 , 李伟伟
, 李伟伟 东北大学 工商管理学院,辽宁 沈阳 110169
收稿日期:2022-03-26
基金项目:国家自然科学基金资助项目(72171040, 72171041);中央高校基本科研业务费专项资金资助项目(N2006013)。
作者简介:易平涛(1981-),男,湖南永州人,东北大学教授,博士生导师。
摘要:分层无量纲化方法能够有效去除指标量纲影响的同时解决异常指标造成的数据分布不均衡、区分度低等问题.然而,该方法的使用需要人为指定区间数,使得无量纲化结果受人为因素的干扰,失去客观性.针对该问题,考虑原始数据的分布特征,提出了密度分层无量纲化方法.该方法按照数据分布的疏密程度进行区间划分,客观确定分层级数,同时兼顾分层无量纲化方法的优点,计算相对简单且减少了人为干扰.此外,通过随机模拟发现,该方法对于异常值具有较好的抗干扰性,且无量纲化结果的均衡性受原始数据规模影响.
关键词:无量纲化方法异常值分层无量纲化方法数据密度客观分层
Hierarchical Dimensionless Method Based on Data Distribution Characteristics and Its Equilibrium Analysis
YI Ping-tao, YUAN Jian-rong
, LI Wei-wei School of Business Administration, Northeastern University, Shenyang 110169, China
Corresponding author: YUAN Jian-rong, E-mail: jianrong_yuan@163.comjianrong_yuan@163.com.
Abstract: The hierarchical dimensionless method can effectively remove the effect of different index dimensions, and solve imbalanced data distribution and low discrimination caused by anomalous index values. However, when using this method, it is necessary to artificially specify the number of partition intervals so that the dimensionless results are interfered by human factors and lose objectivity. To solve this problem, a dimensionless method of density hierarchy is proposed considering the distribution characteristics of raw data. This method divides the interval according to the density of data distribution, objectively determines the hierarchical series, and takes into account the advantages of the hierarchical dimensionless method. The calculation is comparatively simple and reduces human factors. In addition, through the stochastic simulation method, it is found that the method has good anti-interference to outliers, and the balance of dimensionless results is affected by the scale of raw data.
Key words: dimensionless methodoutlierhierarchical dimensionless methoddata densityobjective hierarchy
综合评价,是指对被评价对象所进行的公正、客观以及合理的全面评价,广泛应用于经济管理、统计及决策等各领域,具有重大的实用价值和广泛的应用前景[1-8].作为评价流程中的重要环节,指标的无量纲化过程消除了不同量纲对评价结果的影响[9-10],为多属性数据的集结奠定了基础.根据函数特性的不同可将无量纲化方法主要分为两类:线性无量纲化方法和非线性无量纲化方法[11].由于计算简洁,易于操作,线性无量纲化方法的使用更为广泛[12-17].
线性无量纲化方法,其最大特点在于能够保留原始数据的分布特征.但是,在综合评价过程中,原始指标数据之间的关系并非都是线性的,其分布也并非都是均匀.数据间分布差异大,甚至存在异常数据的情况时有发生.异常数据的分布远离于大部分评价数据,它的存在间接压缩了其他数据的分布范围,导致评价数据呈现明显的不均匀分布[18],使得绝大部分数据之间区分度不高.在存在异常值的情况下,若选择线性无量纲化方法,会导致结果出现分布不均衡的问题[19],进而降低指标的区分度,从整体上削弱了评价的差异测度功能.
针对此问题,“分层处理”的思想被引入无量纲化处理过程中.文献[18]首先对原始数据进行异常值判断、识别,然后以极值处理法为基础分别指定异常值和非异常值的无量纲化取值区间,从而进行分层无量纲化处理.文献[20]则省去对异常信息的判别,在尽量保证原始数据分布特征的前提下,基于极值处理法提出了一种根据数据位置分布进行划分区间的分层无量纲化处理方法,即“位置分布处理法”.在此基础上,文献[19]又对该方法做了进一步的优化,对其分层方法展开细化改进,提出了按照原始数据排序值百分比实现区间划分,进而对原始数据实行无量纲化处理,即“序比例诱导分段无量纲化方法”.
然而,上述方法均未给出分层区间的具体划分层数,需要根据评价者自行确定.因此,在实际应用过程中针对异常值存在的情况,评价者往往会直接选择传统的四分位分层无量纲化方法[20].但将四分位数作为分层区间的依据,也是基于评价者的经验判断所得,无法保证无量纲化结果的客观性.因此,本文在已有研究的基础上,考虑到数据自身的密度特征,即按照数据分布的疏密程度客观地划分分层区间,提出了一种新的基于原始数据分布疏密程度的分层无量纲化方法.此外,本文还对运用该方法进行处理所得结果的均衡性进行对比分析,并提出相关结论.
1 研究基础及问题描述本文在分层无量纲化方法[20]的基础上进行拓展研究,下面简要介绍分层无量纲化方法.
设n个被评价对象o1, o2, …, on关于m个指标x1, x2, …, xm的取值矩阵为[xij]n×m,记无量纲化处理后的矩阵X*=[xij*]n×m.不失一般性,令m, n≥3.分层无量纲化方法的基本步骤如下:
对某一指标下的原始数据按升序排列,在[0, 1]区间内取l+2个分层点(记为α0, α1, …, αl+1),将区间划分为l+1个子区间,其中α0=0, αl+1=1.不失一般性,令l≥1,子区间分别为[α0, α1], (α1, α2], …, (αl, αl+1].与此同时,依据原始指标数据按照分层点依次计算其相对应的百分位数,记为γ0, γ1, …, γl+1.在明确分层区间且得到相应的百分位数后,可按式(1)对原始数据进行无量纲化处理:
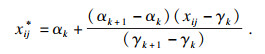 | (1) |
分层无量纲化方法的关键是分层区间数的确定,即l值的确定.现有研究中评价者往往直接选用四分位数来划分区间,进而实现分层无量纲化处理,但其合理性和结果的均衡性都无法得到保障.因此,本文聚焦于如何客观合理地确定分层区间数,并将其与传统的四分位分层无量纲化方法进行对比,以突出本文方法的优势.
2 基于密度划分区间的分层无量纲化方法2.1 基于数据密度的分层区间划分本文依据指标数据的分布密度对其进行区间分层,划分的基本思路为:首先,将原始指标数据进行按序排列,并计算前后相邻数据之间的差值;其次,对其差值作标准化处理并进行判断,将不符合条件的差值所对应的数据单独成数据集,同时将符合条件的差值作为划分依据,进行区间的划分;最后,对初次划分的区间进行判断、校正,从而得到最终的分层区间.
2.1.1 原始数据集的初步划分步骤1 指标值的排序.对n个被评价对象关于第j(j=1, 2, …, m)个指标取值{x1j, x2j, …, xnj},按升序排列,为便于理解,排序后的指标值仍记为{x1j, x2j, …, xnj}.
步骤2 相邻指标间差值的计算.依次计算前后相邻数据间的差值(记为Δtj),如式(2)所示:
 | (2) |
 | (3) |
步骤4 分层条件的判断.本文以首个非零差值Δ1j(Δ1j≠0)作为比较基准,为防止Δ1j值过大导致判别条件失效,在进行比较前需对Δ1j进行异常值判断.若满足|z1j|<z(z的取值依据拉依达准则进行确定,2.1.2节中给出),则可将Δ1j作为判断标准并进入下一步处理;否则,表明该差值异常,需顺次对z2j进行判断,直至出现满足上述条件的Δtj为止.
步骤5 根据分层点,初步得到分层区间.若存在异常差值,则需先将其所处位置作为分层点进行区间划分.然后,以前文正常差值Δtj为基准依次作比,若出现Δδj>Δtj(δ>t),则将Δδj所在位置作为分层点进行区间划分.不失一般性,设原始数据划分为Ω1={x1j, x2j, …, xμj}, Ω2={x(μ+1)j, x(μ+2)j, …, xnj}(1≤μ<n)两个子数据集,并将Ω1和Ω2数据集的间距定义为Δδj(Δδj=x(μ+1)j-xμj).
步骤6 对数据集Ω2进行划分.一般地,Ω2内数据分布密度不均衡,仍需对其进行细致划分.以Δδj作为基准,按照前文规则识别其中分层点并以此进行数据分割,得到分层区间Ω3与Ω4.依此类推,得到所有分层区间Ωρ(1≤ρ≤n).
2.1.2 数据集划分的检验经上述处理,原始数据被划分为若干个区间,为了使划分结果更加精确,需进一步判断和处理每个分层区间.具体过程如下:
步骤1 对已划分好的各个分层区间,分别计算其内部所有差值Δσj*(1<σ<n)的平均值Δρj*和标准差sρj*,并根据式(3)对各分层区间内的每个Δσj*进行标准化处理,令其标准分数值为zσj*(zσj*同2.1.1节步骤3中的ztj含义及作用完全一致).
步骤2 对各个分层区间内的异常差值进行辨识.若分层区间内所有的Δσj*均满足|zσj*|<z(此处z同前文一致),表明前文对于该区间的划分没有问题;否则,若存在Δσj*不满足此条件,则表明前文对该分层区间的划分存在问题,需重新对其进行处理划分,进而转入步骤3.
步骤3 根据异常差值Δσj*的位置,对其所在分层区间Ωρ再次分割,并重复步骤1~3,直至所有区间内的zσj*满足条件为止,得到最终各分层区间Ωλ(1≤λ≤n).
根据上述分层区间划分步骤中对于判断差值是否异常的需要,本文选择拉依达准则对差值所对应的标准分数值进行比较.拉依达准则是指对一组数据进行处理得到标准偏差,并按一定概率确定一个区间,若有数据超过该区间,则表明该数据属于异常值应予以剔除[21].此原则主要对正态或近似正态分布的样本数据进行处理,用于判别数据中是否存在异常值.根据拉依达准则理论,本文中z值取3.另外,运用拉依达准则进行异常值判断时,对于样本量有一定的要求,当样本量较小时,则不适用.
2.2 无量纲化处理经前文处理,原始数据已按分布的疏密程度进行了区间划分,使得区间内部的数据分布相对紧密,而各区间的分布则相对分散,接下来就是无量纲化处理.
步骤1 无量纲化分层点的确定.统计各分层区间Ωλ内原始数据个数ηω(ω=1, 2, …, λ),计算其占全部数据个数的百分比,
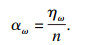 | (4) |
步骤2 无量纲化分位数的确定.计算相邻分层区间的差值Δεj(Δεj=x(φ+1)j-xφj, 1≤φ≤n-1, ε=1, 2, …, λ-1),根据相邻数据集的个数对差值Δεj进行均分,并依此确定相应的分位数,记为γl,
 | (5) |
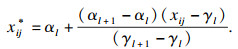 | (6) |
由于本文的无量纲化方法是基于数据分布特征进行区间划分,因此若原始数据无明显分布特征、数据太过杂乱或者数据分布呈现特殊状态时,可使用四分位分层无量纲化方法进行数据处理.
密度分层无量纲化方法,主要特征是基于指标数据分布的疏密程度划分区间,从而根据分层无量纲化方法的原理进行处理.通过该方法,将分布相近的数据划分在同一区间内,各区间则相距较远;与此同时,还可将异常数据与正常数据划分开,避免了将异常值与正常值划分在同一区间后,正常数据被压缩而无法发挥作用的可能.总的来说,本文方法在保证客观划分分层区间的基础上,提高了无量纲化结果分布的均衡性.
3 均衡性分析在分层无量纲化方法中四分位法最为常用,但其合理性以及结果的均衡性无法得到保证; 而本文方法在分层无量纲化方法的基础上,实现了对分层区间的客观划分.因此,为了突出本文方法的优势,将本文方法与四分位分层无量纲化方法进行均衡性对比.本文采用模拟仿真的方法从原始数据个数、异常值个数和偏离方向入手,探究两种方法下无量纲化结果的分布均衡性.无量纲化后数据分布均衡性的判断,采用文献[19]中的测度值.均衡性测度值越小,表明数据的均衡性越高.
针对异常值主要从以下2种情形进行分析:1)在原始数据的最小值方向生成1个异常值;2)在原始数据的最大及最小值方向分别生成1个异常值,2个异常值方向相反.异常值的产生方式分别为:max{xij}+cσt(i=1, 2, …, n)和min{xij}-cσt(i=1, 2, …, n).其中:σ为原始指标数据{x1j, x2j, …, xnj}的标准差;c(c<0)为偏离系数,cσ为异常值偏离原始数据的步长;t为步长的个数,取值为自然数.为了能够使产生的异常值足够偏离原始正常数据,本文取c=0.4, t=10.
本文运用模拟仿真技术对无量纲化结果进行均衡性分析,具体仿真过程如下所示.
1) 设置总仿真次数sum、原始数据个数n及其取值区间(设为[a, b],结果不受a, b取值的影响),循环变量v(初始值为0),初始变量s(初始值为0);2) 令v=v+1,在[a, b]内按正态分布方式随机生成n个原始数据,记为{x1, x2, …, xn};3) 在原始数据的基础上根据前文所示异常值的生成公式,生成异常数据;4) 对数据进行无量纲化处理,并将处理后的结果记为{x1*, x2*, …, xn*};5) 计算无量纲化后结果的均衡性测度值,记为Vs;6) 令s = s + Vs,若v=sum,则转7),否则转2);7) 求解sum次仿真过程中均衡性测度值的平均偏差,记为s=s/sum,并保存值;8)变动1)中的原始数据个数n的取值和异常值,并重复步骤1)~7),保存不同n值、不同异常值下取值,退出程序.
按照上述步骤,本文按正态分布的方式随机生成15, 20, 25, 30, 35, 40, 45, 50, 75和100个原始数据,根据异常值的两种情形分别进行模拟,具体结果如图 1和图 2所示.
图 1(Fig. 1)
 | 图 1 1个异常值时不同原始数据个数下无量纲化结果分布的均衡性Fig.1 Equilibrium of dimensionless result distribution under different numbers of raw data with 1 outlier |
图 2(Fig. 2)
 | 图 2 2个正负异常值时不同原始数据个数下无量纲化结果分布的均衡性Fig.2 Equilibrium of dimensionless result distribution under different numbers of raw data with two positive and negative outliers |
通过图 1中的数值比较,可以得到如下结果:
1) 当原始数据个数超过30后,运用本文方法对存在异常值的原始指标数据进行无量纲化处理,其结果分布的均衡性明显优于四分位分层无量纲化方法,且差距越来越大.这表明,当原始数据规模超过30后,运用本文方法进行无量纲化处理更为客观合理.
2) 随着原始数据规模的增大,运用四分位分层无量纲化方法进行处理所得结果的均衡性测度值变动幅度较大,而运用本文方法所得均衡性测度值的变动幅度则相对较缓.这表明,本文方法的稳定性优于四分位分层无量纲化方法.
3) 两种方法的均衡性测度值随原始数据规模的增大而增大.这表明,无论使用哪种方法,无量纲化结果分布的均衡性随着原始数据个数的增多而减弱.
当原始数据中存在正负2个异常值时,其结果的均衡性与存在1个异常值时类似,如图 2所示.在此种情形下本文方法的均衡性变动幅度更为平缓,而四分位分层无量纲化方法则相反,这进一步表明本文方法的稳定性更高,能更好地抵抗异常值的干扰.另外,拉依达准则进行异常值识别时,对样本量有一定的要求.也就是说,当原始数据规模越大时,本文方法对于异常值的处理越有效.因此,当原始数据个数超过30后,使用本文方法会更加有效.
综上所述,可以看出,数据分布的均衡性主要受原始数据规模的影响.当存在异常值的原始数据个数超过30后,相较于传统的分层无量纲化方法,运用密度分层无量纲化方法进行无量纲化处理,可以更好地减弱异常值的影响,同时保持更高的结构稳定性.即本文方法对异常值有更好的抗干扰性,且操作简单,在实际应用中有广泛的应用前景.
4 应用算例为验证本文提出的无量纲化方法的有效性,选用2021年《中国城市统计年鉴》数据,采用“人均地区生产总值(x1)(元)”、“每万人人均工业企业数(x2)(个)”、“地方一般公共预算收入(x3)(万元)”和“人均年末金融机构人民币各项存款余额(x4)(元)”等4个常用指标对东北三省(辽宁省、吉林省和黑龙江省)34个地级以上城市在2020年的经济发展作简要评价,原始数据如表 1所示.
表 1(Table 1)
| 表 1 原始数据 Table 1 Raw data |
由表 1的数据可以看出,34个城市关于指标x3的取值中包含2个异常值,即沈阳市(7 360 802.00)和大连市(7 026 822.00)的取值远大于其他城市的取值.表 2展示了采用极值处理法、四分位分层无量纲化方法以及本文方法分别对表 1数据进行无量纲化处理的结果.由表 2可以看出,经由本文方法和四分位分层无量纲化方法处理后,数据分布相较极值处理法更加均衡,且2种方法间的结果更加相近.
表 2(Table 2)
| 表 2 3种方法的处理结果 Table 2 Results processed by three methods | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
为进一步分析不同无量纲化方法对最终综合评价值的影响,本文分别对经3种方法处理的指标值进行集结.表 3展示了不同无量纲化方法下的评价值(yi)及序值(ri),以此分析本文方法在评价值层面的影响.为简化问题,消除指标权重的影响,在此将指标权重设置为均权,采用算术平均的方法对数据进行集结.首先,对不含异常值的3个指标“人均地区生产总值”、“每万人人均工业企业数”和“人均年末金融机构人民币各项存款余额”分别运用3种方法进行集结;然后,对全部指标进行集结,具体结果如表 3所示.
表 3(Table 3)
| 表 3 采用不同无量纲化方法得到的评价值及排序值 Table 3 Evaluation value and ranking value obtained by different dimensionless methods | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
为进一步研究各方法在两种情境下(有、无异常值)对最终评价结果的影响,本文引入皮尔逊相关系数及斯皮尔曼等级相关系数分别对评价值以及序值进行分析讨论.本文使用uj, us, um分别表示不存在异常值情况下的极值处理法、四分位分层无量纲化方法以及本文方法,使用uj*, us*, um*分别表示存在异常数据时的3种方法,r1, r2分别表示皮尔逊相关系数与斯皮尔曼等级相关系数.
通过表 4中的信息,可以看出:
表 4(Table 4)
| 表 4 皮尔逊相关系数矩阵 Table 4 Pearson correlation coefficient matrix | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1) uj, us与um三者间的相关系数关系为r1ujus(0.953)<r1ujum(0.959)<r1usum(0.999),3种方法间的一致性程度均很高,且相较于四分位分层无量纲化方法,本文方法与极值处理法间的一致性程度更高.这表明在无异常值存在的情况下,运用3种方法对原始数据进行无量纲化处理所得的评价值相近,且本文方法相较于四分位分层无量纲化方法更贴近极值处理法的结果,使得结果能够更好保留原始数据的分布特征.
2) uj*, us*与um*间的相关系数存在如下关系:r1uj*us*(0.943)<r1uj*um*(0.944)<r1us*um*(0.999).由此可以看出极值处理法与四分位分层无量纲化方法以及本文方法间的一致性程度相对较低,而后两种方法间的一致性程度较高.这表明当指标中存在异常值时,运用分层无量纲化方法和极值处理法所获得的结果差距较大,而经后两种方法处理后的结果更相近.
3) uj与uj*,us与us*以及um与um*间的相关系数关系为r1umum*(0.971)<r1usus*(0.972)<r1ujuj*(0.980),可以看出极值处理法在两种情境下的一致性程度最高,本文方法最低,四分位分层无量纲化方法介于二者之间且与本文方法更加相近.这表明异常值存在前后对于极值处理法的影响最小,当考虑了异常值指标后,由于极值处理法无法兼顾对异常值的处理,使得无量纲化后的绝大部分数据区分度不高,进而使得评价结果变动程度不大,从而无法体现出相应指标的作用,而本文方法则相对较好地克服了这一缺点.
表 5为序值间的等级相关系数,观察表 5可以得出与表 4相似的结论,且相较于评价值本文方法对于序值的影响更大,这里将不再赘述.由表 4和表 5可以看出在无异常值的情况下,运用3种方法对数据进行无量纲化处理得到的评价值及序值相近,且相对于四分位分层无量纲化方法,本文方法更贴近极值处理法的结果,能够更好地保留数据的分布特征;而在考虑了异常值指标后,极值处理法对应的评价值和序值较无异常值存在时变动最不明显,本文方法变动程度最大,四分位分层无量纲化方法介于二者之间.这说明,在本文算例中,相较于其余两种方法,运用本文方法对指标x3进行处理,更能凸显这2个指标在评价过程中的作用.因此,本文方法不仅保证了分层区间划分的客观性和保留了原始数据的分布特征,同时,保证了该指标在评价过程中的作用.
表 5(Table 5)
| 表 5 斯皮尔曼等级相关系数矩阵 Table 5 Spearman rank correlation coefficient matrix | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 结语本文提出一种新的分层无量纲化方法,即密度分层无量纲化方法.该方法依据数据分布的疏密程度划分区间,同时还能有效处理异常值对无量纲化结果造成的影响.该方法有如下特点:①运用该处理方法操作简单,易于理解;②从数据本身出发,根据数据自身分布特征划分分层区间更加贴合数据特征;③可以很好地解决异常值对最终结果的影响;④适宜编程实现,减少交互环节,可大幅提高数据分析的应用效率.对该问题的进一步研究可以从密度分层无量纲化方法的动态拓展等方面展开深入探讨.
参考文献
| [1] | Chen Y, Li W W, Yi P T. Evaluation of city innovation capability using the TOPSIS-based order relation method: the case of Liaoning Province, China[J]. Technology in Society, 2020, 63: 101330. DOI:10.1016/j.techsoc.2020.101330 |
| [2] | Dong Q K, Yi P T, Li W W, et al. Evaluation of city sustainability using the HGRW method: a case study of urban agglomeration on the West Side of the Straits, China[J]. Journal of Cleaner Production, 2022, 358: 132008. DOI:10.1016/j.jclepro.2022.132008 |
| [3] | Chao X R, Kou G, Peng Y, et al. Large-scale group decision-making with non-cooperative behaviors and heterogeneous preferences: an application in financial inclusion[J]. European Journal of Operational Research, 2021, 288(1): 271-293. DOI:10.1016/j.ejor.2020.05.047 |
| [4] | Carli R, Dotoli M, Pellegrino R. Multi-criteria decision-making for sustainable metropolitan cities assessment[J]. Journal of Environmental Management, 2018, 226: 46-61. |
| [5] | Zhang Z G, Hu X, Liu Z T, et al. Multi-attribute decision making: an innovative method based on the dynamic credibility of experts[J]. Applied Mathematics and Computation, 2021, 393: 125816. DOI:10.1016/j.amc.2020.125816 |
| [6] | Li W W, Yi P T, Li L Y. Superiority-comparison-based transformation, consensus, and ranking methods for heterogeneous multi-attribute group decision-making[J]. Expert Systems with Applications, 2023, 213: 119018. DOI:10.1016/j.eswa.2022.119018 |
| [7] | Liu Y T, Sun Z W, Liang H M, et al. Ranking range model in multiple attribute decision making: a comparison of selected methods[J]. Computers & Industrial Engineering, 2021, 155: 107180. |
| [8] | Mohammadi M, Rezaei J. Ensemble ranking: aggregation of rankings produced by different multi-criteria decision-making methods[J]. Omega, 2020, 96: 102254. DOI:10.1016/j.omega.2020.102254 |
| [9] | 郭亚军, 易平涛. 线性无量纲化方法的性质分析[J]. 统计研究, 2008, 25(2): 93-100. (Guo Ya-jun, Yi Ping-tao. Character analysis of linear dimensionless methods[J]. Statistical Research, 2008, 25(2): 93-100. DOI:10.3969/j.issn.1002-4565.2008.02.017) |
| [10] | 易平涛, 张丹宁, 郭亚军, 等. 动态综合评价中的无量纲化方法[J]. 东北大学学报(自然科学版), 2009, 30(6): 889-892. (Yi Ping-tao, Zhang Dan-ning, Guo Ya-jun, et al. Study on dimensionless methods in dynamic comprehensive evaluation[J]. Journal of Northeastern University(Natural Science), 2009, 30(6): 889-892.) |
| [11] | 胡永宏. 对统计综合评价中几个问题的认识与探讨[J]. 统计研究, 2012, 29(1): 26-30. (Hu Yong-hong. Understanding and discussion of some problems in statistical synthesis evaluation[J]. Statistical Research, 2012, 29(1): 26-30. DOI:10.3969/j.issn.1002-4565.2012.01.006) |
| [12] | Li W W, Yi P T, Zhang D N. Investigation of sustainability and key factors of Shenyang City in China using GRA and SRA methods[J]. Sustainable Cities and Society, 2021, 68: 102796. DOI:10.1016/j.scs.2021.102796 |
| [13] | Lama N, Boracchi P, Biganzoli E. Exploration of distributional models for a novel intensity-dependent normalization procedure in censored gene expression data[J]. Computational Statistics & Data Analysis, 2009, 53(5): 1906-1922. |
| [14] | Chakraborty S, Yeh C H. A simulation comparison of normalization procedures for TOPSIS[C]//International Conference on Computers & Industrial Engineering. Troyes: IEEE, 2009: 1815-1820. |
| [15] | Chen Y, Zhang D N. Evaluation and driving factors of city sustainability in Northeast China: an analysis based on interaction among multiple indicators[J]. Sustainable Cities and Society, 2021, 67: 102721. DOI:10.1016/j.scs.2021.102721 |
| [16] | Altintas K, Vayvay O, Apak S, et al. An extended GRA method integrated with fuzzy AHP to construct a multidimensional index for ranking overall energy sustainability performances[J]. Sustainability, 2020, 12(4): 1602. DOI:10.3390/su12041602 |
| [17] | Awasthi A, Omrani H, Gerber P. Investigating ideal-solution based multicriteria decision making techniques for sustainability evaluation of urban mobility projects[J]. Transportation Research Part A: Policy and Practice, 2018, 116: 247-259. |
| [18] | 李伟伟, 易平涛, 李玲玉. 综合评价中异常值的识别及无量纲化处理方法[J]. 运筹与管理, 2018, 27(4): 173-178. (Li Wei-wei, Yi Ping-tao, Li Ling-yu. Outliers recognition and the dimensionless method in comprehensive evaluation[J]. Operations Research and Management Science, 2018, 27(4): 173-178.) |
| [19] | 易平涛, 李伟伟, 李玲玉. 序比例诱导分段无量纲化方法及其影响因素[J]. 系统管理学报, 2020, 29(5): 866-873. (Yi Ping-tao, Li Wei-wei, Li Ling-yu. A segmented dimensionless method induced by ranking percentage and its influencing factors[J]. Journal of Systems & Management, 2020, 29(5): 866-873.) |
| [20] | 易平涛, 李伟伟, 郭亚军. 线性无量纲化方法的结构稳定性分析[J]. 系统管理学报, 2014, 23(1): 104-110. (Yi Ping-tao, Li Wei-wei, Guo Ya-jun. Structure stability analysis of linear dimensionless methods[J]. Journal of Systems & Management, 2014, 23(1): 104-110.) |
| [21] | 张敏, 袁辉. 拉依达(PauTa)准则与异常值剔除[J]. 郑州工业大学学报, 1997(1): 87-91. (Zhang Min, Yuan Hui. The PauTa criterion and rejecting the abnormal value[J]. Journal of Zhengzhou University of Technology, 1997(1): 87-91.) |
