
 , гЖ¶¬Г·, ГП·¶О°
, гЖ¶¬Г·, ГП·¶О° ¶«ұұҙуС§ЗШ»Көә·ЦРЈ ҝШЦЖ№ӨіМС§ФәЈ¬әУұұ ЗШ»Көә 066004
КХёеИХЖЪЈә2021-11-22
»щҪрПоДҝЈәәУұұКЎЧФИ»ҝЖС§»щҪрЧКЦъПоДҝ(F2019501012)ЎЈ
ЧчХЯјтҪйЈәБхСу(1997-)Ј¬ДРЈ¬ЙҪ¶«лшЦЭИЛЈ¬¶«ұұҙуС§Л¶КҝСРҫҝЙъ;
гЖ¶¬Г·(1970-)Ј¬Е®Ј¬ұұҫ©ИЛЈ¬¶«ұұҙуС§ЗШ»Көә·ЦРЈёұҪМКЪЈ¬Л¶КҝЙъөјКҰЎЈ
ХӘТӘЈәХл¶Ф»щУЪҫн»эЙсҫӯНшВзөДРРИЛЦШК¶ұрЛг·ЁИ«ҫЦРЕПўҪЁДЈІ»ЧгөДОКМвЈ¬·ЦОцБЛҫн»эІЩЧчөДҫЦПЮРФЈ¬МбіцТ»ЦЦ»щУЪTransformerёДҪшөДИ«ҫЦ-ҫЦІҝБҪ·ЦЦ§РРИЛЦШК¶ұрЛг·Ё.КЧПИАыУГПа¶ФО»ЦГұаВлёДҪш¶аН·ЧФЧўТвБҰ»ъЦЖЈ¬ІўҪ«ЖдЗ¶ИлөҪResnet50№ЗёЙНшВзЦР.Ц®әуФЪИ«ҫЦ·ЦЦ§ЦР¶ФНјПсҪшРРҝХјдјёәО»®·ЦІўАыУГTransformerөДИ«ҫЦёРКЬТ°ФцЗҝійПуМШХчөДМбИЎДЬБҰЈ»ФЪҫЦІҝ·ЦЦ§ЦР¶ФLayer_3КдіцҪшРРҪөО¬ја¶ҪЈ¬АыУГ¶аіЯ¶ИіШ»Ҝ»сөГёь·бё»өДҫЦІҝМШХч.КөСйҪб№ыұнГчЈ¬ёГЛг·ЁФЪ№«ҝӘКэҫЭјҜMarket-1501әНDukeMTMC-reIDЙПөДmAP/Rank-1·ЦұрҙпөҪБЛ93.45%/95.61%әН88.79%/90.35%Ј¬Па¶ФУЪөҘҙҝ»щУЪҫн»эЙсҫӯНшВзөДЛг·ЁЈ¬ұҫОДЛг·ЁҙпөҪёьёЯөДҫ«¶И.
№ШјьҙКЈәРРИЛЦШК¶ұрTransformerҫн»эЙсҫӯНшВзМШХчМбИЎ¶аН·ЧФЧўТвБҰ»ъЦЖ
Improved Two-Branch Person Re-identification Algorithm Based on Transformer
LIU Yang
, YAN Dong-mei, MENG Fan-wei School of Control Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
Corresponding author: LIU Yang, E-mail: 2071938@stu.neu.edu.cn.
Abstract: In order to solve the problem of insufficient global information modeling of person re-recognition algorithm based on convolutional neural network, the limitation of convolution operation is analyzed, and an improved global-local two-branch person re-recognition algorithm based on Transformer is proposed. Firstly, the multi-headed self-attention mechanism which is embedded in the Resnet50 backbone network is optimized by relative position-coding. After that, the processed image is split into two parts on the global branch geometrically, and the ability of extracting the abstract features is enhanced by the Transformer's global receptive field. On the local branch, the Layer_3 output is under the supervision of dimensionality reduction while the multi-scale pooling obtains richer local features. The experimental result shows that, on the Market-1501 and DukeMTMC-reID datasets, mAP/Rank-1 of the algorithm reaches 93.45%/95.61% and 88.79%/90.35%, respectively. Compared with the algorithm which is only based on convolutional neural network, higher accuracy is achieved.
Key words: person re-identificationTransformerconvolutional neural networkfeature extractionmulti-headed self-attention mechanism
РРИЛЦШК¶ұр(person re-identification)ТІіЖРРИЛФЩК¶ұрЈ¬ұ»ЖХұйИПОӘКЗТ»ёцНјПсјмЛчөДЧУОКМв.НЁ№эёш¶ЁТ»ёцҙэІйСҜНјПсәНјаҝШНјПсҝвЈ¬АыУГЦШК¶ұрЛг·ЁјмЛчіцІ»Н¬ЙгПсН·ПВөДПаН¬РРИЛ.ёГПојјКхФЪРМКВХмІйЎўЧЯК§ҫИЦъЎўРРИЛёъЧЩөИ°І·АБмУтУРЧЕ№гА«өДУҰУГЗ°ҫ°.РРИЛЦШК¶ұрјјКхөДМШХчМбИЎТААөУЪРРИЛНјПсөДРЕПўЈ¬ИзН··ўЎўТВ·юөДСХЙ«ЎўЙнЙПөДЕдКОөИ.ө«ФЪКөјКУҰУГ№эіМЦРТЧКЬөҪ№вХХәНЧЛМ¬І»¶ФЖлөИЦо¶аТтЛШөДУ°ПмЈ¬ТтҙЛЈ¬ИзәОМбИЎёьВі°фөДРРИЛМШХчіЙОӘТ»ёцЦБ№ШЦШТӘөДОКМв.өұЗ°Рн¶а»щУЪұнХчС§П°әН¶ИБҝС§П°өД№ӨЧч¶аКЗАыУГҫн»эЙсҫӯНшВзАҙ»сИЎРРИЛМШХчЈ¬ҫн»эЙсҫӯНшВзФЪјЖЛг»ъКУҫхБмУтИЎөГБЛҫЮҙуөДіЙ№Ұ[1].2018ДкSunөИ[2]МбіцPCBЛг·ЁЈ¬Ҫ«МШХчПтБҝ·ЦОӘ6·ЭЈ¬Іў·ЦұрҪшРРја¶ҪЈ¬ёГЛг·ЁМбёЯБЛРРИЛЦШК¶ұрөДҫ«¶ИЈ¬ТІҙЩҪшБЛРн¶аПИҪшЛг·ЁөДМбіцЈ¬ИзSPReID[3]ЎўPyramidNet[4]өИ.2020ДкZhangөИ[5]МбіцБЛ»щУЪИ«ҫЦЧўТвБҰ»ъЦЖёДҪшөДРРИЛЦШК¶ұрЛг·ЁЈ¬АыУГНЁөАЧўТвБҰәНҝХјдЧўТвБҰ»ъЦЖҪПәГөШ№ШЧўБЛИ«ҫЦРЕПўЈ¬ө«ёГЛг·ЁГ»УРҙУёщұҫЙПҪвҫцҫн»эөДҫЦПЮРФОКМвЈ¬Г»УРҙпөҪҪПёЯөДҫ«¶И.өұЗ°РРИЛЦШК¶ұрЛг·ЁУРТФПВБҪёцЦчТӘОКМв: 1)РРИЛЦШК¶ұрЛг·ЁРиТӘ»сИЎ·бё»өДИ«ҫЦРЕПўЈ¬¶шҫн»эЙсҫӯНшВзКЗНЁ№эҫн»эәРФЪНјПсЙПөДТЖ¶ҜАҙ»сИЎј«РЎөДҫЦІҝРЕПўЈ¬ёь¶аөШ№ШЧўНјПсөДПёҪЪ¶шІ»ИЭТЧ»сөГёьійПуөДИ«ҫЦРЕПў.Т»Р©№ӨЧчИзAANet[6]НЁ№эјУЙоНшВзөДІгКэАҙ»сөГёь¶аөДИ«ҫЦРЕПўЈ¬ҙуҙуФцјУБЛДЈРНөДІОКэәНјЖЛгБҝ.2)ҫн»эЙсҫӯНшВзТ»ҙОҫн»эЦ»ДЬҙҰАнТ»ёцҫЦІҝЗшУтЈ¬»бКЬөҪҫн»эәНПВІЙСщЛгЧУөДУ°ПмЈ¬өјЦВәЬ¶аМШХчРЕПўөД¶ӘК§.
ҪьЖЪЈ¬СРҫҝИЛФұМбіцБЛТ»Р©РВөДҪвҫц·Ҫ·Ё.DosovitskiyөИ[7]өЪТ»ҙОҪ«ЧФИ»УпСФҙҰАнБмУтөДTransformer·Ҫ·ЁУҰУГУЪјЖЛг»ъКУҫхБмУт.2021ДкЈ¬ФЪTransformer·Ҫ·ЁөД»щҙЎЙПЈ¬ОўИнСЗЦЮСРҫҝФәМбіцБЛSwin Transformer[8]Ј¬ЖдО»ТЖҙ°ҝЪәНІгј¶ЙијЖөИЛјПлФЪјмІвЎў·ЦАаөИ¶аёцјЖЛг»ъКУҫхИООсЙПИЎөГБЛҫЮҙуөДіЙ№Ұ.УЙ¶аН·ЧФЧўТвБҰ»ъЦЖЧйіЙөДTransformer·Ҫ·ЁФЪёчёцКУҫхИООсЙПұнПЦіцҪПҙуөДЗұБҰЈ¬Н¬КұФЪ¶аёцИООсөДКэҫЭјҜЙПұнПЦіцЙ«Ј¬УРЧЕЦрҪҘМжҙъҫн»эЙсҫӯНшВзөДЗчКЖ.ө«ҙҝTransformerНшВзИұЙЩ№йДЙЖ«ІоЈ¬ЗТјЖЛгёҙФУ¶ИёЯЈ¬СөБ·№эіМ»әВэЈ¬ЖдДЈРНРиТӘФЪ·ЗіЈҙуөДКэҫЭјҜЙПНкіЙФӨСөБ·Ј¬ІЕДЬ№»ИЎөГіцЙ«өДР§№ы.ТтҙЛІЙУГҙҝTransformer·Ҫ·ЁІ»ДЬВъЧгРРИЛЦШК¶ұрОКМвөДКөјКРиЗу.
Хл¶ФТФЙПОКМвЈ¬ұҫОДЙијЖБЛТ»ёцҪ«CNNУлTransformerПаҪбәПөДБҪ·ЦЦ§РРИЛЦШК¶ұрЛг·ЁЈ¬К№УГПа¶ФО»ЦГұаВлёДҪш¶аН·ЧФЧўТвБҰ»ъЦЖЈ¬ФЪұЈБфCNNҪПҝмНЖАнЛЩ¶ИәНҫЦІҝМШХчМбИЎДЬБҰөДН¬КұЈ¬АыУГTransformerөДИ«ҫЦёРКЬТ°ёьәГөШҪЁБўіӨҫаАлПсЛШөгЦ®јдөДБӘПөЈ¬ФцЗҝИ«ҫЦРЕПўөДМбИЎДЬБҰЈ¬МбЙэЛг·ЁөДВі°фРФәНК¶ұрҫ«¶И.ұҫОДЛг·ЁөДФҙҙъВлПВФШБҙҪУОӘЈәhttps://github.com/yunnoil/ReID.
1 ұҫОДЛг·Ё1.1 НшВзҪб№№ұҫОДЛг·ЁІЙУГResnet50ЧчОӘ»щҙЎДЈРНЈ¬КдИлНјПсҙуРЎОӘ288ЎБ144.ГҝҙОКдИлPЎБKХЕНјПсЈ¬јҙ¶ФУЪГҝёцСөБ·өДbatchЛж»ъМфСЎPёцРРИЛЈ¬¶ФУЪГҝТ»ёцРРИЛЛж»ъМфСЎKХЕНјПсКдИлДЈРН.ұҫОДЛг·ЁЙијЖБЛТ»ёцИ«ҫЦ·ЦЦ§әНҫЦІҝ·ЦЦ§ІўРРөДҪб№№Ј¬ХыМеНшВзҪб№№ИзНј 1ЛщКҫ.
Нј 1(Fig. 1)
 | Нј 1 ұҫОДРРИЛЦШК¶ұрЛг·ЁНшВзҪб№№КҫТвНјFig.1 The overall network architecture of the proposed person re-identification algorithm |
ФЪИ«ҫЦ·ЦЦ§ЦРЈ¬АыУГTransformerДЈҝйөДИ«ҫЦёРКЬТ°АҙМбИЎРРИЛөДИ«ҫЦМШХчЈ¬АыУГҝХјдјёәО»®·ЦөД·Ҫ·ЁЈ¬·Цұрја¶ҪРРИЛ°лЙнНјПсМШХчЈ»ФЪҫЦІҝ·ЦЦ§ЦРЈ¬АыУГҫЦІҝМШХчДЈҝйөГөҪРРИЛөДҫЦІҝРЕПў.ҫЯМеөШЈ¬Ҫ«Layer_3КдіцМШХч·ЦұрҪшРРИ«ҫЦіШ»ҜәНЖҪҫщіШ»ҜЈ¬Ц®әуИЪәПіШ»ҜәуөДМШХчөГөҪРВөДКдіцМШХчЈ¬Чоәу·Цұр¶ФИЪәПЗ°әуөДМШХчҪшРРја¶Ҫ.
КдіцМШХчФЪ·ЦАаЖчҙҰАнЦ®З°Ј¬ФцјУТ»ІгBNІгЈ¬Т»ІгReLuІгәНБҪІгИ«Б¬ҪУІг.ФЪСөБ·КұЈ¬Н¬КұК№УГұнХчС§П°әН¶ИБҝС§П°өД·Ҫ·ЁЈ¬К№УГ2ёц»щУЪДССщұҫНЪҫтөДИэФӘЧйЛрК§әН3ёцёДҪшөД·ЦАаЛрК§НкіЙНјПсМШХчМбИЎәНја¶ҪС§П°.ФЪІвКФКұЈ¬К№УГИЪәПИ«ҫЦәНҫЦІҝБҪ·ЦЦ§өДМШХчөД·ҪКҪ»сИЎјмІвРРИЛНјПсәННјПсҝвРРИЛНјПсөДМШХч.ЧоәуАыУГјЖЛгУаПТПаЛЖ¶ИөД·Ҫ·Ё¶ФНјПсҪшРРПаЛЖ¶ИЕЕРт.
1.2 ёДҪшөД¶аН·ЧФЧўТвБҰ»ъЦЖTransformer[9]КЗТ»ёцНкИ«І»Н¬УЪҫн»эЙсҫӯНшВзәНСӯ»·ЙсҫӯНшВзөДЛг·ЁЈ¬ЛьНкИ«»щУЪЧФЧўТвБҰ»ъЦЖөГөҪКдИләНКдіцЦ®јдөДИ«ҫЦТААө№ШПө.»щУЪ¶аН·ЧФЧўТвБҰ»ъЦЖөДTransformer·Ҫ·ЁҪвҫцБЛseq2seqДЈРНөДІ»ЧгЈ¬ПЦТСіЙ№ҰИЎҙъСӯ»·ЙсҫӯНшВзІў№г·әУҰУГУЪNLP(natural language processing)БмУт.
Улҙ«НіөДЧФЧўТвБҰ»ъЦЖІ»Н¬Ј¬ұҫОДҪ«МбИЎөҪөДРРИЛМШХчНјПс°ҙХХ14ЎБ14ЖҪҫщ»®·ЦОӘ196ёцpatchesЈ¬Ц®әуҪ«ГҝТ»ёцpatchesұд»»ОӘТ»О¬өДРтБР.ИзНј 2ЛщКҫЈ¬Xҫӯ№эИЁЦШҫШХуQ, K, VЦШ№№әуөГөҪqiЈ¬kiЈ¬vi, iЎК(1Ј¬2Ј¬3Ј¬ЎӯЈ¬T).К№УГПа¶ФО»ЦГұаВлөД·ҪКҪ¶ФqiұаВлО»ЦГРЕПўЈ¬Ц®әуУлkiqiЗуәНІўАыУГsoftmaxәҜКэөГөҪЧўТвБҰИЁЦШЈ¬ЧўТвБҰИЁЦШУлviЦөіЛ»эјҙОӘЧоЦХөДКдіц.НјЦРHОӘМШХчөДёЯ¶И, WОӘМШХчөДҝн¶И, CОӘМШХчөДНЁөАКэ.
Нј 2(Fig. 2)
 | Нј 2 ёДҪшөДЧФЧўТвБҰ»ъЦЖFig.2 The improved self-attention mechanism |
ЧФЧўТвБҰИЁЦШ¶ЁТеИзПВЈә
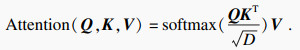 | (1) |
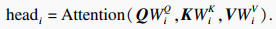 | (2) |
ёьККәПРРИЛНјПсөДПа¶ФО»ЦГұаВлөД·ҪКҪК№НјПс»®·Ц°ьә¬БЛёь·ыәПРРИЛКдИлҪб№№өДПа¶ФО»ЦГРЕПўЈ¬Ҫ«196ХЕНјПсөДРЕПўәНО»ЦГБӘПөЖрАҙ.УЙУЪ·ЦёоНјПсөДКэДҝ№М¶ЁЈ¬Ҫ«ФӯАҙөДІг№йТ»»ҜөД·Ҫ·ЁёДОӘЕъ№йТ»»ҜЈ¬Еъ№йТ»»ҜөД·ҪКҪУРР§өШҪвҫцБЛМЭ¶ИПыК§әНМЭ¶Иұ¬ХЁөДОКМв.ёДҪшөД¶аН·ЧФЧўТвБҰ»ъЦЖёьәГөШҪЁБўБЛРРИЛНјПсіӨҫаАлПсЛШЦ®јдөД№ШПөЈ¬Н¬КұМжҙъБЛҫн»эәНіШ»ҜөИІЩЧчЈ¬І»ТЧФміЙНјПсРЕПў¶ӘК§.
1.3 И«ҫЦTransformerДЈҝй»щУЪҫн»эЙсҫӯНшВзөДResnet50АыУГҫн»эәНіШ»ҜІЩЧч»сИЎНјПсРЕПўЈ¬Иұ·Ұ¶ФёЯј¶МШХчөД»сИЎДЬБҰ.»щУЪҙЛЈ¬ұҫОДФЪёДҪшөД¶аН·ЧФЧўТвБҰ»ъЦЖөД»щҙЎЙПЙијЖБЛТ»ёцTransformerДЈҝйЈ¬К№УГ¶аН·ЧФЧўТв»ъЦЖ»сИЎНјПсөДёЯј¶МШХч.ОӘІ»ФцјУДЈРНІОКэЗТМбёЯФЛЛгР§ВКЈ¬ұҫОДЦұҪУК№УГёГДЈҝйҙъМжResnet50өДөЪЛДІгјЬ№№.
ҫЯМеИ«ҫЦTransformerДЈҝйҪб№№ИзНј 3ЛщКҫЈ¬ёГДЈҝйҪ«Resnet50өЪИэІгөГөҪөДКдіцМШХч»®·ЦОӘ2ёцҙуРЎОӘ64ЎБ1 024ЎБ9ЎБ9(1 024ОӘНЁөАКэ)өДХЕБҝЈ¬РРИЛНјПсұ»·ЦОӘЙП°лЙнәНПВ°лЙнЈ¬КөСйЦӨГч»®·ЦОӘ2ёцХЕБҝөДРОКҪДЬ№»ёьУРР§өШМбёЯЦШК¶ұрР§№ы.Ц®әуЈ¬Ҫ«ұҫОДЦРёДҪшөД¶аН·ЧФЧўТвБҰ»ъЦЖЗ¶ИлResnet50өДStage_4Ҫб№№.¶ФУЪЧФЧўТвБҰ»ъЦЖөДЗ¶ИлО»ЦГЈ¬ұҫОДІЙУГБЛУлBoTNet[10]АаЛЖөДҪб№№.Ҫ«Resnet50өЪЛДІгөД3ЎБ3ҝХјдҫн»эІЩЧчМж»»ОӘұҫОДёДҪшөДИ«ҫЦ¶аН·ЧФЧўТвБҰ»ъЦЖ.»®·ЦәуөДМШХчУЙ3ёцёДҪшөДІРІоҪб№№»сИЎНјПсөДИ«ҫЦМШХч.ЧоЦХАыУГ·ЦАаЖч¶Ф2ёц°лЙнМШХчҪшРР·ЦАаЈ¬·Цұрја¶ҪРРИЛЙП°лЙнәНПВ°лЙнМШХчөД»сИЎ.
Нј 3(Fig. 3)
 | Нј 3 TransformerДЈҝйҪб№№НјFig.3 Diagram of Transformer module structure |
1.4 ҫЦІҝМШХчДЈҝйОӘІ»ФцјУДЈРНөДІОКэЈ¬ІЙУГ¶ФStage_3КдіцҪөО¬ја¶ҪөД·ҪКҪКөПЦҫЦІҝМШХчөД»сИЎ.ИзНј 1ЛщКҫЈ¬ұҫОДЦұҪУ¶Ф»щУЪҫн»эЙсҫӯНшВз»сИЎөҪөДРРИЛМШХчРЕПўҪшРРҙҰАнЈ¬Г»УРФцјУёь¶аөДҫн»эІЩЧч.
ҫЦІҝМШХчДЈҝй¶ФөГөҪөДҝХјдМШХчІЙИЎЧоҙуіШ»ҜәНЖҪҫщіШ»ҜБҪЦЦіШ»Ҝ·ҪКҪЈ¬І»Н¬өДіШ»Ҝ·ҪКҪ»сөГІ»Н¬БЈ¶ИөДРРИЛМШХч.ЧоҙуіШ»ҜөД·ҪКҪҝЙТФМбИЎөҪРРИЛөДМШХчОЖАнЈ¬СЎФсЗшУтЧоУРҙъұнРФөДМШХчЈ¬ИҘіэұіҫ°РЕПўөДУ°ПмЈ»ЖҪҫщіШ»ҜөД·ҪКҪК№МбИЎөДМШХчёьјУИ«Гж.БҪЦЦІ»Н¬өДіШ»Ҝ·ҪКҪК№ДЈРН»сөГБЛёьјУ·бё»И«ГжөДРРИЛМШХч.ҫЦІҝМШХчДЈҝйјЖЛг№эіМИзПВЈә
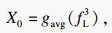 | (3) |
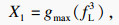 | (4) |
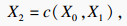 | (5) |
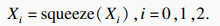 | (6) |
ЧоәуЈ¬ұҫОД¶ФіШ»ҜәуөДМШХчX0Ј¬X1К№УГ»щУЪДССщұҫНЪҫтөДИэФӘЧйЛрК§Ччја¶ҪСөБ·Ј¬¶ФУЪИЪәПәуөДМШХчX2ІЙУГ»щУЪұкЗ©ЖҪ»¬өДҪ»ІжмШЛрК§әҜКэҪшРРја¶ҪСөБ·.
1.5 ЛрК§әҜКэУлЖдЛыЛг·ЁІ»Н¬Ј¬ұҫОДФЪСөБ·№эіМЦРБӘәПБҪЦЦЛрК§әҜКэ¶ФДЈРНҪшРРФјКшЈ¬·ЦұрОӘҪ»ІжмШЛрК§әНИэФӘЧйЛрК§.ұҫОДАыУГұкЗ©ЖҪ»¬[11]өД·Ҫ·ЁҪ«ФӯҪ»ІжмШЛрК§ДҝұкөДone-hotұкЗ©ұдОӘ
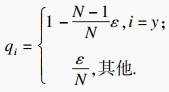 | (7) |
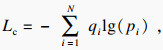 | (8) |
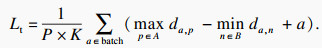 | (9) |
ЧоЦХБӘәП2ёцTriHardЛрК§әН3ёцұкЗ©ЖҪ»¬ёДҪшөДҪ»ІжмШЛрК§ҪшРРСөБ·Ј¬ЧЬЛрК§әҜКэLossОӘ
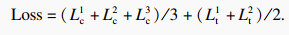 | (10) |
2.2 КэҫЭјҜУлЖАјЫЦёұкОӘСйЦӨЛг·ЁөДУРР§РФЈ¬ұҫОД·ЦұрФЪЗе»ӘҙуС§өДMarket-1501КэҫЭјҜ[14]әН¶ЕҝЛҙуС§өДDukeMTMC-reIDКэҫЭјҜ[15]ЙПҪшРРКөСй.Market-1501°ьә¬ФЪЗе»ӘҙуѧУ԰6ёцКЦ¶ҜЙиЦГөДЙгПс»ъІЙјҜөД1 501ёцРРИЛРЕПўЈ¬№ІУР32 217ХЕРРИЛНјПс.DukeMTMC-reIDКэҫЭјҜ°ьә¬¶ЕҝЛҙуѧУ԰8ёцЙгПсН·ІЙјҜөД2 700¶аёцРРИЛРЕПўЈ¬№ІУР364 441ХЕРРИЛНјПс.КэҫЭјҜ·ЦОӘСөБ·јҜЎўСйЦӨјҜЎўQueryЎўGalleryЛДІҝ·ЦЈ¬АыУГСөБ·јҜУлІвКФјҜҪшРРДЈРНөДСөБ·Ј¬Ц®әу¶ФQueryәНGalleryЦРөДНјПсМбИЎМШХчІўјЖЛгМШХчПаЛЖ¶ИЈ¬¶ФУЪГҝТ»ёцQueryФЪGalleryЦРХТіцЗ°NёцУлЖдПаЛЖөДНјПс.
ұҫОДІЙУГБЛБҪЦЦЖА№А·Ҫ·ЁЈәөЪТ»ЦЦКЗЦШК¶ұрНјПсөДКЧО»ГьЦРВКЈ¬јҙRank-1Ј»өЪ¶юЦЦКЗЖҪҫщҫщЦөҫ«¶ИјҙmAP (mean average precision)Ј¬mAPКЗГҝёцQueryөДAP (average precision) өДЖҪҫщЦө.mAPН¬КұҝјВЗБЛҫ«¶ИәНХЩ»ШВКЈ¬·ҙУіјмЛчөДРРИЛФЪКэҫЭҝвЦРЛщУРХэИ·НјПсЕЕФЪРтБРұнЗ°ГжөДіМ¶ИЈ¬ДЬ№»ёьәГөШ·ҙУіЛг·ЁөДҫ«¶И.
2.3 ПыИЪКөСй2.3.1 ёч·ЦЦ§Ҫб№№УРР§РФСйЦӨОӘСйЦӨёчДЈҝйТФј°И«ҫЦ-ҫЦІҝҪб№№өДУРР§РФЈ¬ұҫОДФЪMarket-1501КэҫЭјҜҪшРРБЛТ»ПөБРПыИЪКөСй.ФЪКөСйЦРұЈБфБЛRandom ErasingөИКэҫЭФцЗҝ·Ҫ·ЁЈ¬Ц®әу·ЦұрХл¶ФўЩ»щУЪResnet50өДРРИЛЦШК¶ұр»щҙЎДЈРНЈ¬ўЪёДҪшөД¶аН·ЧФЧўТвБҰ»ъЦЖЧйіЙөДTransformerДЈҝйМж»»Resnet50_Layer4Ј¬ўЫФЪИ«ҫЦ·ЦЦ§ЦР¶ФМШХчЧцҝХјдјёәО»®·ЦЈ¬ўЬФцјУҫЦІҝМШХчМбИЎДЈҝйЈ¬ўЭЛрК§әҜКэёДОӘұкЗ©К№УГұкЗ©ЖҪ»¬өДЛрК§әҜКэЈ¬Хв5ЦЦ·Ҫ·ЁҪшРРКөСйЈ¬ЛщУРКөСйҫщК№УГПаН¬өДКөСйІОКэ.
Изұн 1ЛщКҫЈ¬Па¶ФУЪ·Ҫ·ЁўЩЈ¬·Ҫ·ЁўЪК№УГ¶аН·ЧФЧўТвБҰ»ъЦЖФцЗҝБЛДЈРН¶ФМШХчөДМбИЎДЬБҰЈ¬mAPМбёЯБЛ1.03%Ј¬Rank-1МбёЯБЛ1.13%Ј¬ЦӨГчБЛИ«ҫЦTransformerДЈҝйҝЙТФМбёЯРРИЛЦШК¶ұрөДЧјИ·ВК.ФЪ·Ҫ·ЁўЪөД»щҙЎЙПЈ¬·Ҫ·ЁўЫҪ«НјПс»®·ЦОӘБҪІҝ·ЦЈ¬ЛдИ»Ҫб№№ёьОӘёҙФУЈ¬ө«КЗmAPТІПаУҰМбёЯБЛ1.32%Ј¬Rank-1МбёЯБЛ0.61%.·Ҫ·ЁўЬПаұИУЪ·Ҫ·ЁўЫЦШК¶ұрЧјИ·ВКөГөҪҪПҙуМбЙэЈ¬mAPМбёЯБЛ7.50%Ј¬Rank-1МбёЯБЛ3.10%Ј¬ФӯТтКЗҫЦІҝМШХчДЈҝй»сИЎБЛёьОӘФӯКјөДөЧІгПёҪЪРЕПўЈ¬ІўЗТ»щУЪДССщұҫНЪҫтөДИэФӘЧйЛрК§ДЬ№»ёьәГөШС§П°өҪНјПсөДПёОўМШХчЈ¬ҙУ¶шЦӨГчҫЦІҝМШХчДЈҝйДЬ№»УРР§МбЙэРРИЛЦШК¶ұрЛг·Ёҫ«¶И.·Ҫ·ЁўЭАыУГұкЗ©ЖҪ»¬өД·Ҫ·ЁФцЗҝБЛЛг·ЁөД·ә»ҜРФДЬЈ¬ұҫОДЛг·Ёҫ«¶ИөГөҪҪшТ»ІҪМбЙэЈ¬mAPМбёЯБЛ0.68%Ј¬Rank-1МбёЯБЛ0.19%.
ұн 1(Table 1)
| ұн 1 ёч·ЦЦ§Ҫб№№УРР§РФСйЦӨ Table 1 Validation of each branch structure ? | ||||||||||||||||||||||||||||||||||||||||||||||||
2.3.2 Па¶ФО»ЦГұаВлУРР§РФСйЦӨОӘЦӨГчПа¶ФО»ЦГұаВл·ҪКҪөДУРР§РФЈ¬ұҫОДФЪMarket-1501КэҫЭјҜЙПҪшРРПыИЪКөСй.Изұн 2ЛщКҫЈ¬ФЪҫЦІҝ·ЦЦ§І»ұдөДЗйҝцПВЈ¬·Цұр¶ФұИБЛҫш¶ФО»ЦГұаВләНПа¶ФО»ЦГұаВл[16]БҪЦЦ¶аН·ЧФЧўТвБҰ»ъЦЖО»ЦГұаВл·ҪКҪ.КөСйЦӨГчЈ¬Па¶ФО»ЦГұаВл·ҪКҪДЬ№»ёьәГөШұнҙпРРИЛНјПсөДЛіРтРЕПў.јУИлПа¶ФО»ЦГРЕПўөДTransformerҪб№№К№өГДЈРНmAPәНRank-1·ЦұрМбёЯБЛ0.32әН0.91ёц°Щ·Цөг.
ұн 2(Table 2)
| ұн 2 TransformerУРР§РФСйЦӨ Table 2 Transformer validity verification ? | ||||||||||||||||||||||||||||||||||||||||||
2.3.3 ¶аіЯ¶ИіШ»ҜУРР§РФСйЦӨ¶ФҫЦІҝ·ЦЦ§МШХчөДЦұҪУја¶ҪІ»АыУЪ»сөГ·бё»өДРРИЛҫЦІҝМШХч.Изұн 3ЛщКҫЈ¬ФЪMarket-1501КэҫЭјҜЙПЈ¬ұҫОД·Цұр¶ФұИБЛҫЦІҝМШХчДЈҝй3ЦЦІ»Н¬өДҪб№№.КөСй№эіМЦРИ«ҫЦ·ЦЦ§Ҫб№№ұЈіЦІ»ұдЈ¬КөСйҪб№ыПФКҫЈ¬ІЙУГЧоҙуіШ»ҜәНЖҪҫщіШ»ҜҪбәПөД¶аіЯ¶ИіШ»Ҝ·ҪКҪЕдәПДССщұҫНЪҫтөДИэФӘЧйЛрК§ПаұИУЪјтөҘөД¶ФКдіцҪшРРЖҪҫщіШ»ҜmAPәНRank-1Цёұк·ЦұрМбёЯБЛ4.82%әН1.31%Ј¬СйЦӨБЛ¶аіЯ¶ИіШ»ҜөД·ҪКҪДЬ№»МбёЯРРИЛЦШК¶ұрЛг·ЁөДҫ«¶И.
ұн 3(Table 3)
| ұн 3 ¶аіЯ¶ИіШ»ҜУРР§РФСйЦӨ Table 3 Multi-scale pooling validity verification ? | |||||||||||||||||||||||||||||||||||||||||||||
2.4 УлПЦУР·Ҫ·ЁұИҪПОӘҪшТ»ІҪЦӨГчұҫОДЛг·ЁДЬ№»УРР§МбЙэРРИЛЦШК¶ұрөДЧјИ·ВКЈ¬Ҫ«ұҫОДЛг·ЁУлҪьИэДкОДХВМбіцөД»щУЪҫн»эЙсҫӯНшВз(CNN)әН»щУЪTransformerЛг·ЁҪшРРұИҪПЈ¬ГҝЦЦЛг·Ё¶јЧўГчБЛЖд»щұҫјЬ№№әНАҙФҙ.
ФЪMarket-1501әНDukeMTMC-reIDКэҫЭјҜЙПҪшРРКөСйЈ¬Ҫб№ыИзұн 4ЛщКҫ.DuATM[21], AANet[6]·ЦұрК№УГБЛDenseNetәНResNet152ЧчОӘ»щҙЎјЬ№№Ј¬ҙпөҪБЛҪПОӘПИҪшР§№ыөДН¬КұФцјУБЛЛг·ЁІОКэЈ¬ұҫОДЛг·ЁФЪІОКэБҝёьЙЩөДЗйҝцПВРРИЛЦШК¶ұрҫ«¶ИУЕУЪЙПКцЛг·Ё.SPReID[3]УлPCB[2]ПаЛЖЈ¬¶јКЗК№УГ·ЦёоРРИЛөД·Ҫ·Ё¶ФҫЦІҝМШХчҪшРРМбИЎЈ¬ұҫОДЛг·ЁұИХвБҪЦЦЛг·ЁёҙФУЈ¬ө«ҫ«¶ИПа¶ФМбЙэБЛ2%~3%.Mancs[17]Ј¬IANet[18]Ј¬CASN[19]Ј¬SNR[22]ЦВБҰУЪМбИЎёьУРЕРұрБҰөДҫЦІҝМШХчЈ¬ЖдЦРҫ«¶ИҪПәГөДSNR[22]Лг·ЁmAPҙпөҪ84.70%Ј¬ҫЎ№ЬИзҙЛЈ¬ұҫОДЛг·ЁИФУРҪь1%өДМбёЯ.
ұн 4(Table 4)
| ұн 4 УлЖдЛыПИҪшЛг·ЁФЪMarket-1501, DukeMTMC-reIDБҪёцКэҫЭјҜЙПөД¶ЁБҝұИҪП Table 4 Quantitative comparison on Market-1501, DukeMTMC-reID datasets with others advanced algorithm | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
»щУЪTransformerөД·Ҫ·ЁТ»ҫӯМбіцҫНҙпөҪБЛҪПёЯөДҫ«¶ИЈ¬ЖдЦРЧоУРҙъұнРФөДКЗ·ўұнФЪICLR21өДVit-Transformer[7]әНҪьЖЪөДSwin-Transformer[8].ПаұИУЪХвЦЦҙҝTransformerҪб№№өДЛг·ЁЈ¬ұҫОДЛг·ЁАыУГTransformer¶Фҫн»эЙсҫӯНшВзҪшРРёДҪшЈ¬ФЪҙпөҪёьёЯөДРРИЛЦШК¶ұрҫ«¶ИөДН¬КұЈ¬Лг·ЁөДНЖАнЛЩ¶ИТІөГөҪМбёЯ.
ИзНј 4ЛщКҫЈ¬2ёцКэҫЭјҜКөСйұнГчЈ¬ұҫОДЛг·Ёҫ«¶ИУЕУЪ»щУЪҫн»эЙсҫӯНшВзөДЛг·ЁәНҙҝTransformerөДЛг·Ё.ҫӯ№эRe-ranking[20]¶ФјмЛчөҪөДНјПсЧцЦШЕЕРтәуЈ¬Лг·Ёҫ«¶ИөГөҪҪшТ»ІҪМбёЯЈ¬ФЪMarket-1501КэҫЭјҜЦРЈ¬mAPәНRank-1·ЦұрҙпөҪ93.45%әН95.61%.ФЪDukeMTMC-reIDКэҫЭјҜЦРЈ¬mAPәНRank-1·ЦұрҙпөҪ88.79%әН90.35%
Нј 4(Fig. 4)
 | Нј 4 І»Н¬·Ҫ·ЁЖҪҫщҫщЦөҫ«¶ИәНКЧО»ГьЦРВККҫТвНјFig.4 The mAP and Rank-1 indicators of different methods |
2.5 Ҫб№ыХ№КҫұҫОДЛг·ЁЦШК¶Ҫб№ыИзНј 5ЛщКҫ.ФЪКдИлТ»ёцРиТӘІйСҜөДРРИЛНјПсәуЈ¬Лг·ЁК¶ұріцІ»Н¬ЙгПсН·ПВПаН¬РРИЛөДНјПсЈ¬ІўҙУRank-1өҪRank-10°ҙХХПаЛЖ¶ИЕЕРт.Нј 5a, Нј 5b·ЦұрХ№КҫБЛұҫОДЛг·ЁФЪMarket-1501КэҫЭјҜәНDukeMTMC-reIDКэҫЭјҜЙПөДК¶ұрҪб№ы.НјЦРКөПЯҝтДЪКЗКфУЪТ»РРИЛөДХэИ·Ҫб№ыЈ¬РйПЯҝтДЪКЗЖҘЕдҙнОуөДҪб№ы.ИзНј 5aЛщКҫЈ¬ҫЎ№ЬЙгПсН·ЕДЙгөДҪЗ¶ИәНЧЛМ¬УРЧЕәЬҙуІоТмЈ¬ұҫОДЛг·ЁТАҫЙДЬ№»ЧјИ·өШК¶ұріц¶ФУҰөДРРИЛ.ИзНј 5bЛщКҫЈ¬ұҫОДЛг·ЁФЪ№вХХәНРРИЛЧЛМ¬ұд»ҜөДЗйҝцПВТІДЬҙпөҪҪПәГөДК¶ұрР§№ыЈ¬өЪ9ХЕНјПсЦРЈ¬УЙУЪРРИЛҙ©ЧЕУлQueryНјПсПаЛЖЈ¬ІъЙъ1ХЕНјПсөДОујм.
Нј 5(Fig. 5)
 | Нј 5 ЦШК¶ұрҪб№ыFig.5 Results of the re-identification (a)ЎӘMarket-1501Ј»(b)ЎӘDukeMTMC-reID. |
3 ҪбУпұҫОДҪ«CNNәНTransformerПаҪбәПУҰУГУЪРРИЛЦШК¶ұрБмУтЈ¬КЗАыУГХвЦЦ·ҪКҪҪвҫцРРИЛЦШК¶ұрОКМвөДФзЖЪіўКФЦ®Т».ұҫОДЙијЖБЛТ»ёцИ«ҫЦ-ҫЦІҝРРИЛЦШК¶ұрНшВз.И«ҫЦ·ЦЦ§АыУГҝХјдјёәО»®·ЦөД·Ҫ·Ё·ЦёоРРИЛНјПсЈ¬НЁ№эПа¶ФО»ЦГұаВләНЕъ№йТ»»Ҝ¶Ф¶аН·ЧФЧўТвБҰ»ъЦЖҪшРРёДҪшЈ¬ІўҪ«ЖдЗ¶ИлөҪҫн»эЙсҫӯНшВзЦРЈ¬ёьәГөШҪЁБўБЛіӨҫаАлПсЛШөгЦ®јдөДБӘПөЈ¬ГЦІ№БЛҫн»эЙсҫӯНшВзөДІ»ЧгЈ»ҫЦІҝ·ЦЦ§АыУГ¶аіЯ¶ИіШ»ҜөД·ҪКҪ»сөГБЛёьјУ·бё»өДНјПсҫЦІҝМШХч.ЧоәуЈ¬АыУГ»щУЪұкЗ©ЖҪ»¬ёДҪшөДҪ»ІжмШЛрК§әН»щУЪДССщұҫНЪҫтөДИэФӘЧйЛрК§¶ФДЈРНҪшРРја¶Ҫ.ұҫОДЛг·ЁФЪMarket-1501КэҫЭјҜәНDukeMTMC-reIDКэҫЭјҜЙПҪшРРБЛҙуБҝКөСйЈ¬Rank-1Цёұк·ЦұрҙпөҪ95.61%әН90.35%Ј¬mAPЦёұк·ЦұрҙпөҪ93.45%әН88.79%Ј¬ПаҪПУЪДҝЗ°»щУЪҫн»эЙсҫӯНшВзөДЛг·ЁәНҙҝTransformerҪб№№өДЛг·Ёҫ«¶И¶јУРЛщМбёЯ.
ІОҝјОДПЧ
| [1] | ВЮәЖ, ҪӘО°, ·¶РЗ, өИ. »щУЪЙо¶ИС§П°өДРРИЛЦШК¶ұрСРҫҝҪшХ№[J]. ЧФ¶Ҝ»ҜС§ұЁ, 2019, 45(11): 2032-2049. (Luo Hao, Jiang Wei, Fan Xing, et al. A survey on deep learning based person re-identification[J]. Acta Automatica Sinica, 2019, 45(11): 2032-2049.) |
| [2] | Sun Y, Zheng L, Yang Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline)[C]//Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 480-496. |
| [3] | Mahdi M K, Emrah B, Muhittin G, et al. Human semantic parsing for person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake: IEEE, 2018: 1062-1071. |
| [4] | Lin T, Dollar P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 2117-2125. |
| [5] | Zhang Z, Lan C, Zeng W, et al. Relation-aware global attention for person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 3186-3195. |
| [6] | Tay C P, Roy S, Yap K H. AANet: attribute attention network for person re-identifications[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 7134-7143. |
| [7] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv, 2020, 2010.11929. |
| [8] | Liu Z, Lin Y, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[J]. arXiv preprint arXiv, 2021, 2103.14030. |
| [9] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. La Jolla: NIPS, 2017: 5998-6008. |
| [10] | Srinivas A, Lin T Y, Parmar N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Kuala Lumpur: IEEE, 2021: 16519-16529. |
| [11] | Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2818-2826. |
| [12] | Lyu Y, Gu Y, Liu X G. The dilemma of TriHard loss and an element-weighted TriHard loss for person re-identification[J]. Advances in Neural Information Processing Systems, 2020, 33: 17391-17402. |
| [13] | Zhong Z, Zheng L, Kang G, et al. Random erasing data augmentation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto : AAAI, 2020: 13001-13008. |
| [14] | Zheng L, Shen L, Tian L, et al. Scalable person re-identification: a benchmark[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1116-1124. |
| [15] | Ristani E, Solera F, Zou R, et al. Performance measures and a data set for multi-target, multi-camera tracking[C]//European Conference on Computer Vision. Amsterdam: Springer, 2016: 17-35. |
| [16] | Shaw P, Uszkoreit J, Vaswani A. Self-attention with relative position representations[J]. arXiv preprint arXiv, 2018, 1803.02155. |
| [17] | Wang C, Zhang Q, Huang C, et al. Mancs: a multi-task attentional network with curriculum sampling for person re-identification[C]//Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 365-381. |
| [18] | Hou R, Ma B, Chang H, et al. Interaction-and-aggregation network for person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9317-9326. |
| [19] | Zheng M, Karanam S, Wu Z, et al. Re-identification with consistent attentive siamese networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5735-5744. |
| [20] | Zhong Z, Liang Z, Cao D, et al. Re-ranking person re-identification with k-reciprocal encoding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 1318-1327. |
| [21] | Si J, Zhang H, Li C G, et al. Dual attention matching network for context-aware feature sequence based person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake: IEEE, 2018: 5363-5372. |
| [22] | Jin X, Lan C, Zeng W, et al. Style normalization and restitution for generalizable person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 3143-3152. |
