
 , 谢永芳
, 谢永芳 中南大学 自动化学院,湖南 长沙 410083
收稿日期:2021-10-28
基金项目:国家自然科学基金资助项目(62133016,61773405);中央高校基本科研业务费专项资金资助项目(2020zzts577)。
作者简介:林清扬(1997-),男,广东汕头人,中南大学硕士研究生;
陈晓方(1975-),男,福建福州人,中南大学教授,博士生导师;
谢永芳(1972-),男,河南郑州人,中南大学教授,博士生导师。
摘要:过热度是反映铝电解槽当前生产效率的重要指标,由于过热度难以在线实时测量,本文提出一种基于残差卷积自注意力神经网络的过热度识别方法.针对铝电解生产过程数据为时间序列数据且具有多源异构特性,设计异构数据的同构表示方法.在此基础上建立残差卷积自注意力神经网络模型以提取同构时间序列数据的全局与局部特征.针对过热度数据标签少且类别分布不均匀问题,采用基于自动编码器的无监督预训练方法与加权交叉熵损失函数以提高过热度识别任务的性能.在基准数据集上进行仿真对比实验以验证本文所提方法的有效性,然后在只包含少量不平衡标签的铝电解过热度数据集上进行实验验证,结果表明本文构建的过热度识别模型相较与其他现有模型不仅提高了过热度识别准确率,而且在训练样本较少时保证了模型的泛化能力.
关键词:过热度识别多源异构残差卷积自注意力机制无监督预训练铝电解过程
An Superheat Identification Method in Aluminium Electrolysis Based on Residual Convolutional Self-Attention Neural Network
LIN Qing-yang, CHEN Xiao-fang
, XIE Yong-fang School of Automation, Central South University, Changsha410083, China
Corresponding author: CHEN Xiao-fang, E-mail: xiaofangchen@csu.edu.cn.
Abstract: Superheat is an important indicator to reflect the current production efficiency of aluminium electrolytic cells. Due to the difficulty of superheat online real-time measurement, this paper proposes a superheat identification method based on residual convolution self-attention neural network (RCSANN). As the production data in aluminium electrolysis process is time series data and featured with multi-source heterogeneous characteristics, the isomorphic representation method is designed for heterogeneous data. On this basis, the RCSANN superheat model is proposed to extract the global and local features of the isomorphic time series data. Aiming at the problem of few labels and uneven category distribution of superheat data, the unsupervised pre-training method based on auto-encoder and the weighted cross-entropy loss function are used to improve the performance of the superheat identification task. The validity of the proposed method is verified by simulation and comparison experiments on the benchmark dataset. Then, experiments are carried out on the dataset of superheat in aluminium electrolysis with only a few unbalanced labels. The results show that not only the accuracy of superheat identification is improved compared with other existing models, but also the generalization ability can be guaranteed under few training labeled-samples.
Key words: superheat identificationmulti-source heterogeneousresidual convolutional self-attention mechanismunsupervised pre-trainingaluminium electrolysis process
铝是国民经济发展的重要基础原材料,广泛应用于航天航空、交通运输、民用建筑、电力电子等领域.铝电解槽是铝电解工业生产的主要设备,其运行情况的好坏将直接影响到铝电解厂的生产、产品质量和能源消耗[1].过热度是反映铝电解槽当前生产效率与质量的关键指标之一,保持适当的过热度,可以提高电流效率,稳定生产过程,降低生产能耗.过热度为电解质温度与初晶温度的差值[2].由于缺乏有效的初晶温度测量技术,当前铝电解厂实际生产过程中,过热度主要由工艺人员肉眼观察火眼视频进行判断.但由于铝电解槽生产环境温度高、磁场大、腐蚀性强,会对人工判断造成很大的干扰.同时人工判断过热度的过程严重依赖于小部分经验丰富的工艺人员,判断过程存在主观因素,不利于过热度的精确判断.长期依赖工人经验来识别过热度情况会造成生产过程不稳定、产品质量一致性差、能源消耗大等情况,不利于高效节能生产[3].为此,高效、准确地对过热度进行识别,可提高铝电解生产过程的生产效率,为实现铝电解过程的精细化智能控制提供技术支撑.
近些年,随着大数据分析技术的发展,很多****提出了生产数据驱动的方法来代替工艺人员进行过热度识别.铝电解生产数据主要来源于铝电解生产过程由传感器在线实时获得的短采样间隔的时间序列数据与人工离线化验获得的长采样间隔的时间序列数据.基于生产数据的铝电解过热度识别存在以下挑战:1)生产数据采样频率不一致,同时数据的表现形式也存在差异;2)由于生产中传感器偶发的故障以及传输过程中环境的干扰,生产数据存在少量缺失;3)由于实际生产过程中过热度由工艺人员进行决策判断,获得过热度标签代价较大,过热度标签相对生产数据较少,且标签类别数量不均衡.针对铝电解槽过热度识别方法,许多****作了深入的研究.郭英杰等[4]提出一种基于时间粒的铝电解过热度预测方法,根据经验值确定滑动窗口和时间粒的天数大小,构建特征集,然后用分类器预测过热度.Lei等,Min等[5-6]提出了改进的极限学习机,并用于过热度识别,同时采用无标签样本基于半监督学习方法来提高模型的精度.上述方法针对生产数据存在缺失与错误、样本标签少的问题作了不同的探索研究,但这些方法属于静态建模方法,假设铝电解生产过程中属性变量波动不大,对于不同采样频率的时间序列数据采用取平均值、标准差与极值的方法来统一采样频率并构建样本集.这种处理方法简化了反映铝电解生产过程中不同时刻生产数据变化情况的时间序列信息,缺乏对生产数据动态变化的描述.
为解决铝电解过程过热度识别中动态变化数据建模的问题,需采用时间序列分类方法.基于传统机器学习的时间序列分类方法主要是基于Shapelets[7-8]、DTW[9]等特征与不同的距离度量[10],采用最近邻分类器[10]、决策树[11]、随机森林[12]、集成学习[13]等方法,来对时间序列进行分类.但这些方法对时间序列分类方法使用的特征均为人工设计,难以灵活地提取深层次的特征.最近几年,深度学习[14]发展迅速,在多个识别任务[15-18]上取得极大进展.在时间序列分类领域中,采用卷积神经网络[19](convolutional neural network, CNN)、长短期记忆网络[20](long short-term memory, LSTM)等方法可自动学习到样本的特征提取方式,在识别任务中显著提高识别准确率.但CNN中每层卷积层提取的特征为局部领域特征,单个卷积层难以获得数据的全局特征;LSTM对时间序列数据的长距离特征提取能力较短距离特征弱,存在一定的长期依赖性问题,推理时无法并行化,运行效率低.如何从铝电解过程异构且动态变化的数据中提取全局特征,实现过热度的智能识别,仍是一项具有挑战性的工作.
为此,本文首先设计一种多源异构数据的同构表示方法,将铝电解生产过程与过热度相关的数据统一表示为多维时间序列数据.然后,构建基于多头自注意力的残差卷积自注意力模块,提取时序数据的全局和局部特征.通过堆叠残差卷积自注意力模块,建立基于残差卷积自注意力神经网络的过热度分类模型.在模型训练阶段,提出一种基于自动编码器的无监督预训练方法,以解决过热度数据标签少且类别分布不均匀的问题,同时引入加权交叉熵损失函数以降低分类模型的有偏性.基准数据集上的仿真对比实验验证本文所提方法的有效性,铝电解过热度识别的实验结果表明本文提出的方法提高了过热度识别的准确率,同时训练样本较少时保证了模型的泛化能力.
1 铝电解多源异构数据同构表示方法铝电解生产过程的多源异构数据来源于不同类型传感器,其采样点数与数据形式存在差异,直接输入识别网络会导致在网络底层不同类型数据无法信息融合,难以获得输入数据的全局注意力,造成模型的识别性能下降.为了解决该问题,本文提出了一种多源异构数据的同构表示方法,将一天内不同类型的生产数据变换为同构时间序列表示.
记X={X1, X2, X3, X4}为铝电解厂一天的多源异构生产数据,其中Xi∈RTi×Di表示第i种类型的生产数据,Ti表示每天数据采样点数,Di表示属性数量即维度.生产数据共包含4种类型:数据类型X1表示生产过程中在线实时获得的监测属性值;数据类型X2表示生产过程中人工离线化验获得的化验属性值;数据类型X3表示生产过程中在线实时获得的表示某种操作至今的时间值;数据类型X4表示生产过程中在线实时获得的表示某些生产状态的8b状态值.4种生产数据类型的差异如表 1所示.
表 1(Table 1)
| 表 1 铝电解生产数据类型 Table 1 Data type of aluminum electrolysis |
1) 在铝电解的生产过程中,生产数据的时序信息为不可或缺的重要信息.但自注意力机制本身无法对时序数据的顺序信息进行编码.所以本文采用文献[21]的位置编码方法,对生产数据的时序信息进行编码.
对一个长度为L的时序数据,其位置编码P为
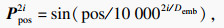 | (1) |
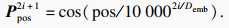 | (2) |
2) 对于数据类型X1∈RT1×D1, 其中T1=720.在时间维度上对输入数据进行一维卷积处理,其中卷积核大小为3,步长为1,扩充为1.过程表示为
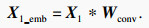 | (3) |
3) 对于数据类型X2∈RT2×D2,其中T2=1.通过线性变换将其映射到另一个向量空间,并将其沿着时间维度复制Temb次.过程表示为
 | (4) |
4) 对于数据类型X3∈RT3×D3,其中T3=720.对于每个属性维度的至今时间值向量X3d∈R1×T3, 其中d∈[1, D3], 采用固定的位置嵌入,将离散的时间值映射到固定的向量空间.
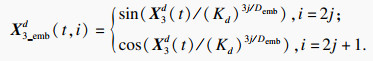 | (5) |
将所有属性维度的位置嵌入相加,得到
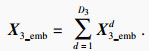 | (6) |
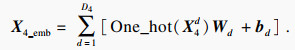 | (7) |
结合式(1)~式(7)对铝电解生产过程中不同类型的生产数据进行同构化处理,得到统一的时间序列表示Xemb∈RTemb×Demb为
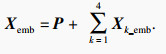 | (8) |
残差卷积自注意力模块由自注意力层与残差卷积层组成.自注意力层采用多头自注意力机制关联时间序列全局不同位置的特征与模型识别输出以计算时间序列的表示;残差卷积层采用卷积神经网络进行特征转换以关注自注意力层输出时间邻域上的局部特征信息,同时采用残差连接减少模型训练难度.
2.1 自注意力层自注意力机制关联时间序列输入的全局序列信息,对当前识别任务相关联的序列特征信息加以强化,相比LSTM网络可以更好地协调输入数据中不同范围、层次的依赖关系对输入进行建模.因此本文多头引入自注意力机制,利用全局信息对过热度的识别进行建模,自注意力机制操作如图 1所示.
图 1(Fig. 1)
 | 图 1 自注意力机制操作Fig.1 Operation of self-attention mechanism |
设自注意力层的输入X∈RL×Dk, 其中L为输入时间序列数据的时间采样点数, Dk为输入时间序列数据的属性数量即维度.首先采用3个不同的线性变换将输入X分别投影到3个不同的特征空间Q∈RL×Dk, K∈RL×Dk, V∈RL×Dk.然后,分别对矩阵Q, K, V进行均匀维度分块操作,将属性数量值维度分为相同大小的h部分得到

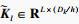
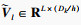
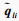
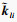
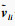
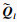
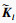
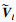
第l个自注意力输出为计算每一个
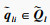
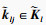
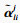

第i个时间点的查询向量
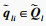
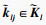
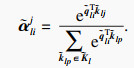 | (9) |
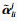
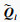
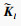
记
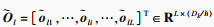
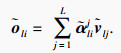 | (10) |
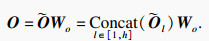 | (11) |
将多头注意力输出O与输入X相加,得到自注意力层的最终输出Y∈RL×Dk为
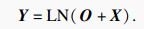 | (12) |
2.2 残差卷积层Transformer[21]模型在自注意力机制操作后,将每个采样时间点的输出结果输入FFN(feed-forward networks)层进行非线性变换,以提高模型的表达能力.FFN为两层全连接层组成,但全连接层的参数量较多,导致模型在训练数据较少时容易陷入过拟合[24],造成模型性能下降.卷积神经网络(CNN)具有空间不变性,可学习输入数据的局部特征.CNN采用局部连接与权值共享减少了神经网络模型的参数量,以缓解模型过拟合.然而,卷积层在多层堆叠时会出现网络退化现象,造成模型性能下降.残差卷积神经网络引入了残差连接的思想,将残差块的输入与输出相加作为后继网络的输入.残差连接放大了输入与输出的差异,网络只需学习输入与输出的残差,极大地减少了网络的学习难度.为了在训练数据较少时提高模型的表达能力,本文通过引入残差卷积层来代替Transformer模型中的全连接层以学习数据的局部特征,残差卷积层如图 2所示.
图 2(Fig. 2)
 | 图 2 残差卷积层Fig.2 Residual convolution layer |
残差卷积层由两层1D卷积层组成,输入X经过两层卷积层得到其输出H(X),H(X)与原输入X相加得到最终输出Y.残差连接可将某一层的输入信息直接传输至输出,避免了通过卷积层导致的信息损失,保证了模型对复杂数据的表达能力.
3 基于残差卷积自注意力神经网络的过热度识别方法基于残差卷积自注意力模块,本文构建了基于残差卷积自注意力神经网络(residual convolutional self-attention neural network, RCSANN)的过热度识别方法.
铝电解工业现场中生产数据标签数量少且分布不均匀,若只采集有标签数据进行过热度模型的识别训练,会导致识别模型过拟合,影响模型的性能.为了将工业现场中的无标签样本与有标签样本均用于过热度识别模型的训练,本文基于自动编码器的思想设计了RCSANN的无监督预训练方法,以解决铝电解生产过程标签少影响模型训练的问题.
同时由于标签分布不均匀,基于不平衡分布的标签进行模型训练会给模型引入输出偏好,导致无法得到公平的输出结果.本文在训练过程中引入了加权交叉熵损失函数代替传统的交叉熵损失函数,以减少模型的有偏性.
3.1 残差卷积自注意力神经网络结构本文构建的RCSANN由特征提取部分与分类输出部分组成,其模型结构图如图 3所示.特征提取部分堆叠4个残差卷积自注意力模块,并在残差卷积自注意力模块之间加入最大池化层.分类输出部分由全局平均池化层、Dropout层、全连接层与Softmax分类器组成.铝电解异构生产数据经过同构化处理得到统一表示的多维时间序列数据作为网络的输入,特征提取部分负责对时间序列数据的特征提取,分类输出部分将提取到的高维深度特征进行变换以得到分类结果.特征提取部分中残差卷积自注意力模块基于输入数据的全局与局部特征对其进行深度编码,最大池化层在保留主要特征的同时对数据进行维度压缩,去除数据中的冗余信息.分类输出部分对高维深度特征在时间采样点数维度进行全局平均池化,经过Dropout层神经元随机失活以降低过拟合概率,经过两层全连接层的非线性变换,再经过Softmax分类器来得到过热度的识别结果.
图 3(Fig. 3)
 | 图 3 RCSANN结构图Fig.3 The architecture of RCSANN |
3.2 基于自动编码器的无监督预训练方法由于铝电解生产过程获得的数据绝大部分为无标签数据,为了充分利用铝电解工业现场获得的生产数据来训练RCSANN,本文提出了基于自动编码器的无监督预训练方法.该方法设计基于残差卷积自注意力模块的自动编码器E,采集大量无标签生产数据对其进行重建任务训练,以无监督的方式学习到无标签数据中的共有特征.经过无监督训练得到的自动编码器E网络的编码结构作为RCSANN的预训练模型,其权重作为过热度识别训练的初始化.
自动编码器E网络的编码结构Een采用RCSANN的特征提取部分,解码结构Ede采用如图 4所示的网络结构.解码结构Ede由特征解码部分与重建输出部分两部分组成.特征解码部分负责将降维特征Z逐步重建为解码向量Xde,重建输出部分将解码向量Xde转换为重建输出
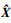
图 4(Fig. 4)
 | 图 4 自动编码器解码部分Ede结构图Fig.4 The architecture of decoder Ede |
Ede的特征解码部分堆叠4个残差卷积自注意力模块,在残差卷积自注意力模块之间加入上采样层.由于RCSANN中使用了池化操作,使得降维特征Z的时间采样点数小于输入X.在特征解码部分需采用上采样层逐步将Z的时间采样点数还原至与X一致.研究表明插值与卷积结合的方法在上采样操作中效果优于反卷积[25-26],为此,本文采用线性插值与卷积操作实现对时间序列数据的上采样.
Ede的重建输出部分将解码向量Xde重建为
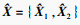

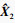
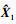
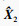
无监督预训练方法使用均方误差损失(MSE loss)作为损失函数:
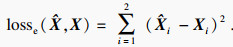 | (13) |
3.3 基于加权交叉熵的过热度识别损失函数在分类识别任务中,通常采用交叉熵损失(cross entropy loss)作为分类任务的损失函数.但是在铝电解过热度识别任务训练过程中,由于铝电解生产数据的过热度标签分布不平衡,直接使用交叉熵损失函数对训练样本进行训练,会得到有偏的模型预测结果.为了降低模型对新样本预测的有偏性,本文引入加权交叉熵损失(weighted cross entropy loss)作为过热度识别任务的损失函数:
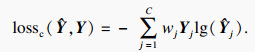 | (14) |
3.4 算法步骤基于残差卷积自注意力神经网络的铝电解过热度识别方法的算法步骤如下:
Step1?将无标签数据Xunlabel输入自动编码器网络模型E中,输出为生产数据重建值

Step2?计算


Step3?重复step1~step2 T1次,得到训练完成的自动编码器网络模型E,完成无监督预训练;
Step4?采用自动编码器网络模型E的编码结构Een参数初始化基于RCSANN的过热度识别模型G;
Step5?将有标签数据(Xlabel, Ylabel)输入分类模型G中,输出为过热度识别结果
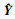
Step6?计算
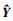

Step7?重复step5~step6 T2次,得到训练完成的过热度识别模型G;
Step8?将新采集的无标签待识别数据Xpred输入过热度识别模型G,得到过热度识别结果
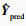
4 实验结果与分析为了验证残差卷积自注意力神经网络的有效性,本文首先在基准数据集上将RCSANN与常见的多维时间序列分类模型进行了对比,验证了RCSANN的有效性.然后,在过热度识别任务中验证了无监督预训练方法与加权交叉熵损失函数对提升模型性能的有效性.最后,将基于RCSANN的铝电解过热度识别方法与常见的方法进行了对比,验证了本文方法的有效性.
4.1 环境配置本文实验采用的主要环境配置如表 2所示.
表 2(Table 2)
| 表 2 实验主要硬件与软件配置 Table 2 Hardware and software configuration |
4.2 基准数据集验证实验4.2.1 数据集与预处理UEA-UCR[27]数据集是东英吉利大学(UEA)与加州大学河滨分校(UCR)共同发布的多维时间序列分类数据集,从数据集中选择部分数据如表 3所示,共包括7个等长多维时间序列数据集.
表 3(Table 3)
| 表 3 UEA-UCR选取数据集 Table 3 Selected dataset of UEA-UCR |
4.2.2 实验设置与结果RCSANN存在3个超参数,分别为多头注意力头数h、模型的隐藏单元大小Dk、Dropout层的概率p.经过网格搜索,得到模型的最优超参数为h=12,Dk=192,p=0.1.实验采用Adam优化器,训练过程中学习率α=0.000 05,训练轮数为400个epoch.为验证网络的有效性,本文选取以下3种深度学习算法与RCSANN进行对比:
1) MLSTM-FCN(multivariate LSTM-FCN)[28]:结合LSTM神经网络与全卷积神经网络的模型,并在卷积层中引入空间注意力;
2) TCN(temporal convolutional network)[29]:结合因果卷积和扩展卷积的一维残差神经网络模型;
3) TEC(Transformer encoder with softmax classifier)[21]:使用Transformer网络的编码层部分,并将其输出经过线性变换与Softmax分类器;该模型为完全基于自注意力机制的神经网络模型.
实验结果采用准确率(accuracy)作为评价指标,进行10次训练并取平均值,不同模型的实验结果如表 4所示.
表 4(Table 4)
| 表 4 UEA-UCR数据集实验结果 Table 4 Experimental results in UEA-UCR | |||||||||||||||||||||||||||||||||||||||||||||||||
由表 4可知,本文提出的RCSANN在所有数据集上均取得最优效果.在ArticularyWord-Recognition, Cricket, Libras与RacketSports四个102数量级的小规模数据集上,MLSTM-FCN与TCN在测试集上的准确率与RCSANN的准确率差距较小,在FaceDetection, LSST, Phoneme三个103数量级的中等规模数据集上,RCSANN具有明显的性能优势.随着训练数据规模的增大,具有多头自注意力机制的RSCANN较只基于LSTM与CNN的模型可更好地提取数据的深层特征,提高了识别的准确率.在7个数据集中,RCSANN算法的准确率均高于基于Transformer编码层的TEC,采用残差卷积层替换Transformer模型中的全连接层,可降低基于自注意力的模型在小数据规模下的学习难度,以提高模型在测试集上的准确率.
4.3 铝电解过热度验证实验4.3.1 数据集与预处理将基于RCSANN的过热度识别模型应用于实际的铝电解生产过程,实验数据来源于中国某铝业集团有限公司,数据包括2019年12月至2020年11月共288个铝电解槽的生产数据.根据其每天采样点数与表现形式可将数据分为化验属性值、监测属性值、至今时间值、8b状态值4个类别,如表 1所示.在4类数据中结合专家经验,选择28个属性变量(见表 5)用于过热度识别的模型构建.对选择的属性值按天进行匹配,对存在缺失值的数据进行删除,得到的94 494条无标签样本可作为无监督预训练的数据集.由于数据传输原因,原始生产数据存在少量数据缺失.为了增强模型的上下文表达能力,使模型在遇到缺失值可根据时间上下文得到输出结果,本文在训练过程中对输入采用随机遮掩的方式,所有训练数据输入网络之前随机将10%的数据置为0.
表 5(Table 5)
| 表 5 选取的生产数据变量 Table 5 Selected production data variables |
过热度在实际生产过程中根据其高低可分为过低、正常、过高三种类别,在工业现场中一般由工艺人员基于经验进行识别评价.为了减少因不同工艺人员不同时间点认知差异对结果的影响,本文选择2020年11月12日一天某工艺人员的识别过热度标签共126个数据,作为识别任务训练的数据集,其中过热度标签为过低、正常、过高的数据数量分别为30,73,23个.对于数据集随机取10%作为测试集,剩余90%作为训练集.训练过程中利用随机剪裁、增加噪声的方法将训练集进行扩充至912个样本.
在铝电解过热度的识别任务中,由于过热度的种类分布并不均衡,只采用准确率无法很好地反映模型的性能.本文采用准确率(Acc)、宏精确率(Pmacro)、宏召回率(Rmacro)与宏F1值(F1_macro)作为过热度识别任务的评价指标,计算公式如下:
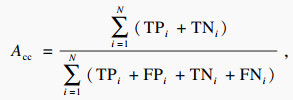 | (15) |
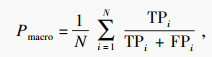 | (16) |
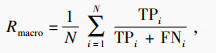 | (17) |
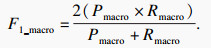 | (18) |
4.3.2 模型训练设计验证实验针对铝电解生产数据只存在少数标签问题,本文设计了基于自动编码器的无监督预训练方法,为过热度识别模型训练之前进行了预训练.针对铝电解生产过程中过热度标签类别分类不均匀的问题,本文提出了一种加权交叉熵函数,根据不同类别的样本数量对其损失赋予不同的权重,以减少模型的有偏性.为了验证无监督预训练与加权交叉熵损失对过热度识别模型性能的影响,本文设计了4种组合方式进行10次训练并取平均值,实验结果如表 6所示.
表 6(Table 6)
| 表 6 模型训练设计验证实验结果 Table 6 Validation experiment results of training design | ||||||||||||||||||||||||||||||||||||||||
由表 6可知,无监督预训练与加权交叉熵损失均可提高最终分类模型的性能.基准模型采用随机生成的权重作为初始化,使用交叉熵损失进行训练得到识别模型.只使用无监督预训练方法得到的权重作为分类模型权重初始化,最终识别模型的评价指标均高于基准模型.只使用加权交叉熵损失进行识别模型训练,最终识别模型在准确率与基准模型相同的基础上,宏精确率、宏召回率与宏F1值均高于基准模型.结合无监督预训练方法与加权交叉熵损失训练得到的最终识别模型,其评价指标均高于其他模型.
铝电解生产过程中的生产数据只有少量存在过热度标签,对于权重随机初始化的模型,由于标签数据量不足,导致模型在训练过程过拟合.基于自动编码器的无监督预训练方法采集大量无标签数据进行训练,使得自动编码器的编码层Een能学习到数据的高维深度特征表示.将Een的权重迁移至过热度识别模型作为权重初始化,有助于识别任务训练.
此外,铝电解生产过程中存在过热度标签分布不均匀的现象,训练过程计算中,不同类别在输出概率相同时,样本数量大的类别总损失大,导致模型优化时会更关注样本数量大的类别,使得最终模型的分类结果会偏好于训练样本中数量大的类别,模型存在有偏性,在评价指标上表现为准确率与宏F1值差距较大.加权交叉熵损失通过在训练过程中对不同的类别给予不同的权重,不同类别在输出概率相同时,其类别总损失相同,使模型能够平等对待不同类别进行优化,降低模型的有偏性.
为了进一步验证加权交叉熵损失对分类模型的影响,本文基于经过无监督预训练的模型分别采用交叉熵损失(CE loss)与加权交叉熵损失(WCE loss)训练得到2个过热度识别模型.2个模型在测试集中各个类别的F1值如图 5所示.
图 5(Fig. 5)
 | 图 5 不同模型各类别效果图Fig.5 Effect of different models in all classes |
采用加权交叉熵损失训练得到的模型各个类别的F1值均大于等于采用交叉熵损失训练得到的模型的F1值;同时采用加权交叉熵损失训练得到的模型各类别F1值的方差较小,仅为0.027 4,采用交叉熵损失训练得到的模型各类别F1值的方差为0.062 5,说明模型的预测结果较为均衡,不偏向于某一个类别.在训练过程中加权交叉熵损失减小了模型的有偏性,使得在训练集类别分布不均匀的情况下,经过训练的模型能够对不同类别取得较平衡的预测结果,从而提高模型的性能.
4.3.3 过热度识别对比实验为了证明本文模型的有效性,本文选择传统的机器学习算法SVM[30],XGBoost[31]进行对比实验.在传统机器学习模型中,为统一不同长采样间隔的输入,本文拼接经过处理后的监测属性值与原始化验属性值作为输入.对X1采用下列两种处理方式:1)求取平均值,记为M;2)求取平均值、标准差与最大值,记为MSM.按采用的机器学习模型与处理方式的不同,可得到4组模型,分别为M_SVM,MSM_SVM,M_XGBoost,MSM_XGBoost.同时本文选取MLSTM-FCN,TCN,TEC三个深度学习模型分别在铝电解过热度上使用无监督预训练与加权交叉熵损失进行过热度识别任务训练,来进行对比实验.实验重复10次并取平均值,各个模型的性能指标如表 7所示.
表 7(Table 7)
| 表 7 不同模型对比实验结果 Table 7 Comparing experiment results of different models | |||||||||||||||||||||||||||||||||||||||||||||||||
从表 7可知,本文提出的基于RCSANN的铝电解过热度识别算法在准确率、宏精确率、宏召回率、宏F1值4个评价指标均高于其他算法,证明了本文方法的有效性.
与SVM,XGBoost算法使用不同数据处理方式的模型相比,本文直接对铝电解生成数据的时序时间进行建模得到的模型性能最优;在SVM,XGBoost算法中,取平均值、标准差与最大值(MSM)处理的结果次之,只取平均值(M)处理的结果最差.这表明了铝电解生产数据中的动态特征对于过热度识别建模的重要性.
对比基于MLSTM-FCN,TCN,TEC三个深度学习模型的铝电解过热度识别算法,基于RCSANN的过热度识别算法在评价指标上最优,证明了自注意力层对于提取全局特征的有效性,同时引入的残差卷积可有效减小模型训练难度,在训练样本较少时保证模型的表达能力.
5 结语本文提出了一种基于残差卷积自注意力神经网络的铝电解过热度识别方法.该方法引入铝电解生产过程中动态变化的时间序列信息,提出了铝电解异构数据的同构表示方法.设计一种残差卷积自注意力模块,提出了一种基于RCSANN的对过热度识别模型,引入无监督预训练方法与加权交叉熵损失以改善模型性能.最后,通过实验对本文提出方法的性能进行了验证.实验结果表明,对比现有的方法,本文提出的RCSANN在公开基准数据集上获得了更优秀的性能,在实际铝电解过程过热度识别中,准确率达到83.3%,宏F1值达到84.1%,在过热度标签样本较少时基于RCSANN的过热度识别模型仍能保证较强的泛化能力.
参考文献
| [1] | 桂卫华, 岳伟超, 谢永芳, 等. 铝电解生产智能优化制造研究综述[J]. 自动化学报, 2018, 44(11): 1957-1970. (Gui Wei-hua, Yue Wei-chao, Xie Yong-fang, et al. A review of intelligent optimal manufacturing for aluminum reduction production[J]. Acta Automatica Sinica, 2018, 44(11): 1957-1970. DOI:10.16383/j.aas.2018.c180198) |
| [2] | Li J, Liu Y X, Huang Y Z, et al. Bath temperature model for point-feeding aluminium reduction cells[J]. Transactions of Nonferrous Metals Society of China, 1994, 4(1): 26-32. |
| [3] | Drengstig T, Ljungquist D, Foss B A. On the AlF3 and temperature control of an aluminum electrolysis cell[J]. IEEE Transactions on Control Systems Technology, 1998, 6(2): 157-171. DOI:10.1109/87.664183 |
| [4] | 郭英杰, 胡峰, 于洪, 等. 基于时间粒的铝电解过热度预测模型[J]. 南京大学学报(自然科学), 2019, 55(4): 624-632. (Guo Ying-jie, Hu Feng, Yu Hong, et al. Prediction model of superheat in aluminum electrolysis based on time granularity[J]. Journal of Nanjing University(Natural Science), 2019, 55(4): 624-632.) |
| [5] | Lei Y X, Karimi H R, Cen L H, et al. Processes soft modeling based on stacked autoencoders and wavelet extreme learning machine for aluminum plant-wide application[J]. Control Engineering Practice, 2021, 108: 104706. DOI:10.1016/j.conengprac.2020.104706 |
| [6] | Min M C, Chen X F, Xie Y F. Constrained voting extreme learning machine and its application[J]. Journal of Systems Engineering and Electronics, 2021, 32(1): 209-219. DOI:10.23919/JSEE.2021.000018 |
| [7] | Bostrom A, Bagnall A. Binary shapelet transform for multiclass time series classification[C]//International Conference on Big Data Analytics and Knowledge Discovery. Berlin: Springer, 2015: 257-269. |
| [8] | Wan W X, Chen X F, Gui W H, et al. A novel shapelet transformation method for classification of multivariate time series with dynamic discriminative subsequence and application in anode current signals[J]. Journal of Central South University, 2020, 27(1): 114-131. DOI:10.1007/s11771-020-4282-5 |
| [9] | Kate R J. Using dynamic time warping distances as features for improved time series classification[J]. Data Mining and Knowledge Discovery, 2016, 30(2): 283-312. DOI:10.1007/s10618-015-0418-x |
| [10] | Lines J, Bagnall A. Time series classification with ensembles of elastic distance measures[J]. Data Mining and Knowledge Discovery, 2015, 29(3): 565-592. DOI:10.1007/s10618-014-0361-2 |
| [11] | Baydogan M G, Runger G, Tuv E. A bag-of-features framework to classify time series[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2796-2802. DOI:10.1109/TPAMI.2013.72 |
| [12] | Deng H, Runger G, Tuv E, et al. A time series forest for classification and feature extraction[J]. Information Sciences, 2013, 239: 142-153. DOI:10.1016/j.ins.2013.02.030 |
| [13] | Bagnall A, Lines J, Hills J, et al. Time-series classification with COTE: the collective of transformation-based ensembles[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(9): 2522-2535. DOI:10.1109/TKDE.2015.2416723 |
| [14] | Goodfellow I, Bengio Y, Courville A. Deep learning[M]. Cambridge: MIT Press, 2016. |
| [15] | Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. DOI:10.1145/3065386 |
| [16] | Tan M, Le Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]//International Conference on Machine Learning. New York: PMLR, 2019: 6105-6114. |
| [17] | Liu A T, Yang S, Chi P H, et al. Mockingjay: unsupervised speech representation learning with deep bidirectional transformer encoders[C]//ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona: IEEE, 2020: 6419-6423. |
| [18] | 宋欣, 李奇, 解婉君, 等. YOLOv3-ADS: 一种基于YOLOv3的深度学习目标检测压缩模型[J]. 东北大学学报(自然科学版), 2021, 42(5): 609-615. (Song Xin, Li Qi, Xie Wan-jun, et al. YOLOv3-ADS: a compression model for deep learning object detection based on YOLOv3[J]. Journal of Northeastern University(Natural Science), 2021, 42(5): 609-615.) |
| [19] | Dempster A, Petitjean F, Webb G I. ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels[J]. Data Mining and Knowledge Discovery, 2020, 34(5): 1454-1495. DOI:10.1007/s10618-020-00701-z |
| [20] | Qiao M, Yan S, Tang X, et al. Deep convolutional and LSTM recurrent neural networks for rolling bearing fault diagnosis under strong noises and variable loads[J]. IEEE Access, 2020, 8: 66257-66269. DOI:10.1109/ACCESS.2020.2985617 |
| [21] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. New York: Curran Associates, 2017: 5998-6008. |
| [22] | Lai S, Liu K, He S, et al. How to generate a good word embedding[J]. IEEE Intelligent Systems, 2016, 31(6): 5-14. |
| [23] | Xiong R, Yang Y, He D, et al. On layer normalization in the transformer architecture[C]//International Conference on Machine Learning. New York: PMLR, 2020: 10524-10533. |
| [24] | Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. New York: PMLR, 2021: 10347-10357. |
| [25] | Odena A, Dumoulin V, Olah C. Deconvolution and checkerboard artifacts[J]. Distill, 2016, 1(10): e3. |
| [26] | Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Computer Society, 2015: 1520-1528. |
| [27] | Bagnall A, Dau H A, Lines J, et al. The UEA multivariate time series classification archive, 2018[J]. arXiv preprint arXiv: 1811.00075, 2018. |
| [28] | Karim F, Majumdar S, Darabi H, et al. Multivariate LSTM-FCNs for time series classification[J]. Neural Networks, 2019, 116: 237-245. |
| [29] | Yan J, Mu L, Wang L, et al. Temporal convolutional networks for the advance prediction of ENSO[J]. Scientific Reports, 2020, 10(1): 1-15. |
| [30] | 曹德芳, 刘柏池. SVM财务欺诈识别模型[J]. 东北大学学报(自然科学版), 2019, 40(2): 295-299, 304. (Cao De-fang, Liu Bai-chi. SVM model for financial fraud detection[J]. Journal of Northeastern University(Natural Science), 2019, 40(2): 295-299, 304.) |
| [31] | Chen T, Guestrin C. Xgboost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Assoc Computing Machinery, 2016: 785-794. |
