
 , 苏畅, 龙涛
, 苏畅, 龙涛 天津大学 电气自动化与信息工程学院, 天津 300072
收稿日期:2022-02-28
基金项目:科技创新2030-“新一代人工智能”重大项目(2022ZD0160400);天津市科技计划项目(19ZXZNGX00050)。
作者简介:庞彦伟(1976-), 男, 河北衡水人, 天津大学教授,博士生导师。
摘要:基于卷积神经网络的双目立体匹配算法取得了重要进展, 但现有方法在弱纹理区域、细节和边缘等位置仍然存在匹配不准确的问题.立足于双目立体匹配任务中常用的匹配代价体(cost volume), 提出自适应构造与聚合多尺度代价体的双目立体匹配网络.首先将多个尺度的输入特征融合成为重组特征;然后设计可学习的特征增强模块, 为各个尺度的匹配代价体恢复所需的细节信息;最后基于全局注意力对各尺度匹配代价体进行尺度内聚合, 并提出自适应多尺度加权方法进行尺度间聚合, 筛选出适用于回归各尺度视差的匹配特征.在SceneFlow和KITTI2015数据集上的实验表明:所提方法在较小网络规模的情况下取得了有竞争力的性能表现, 验证了所提方法的有效性.
关键词:双目立体匹配匹配代价体特征增强自适应聚合
Adaptive Multi-scale Cost Volume Construction and Aggregation for Stereo Matching
PANG Yan-wei
, SU Chang, LONG Tao School of Electrical and Information Engineering, Tianjin University, Tianjin 300072, China
Corresponding author: PANG Yan-wei, E-mail: pyw@tju.edu.cn.
Abstract: Stereo matching based on convolutional neural network has made great progress. Existing methods still suffer from mismatching in weak texture regions, details and edges. Based on the cost volume commonly used in stereo matching, a stereo matching network with adaptive multi-scale cost volume construction and aggregation was proposed. Firstly, the proposed method fully fused the multi-scale features to obtain the recombined features. Then, a learnable feature enhancement module was used to recover the detail information for multi-scale cost volumes. Finally, after intra-scale aggregation based on global attention, an adaptive multi-scale weighting method was proposed for inter-scale aggregation to screen the matching features adapted to the disparity regression of each scale. Massive experiments on the SceneFlow and KITTI2015 datasets show that the proposed method achieves competitive performance with smaller network size which verifies the effectiveness of the proposed method.
Key words: stereo matchingcost volumefeature enhancementadaptive aggregation
双目立体匹配是计算机视觉领域非常关键但有很强挑战性的任务, 其目标是通过对双目图像进行像素匹配并估计深度, 广泛应用在虚拟现实[1]、自动驾驶[2]、3D人脸识别[3]等领域.
基于卷积神经网络(convolutional neural network, CNN)[4-5]的双目立体匹配近年取得了显著进展, 已有方法通过提取左右图像的特征并以此构造匹配代价体(cost volume)及对其进行聚合.根据对匹配代价体进行聚合方式的不同, 可划分为基于3D卷积的方法和基于2D卷积的方法.基于3D卷积的方法主要包括PSMNet[6],PCR-PSMNet[7]等.这类方法构建大小为H×W×D×C(H, W, D, C分别表示高度、宽度、最大视差、通道数量)的4维匹配代价体, 并采用3D卷积进行聚合.总体上该类方法精度较高,其主要缺点是计算效率低, 难以满足实时性的要求.相比于基于3D卷积的方法, 基于2D卷积的方法具有更高的计算效率, 在实时系统中具有重要应用前景.本文重点研究基于2D卷积的方法,基于2D卷积的方法主要包括iResNet[8],ESNet[9],RLStereo[10]和AANet[11]等.这类方法构建大小为H×W×D的3维匹配代价体, 并采用2D卷积进行聚合, 在大幅提高速度的同时获得了有竞争力的性能.
上述基于CNN的工作在双目立体匹配领域取得了显著进展, 但这些方法在弱纹理区域和边缘等细节区域下仍然存在误匹配、匹配点细节丢失等缺点.
上述问题出现的原因是:现有方案大多数使用的是单尺度的匹配代价体[8-10], 或使用多尺度的匹配代价体[11]但尺度间融合不充分, 这些方法没有充分利用不同尺度间的上下文信息和跨尺度特征的互补关系, 导致在弱纹理区域可能产生多对一的像素匹配从而得到不准确的视差估计结果;并且, 在深度卷积神经网络堆叠的下采样过程中损失了空间分辨率信息, 导致细节和边缘区域特征的模糊和缺失.
针对这些问题, 本文提出能够为基于卷积神经网络的双目立体匹配模型高质量构造匹配代价体、聚合匹配特征的方案, 在SceneFlow和KITTI2015数据集上的实验表明:本文方法在较小网络规模的情况下, 在弱纹理区域、边缘和实际场景中具备鲁棒的匹配性能.
1 研究动机基于CNN的双目立体匹配算法往往预先人为设定一个视差阈值, 即预设左右图中所有对应像素点之间的视差值范围.若以左图为基准, 匹配代价体即代表了左图像素点与右图候选像素点在所有可能视差值下的对应匹配代价.
因此, 用于计算匹配代价的特征图的质量直接决定了初步构造的匹配代价体的精度.另外, 仅考虑单个像素或像素局部区域的匹配代价是有局限性的, 特别是对于弱纹理或重复纹理区域, 该代价值很有可能无法准确反映像素之间的相关性.因此, 匹配代价体聚合通过整合每个像素在不同视差下的匹配代价并参考其邻域像素在同一视差值或附近视差值下的匹配代价对初步构造的匹配代价体进行全局优化, 从而回归最终的视差值.
根据上述原理, 本文提出自适应构造与聚合多尺度匹配代价体的双目立体匹配网络.为了增强用于构建匹配代价体的特征表达能力, 首先将多个尺度的输入特征融合成为重组特征, 然后通过可学习的特征增强模块, 将重组特征重新配置为各特定尺度相关的特征;为了对初步构造的匹配代价体进行高效聚合, 在尺度内聚合步骤, 利用匹配代价体的视差维度初步整合像素在不同候选视差下的匹配信息, 在尺度间聚合步骤, 通过自适应多尺度加权策略筛选出适用于回归各尺度视差的匹配特征.从匹配代价体特征输入和聚合两个方面出发, 本文方法充分融合了跨尺度特征的互补信息, 改善了现有方案在弱纹理区域、细节和边缘区域的误匹配情况.
当前双目立体匹配方法存在的问题见图 1.图 1c选取了AANet在SceneFlow数据集的视差估计结果, AANet是发表在CVPR2020的双目立体匹配代表性方法.如图 1所示, 在第1张图像框选出的弱纹理区域, 由于其纹理特征单一且与背景物体的颜色和纹理相似, 该区域与背景物体交界部分的视差被错误估计;在第2张图像框选出的细节区域, 由于其与背景物体的纹理产生了混淆且可能在下采样过程中造成了信息损失, 因此在视差估计中产生错误;在第3张图像框选出的边缘区域, 由于该区域边缘多且各条边缘间距离小导致视差跳变频繁, 可能受到空间分辨率损失的影响, 导致边缘区域视差估计不准确.针对这些问题, 本文提出自适应构造与聚合多尺度代价体的双目立体匹配网络.如图 1d所示, 本文方法在弱纹理、细节和边缘等情况, 都显示出了比较稳健的检测效果.
图 1(Fig. 1)
 | 图 1 当前双目立体匹配方法存在的问题Fig.1 Poor performance of existing methods on stereo matching (a)—双目左图;(b)—真值标签;(c)—AANet结果;(d)—本文结果. |
2 双目立体匹配网络本文所提自适应构造与聚合多尺度匹配代价体的双目立体匹配网络如图 2所示.给定一组双目RGB图像, 首先通过对左、右图权值共享的特征提取网络生成1/3,1/6,1/12三个尺度的左、右特征图, 再通过关联左右特征图构造多尺度的匹配代价体, 然后由6个堆叠的自适应多尺度匹配代价体聚合模块对其聚合, 并对聚合后的匹配代价体进行视差预测和细化, 最终生成与原图尺寸相同的视差图.
图 2(Fig. 2)
 | 图 2 自适应构造与聚合多尺度匹配代价体的双目立体匹配网络Fig.2 Adaptive multi-scale cost volume construction and aggregation for stereo matching |
本文主要工作是基于匹配代价体的特征输入和聚合.
2.1 特征重组与特征增强特征提取网络提取特征作为输入构造匹配代价体, 融合充分、具备细节表达力并自适应于各尺度匹配代价体的输入特征对构造多尺度匹配代价体至关重要.仅通过骨干网络最终提取的特征构造单一尺度匹配代价体的方法由于对尺度间上下文信息利用不足, 在大面积的弱纹理区域往往难以找到准确的匹配点, 且深层网络在堆叠的下采样过程中损失了空间分辨率信息, 容易导致细节和边缘区域视差的错误估计.针对这些问题, 如图 2中虚线框所示, 本文提出包含特征重组与特征增强的金字塔特征增强模块(enhanced feature pyramid module, EFPM).
骨干网络采用结构如表 1所示的40层ResNet[12]:对给定的一组双目图像, 使用权重共享的ResNet分别对左、右图提取1/3,1/6,1/12分辨率的多尺度特征金字塔.为了增大感受野, 在layer3中将普通的3×3卷积替换为膨胀的可变形卷积(deformable convolution)[13], 膨胀率(dilation rate)设为2, 变形组(deformable groups)设为2.
表 1(Table 1)
| 表 1 40层ResNet结构 Table 1 Structure of 40-layers ResNet |

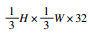






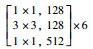

针对弱纹理区域的匹配, 本文通过特征重组方法, 得到多尺度特征充分融合的重组特征, 对骨干网络ResNet提取到的不同分辨率特征图分别进行卷积和上采样, 调整通道数量和大小相同后再将结果拼接(concatenate)到一起, 拼接结构细节如表 2所示.
表 2(Table 2)
| 表 2 金字塔特征重组结构细节 Table 2 Structure details of feature pyramid recombination |
考虑到深层网络提取到的特征虽然包含更多的上下文信息, 但在大量的下采样过程中可能丢失了浅层网络提取到的颜色纹理等特征, 不利于进行双目立体匹配任务中大面积弱纹理区域、重复纹理区域等具有挑战性场景的像素匹配, 因此增加对浅层大分辨率特征图的利用, 与此同时通过减少小分辨率特征图的数量来平衡计算量.经过卷积和上采样后, 模型分别从骨干网络三个尺度的特征输出中学习到4组特征, 特征图大小与原1/3分辨率特征图的大小相同, 通道数量均为64.
图 3展示了不同的金字塔特征重组方式, 如图 3a所示, 相加重组是将不同分辨率的特征图输入通过卷积核分别为3×3,1×1,1×1的卷积将通道数量调整为128,64,64, 再通过不同比率的上采样调整到同一分辨率(H/3)×(W/3), 然后直接相加;如图 3b所示, 拼接重组是将不同分辨率的特征图通过卷积核分别为3×3,1×1,1×1,1×1的卷积将通道数量调整为64,64,64,64, 再通过不同比率的上采样将分辨率调整到(H/3)×(W/3)后拼接起来.图 3c,图 3d相比图 3a,图 3b输出更小分辨率的特征图, 其将不同分辨率的特征图通过卷积和上采样调整为(H/6)×(W/6), 再相加或拼接起来.实验测得大分辨率版本相比小分辨率版本, 以少量的参数量增加换取了匹配精度提升.
图 3(Fig. 3)
 | 图 3 不同的特征重组方式Fig.3 Different ways of feature recombination (a)—大分辨率下相加重组;(b)—大分辨率下拼接重组;(c)—小分辨率下相加重组;(d)—小分辨率下拼接重组. |
然而仅仅通过上采样并不能恢复在堆叠的下采样过程中丢失的细节特征和空间分辨率信息, 针对细节和边缘区域的匹配, 本文提出了如图 4所示的自适应特征增强方法, 能让网络更好地学习到对于不同尺度的特征, 哪些空间位置的信息需要被强调和补充.全局平均池化为每个像素学习一个权重, 增大有用的特征, 弱化无用特征, 从而达到特征筛选和增强的效果.同时, 应用1×1卷积引入残差, 使网络能精细调整每一像素上的特征融合权重, 以达到更好的特征增强效果.
图 4(Fig. 4)
 | 图 4 自适应特征增强模块Fig.4 Adaptive feature enhancement module |
2.2 多尺度匹配代价体构造在特征提取网络后, 在特征金字塔的每一个尺度上, 通过对左右特征图进行水平方向的相关(correlation)操作构造多尺度代价体:
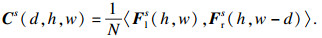 | (1) |
如图 5所示, 在每个候选视差下对左特征图和经过对应视差偏移的右特征图做内积构造D×H×W的三维匹配代价体, 其中D维度表示候选视差(0, 1, …, Dmax-1).
图 5(Fig. 5)
 | 图 5 三维匹配代价体构造Fig.5 3D cost volume construction |
2.3 多尺度匹配代价体聚合网络匹配代价体包含每个像素在每个候选视差下的匹配代价, 对其进行聚合优化使聚合后的匹配代价体能够更准确反映像素之间的相关性, 从而回归出更准确的像素视差.仅对各尺度匹配代价体孤立地进行聚合的方法忽略了跨尺度特征的互补关系, 导致在弱纹理区域可能产生多对一的像素匹配并得到不准确的视差估计结果, 而仅对多尺度匹配代价体进行固定等权相加的方法容易导致不同尺度匹配代价体的特征不一致问题并引起混淆.针对这些问题, 如图 2中虚线框所示, 本文提出自适应多尺度聚合模块(adaptive multi-scale aggregation module, AMAM), 包含基于空间注意力机制的尺度内聚合和基于全局池化加权的尺度间聚合.
在尺度内聚合步骤, 首先使用包含空间注意力模块的残差模块(Resblock)对匹配代价体进行尺度内聚合.Resblock包含1×1,3×3,1×1三个卷积并带有残差连接.由于在双目立体匹配任务中采用水平方向的相关操作构造匹配代价体使三维匹配代价体的通道维度代表候选视差, 因此利用空间注意力对每个像素在候选视差范围内(即所有通道下)做全局池化, 可以整合像素在不同候选视差下的匹配信息, 弥补相关操作带来的信息损失.另外, 为了扩大感受野以引导网络更好利用上下文信息, 该步骤还引入了膨胀的可变形卷积, 膨胀率为2, 变形组为2, 即将所有视差候选值均匀划分为2组, 共享学习到的偏移量和位置相关的权重, 但考虑到对运算量的影响, 膨胀的可变形卷积只在后三个堆叠的模块中采用.
在尺度内聚合后, 不同于调整分辨率后直接相加(图 6a)和固定等权相加(图 6b)的多尺度匹配代价体聚合方法, 尺度间权重融合策略为每个尺度的匹配代价体学习一个权重矩阵(图 6c), 通过自适应加权聚合的方式筛选出自适应于各相应尺度匹代价体的特征, 充分利用了跨尺度特征的互补信息, 解决了不同尺度匹配代价体的特征不一致问题.
图 6(Fig. 6)
 | 图 6 不同的匹配代价体聚合策略Fig.6 Different methods of cost volume aggregation (a)—直接相加;(b)—固定权重相加;(c)—自适应权重相加. |
首先对不同尺度匹配代价体通过卷积和上采样将分辨率和通道数量调整一致, 再对调整后的各尺度匹配代价体自适应学习权重相加:
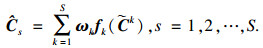 | (2) |
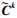

 | (3) |
假定H, W, D分别表示裁剪后图像的高度、宽度、最大视差值(本文为192), 根据上述过程, 以最高尺度代价体C∈R1/3H×1/3W×1/3D为例, 其尺度间自适应加权聚合过程如图 7所示, 首先将两个小分辨率的匹配代价体通过卷积和上采样使其与最高分辨率相同, 再对其分别进行最大池化、平均池化和7×7卷积并将结果拼接到一起, 通过softmax函数回归出权重α, β, γ与三个尺度代价体分别对应相乘, 将结果相加后得到自适应高效聚合的代价体.
图 7(Fig. 7)
 | 图 7 尺度间自适应加权聚合Fig.7 Inter-scale adaptive weighted aggregation |
最终的代价聚合网络由6个堆叠的自适应多尺度聚合模块组成, 在卷积过程中每个尺度匹配代价体都保持通道数量始终等于候选视差的数量.最后一个堆叠的聚合模块后通过1×1卷积生成3个尺度的聚合匹配代价体.
2.4 视差预测和视差细化网络视差预测模块采用soft argmax函数[14]获取视差预测值:
 | (4) |
视差细化(refinement)模块遵循StereoDRNet[15]的工作, 首先计算重建误差:
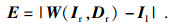 | (5) |
2.5 损失函数本文提出的模型是一个端到端可训练的网络, 在最后的视差预测步骤以视差真值作为监督:
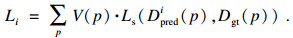 | (6) |
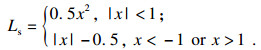 | (7) |
 | (8) |
3 实验结果与分析3.1 实验细节为验证所提方法的有效性, 本文在双目立体匹配数据集SceneFlow[16]和真实场景数据集KITTI2015[17]上进行了实验.SceneFlow数据集是一个大规模的合成数据集, 包含35 454张训练图像和4 370张测试图像, 并提供了视差真值标注, 图像大小为H×W=540×960.SceneFlow数据集包含cleanpass和finalpass两个RGB图像版本, cleanpass版本没有图像退化, 而finalpass版本对图像做了额外的模拟景深模糊、运动模糊和伽马曲线操作等后处理效果.KITTI2015数据集包含200对训练图像和200对测试图像, 图像的尺寸约为375×1 242像素, 但每张图像的尺寸不尽相同.它是由安装在汽车车顶上一对经过校准的相机拍摄的真实场景构成, 这些场景主要包括道路、行人、城市、街区和学校等.利用三维激光扫描仪结合汽车的运动数据, KITTI提供了稀疏的视差真值标签.
本文工作在PyTorch深度学习框架下实现, 并使用自适应矩估计(adaptive moment estimation, Adam)(β1=0.9, β2=0.999)作为优化器端到端训练.本文在4个GTX 1080Ti GPU上训练提出的模型, 在SceneFlow数据集上, 将原始图像随机裁剪成288 576, 批处理大小(batch size)为16, 共训练85个epoch.学习率初始值设置为5×10-4, 自第20个epoch开始, 每经过10个epoch, 学习率下降为之前的一半.在KITTI数据集上, 将原始图像随机裁剪成336×960, 批处理大小为8, 首先在KITTI2012和KITTI2015的混合训练集上对在SceneFlow数据集上的预训练模型进行微调, 共训练1 000个epoch, 然后在单独的KITTI2015训练集上再训练1 000个epoch, 并采用4倍交叉验证(cross validation), 初始学习率为5×10-4, 从第200个epoch开始, 每经过100个epoch, 学习率下降为之前的一半.另外, 遵循AANet的做法, 利用预先训练的GANet对稀疏的真值标签进行填充, 以减少真值标签缺失区域(例如天空区域)的伪像.对所有图像均采用ImageNet均值和标准差进行归一化处理.
3.2 所提模块有效性验证为验证本文所提出的金字塔特征增强模块(EPRM)和自适应多尺度聚合模块(AMAM)的有效性, 在SceneFlow数据集的cleanpass版本上进行消融实验, 实验结果如表 3~表 5所示, 其中Δ表示各种方法实验结果与基线实验结果的差值.本文的基线方法是AANet[11], 基线实验结果由作者提供的代码按照给定的训练参数在两块NVIDIA GTX 1080Ti显卡训练后进行测试得出.
表 3(Table 3)
| 表 3 不同特征图分辨率参数量和精度比较 Table 3 Parameters vs EPE of different output resolutions |


表 4(Table 4)
| 表 4 EFPM消融实验 Table 4 Ablation experiments of EFPM |
表 5(Table 5)
| 表 5 AMAM消融实验 Table 5 Ablation experiments of AMAM |
对特征金字塔重组模块, 实验测试了不同的特征重组方式和特征增强模块的引进对模型性能的影响.在不同尺度特征的重组方式上, 实验测试了矩阵元素相加和拼接(concatenate)两种特征重组方式及其不同分辨率下的性能.首先, 如表 3所示, 实验测得大分辨率版本相比小分辨率版本, 以少量的参数量增加换取了匹配精度提升.
表 4的实验结果表明, 与传统特征金字塔融合骨干网络特征的方法(基线方法)相比, 所提特征重组方法通过对高、中、低分辨率特征进行一次性完全融合, 充分利用了跨尺度特征的互补能力, 拼接重组方法将结果降低了0.08像素误差.所提特征增强模块通过全局池化对特征进行筛选和增强.与基线方法相比, 所提金字塔特征增强模块同时使用拼接重组方法和特征增强方法, 恢复了在下采样中丢失的空间分辨率信息和细节特征, 解决了多尺度特征融合不充分、细节表达力不足的问题, 使平均视差误差降低了0.1像素左右.
在自适应多尺度聚合模块, 实验测试了在尺度内代价体聚合步骤中引入全局注意力机制、在尺度间代价体聚合步骤中采用可学习加权聚合方法对模型性能的影响.表 5的实验结果表明, 在尺度内代价体聚合步骤, 通过全局注意力整合了像素在不同候选视差下的匹配信息, 相比基线方法降低了0.095像素误差.在尺度间代价体聚合步骤, 与基于固定等权相加的尺度间代价体聚合方法(基线方法)相比, 所提出的基于全局池化的自适应加权聚合方法筛选出了自适应于各相应尺度代价体的特征, 充分利用了跨尺度特征的互补信息, 缓解了不同尺度代价体的特征不一致问题, 将像素的平均误差降低了0.05像素.将上述可学习、自适应的尺度内代价体聚合和尺度间代价体聚合方法结合, 所提方法相比基线方法将误差降低了0.1像素左右.
3.3 实验结果分析为了验证本文方法在双目立体匹配任务上的优越性, 本文在SceneFlow数据集的finalpass版本上与一些优秀的端到端模型就参数量、浮点运算数(FLOPs)和端点误差(EPE)进行比较.如表 6所示, 本文方法的EPE为0.86, 均优于其他5个对比方法(其中, PSMNet, PCR-PSMNet为基于3D卷积的代表性方法, iResNet, ESNet, RLStereo为基于2D卷积的代表性方法).表 7展示了本文方法与代表性方法网络规模的比较, 可以看出本文方法的参数量和FLOPs均为最低, 表明本文方法在网络规模上具备轻量性优势.得益于金字塔特征增强模块和多尺度匹配代价体聚合模块的有效设计, 本文方法与PSMNet相比, 在参数量下降25%,FLOPs下降16倍的情况下, EPE提升了21%, 表明即使不使用3D卷积, 也可以取得领先水平的匹配精度;与RLStereo相比, 在参数量下降46%的同时, EPE提升了7.5%, 充分体现了本文方法的高效性与精准性.与基线方法AANet相比, 本文在相同实验条件下对AANet的复现结果(*)与原文结果有些差距, 但本文方法比原文结果在参数量、FLOPs和EPE上均有更好的表现.
表 6(Table 6)
| 表 6 与其他方法在SceneFlow数据集上的比较 Table 6 Comparison with other methods on SceneFlow dataset |
表 7(Table 7)
| 表 7 网络规模的比较 Table 7 Comparison of network size |
图 8,图 9展示了本文所提方法在SceneFlow测试集上的可视化结果, 在较小网络规模的情况下, 本文方法提高了模型在大面积的重复纹理和弱纹理区域以及细节和边缘的表现.如图 8第一张图像的测试结果所示, 在框选出的大面积的弱纹理区域, 本文方法相比AANet可以更精准预测视差;如图 9第二张图像和第三张图像的测试结果所示, 在框选出的锯齿状薄结构和植被边缘等细节部分, 本文方法相比AANet更有效地保留细节信息, 充分表明所提基于特征金字塔增强模块提取高度融合特征构造匹配代价体的方法和基于自适应多尺度加权策略聚合匹配代价体的方法的有效性.
图 8(Fig. 8)
 | 图 8 在SceneFlow测试集上关于弱纹理区域的可视化结果Fig.8 Visualization results of weak texture regions on the SceneFlow test set (a)—双目左图;(b)—真值标签;(c)—AANet结果;(d)—本文结果. |
图 9(Fig. 9)
 | 图 9 在SceneFlow测试集上关于细节和边缘的可视化结果Fig.9 Visualization results of details and edges on the SceneFlow test set (a)—双目左图;(b)—真值标签;(c)—AANet结果;(d)—本文结果. |
为进一步验证本文方法在实际场景中的匹配性能, 在KITTI2015数据集上进行实验.表 8给出了本文方法与一些优秀的端到端模型就3像素误差(3-px)进行比较的结果, 可以看到, 本文所提方法的3-px为2.43%, 均优于其他几个对比方法.
表 8(Table 8)
| 表 8 与其他方法在KITTI2015数据集上的比较 Table 8 Comparison with other methods on KITTI2015 dataset? | ||||||||||||||||||||||||||||||||||||||||||
为更直观体现本文方法在实际场景下的匹配性能, 图 10展示了本文方法在KITTI2015验证集上的可视化结果.如图 10中左图框选区域所示, 本文方法清楚地还原了图中框选的两组车辆的远近关系, 也准确地估计了颜色、纹理与背景楼墙相似的框选的路标的视差.可视化结果表明,所提基于金字塔特征增强方法提取高度融合特征作为输入构造多尺度匹配代价体的方法和基于自适应多尺度加权方法聚合多尺度匹配代价的方法在实际场景下也具有鲁棒的匹配性能, 具有实际应用意义.
图 10(Fig. 10)
 | 图 10 在KITTI2015验证集上的可视化结果Fig.10 Visualization results on KITTI 2015 validation set (a)—双目左图;(b)—稀疏真值标签;(c)—本文预测结果. |
4 结论1) 提出了基于特征金字塔重组与特征增强模块的特征融合方案, 首先将骨干网络提取的多尺度特征融合成为重组特征, 然后通过自适应的特征增强模块将重组特征重新配置为各特定尺度相关的特征, 增强了各特定尺度特征的局部敏感性.
2) 提出了基于空间注意力的尺度内聚合和基于全局池化加权的尺度间聚合方案, 首先利用匹配代价体的视差维度初步整合了像素在不同候选视差下的匹配信息, 然后通过自适应多尺度加权聚合策略筛选和强化了适用于回归各尺度视差的匹配特征.
3) 基于匹配代价体特征输入和匹配代价体聚合, 构造了一个端到端学习的双目立体匹配网络.在SceneFlow数据集和KITTI2015数据集上的实验表明,本文方法在较小网络规模的情况下, 在弱纹理区域、边缘和实际场景中具备鲁棒的匹配性能.
参考文献
| [1] | Zhao Q, Zhou B, Jia L I, et al. A brief survey on virtual reality technology[J]. Science and Technology Review, 2016, 34(14): 71-75. |
| [2] | Chen C Y, Seff A, Kornhauser A, et al. Deepdriving: learning affordance for direct perception in autonomous driving[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, 2015: 2722-2730. |
| [3] | Oisel L, Mémin é, Morin L, et al. One-dimensional dense disparity estimation for three-dimensional reconstruction[J]. IEEE Transactions on Image Processing, 2003, 12(9): 1107-1119. DOI:10.1109/TIP.2003.815257 |
| [4] | 李晶皎, 马利, 王爱侠, 等. 基于改进Patchmatch及切片采样粒子置信度传播的立体匹配算法[J]. 东北大学学报(自然科学版), 2016, 37(5): 609-613. (Li Jing-jiao, Ma Li, Wang Ai-xia, et al. Stereo matching algorithm based on improved Patchmatch and slice sampling particle belief propagation[J]. Journal of Northeastern University(Natural Science), 2016, 37(5): 609-613.) |
| [5] | 张之敏, 乔建忠, 林树宽, 等. 一种基于深度网络的视图重建方法[J]. 东北大学学报(自然科学版), 2020, 41(8): 1065-1069. (Zhang Zhi-min, Qiao Jian-zhong, Lin Shu-kuan, et al. A view reconstruction method based on deep network[J]. Journal of Northeastern University(Natural Science), 2020, 41(8): 1065-1069.) |
| [6] | Chang J R, Chen Y S. Pyramid stereo matching network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 5410-5418. |
| [7] | Deng H, Liao Q, Lu Z, et al. Parallax contextual representations for stereo matching[C]//Proceedings of the IEEE International Conference on Image Processing. Anchorage, 2021: 3193-3197. |
| [8] | Liang Z, Feng Y, Guo Y, et al. Learning for disparity estimation through feature constancy[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 2811-2820. |
| [9] | Huang Z, Norris T B, Wang P. ES-Net: an efficient stereo matching network[C]//Proceedings of the IEEE International Conference on Intelligent Robots and Systems. Prague, 2021. |
| [10] | Yang M, Wu F, Li W. RLStereo: real-time stereo matching based on reinforcement learning[J]. IEEE Transactions on Image Processing, 2021, 30: 9442-9455. DOI:10.1109/TIP.2021.3126418 |
| [11] | Xu H F, Zhang J Y. AANet: adaptive aggregation network for efficient stereo matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 1956-1965. |
| [12] | He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 770-778. |
| [13] | Dai J F, Qi H Z, Xiong Y W, et al. Deformable convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, 2017: 764-773. |
| [14] | Kendall A, Martirosyan H, Dasgupta S, et al. End-to-end learning of geometry and context for deep stereo regression[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, 2017: 66-75. |
| [15] | Chabra R, Straub J, Sweeny C, et al. StereoDRNet: dilated residual stereo net[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 11786-11795. |
| [16] | Mayer N, Ilg E, Hausser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 4040-4048. |
| [17] | Menze M, Geiger A. Object scene flow for autonomous vehicles[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, 2015: 3061-3070. |
