИГжПтЧҘИЎјмІвИООс¶ФCascade R-CNNөДі¬ІОКэЙиЦГҪшРРБЛУЕ»ҜЈ¬И»әу·ЦұрТэИлResNeXtҪб№№әНјУИлҙшУРҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝйАҙҪшТ»ІҪМбёЯЧҘИЎҝтјмІвҫ«¶ИЈ¬ІўҪ«ҪЗ¶И·ЦАаТФј°ЧҘИЎҝт»Ш№йөД·ЦЦО·Ҫ·ЁУҰУГөҪЧҘИЎјмІвЦРЈ»ҙЛНв»№ІЙУГјҜіЙ№ІПнУЕ»ҜБЛөЪИэҪЧ¶ОөДIoUгРЦө.
Нј 2(Fig. 2)
 | Нј 2 PI-Cascade R-CNNНшВзҪб№№НјFig.2 Network structure of PI-Cascade R-CNN |
ҫЯМеЙијЖІҪЦиИзПВЈәКЧПИҪ«НјПсКдИлөҪPI-Cascade R-CNNөДМШХчМбИЎНшВзResNeXt[24]ЦРЈ¬И»әуҫӯ№эResNeXtМШХчМбИЎЈ¬Хл¶ФКэҫЭјҜ(MOGD)ЦР°ьә¬РЎДҝұкөДОпМеөДЗйҝцЈ¬јУИлҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»Ҝ(ASPP)ДЈҝй.ҝХ¶ҙҫн»эЧчУГКЗА©ҙуёРКЬТ°ТФј°І¶»с¶аіЯ¶ИРЕПўЈ¬ҝЙТФ»сөГҪПҙуөД·ЦұжВКНјЈ¬¶ФМбЙэРЎДҝұкОпМејмІв°пЦъәЬҙуЈ¬ФЪМШХчИЪәП№эіМ¶ФЗіІгМШХчНјПВІЙСщЈ¬ФЩУлЙоІгМШХчНјҪшРРИЪәПЈ¬ФЪМШХчИЪәПәуГҝТ»ІгКдіцөДМШХчНјҪшРРУЙЙоөҪЗіөД¶аіЯ¶ИМШХчИЪәПЈ¬јхЙЩБЛМШХч¶ӘК§Ј¬¶ФРЎДҝұкОпМеҝЙТФәЬәГөШК¶ұр.ОӘөГөҪЧҘИЎәтСЎҝтЈ¬Ҫ«ИЪәПәуөДМШХчНјКдИлөҪRPN(ЗшУтҪЁТйНшВз).ҫӯRPNөГөҪЧҘИЎәтСЎҝтәуЈ¬ҪшИлМнјУҪЗ¶И·ЦАаТФј°ЧҘИЎҝт»Ш№йөДМШХч№ІПн»ъЦЖөДј¶БӘјмІвЖчЦРЈ¬Т»№І°ьә¬3ёцјмІвЖчЈ¬ГҝёцЦ§В·өДјмІвЖчЦР°ьә¬іШ»Ҝ(Pool)ІгЎўИ«Б¬ҪУІг(FC)ЎўҪЗ¶И·ЦАа(РэЧӘҪЗC)ТФј°ЧҘИЎҝт»Ш№й(B)Ј»НЁ№эPoolІгНіТ»іЯҙзәуҪшРРИЪәПЈ¬И»әуКдИлИ«Б¬ҪУІгҪшРРРэЧӘҪЗЖА№АТФј°ЧҘИЎҝт»Ш№йЈ¬ЧоЦХМбИЎіцЧоУЕЧҘИЎјмІвҝт.
PI-Cascade R-CNNөДНшВзҪб№№ИзНј 2ЛщКҫЈ¬ЖдЦРұҫОДФЪ»Ш№й·ЦЦ§ЦРУГҫн»эМжҙъЦ®З°өДИ«Б¬ҪУІг.НјЦРB0Ј¬B1Ј¬B2ұнКҫәтСЎұЯҪзҝтЈ¬ЧоЦХКдіцөДB3ұнКҫФӨІвЧҘИЎҝтЈ»ұҫОДҪ«»Ш№й·ЦЦ§әН·ЦАа·ЦЦ§өҘ¶АІр·ЦҝӘҙҰАнЈ»ІЙУГјҜіЙ№ІПн¶ФөЪИэҪЧ¶ОIoUгРЦөҪшРРУЕ»Ҝ.
2.2 ResNeXtҪб№№ResNeXtҪб№№ХыәПБЛVGG(visual geometry group)НшВзөД¶СөюЛјПләНInceptionЦРөДІр·Ц-ЧӘ»»-әПІўөДІЯВФ.ResNeXtІЙУГЖҪРР¶СөюПаН¬НШЖЛҪб№№(blocks)Мж»»ФӯАҙResNetөДИэІгҫн»эөДblockЈ¬ҝЙТФМбЙэДЈРНөДЧјИ·ВКЈ¬ө«І»»бГчПФФцјУІОКэБҝј¶Ј¬НШЖЛҪб№№ТІГ»УРәЬҙуёДұдЈ¬І»Ҫці¬ІОКэјхЙЩБЛЈ¬¶шЗТДЈРНөДТЖЦІРФТІМбёЯБЛ[24].
ТтҙЛЈ¬ФЪPI-Cascade R-CNNЦРІЙУГResNeXtМШХчНшВзЈ¬НјПсЦұҪУКдИлөҪResNeXt50МШХчМбИЎНшВзЦРЈ¬НЁ№эҫн»эәЛҪшРРМШХчМбИЎ(МнјУҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝйҪ«ФЪ2.4ҪЪГиКц)Ј¬И»әуResNeXtНшВзёҙЦЖЗіІгНшВзКдіцУлЙоІгНшВзКдіцөДФӘЛШПајУөГөҪПВТ»ІгөДКдіц.
ResNeXtІРІоҪб№№ИзНј 3ЛщКҫЈ¬ОпМеНјПсТФRGBРОКҪКдИлResNeXtНшВзЈ¬КдИлОӘ256О¬Ј¬КЧПИНЁ№э1ЎБ1ҫн»эәЛҪ«КдИлөД256ёцНЁөА·ЦіЙ128ёцНЁөАөДөНО¬ХЕБҝЈ»И»әуСЎФс·ЦЦ§КэДҝОӘ64Ј¬ҫӯ№э3ЎБ3өДҫн»эәЛҪшРРМШХчМбИЎЈ»ЧоәуРиТӘЧӘ»»КэҫЭЈ¬¶ФЛщУРөД·ЦЦ§К№УГ1ЎБ1ҫн»эҪ«КдіцөДНЁөАКэҙУ128О¬ФцјУөҪ256О¬Ј¬¶Ф64ёц256О¬өДХЕБҝЗуәНЈ¬ТАИ»әНКдИлұЈіЦПаН¬ҙуРЎ.
Нј 3(Fig. 3)
 | Нј 3 ResNeXtөДІРІоҪб№№Fig.3 Residual structure of ResNeXt |
ResNeXtІРІоҪб№№Ј¬ҫЯУРРн¶аПаН¬·ЦЦ§өДДЈҝйЈ¬Гҝёц·ЦЦ§Ҫ«КдИлҪшРРНЁөАІГјфЈ¬И»әуНЁ№э3ЎБ3ҫн»эҪшРРЧӘ»»Ј¬ЧоәуҪ«Ҫб№ыҪшРРәПІў.
2.3 ·ЦЦО·ЦАаәН»Ш№йЦ§В·И«Б¬ҪУІгФЪЙсҫӯНшВзЦРЦчТӘЖр·ЦАаЖчөДЧчУГЈ¬ө«КЗ¶Ф»Ш№йИұЙЩ°пЦъЈ¬ЛщТФИ«Б¬ҪУІгёьККәПҪЗ¶И·ЦАаУҰУГЈ¬ҫн»эІгёьККәПУГУЪЧҘИЎҝт»Ш№йИООсЈ¬Хл¶ФҙЛОКМвАыУГ·ЦЦОөД·Ҫ·ЁҪшРРҪвҫц.
Ҫ«·ЦЦО¶ФПу°ҙХХЧФЙнЧҘИЎјмІвөДЙи¶ЁЈ¬·Цұр¶ФУҰ»щУЪR-CNNөДН·ІҝјмІвЖчҪЗ¶И·ЦАа·ЦЦ§ТФј°ЧҘИЎҝт»Ш№й·ЦЦ§Ј»¶ФУЪ»Ш№йНшВзұҫОДСЎУГҫн»эАҙҙъМжЦ®З°өДИ«Б¬ҪУІгЈ»Ҫ«ЧҘИЎјмІвЧӘ»ҜОӘДҝұк¶ЁО»јУЙПҪЗ¶И·ЦАаОКМвЈ¬Ҫ«ёчОпМеЧҘИЎҝтУлЛ®ЖҪ·ҪПтөДјРҪЗЧӘ»ҜіЙ19ёцАаұрЈ¬ЛщТФТэЙкіцЧҘИЎҝт»Ш№й·ЦЦ§әНҪЗ¶И·ЦАа·ЦЦ§.
ұҫОДҪ«»Ш№й·ЦЦ§әН·ЦАа·ЦЦ§өҘ¶АІр·ЦҝӘЈ¬·ЦұрКөПЦ»Ш№йәН·ЦАа.PI-Cascade R-CNNНшВзј¶БӘРОКҪИзНј 2ЛщКҫЈ¬ЖдЦРіШ»ҜҪ«әтСЎЗшөДМШХчіШ»ҜОӘ№М¶ЁҙуРЎ, ФЪ»Ш№й·ЦЦ§ЦРУГҫн»эМжҙъЦ®З°өДИ«Б¬ҪУІг.НјЦРB0Ј¬B1Ј¬B2ұнКҫәтСЎЧҘИЎҝтЈ¬ЧоЦХКдіцөДB3ұнКҫФӨІвЧҘИЎҝтЈ»FC1Ј¬FC2әНFC3ұнКҫҪЗ¶И·ЦАа·ЦЦ§өДИ«Б¬ҪУІг; C1әНC2ұнКҫҪЗ¶ИФӨІв·ЦАаҪб№ыЈ¬C3КЗЧоЦХҪЗ¶ИФӨІв·ЦАаҪб№ы; Conv1Ј¬Conv2әНConv3КЗҫн»эІгЈ¬ҫӯ№э2ёцҫн»эІгәН1ёцЖҪҫщіШ»ҜІгҪшРРұЯҪзҝтөД»Ш№й.
Cascade R-CNNЦРМбіцБЛј¶БӘНшВзЈ¬ГҝёцҪЧ¶О¶јУРТ»ёцІ»Н¬өДIoUгРЦөЈ¬Cascade R-CNNК№УГCascade»Ш№йЧчОӘТ»ЦЦЦШІЙСщөД»ъЦЖЈ¬Црј¶МбёЯProposalөДIoUгРЦөЈ¬ҙУ¶шК№өГЗ°Т»ёцҪЧ¶ОЦШРВІЙСщ№эөДProposalsДЬ№»ККУҰПВТ»ёцУРёьёЯгРЦөөДstage[23].
Cascade R-CNNј¶БӘНшВзЦчТӘХл¶ФИэёцҪЧ¶ОЕР¶ЁХэёәСщұҫөДКдИлIoUгРЦөЈ¬ИэёцҪЧ¶ОөДјмІвЖчКдИлөДIoUгРЦөІ»Н¬Ј¬ГҝёцјмІвЖчКЗөЭҪш№ШПөЈ¬Из№ыөҘ¶АУГCascade R-CNNЦРөДөЪИэҪЧ¶ОIoUФЪ0.5~0.7ҪшРРҙҰАнКұЈ¬»бұ»өұЧчёәСщұҫ(әНұіҫ°ҝтТ»Н¬)ҙҰАнЈ¬ДЗГҙХвР©ҝтөД·ЦКэ»бұ»ҙтөНЈ¬ХвҫНөјЦВБЛөЪТ»ҪЧ¶ОәНөЪИэҪЧ¶ОЦ®јдөДІоҫа[24].
Хл¶ФХвТ»ОКМвұҫОДК№УГјҜіЙ№ІПнөД·Ҫ·Ё¶ФөЪИэҪЧ¶ОөДIoUгРЦөҪшРРУЕ»ҜЈ¬Ҫ«өЪИэҪЧ¶ОөДIoUгРЦөұдОӘИэёцҪЧ¶ОөДјҜіЙ№ІПнәуөДҪб№ыЈ¬ХвСщҝЙТФјхЙЩХэСщұҫұ»өұіЙёәСщұҫөДЗйҝцЈ¬МбёЯCascade R-CNNөДЧҘИЎјмІвЧјИ·ВК.
2.4 ҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝй¶аДҝұкЧҘИЎКэҫЭјҜ(MOGD)ЦР°ьә¬ҪПРЎОпМеЈ¬ХвҫНТӘЗуНшВзУРЧг№»өДёРКЬТ°АҙёІёЗөҪДҝұкОпМе.ФЪResNeXtМШХчИЪәП№эіМЦРЈ¬јУИлҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝй.ёГ№эіМ¶ФЗіІгМШХчНјҪшРРЙПІЙСщЈ¬УлҪөО¬әуЙоІгМШХчНјИЪәПЈ¬ТФјхЙЩМШХч¶ӘК§.УлЖХНЁҫн»эПаұИЈ¬ҝХ¶ҙҫн»э¶аіцБЛҝХ¶ҙВКОӘRateөДІОКэЈ¬ЖдЦРRateҝШЦЖёРКЬТ°өДҙуРЎЈ¬RateФҪҙуёРКЬТ°ФҪҙу.
ASPPДЈҝйІ»ҪцҝЙТФА©ҙуёРКЬТ°Ј¬¶шЗТІ»У°ПмНјПсөД·ЦұжВКТФј°І»ФцјУ¶оНвјЖЛгБҝ.ТтҙЛЈ¬Хл¶ФУЪІ»Н¬іЯ¶ИДҝұк¶ФУҰёРКЬТ°өДІ»Н¬Ј¬ұҫОДҪ«ИэЦЦІ»Н¬ҝХ¶ҙВКөДҝХ¶ҙҫн»эҪшРРІўБӘЈ¬И»әуҫӯ№эЙПІЙСщЈ¬ХвСщҝЙ»сИЎДҝұкЦЬұЯІ»Н¬·¶О§ЎўІ»Н¬ҙуРЎөДРЕПў.І»Н¬өДҝХ¶ҙҫн»эөДҝХјдВКІ»ПаН¬Ј¬ХвСщҫн»эәуҫНұЈБфёРКЬТ°·¶О§І»Н¬өДМШХчЈ¬УРР§МбёЯДЈРН¶ФІ»Н¬іЯ¶ИДҝұкөДёРЦӘДЬБҰ.ASPPДЈҝйОҙёДұдМШХчНјөДҙуРЎЈ¬Н¬КұёРКЬТ°·¶О§ЛжЦ®ҝШЦЖЈ¬УРАыУЪМбИЎ¶аіЯ¶ИРЕПўЈ¬ИзНј 4ЛщКҫ.
Нј 4(Fig. 4)
 | Нј 4 ASPP·ЦАаЖчДЈҝйFig.4 ASPP classifier module |
ёГДЈҝйЦчТӘ°ьә¬ТФПВјёёцІҝ·Ц[25]Јә
И«ҫЦЖҪҫщіШ»ҜІгөГөҪimage-levelМШХчЈ¬ҪшРРҫн»э(ҫн»эәЛОӘ1ЎБ1)Ј¬И»әуЛ«ПЯРФІеЦөөҪФӯКјҙуРЎЈ»Т»ёц1ЎБ1ҫн»эІгЈ¬»№УРИэёц3ЎБ3өДҝХ¶ҙҫн»эЈ»НЁ№э¶аЗюөАО¬¶ИИЪәПҪ«5ёцІ»Н¬іЯ¶ИөДМШХчИЪәПөҪТ»ЖрЈ¬ЛНИлҫн»э(ҫн»эәЛОӘ1ЎБ1)ҪшРРИЪәПКдіц.
2.5 ЛрК§әҜКэІОКэФӨІвНшВзРиТӘ¶ФЧҘИЎҝтөДҪЗ¶ИәНО»ЦГРЕПўҪшРРФӨІв.¶ФУЪҪЗ¶ИФӨІвІЙУГөДКЗ·ЦАа·Ҫ·ЁЈ¬ІЙУГөДЛрК§әҜКэКЗҪ»ІжмШЈ¬јЗОӘLcls.јЩЙиГҝёцКдИлНјПс°ьә¬Т»ёцҝЙЧҘИЎ¶ФПуЈ¬НшВзРиТӘФӨІвЧҘИЎҫШРОөД·ҪПтәНО»ЦГ.·ҪПтФӨІвІЙУГ·ЦАа·Ҫ·ЁЈ¬ІЙУГөДЛрК§әҜКэКЗҪ»ІжмШЛрК§әҜКэЈ¬·ЦАаЛрК§ұнКҫИзПВЈә
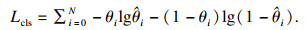 | (1) |
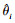
¶ФУЪО»ЦГ»Ш№йЛрК§Ј¬ІЙУГЖҪ·ҪОуІоұнКҫИзПВЈә
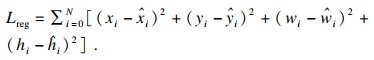 | (2) |
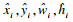
ТӘҪ«КэҫЭјҜұкЗ©ҪшРР№йТ»»ҜҙҰАнЈ¬ө«·ЦАаЛрК§әН»Ш№йЛрК§ұд»Ҝ·¶О§ПаІоІ»¶аЈ¬І»РиТӘјУИлЖҪәвПөКэЈ¬Н¬КұТІјхЙЩБЛі¬ІОКэөДКэБҝ.ЛщТФЧоЦХөДЛрК§әҜКэLall¶ЁТеОӘ
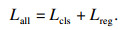 | (3) |
3 КэҫЭјҜёш¶ЁТ»ёц°ьә¬¶аёцІ»Н¬¶ФПуөДКдИлНјПсЈ¬ХэИзLenzөИ[1]ЛщМбіцөДОеІОКэұнХчЧҘИЎјмІвЈ¬УГУЪХжКөіЎҫ°ЦРөД»ъЖчИЛЧҘИЎ.ұҫОДЦШөгСРҫҝ»ъЖчИЛЖҪРР°ејРіЦЖчөД¶юО¬НјПсөДОеО¬ЧҘИЎұнКҫ.¶юО¬НјПсЦРөДЧҘИЎЧЛМ¬ИзНј 5әНКҪ(4)ЛщКҫ.
 | (4) |
 | Нј 5 ОеО¬ЧҘИЎІОКэFig.5 Parameters of 5D grasping parameters |
ЖдЦРЈә(xg, yg)ұнКҫЧҘИЎҫШРОөДЦКРД; hgәНwg·ЦұрҙъұнЧҘИЎҝтҫШРОөДёЯ¶Иј°ҝн¶И; ҰИgКЗУЙЧҘИЎҝн¶ИhgУлНјПсәбЦбјРҪЗёшіцөДЧҘИЎҪЗ¶ИЈ¬gұнХчЧҘИЎОпМе.
¶ФУЪ»ъЖчИЛөД¶юЦёКЦЧҘИЎЕдЦГјыКҪ(5)Ј¬ЖдЦРGұнКҫТ»ёцЖҪГжЧҘИЎО»ЧЛЈ¬(x, y)ұнКҫ»ъРөұЫД©¶ЛФЪЖҪГжЦРөДО»ЦГРЕПўЈ¬w, h·ЦұрұнКҫЖҪРР¶юЦёКЦөДҝнәНёЯЈ¬ЖдЦРҰИұнКҫЧҘИЎҪЗ¶ИЈ¬¶ФУЪ»ъРөұЫЈ¬РиТӘСШЛ®ЖҪ·ҪПтРэЧӘТ»¶ЁөДҪЗ¶ИөҪҙпЧҘИЎөг.
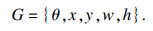 | (5) |
Нј 6(Fig. 6)
 | Нј 6 ¶аДҝұкЧҘИЎКэҫЭјҜұкЧўFig.6 Annotation of the multi-object grasping dataset |
3.2 КэҫЭФӨҙҰАнұҫОДЦЖЧчөД¶аОпМеЧҘИЎКэҫЭјҜ(MOGD)Ј¬УЙУЪСщұҫЦЦАаәНКэБҝөИТтЛШПЮЦЖЈ¬КэҫЭБҝҙпІ»өҪҙу№жДЈКэҫЭјҜөДұкЧјЈ¬ИЭТЧөјЦВДЈРНЗ·ДвәПЈ¬НшВзОЮ·ЁС§П°өҪУРР§өДМШХчЈ¬№КІЙУГКэҫЭФцЗҝөД·Ҫ·ЁҪвҫцёГОКМв.НЁ№эМнјУDropoutІг·АЦ№№эДвәПЈ¬СөБ·№эіМЦРDropout»бЛж»ъөШЮрЖъІҝ·ЦЙсҫӯФӘЈ¬ҝЙТФЖИК№НшВзС§П°ёь¶аВі°фөДМШХчЈ¬¶шІ»КЗТААөУЪІҝ·ЦёәФрФӨІв№ҰДЬөДЧУЙсҫӯФӘ.
1) КэҫЭФцЗҝ.ПИҪ«ФӯКј640ЎБ480НјПсУЙЦРРДПтЛДЦЬіКХэ·ҪРОІГјфЈ¬ХвСщҝЙТФИ·ұЈҙэЧҘИЎОпМеНкХыөШұЈБфЈ¬өГөҪ351ЎБ351НјПсЈ¬И»әуПтЛДЦЬҪшРРА©ід75ПсЛШЈ¬ІЙУГopencvЦРөДreplicateДЈКҪЈ¬өГөҪ501ЎБ501НјПсЈ¬И»әуҪшРРИфёЙПсЛШөДСШЛ®ЖҪ·ҪПтәНКъЦұ·ҪПтөДЖҪТЖЈ¬ФЩҪшРР5ҙО180ЎгДЪЛж»ъҪЗ¶ИөДРэЧӘЈ¬ЧоәуҪшРРТ»ҙОНјПсөДresizeЈ¬өГөҪ320ЎБ320өДНјПсЈ»УЙҙЛҝЙТФөГөҪПа¶ФУЪФӯКјКэҫЭјҜ100ұ¶өДФцЗҝЈ¬ИҘіэІҝ·ЦІ»әПАнСщұҫәуЈ¬ЧоЦХөГөҪСөБ·јҜ45 000ёцСщұҫЈ¬СйЦӨјҜ10 000ёцСщұҫЈ¬ІвКФјҜ5 000ёцСщұҫЈ¬ГҝёцСщұҫ°ьә¬RGBНјПсЈ¬¶ФУҰЧҘИЎұкЧў.
2) ЧҘИЎҝтҪЗ¶И·ЦАаОКМвҙҰАн.УЙУЪЧҘИЎҪЗ¶ИұИО»ЦГөДГфёР¶ИөНЈ¬јҙЧҘИЎҪЗ¶ИҝЙТФФЪТ»¶ЁөДгРЦөДЪұд»ҜЈ¬ЛщТФҝЙТФҪ«ЧҘИЎҪЗ¶ИөДФӨІвЧӘ»»іЙТ»ёц·ЦАаОКМв.ҫЯМеөДЧӘ»»№эіМГиКцИзПВЈә¶ФУЪТ»ёцЖҪРР¶юЦёјРҫЯЈ¬ЧҘИЎЖҪГжЙПөДОпМеЈ¬УЙУЪјРҫЯөД¶ФіЖРФЈ¬№КјРҫЯФЪЖҪГжЙПөДРэЧӘҪЗ¶ИОӘ[0Ўг, 180Ўг]Ј¬ұҫОДёщҫЭҝөДО¶ыЧҘИЎКэҫЭјҜЦРМṩөДұкЗ©КэҫЭЈ¬ЖдКҫТвНјИзНј 7ЛщКҫ.
Нј 7(Fig. 7)
 | Нј 7 ЧҘИЎјмІвОКМв·ЦҪвНјFig.7 Decomposition diagram of grasping detection problems |
РиТӘ¶ФНјПсҪшРРresizeТФј°paddingЈ¬ұЈЦӨОпМеІ»·ўЙъРОұдөДН¬КұЈ¬ҫЎБҝК№ОпМеұЈіЦФЪКУТ°Ц®ЦРЈ¬МЮіэФцЗҝәуОЮР§өДЧҘИЎҝтЈ¬ІЙјҜөГөҪөДНјПсіЯҙзКЗ640ЎБ480Ј¬ҫӯ№эФцЗҝәуөДНјПсіЯҙзКЗ320ЎБ320Ј¬ЧоәуҪ«ЙъіЙөДСщұҫөјИлөҪ·ыәПCOCOДҝұкјмІвКэҫЭјҜёсКҪJsonОДјюЦРЈ¬ЙъіЙөДСөБ·јҜНјЖ¬45 000ХЕЈ¬ІвКФјҜ15 000ХЕЈ¬ГҝёцСщұҫ°ьә¬ЧҘИЎҝтЈ¬Д¬ИПЛщУРөДСщұҫСөБ·ДСТЧіМ¶ИПаН¬.
ҫӯ№эКэҫЭФцЗҝТФј°МЮіэІ»ҝЙУГСщұҫЈ¬¶ФУЪҪЗ¶ИФӨІвЈ¬Ҫ«ҪЗ¶ИФӨІвОКМвУГ·ЦАаОКМвАҙМж»»Ј¬180Ўгҫщ·Ц19ёцАаұр.ЧоәуЈ¬ГҝёцСщұҫУР1·щRGBНјПсЈ¬1~19өДХыКэұкЗ©әНО»ЦГІОКэРЕПўОӘ(ҰИЈ¬xЈ¬yЈ¬wЈ¬h).
3.3 СөБ·ІЙУГCOCOКэҫЭјҜөДФӨСөБ·ДЈРНіхКј»ҜДЈРНІОКэТФј°4ҝйGPUІўРРСөБ·Ј¬ДЈРНepochөДСЎИЎИзПВЈәөұДЈРНepochСЎФсі¬№э20КұЈ¬ДЈРНЧјИ·ВКІ»ФЩМбЙэЈ¬№КЙиЦГepochЦөОӘ20Ј¬ЙиЦГbatchsizeОӘ64Ј¬УЙУЪКэҫЭјҜЦРҝЙДЬ»бУРПаЛЖСщұҫЈ¬ЛщТФУЕ»ҜЖчІЙУГSGDЈ¬SGDТ»ҙОЦ»ҪшРРТ»ҙОёьРВЈ¬Г»УРИЯУаЈ¬ЛЩ¶ИҪПҝмЈ¬ІўЗТҝЙТФРВФцСщұҫ.С§П°ВККЗҪ«КдіцОуІо·ҙПтҙ«ІҘёшНшВзІОКэЈ¬ТФҙЛАҙДвәПСщұҫөДКдіц.С§П°ВКөДСЎФс¶ФУЪЧоУЕ»ҜөДР§№ыЦБ№ШЦШТӘЈ¬ёщҫЭіхКјС§П°ВКСөБ·Ј¬№ЫІмІвКФР§№ыЈ¬ЧоЦХЙиЦГС§П°ВК0.02Ј¬ЙиЦГ¶ҜБҝІОКэОӘ0.9.
3.4 ЖА№АЦёұкұҫОДЦчТӘСРҫҝ»ъРөұЫөД¶аОпМеЧҘИЎОКМвЈ¬ХвЦЦ»ъЖчИЛЧҘИЎөДЖАјЫЦёұкУРБҪЦЦЈәөг¶ИБҝәНҫШ¶ИБҝ.өг¶ИБҝ[26-27]НЁ№эИЁәвФӨІвЧҘИЎҝтЦРРДәНұкЗ©ЧҘИЎҝтЦРРДЦ®јдөДҫаАлАҙЖА№АЧҘИЎ.
УЙJiangөИ[28]МбіцөДҫШ¶ИБҝЈ¬ДҝЗ°ЧҘИЎЖА№А¶аІЙУГҫШ¶ИБҝЈ¬Н¬КұК№УГЧҘИЎҪЗ¶ИәНJaccardЦёКэұкЧј¶Ф»ъЖчИЛЧҘИЎҪшРРЖА№А.өұәтСЎЧҘИЎЕдЦГВъЧгПВГжПкПёГиКцөДБҪёцұкЧјКұЈ¬ёГәтСЎЧҘИЎЕдЦГұ»ИПОӘКЗУРР§өД.
1) ФӨІвөДЧҘИЎҝтҪЗ¶ИУлУРР§өДЧҘИЎҝтҪЗ¶ИЦ®ІоФЪ30ЎгТФДЪ.
2) ФӨІвөДЧҘИЎҝтApәНХжЦөAtЦ®јдJaccardЦёКэҙуУЪ25%Ј¬JaccardЦёКэ°ҙКҪ(6)јЖЛгЈә
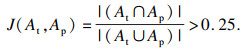 | (6) |
4 ЧҘИЎјмІвҪб№ыј°·ЦОцФЪ¶аОпМеЧҘИЎКэҫЭјҜ(MOGD)ЙПҪшРР¶ФұИКөСйТФј°ПыИЪКөСйЈ¬СйЦӨЛщМбҙҙРВөгөДУРР§РФ. КөСй·юОсЖчФЛРР»·ҫіИзПВ.
ІЩЧчПөНіЈәUbuntu MATE16.04Ј»
CPUЈәIntel(R) Xeon(R) CPU E5-2620 v4@2.10 GHzЈ»
GPUЈәTitan XЈ»
Python°жұҫЈә3.6.7Ј»
Torch°жұҫЈә1.1.0.
4.1 АыУГCascade R-CNNЧҘИЎјмІвЛг·Ё¶Ф¶аДҝұкЧҘИЎКэҫЭјҜҪшРРјмІвФЪ¶ФМбіцөДЛг·ЁҪшРРЖА№АКұЈ¬јмІвHeadІҝ·ЦІЙУГRPNHeadЈ¬УГАҙЙъіЙёЯЦКБҝөДProposal.ЛрК§әҜКэІЙУГҪ»ІжмШЖА№А·ЦАаРФДЬЈ¬ҫщ·ҪІоЖА№А»Ш№йРФДЬ.ІЙУГФЪCOCOКэҫЭјҜөДФӨСөБ·ДЈРНіхКј»ҜДЈРНІОКэЈ¬НкХыөДСөБ·№эіМәНІвКФҙъВл№№ҪЁФЪPytorchЙП.
ФЪMOGDЙПөДјмІвҪб№ыИзұн 1ЛщКҫЈ¬ЖдЦРЎ°RЎұұнКҫёДҪшbackboneЈ¬ТэИлResNeXtҪб№№Ј¬Ў°JЎұұнКҫҙшУРҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝйЈ¬Ў°FЎұұнКҫјУИлјҜіЙ№ІПн·ЦЦО·ЦАаәН»Ш№йЦ§В·.УЙУЪҝХ¶ҙҫн»эЎ°JЎұКЗФЪResNeXtҪб№№ЙПМнјУөДЈ¬ЛщТФЦ»УРResNeXtҪб№№ЙПУРҝХ¶ҙҫн»э.
ұн 1(Table 1)
| ұн 1 ¶аДҝұкЧҘИЎјмІвЛг·ЁөДРФДЬ Table 1 Perfermance of multi-object grasping detection algorithm |
ОӘБЛСйЦӨұҫОДЛщМбіцөД¶аОпМеЧҘИЎјмІвЛг·Ё¶ФУЪМнјУІ»Н¬ёДҪшІЯВФөДРФДЬМбЙэЈ¬ЙиЦГБЛ·ЦұрІЙУГ6ЦЦЛг·ЁөДКөСй¶ФХХЧй.¶ФХХЧйөДСөБ·ЕдЦГЎўІОКэ»щұҫУлPI-Cascade R-CNNТ»ЦВЈ¬°ьАЁКэҫЭјҜЎўЦчёЙНшВзЎўУЕ»ҜЖчЎўЛрК§әҜКэөИ.
КөСйҪб№ыИзұн 1ЛщКҫЈ¬ЖдЦРPI-Cascade R-CNNКЗұҫОДХл¶Ф¶аДҝұкЧҘИЎјмІвөДCascade R-CNNёДҪшДЈРНЈ¬PI-Cascade R-CNNУлCascade R-CNNПаұИХыМеМбЙэ1.5ёц°Щ·Цөг.ІвКФКөСйҪб№ыұнГчЈ¬ұҫОДМбіцөДёДҪш·Ҫ·ЁФЪЧҘИЎјмІвОКМвЙПёДҪшР§№ыҪПәГ.»щУЪPI-Cascade R-CNNөДЧҘИЎјмІвЛг·ЁФЪ¶аДҝұкЧҘИЎКэҫЭјҜЙПИЎөГ93%өДЖҪҫщФӨІвЧјИ·ВКЈ¬Па¶ФУЪ»щҙЎНшВзFaster R-CNNәНCascade R-CNNФӯНшВзҫщУРМбЙэ.
¶аДҝұкЧҘИЎјмІвЛг·ЁҪб№ыИзНј 8ЛщКҫ.»щУЪPI-Cascade R-CNNөД¶аОпМеЧҘИЎјмІвЛг·ЁФЪЧҘИЎјмІв·ҪГжУРҪПЗҝөДККУҰРФЈ¬ҝЙТФФӨІвіцЧҘИЎҝт¶ФУҰөДО»ЦГРЕПўәНРэЧӘҪЗ¶ИРЕПўЈ¬ЦӨГчұҫОДМбіцөД¶аОпМеЧҘИЎјмІвЛг·ЁөДУРР§РФ.
Нј 8(Fig. 8)
 | Нј 8 ¶аДҝұкЧҘИЎјмІвЛг·ЁҪб№ыFig.8 Result of the multi-object grasping detection algorithm |
4.2 »щУЪKinova»ъРөұЫҪшРРЧҘИЎЖҪМЁөДҙоҪЁ4.2.1 КөСйЖҪМЁҙоҪЁұҫөШKinova»ъЖчұЫҝШЦЖЖҪМЁ»·ҫіИзПВЈә
ІЩЧчПөНіЈәUbuntu 16.04;
CPUЈәIntel(R) Core(TM) i5-10400 CPU@2.90 GHz;
УІјюЈәKinova mico2БщЧФУЙ¶И»ъРөұЫЎўRealsense D435Па»ъ.
4.2.2 КЦСЫұк¶ЁұҫОДІЙУГҝӘФҙПоДҝeasy_hand/eye[29]НкіЙeye-in-handКЦСЫұк¶Ё.Па»ъ№М¶ЁУЪ»ъЖчұЫД©¶ЛЈ¬¶ЁТеИзПВЧшұкПөЈә»ъРөұЫ»щЧшұкПөОӘBЈ¬»ъРөұЫД©¶Л№ШҪЪЧшұкПөОӘEЈ¬Па»ъЧшұкПөОӘCЈ¬ұк¶Ё°еЧшұкПөОӘKЈ¬EBTұнКҫ»ъРөұЫД©¶Л№ШҪЪЧшұкПөПа¶ФУЪ»ъРөұЫ»щЧшұкПөөДЧӘ»»Ј¬CETұнКҫПа»ъЧшұкПөПа¶ФУЪ»ъРөұЫД©¶Л№ШҪЪЧшұкПөөДЧӘ»»Ј¬ёГІОКэФЪПа»ъ°ІЧ°НкіЙәуКЗ№М¶ЁЦөЈ¬KCTұнКҫұк¶Ё°еЧшұкПөПа¶ФУЪПа»ъЧшұкПөөДЧӘ»»Ј¬KBTұнКҫұк¶Ё°еЧшұкПөПа¶ФУЪ»ъРөұЫ»щЧшұкПөөДЧӘ»».ұк¶Ё№эіМЦРЈ¬ұЈіЦұк¶Ё°еО»ЦГөД№М¶ЁЈ¬ІЙУГЧФ¶Ҝ»тХЯКЦ¶Ҝ·ҪКҪөчХыПа»ъО»ЧЛЈ¬¶ФУЪІ»Н¬өДІЙСщөгЈ¬ФтУР
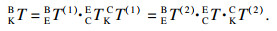 | (7) |
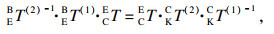 | (8) |
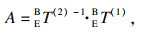 | (9) |
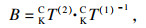 | (10) |
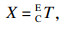 | (11) |
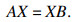 | (12) |
4.2.3 Па»ъұк¶ЁПа»ъДЪІОКэұк¶ЁІЙУГХЕХэУСұк¶Ё·ЁЈ¬ФЪUbuntu16.04ПВНкіЙRealsense D435°ІЧ°Зэ¶ҜЈ¬ФЪrosПВЖф¶ҜПа»ъЈ¬°ІЧ°ҝӘФҙПа»ъұк¶Ё№ӨҫЯKalibrЈ¬ұк¶Ё°еІЙУГ6ЎБ7ұИАэЈ¬іЯҙзОӘ0.029 mЎБ0.029 mөДәЪ°ЧЖеЕМёсЈ¬НЁ№эұк¶Ё№ӨҫЯЦРөДrosbagВјЦЖұк¶ЁКэҫЭЈ¬ЧоәуНЁ№эұк¶ЁіМРтНкіЙұк¶Ё.
4.3 »щУЪPI-Cascade R-CNNЧҘИЎјмІвЛг·Ё¶Ф¶аДҝұкЧҘИЎКэҫЭјҜҪшРРЧҘИЎКөСйёщҫЭ»ъЖчұЫЧҘИЎОпМеёцКэөДІ»Н¬Ј¬ұҫОД·ЦұрЙиЦГөҘёцОпМеЧҘИЎЈ¬¶аёцОпМеЧҘИЎ.ЧҘИЎКөСйЙиЦГCascade R-CNNј°PI-Cascade R-CNNБҪЧй·ЦұрФЪөҘДҝұкәН¶аДҝұкіЎҫ°ПВҪшРР¶ФұИСйЦӨ.
өЪТ»ЧйКөСйЈ¬Хл¶ФөҘДҝұкіЎҫ°Ј¬ҪшРР150ЧйЧҘИЎКөСйЈ¬КөСй№эіМЦРЈ¬»ъРөұЫДЬ№»јРИЎөҪОпМеЗТұЈіЦТ»¶ЁКұјдЈ¬ФтНіјЖОӘіЙ№Ұ.өЪ¶юЧйКөСйЈ¬Хл¶Ф¶аДҝұкіЎҫ°Ј¬Лж»ъСЎФс2ЦБ3ЦЦОпМеХэ·ЕУЪЧАГжЈ¬ОпМеЦ®јдұЛҙЛІ»ҪУҙҘЈ¬»ъЖчұЫРиТӘёщҫЭЧҘИЎјмІвөДҪб№ыҪшРРЛіРтЧҘИЎ.ЧҘИЎіЙ№ҰУл·сЕР¶ЁұкЧјН¬ЙПЈ¬№ІҪшРР150ҙОЧҘИЎКөСй.
Нј 9ОӘКөјКЧҘИЎ№эіМ.КөСй№эіМЦРЈ¬НіјЖГҝёцОпМеөДЧҘИЎҙОКэЎўЧҘИЎіЙ№ҰҙОКэТФј°ЖҪҫщЧҘИЎіЙ№ҰВКЈ¬ЧоЦХ¶ФұИКөСйҪб№ыјЗВјУЪұн 2ЦР.
Нј 9(Fig. 9)
 | Нј 9 ¶аДҝұкіЎҫ°ПВОпМеЧҘИЎКөСйFig.9 Grasping experiment under the multi-object scene |
ұн 2(Table 2)
| ұн 2 ёДҪшЗ°әуЧҘИЎКөСйҪб№ы¶ФХХ Table 2 Comparison of grasping experimental results before and after improvement |
ёщҫЭЧҘИЎКөСйНіјЖұн 2КэҫЭ¶ФұИҝЙЦӘЈ¬ұҫОДөДPI-Cascade R-CNNЛг·ЁФЪөҘДҝұкіЎҫ°ПВЧҘИЎіЙ№ҰВКОӘ96.6%Ј¬¶аДҝұкіЎҫ°ПВЧҘИЎіЙ№ҰВКОӘ90.6%.ПаҪПУЪCascade R-CNNЛг·ЁЈ¬ұҫОДЛг·ЁҫЯУРҪПёЯөДіЙ№ҰВК.КөСйҪб№ыЦӨГчБЛұҫОДМбіцөД¶аОпМеЧҘИЎјмІвЛг·ЁөДУРР§РФЈ¬Н¬КұФЪҪшРРЧҘИЎКөСйөД№эіМЦРЈ¬Т»Р©УлСөБ·КэҫЭјҜҪПОӘПаЛЖөДОпМеЈ¬ЧҘИЎјмІвПөНіТІДЬ№»ФӨІвіцәПАнөДЧҘИЎО»ЧЛЈ¬ұнПЦіцНшВзөД·ә»ҜРФДЬ.
5 ҪбУпұҫОДМбіцБЛТ»ЦЦ»щУЪCascade R-CNNёДҪшЛг·ЁөД¶аДҝұкЧҘИЎјмІвДЈРН.ФЪЙо¶ИЙсҫӯНшВзЦРТэИлБЛҫЯУРЖҪРР¶СөюПаН¬НШЖЛҪб№№өДResNeXtНшВзЈ¬УРР§өШМбЙэДЈРНөДЧјИ·ВКІўЗТІ»»бФцјУНшВзІОКэБҝј¶.¶ФҪЗ¶И·ЦАа·ЦЦ§әНЧҘИЎҝт»Ш№й·ЦЦ§ҪшРРІр·ЦУЕ»ҜЈ¬ІўХл¶ФCascade R-CNNНшВзөЪИэҪЧ¶ОөДIoUгРЦөІ»ЖҘЕдФміЙёәСщұҫОКМвІЙУГјҜіЙ№ІПн·ҪКҪҪшРРёДЙЖ.ТэИлҙшҝХ¶ҙҫн»эөДҝХјдҪрЧЦЛюіШ»ҜДЈҝйАҙҪвҫц·ЦұжВКөНөДОКМвЈ¬ҝЙТФФЪІ»ёДұдМШХчНјҙуРЎөДН¬КұҝШЦЖёРКЬТ°Ј¬ТФұгУЪМбИЎ¶аіЯ¶ИРЕПў.
ЧЫЙПЛщКцЈ¬ұҫОДМбіцөДЛг·ЁҝЙТФәЬәГөШНкіЙЧҘИЎјмІвИООс.КөСйСйЦӨұҫОДМбіцөДДЈРНФЪ¶аДҝұкЧҘИЎКэҫЭјҜөДЧҘИЎјмІвЦРЈ¬ҫЯУРҪПёЯөДР§ВКәНЧјИ·ВК.ОҙАҙҪ«ФЪ¶Сөю»·ҫіәНК¶ұрОпМеРЕПў·ЦАаОКМвЙПҪшРРЙо¶ИСРҫҝ.
ІОҝјОДПЧ
| [1] | Lenz I, Lee H, Saxena A. Deep learning for detecting robotic grasps[J]. The International Journal of Robotics Research, 2015, 34(4/5): 705-724. |
| [2] | Wei J, Liu H, Yan G, et al. Robotic grasping recognition using multi-modal deep extreme learning machine[J]. Multidimensional Systems and Signal Processing, 2017, 28(3): 817-833. DOI:10.1007/s11045-016-0389-0 |
| [3] | Wang Z, Li Z, Wang B, et al. Robot grasp detection using multimodal deep convolutional neural networks[J]. Advances in Mechanical Engineering, 2016, 8(9): 1687814016668077. |
| [4] | АоРгЦЗ, АојТәА, ХЕПйТш, өИ. »щУЪЙо¶ИС§П°өД»ъЖчИЛЧоУЕЧҘИЎЧЛМ¬јмІв·Ҫ·Ё[J]. ТЗЖчТЗұнС§ұЁ, 2020, 41(5): 108-117. (Li Xiu-zhi, Li Jia-hao, Zhang Xiang-yin, et al. Robot optimal grasping posture detection method based on deep learning[J]. Instruments Journal, 2020, 41(5): 108-117.) |
| [5] | ҙЮЙЩО°, ОәҝЎәј, НхоЈ, өИ. »щУЪКУҙҘИЪәПөД»ъЖчИЛЧҘИЎ»¬¶ҜјмІв[J]. »ӘЦРҝЖјјҙуѧѧұЁ(ЧФИ»ҝЖС§°ж), 2020, 48(1): 98-102. (Cui Shao-wei, Wei Jun-hang, Wang Rui, et al. Robot grasping sliding detection based on visual-tactile fusion[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2020, 48(1): 98-102.) |
| [6] | Ой№гұт. »щУЪБмУтЧФККУҰС§П°өД»ъЖчИЛ¶аДҝұкОпМеЧҘИЎК¶ұрЛг·ЁСРҫҝ[D]. №ю¶ыұх: №ю¶ыұх№ӨТөҙуС§, 2021. (Wu Guang-bin. Research on robot multi-target object grasping recognition algorithm based on domain adaptive learning[D]. Harbin : Harbin Institute of Technology, 2021. ) |
| [7] | Guo D, Sun F, Liu H, et al. A hybrid deep architecture for robotic grasp detection[C]//2017 IEEE International Conference on Robotics and Automation(ICRA). Singapore: IEEE, 2017: 1609-1614. |
| [8] | ПДҫ§, З®ҲТ, ВнРс¶«, өИ. »щУЪј¶БӘҫн»эЙсҫӯНшВзөД»ъЖчИЛЖҪГжЧҘИЎО»ЧЛҝмЛЩјмІв[J]. »ъЖчИЛ, 2018, 40(6): 794-802. (Xia Jing, Qian Kun, Ma Xu-dong, et al. Rapid detection of robot plane grasping pose based on cascaded convolutional neural network[J]. Robot, 2018, 40(6): 794-802.) |
| [9] | УчИәі¬, ЙРО°О°, ХЕіЫ. »щУЪИэј¶ҫн»эЙсҫӯНшВзөДОпМеЧҘИЎјмІв[J]. »ъЖчИЛ, 2018, 40(5): 762-768. (Yu Qun-chao, Shang Wei-wei, Zhang Chi. Object grasping detection based on three-level convolutional neural network[J]. Robot, 2018, 40(5): 762-768.) |
| [10] | Depierre A, DellandrЁҰa E, Chen L. Jacquard: a large scale dataset for robotic grasp detection[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS). Madrid, Spain: IEEE, 2018: 3511-3516. |
| [11] | Morrison D, Corke P, Leitner J. Learning robust, real-time, reactive robotic grasping[J]. The International Journal of Robotics Research, 2020, 39(2/3): 183-201. |
| [12] | Saxena A, Driemeyer J, Ng A Y. Robotic grasping of novel objects using vision[J]. The International Journal of Robotics Research, 2008, 27(2): 157-173. DOI:10.1177/0278364907087172 |
| [13] | Le Q V, Kamm D, Kara A F, et al. Learning to grasp objects with multiple contact points[C]//2010 IEEE International Conference on Robotics and Automation. Anchorage: IEEE, 2010: 5062-5069. |
| [14] | Wang P, Ye F, Chen X, et al. Datanet: deep learning based encrypted network traffic classification in SDN home gateway[J]. IEEE Access, 2018, 6: 55380-55391. |
| [15] | Deng Y, Ren Z, Kong Y, et al. A hierarchical fused fuzzy deep neural network for data classification[J]. IEEE Transactions on Fuzzy Systems, 2016, 25(4): 1006-1012. |
| [16] | Wang K, Zhang D, Li Y, et al. Cost-effective active learning for deep image classification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 27(12): 2591-2600. |
| [17] | Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus, 2014: 580-587. |
| [18] | Girshick R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, 2015: 1440-1448. |
| [19] | Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(6): 1137-1149. |
| [20] | Redmon J, Angelova A. Real-time grasp detection using convolutional neural networks[C]//2015 IEEE International Conference on Robotics and Automation(ICRA). Seattle, WA: IEEE, 2015: 1316-1322. |
| [21] | Park D, Chun S Y. Classification based grasp detection using spatial transformer network[J]. arXiv Preprint arXiv: 1803. 01356, 2018. |
| [22] | Asif U, Tang J, Harrer S. GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices[C]//International Joint Conference on Artificial Intelligence. Stockholm: CVPR, 2018: 4875-4882. |
| [23] | Cai Z, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 6154-6162. |
| [24] | Li A, Yang X, Zhang C. Rethinking classification and localization for cascade R-CNN[J]. arXiv Preprint arXiv: 1907. 11914, 2019. |
| [25] | Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. arXiv Preprint arXiv: 1412. 7062, 2014. |
| [26] | Xie S, Girshick R, DollЁўr P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, 2017: 1492-1500. |
| [27] | Saxena A, Driemeyer J, Kearns J, et al. Robotic grasping of novel objects[C]//Proceedings of the 19th International Conference on Neural Information Processing Systems. Vancouver, 2006: 1209-1216. |
| [28] | Jiang Y, Moseson S, Saxena A. Efficient grasping from RGBD images: learning using a new rectangle representation[C]//2011 IEEE International Conference on Robotics and Automation. Shanghai: IEEE, 2011: 3304-3311. |
| [29] | Tsai R Y, Lenz R K. A new technique for fully autonomous and efficient 3D robotics hand/eye calibration[J]. IEEE Transactions on Robotics and Automation, 1989, 5(3): 345-358. |
