

厦门大学 航空航天学院,福建 厦门 361005
收稿日期:2021-09-06
基金项目:国家自然科学基金资助项目(62171391)。
作者简介:柴沛华(1996-),女,河北邯郸人,厦门大学博士研究生。
摘要:社团的演化往往是复杂多变的,如何对这些嵌入在网络中的社团进行个性化干预,使得不同的社团朝着不同的既定方向演化的研究逐渐成为社交网络领域的一个重要问题.在社团演化的干预框架下,基于状态转移视角,提出了基于马尔可夫决策过程的社团演化干预模型.该模型通过对社团状态维度分数与干预目标的综合考虑,确立社团演化过程与马尔可夫决策过程的对应关系,对社团演化中的状态、动作、回报进行精细建模,同时将社团演化期望回报与研究者的奖励相对应,对马尔可夫决策过程求解,实现对社团演化的干预.在不同社团数据集上的实验结果表明,基于马尔可夫决策过程的干预模型能够对社团的演化进行有效的干预.
关键词:社团演化社团干预马尔可夫决策过程
The Intervention of Community Evolution Based on Markov Decision Process
CHAI Pei-hua, MAN Jun-yi, ZENG Yi-feng, CAO Lang-cai
School of Aerospace Engineering, Xiamen University, Xiamen 361005, China
Corresponding author: CAO Lang-cai,E-mail: langcai@xmu.edu.cn.
Abstract: The evolution of the community always tends to be complex and changeable. It becomes an important issue in the field of social networks about how to conduct personalized intervention on communities which are embedded in the network and make different communities evolve toward to different aims. Based on the intervention framework of community evolution, an intervention model based on Markov decision process(MDP)was proposed with the perspective of state transition. With the score of the state dimension and intervention goal, this model establishes the corresponding relationship between the evolution process and MDP, and then models the state, action, and reward in evolution process. Meanwhile, the expected reward of community evolution corresponds to the researcher's reward. By solving the MDP, the community evolution can be effectively intervened. The experiment results indicated that the community evolution intervention model based on MDP can intervene the community evolution on different true data sets.
Key words: community evolutioncommunity interventionMarkov decision process(MDP)
网络中的社团往往是拥有相似的特征或兴趣的用户的团体[1-2],其演化过程引起了****们的广泛探讨.传统社团演化算法聚焦于社团检测,发现不同时段的社团结构,以观察在不同时间节点的社团信息或结构的变化,从而挖掘人类行为的规律及其背后更深层的动机[3-5].同时对社团演化的预测可以帮助人们了解社团的未来发展方向[6-7],而对社团演化加以适当的行动予以控制和干预,可以加速或更改预期的演化方向,在实际生活中,具有很高的应用价值[8].例如,通过观测一个公关事件中网民心理、行为、交往关系的网络模型,并且在社团演化的过程中进行干预,可以指导人们如何有效进行舆论控制,以达到对事态结果的期望改变,从而有效维护网络稳定,避免造成不良信息快速传播.
目前针对社团演化的干预问题的研究工作较少,没有明确的干预模型.针对此问题,本文在实现对社团检测和有效预测基础上,为了让社团朝着既定期望目标进行演化,在状态转移视角下,提出了基于马尔可夫决策过程的社团演化干预模型, 同时设置智能体的奖励与研究者的奖励方法,并通过对马尔可夫最优策略的求解,实现对社团演化的干预.
1 社团演化干预框架1.1 社团演化与马尔可夫决策过程社团演化是在社会网络中在连续的时间片内相互接替的一系列事件变化.通常,社团演化过程区分定义了以下7种演化事件:持续、缩小、扩大、分裂、融合、消亡、生成[9].而马尔可夫决策过程是从人类作决策的真实过程中提取重要因素:动作集合A、状态集合S、回报r、折扣因子γ和状态转移概率P,构建学习模型,令智能体自主地作出决策判断[10].
在状态转移视角下,将社团演化中事件与事件之间的转移看作是一个马尔可夫过程,即当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;在给定社团现在状态时,它与过去状态(该过程的历史路径)是条件独立的,其具有马尔可夫性质.社团演化过程可视作在当前事件状态s(t)下,采取一定的措施(动作a),社团会以状态转移概率P转移至下个事件状态s(t+1).
1.2 社团演化干预流程图对社团演化进行干预的完整流程主要包括三部分:社团检测、社团演化预测和社团演化干预.其流程图见图 1.
图 1(Fig. 1)
 | 图 1 社团演化干预框架Fig.1 The framework for intervention of community evolution |
1) 社团检测.干预社团演化前,首先针对数据集进行社团检测和演化事件检测.社团检测的目的是在不同的网络中提取社团,本文采用派系过滤方法(clique percolation method, CPM)[11]发现社团;社团演化事件检测的目的是判断社团所处阶段,针对这一问题,采用社团演化发现(group evolution discovery,GED)算法[9]进行演化事件的检测.
2) 社团演化预测.在实现社团检测的基础上,要对社团演化进行多步预测,以便判断在实际应用中是否需要对社团演化进行干预.其中,基于马尔可夫链的社团演化的多步预测算法从状态转移角度着手,发掘导致社团间状态转移的潜在影响因子,能够对社团演化进行有效多步预测[12].在实验过程中,为避免预测失误带来的干扰和简化实验,以便于验证干预是否真实有效,采取真实数据进行检验.
3) 社团演化干预.在实现社团检测和精确预测的基础上,在社团演化过程中可以采取一定的干预措施,使社团朝期望的状态演化.本文提出了基于马尔可夫决策过程的社团演化干预模型.
2 基于马尔可夫过程的干预过程建模及要素分析2.1 干预过程建模要实现社团演化的合理干预,首先要对社团演化过程构建马尔可夫决策建模,而模型构建的关键在于马尔可夫决策过程的五要素如何合理地定义.考虑到马尔可夫决策过程中状态转移的特点,设计了如下模型(图 2).
图 2(Fig. 2)
 | 图 2 基于马尔可夫过程的建模示意图Fig.2 Modelling for community evolution based on MDP |
具体包含以下6个步骤:
1) 提取社团维度的特征;
2) 根据层次聚类算法[13]选取合适的状态个数值;
3) 选择相邻k的值,比较聚类后的评价指标的值,确定最合适的状态个数;
4) 聚类,标记各个社团的状态s;
5) 提取目标维度各状态的聚类中心值,并根据其排序设置回报r与状态分数;
6) 计算状态转移概率矩阵P,确定折扣因子γ.
在构建马尔可夫决策模型的五要素均被确定的条件下,其社团演化干预算法如下.
算法1??基于马尔可夫决策过程的社团演化干预算法
输入:数据集,实验参数,折扣因子.
初始化:k, s, r, a, γ
MDP建模
????提取社团维度的特征;
????模型参数求解k, s, r, a, γ;
迭代:
????1) 更新社团状态;
????2) 更新状态分数值;
????3) 更新策略.
输出:最优策略,选择最优策略对应的状态分数值.
2.2 干预模型各要素合理性分析与建模1) 社团状态的建模.从复杂网络中提取的社团是抽象的,且没有显式“状态”.由于没有已知的类别标签,为了发现社团潜在的差异,本文采用无监督学习的方法对社团进行类别区分.社团的特征对社团演化而言只是具有一定的相关性,但却是社团所处的状态的决定因素.多维拓扑特征不仅能够体现网络的静态特征,如社团的尺寸、全部节点总度数等,而且能够体现网络的动态特征,如社团的介数、最小的节点入度、最大的节点入度等.静态特征与动态特征一起描述了所有具有网络结构的子图.
因此,提取了28个不同维度用于描述社团的特征来定义状态,分别是:社团的尺寸、密度、内聚度、交互性、领导性、社团中点(最大、最小、平均、求和)的入度、出度、总度、介数、特征向量[14-15].
同时,由于拓扑特征的数量,直接影响到状态个数的数量,为避免状态数目过大对实验带来的困难,考虑如何对相似状态进行恰当聚类,以确定最适合的状态s个数k.本文采取了层次聚类算法,通过对比聚类后的戴维森堡丁指数(Davies-Bouldin index, DBI)[13]的值,确定k值,并在此基础上标记各社团的状态s.
2) 回报r的建模.社团的演化不同于其他状态转移决策过程,它往往以一个隐藏的规律在进行着演化,却没有明确的目标,因此不管是真实的社团演化数据还是人工生成数据,都不能直接对演化目标状态的好坏作出评判,即无法给出统一而明确的演化目标状态评分.而干预目标是客观存在的,例如从蛛丝马迹中发现小型犯罪团伙并进行暗中干预,目标是网络的稀疏化;为了提高社交软件的用户活跃度、增强用户的归属感而进行的干预操作,目标为提高网络连接的紧密性.因此考虑根据干预目标设置动态状态评分,控制的目标维度不同,对目标状态的评价标准随之变化.
为了适应不同的目标维度,所采取目标状态的评价标准应同步于控制目标的维度:当目标是最小化社团尺寸时,那么目标状态的社团尺寸越小,这个状态就越好;如果目标为最大化社团内最小的节点入度,那么目标状态的社团内最小节点入度越大,这个状态就越好.因此,将状态的特征用聚类中心的维度特征表示,而目标则体现在对回报值r的设置.r是形如|A|×|S|×|S|的张量,意为在动作a下由状态s转移到另一个状态s′的回报值,其中|A|为动作集合的元素数量,|S|为状态集合的元素数量.只要到达目标状态,便给予相应的奖励,对状态的奖励数量的相对大小与状态的相对好坏一一对应.即在形如|A|×|S|×|S|的奖励张量里,奖励值被设置为
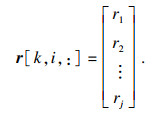 |
3) 动作集合A与状态转移概率P的建模.本文采用社团演化发现(GED)算法检测出的事件作为MDP决策中社团将要进行的动作.GED算法检测出的事件(生成,持续,扩大,融合,缩小,分裂,消亡)中,生成状态不能由其他状态转化,消亡状态不能转化为其他状态,不参与社团演化干预决策.因此实际参与建模的动作集包含以下5个动作:持续,扩大,融合,缩小,分裂.这将是处在状态集S中的每一个状态的社团在下一时刻可以进行的动作.
GED算法仅进行了SP(social position, 社团位置)和包含度的计算与比较,没有用到28个社团特征,因此动作a与状态s的检测是相互独立的,其检测的结果无依赖关系.
其中,状态转移概率P定义如下:在马尔可夫决策过程中,状态转移概率P是在动作a下由状态s转移到另一个状态s′的概率构成的张量.通过统计在不同的动作下状态转移的频率,将其作为概率,得到状态转移概率:
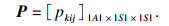 |
3 数据处理及社团检测首先对三个不同的真实网络数据集进行预处理,然后对社团演化阶段作出检测并分析不同网络中社团特点,作为后期演化干预的基础.
3.1 实验设计和数据预处理实验中,使用3个数据集来验证模型的有效性:DBLP数据集、Facebook数据集和Salon24数据集[16].
目前已知真实社团划分情况的数据集较少,大部分数据集,尤其本文所选的带有时间戳的、数据量较大、网络密度也较大的动态网络数据,是没有真实的社团划分情况作为社团检测结果的直接对照,其他步骤也都较为抽象.
由于所干预的训练数据实际上并非网络数据所涵盖的点与边本身,故原始的网络数据将经过多个数据预处理的步骤:社团检测、演化事件检测,预处理后实际用于干预的训练数据是由一个个社团串成的一条条演化链,如图 3所示,其基本单位为单条演化链,因此数据集体量逐步缩减,表现为漏斗流失过程.
图 3(Fig. 3)
 | 图 3 社团干预准备工作Fig.3 The preparation for community intervention |
3.2 社团检测对得到的连续时间片的网络数据采用CPM进行社团检测.CPM需要参数来决定社团的最小规模.实验相关参数设定如表 1.对于DBLP,Facebook和Salon24数据集,根据实际网络特性分别将值设置为7,3和5.
表 1(Table 1)
| 表 1 实验参数设置 Table 1 Setting of experimental parameters |
3.3 社团演化事件检测在得到由社团构成的连续时间片后,对每相邻两时间片的每两社团对进行演化关系检测:若第t-1个时间片检测出社团Gt-11,Gt-12,Gt-13,第t个时间片检测出社团Gt1,Gt2,那么分别对(Gt-11, Gt1),(Gt-12, Gt1),(Gt-13, Gt1),(Gt-11, Gt2),(Gt-12, Gt2),(Gt-13, Gt2)这6个社团用GED算法进行演化事件的检测.如此,可得到由存在层层关系的社团所构建的社团演化链,形如:
 |
经过检测,得到长度不同的演化链,在不同数据集上的结果如表 2所示.
表 2(Table 2)
| 表 2 特定链长的演化链数量 Table 2 The number of evolutionary chains of a specific chain length | ||||||||||||||||||||||||||||||||||||||||
表 2呈现了演化链检测的结果:在DBLP数据集上,检测出长度为2的演化链有20 324条,长度为6的演化链有135条.在Salon24数据集上,检测出长度为2的演化链有26 619条.注意:由于GED社团演化检测算法的特性,演化链由事件“生成”开始, 但不一定由事件“消亡”结束.
表 3展示了特定演化事件在不同的数据集、不同长度演化链中的分布.从表 3中可以看出,DBLP和Facebook数据集的演化链数量随着演化链长度的增加而减少,表明该数据集中的社团寿命较短.Salon24数据集(分裂事件占主导地位)则有相反的趋势.对于DBLP数据集,随着演化链长度的增加,演化链总数在减少,消亡事件数量也在减少,即群体寿命更长,导致演化链越来越长.因此,对于长度为6的演化链只随机选取10%用于训练,长度为7的演化链只随机选取5%.对于长度为8或8以上的演化链,由于计算复杂度过大,不展开实验.同时,DBLP和Facebook数据集中,演化链长为2的演化链数量远大于其他,表明在变化比较剧烈的网络中,其社团演化的方向多变,为了使社团朝着符合需求的方向发展,对社团演化进行有效的干预变得尤为重要.
表 3(Table 3)
| 表 3 特定演化事件在不同的数据集、不同长度演化链中的分布 Table 3 The distribution of specific evolution events in different data sets and different length of evolution chains | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 社团演化干预实验及分析4.1 状态个数值的确定本文采用层次聚类算法对提取特征值后的社团数据进行聚类分析,从而选取一个合适的状态个数值.用于聚类分析的数据集大小见表 4.
表 4(Table 4)
| 表 4 数据集大小 Table 4 Size of data sets | |||||||||
本文采用凝聚式层次聚类算法,不需要提前确定类别数量k,将每一个样本都单独视为一个簇,迭代式合并两个距离最近的簇.由于数据集的数据量较大,采取平均连接距离会大量增加计算成本,且类别对干预并无直接影响,因此本文选取最小连接距离进行计算,即两个簇的距离等于两个簇中距离最近的两个样本的距离,在最小的计算量下取得好的结果.为了最终确定k值大小,采用k-means算法分别对三个数据集进行聚类,观察DBI值.当k值设置为2,3,4,5时,聚类的效果如表 5所示.
表 5(Table 5)
| 表 5 不同k值下的DBI值 Table 5 DBI values under different k values |
根据表 5可知,在三个数据集中均表现出k=3时,DBI值最小,其聚类效果较好.
4.2 回报值r与状态分数值智能体达到的最终状态,即对智能体吸引力最大、能获得的回报最多的状态,这同时也是操作者想要达到的最好状态.因此,在对理想状态设置期望回报值r时,可以同时对状态设置评分.
回报值r体现了不同状态的差异性和任意的一种目的偏好.因此,在无监督学习中,选择训练数据差异最大的一维属性作为其演化达到的期望目标,并提取出实际数据,用于设定回报值r和MDP中目标状态的分数.在MDP对社团的演化作出干预并产生结果时,即达到一个状态后,统计该状态的分数,与干预前的状态分数作比较,来验证干预是否有效.
根据表 5可知,在k=3时选择差异性体现最大的一维设置演化目标,不同数据集k=3时聚类中心每个维度值如图 4所示.
图 4(Fig. 4)
 | 图 4 不同数据集k=3时聚类中心每个维度的值Fig.4 Values of each dimension in the clustering center of different data sets when k=3 (a)—DBLP数据集;(b)—Facebook数据集;(c)—Salon24数据集. |
以DBLP数据集为例,选择第2维特征作为目标,并规定该指标越大越好,输出第2维特征的值为[-0.424 4, -0.264 1, 2.383 5],则依据维度值的大小排序,所设置回报r值为[0, 5, 10].其中,r值的设定只需要遵循目标排序以达到鼓励或惩罚的作用,而不需要正比于特征值.相反,状态分数则需正比于特征值,以更准确地对社团状态好坏进行评判.
同理,对于Facebook数据集, k设置为3,选择第2维特征作为目标,该目标数值越大越好.设置r值为[0, 5, 10],记录状态分数[-0.524 2, 0.112 1, 2.975 7].对于Salon24数据集,k设置为3,选择第2维特征作为目标,该目标数值越大越好.记录状态分数为[0.189 4, -0.387 0, 4.209 8],设置r值为[5, 0, 10].
依照马尔可夫策略迭代算法,社团演化会朝着回报值最大的方向发展.为了评估干预后的社团是否优于原社团演化的方向,以干预前、后社团演化各阶段的状态分数值作为评价指标,并于下文作出比较.
4.3 社团演化干预及有效性分析通过对比社团经过自然发展达到的结果状态分数值与采取干预动作后社团达到的结果状态的分数值,进行干预有效性比较.经过演化检测后的数据集有1步演化,2步演化,…,8步演化.在DBLP数据集中,由于干预的是第2步及之后的结果,因此,比较从2步演化至8步演化的干预结果.在Facebook数据集与Salon24数据集中,由于数据量较大,只对截取部分链长的干预结果进行比较.在实验中,对结果状态分数求平均值,首先计算在该演化链长下每一步的干预或自然发展达到这一状态的分数总和,再除以演化链数.其中,求平均值的目的是消除不同链长的演化链数量的影响,对不同链长的干预结果进行比较,在不同数据集的实验结果呈现在图 5中.
图 5(Fig. 5)
 | 图 5 不同数据集中聚类中心各维度值Fig.5 Each dimension value of the cluster center in different data sets (a)—DBLP数据集;(b)—Facebook数据集;(c)—Salon24数据集. |
在图 5中,虚线是干预前社团自然发展的得分,实线是干预后的得分.在DBLP数据集上,如图 5a所示,从上至下依次是1步演化(干预),2步演化(干预), …, 8步演化(干预).可以看到实线在虚线上方,说明干预后社团各阶段演化的得分均高于干预前社团自然发展状态的得分,说明在基于马尔可夫决策过程的干预的作用下,社团确在朝着期望的方向演化,充分证明了本文提出的基于马尔可夫决策过程的社团演化干预模型的有效性.
在Facebook数据集和Salon24数据集的结果中,实线均在虚线以上,且虚线在0值附近上下波动,而实线呈现稳步上升的趋势,表明采取的“干预”使社团逐渐“步入正轨”.
5 结语本文针对社团演化的动态规律展开研究,采用真实数据集进行相关实验验证,实验结果既体现了数据集的差异性,又一定程度表现出本文提出算法的鲁棒性.同时考虑到实际应用问题,能够根据不同场景下实际需求,通过改变对目标状态的评价标准来干预社团.针对干预的结果,本文同时设置智能体的奖励与研究者的奖励方法,提高符合条件状态的回报,来影响社团演化的方向,该方法能够成功地对干预结果作评估.
在下一步的研究中,希望能够将更多的社团个性化信息纳入干预过程的考量中,以期实现更加快捷、有效、有针对性的演化干预.
参考文献
| [1] | Liu L Y, Xu L L, Wang Z, et al. Community detection based on structure and content: a content propagation perspective[C]//2015 IEEE International Conference on Data Mining. Atlantic City, 2015: 271-280. |
| [2] | Malek J, Hocine C, Chantal C, et al. Community detection algorithm evaluation with ground-truth data[J]. Physica A: Statistical Mechanics and Its Applications, 2018, 492: 651-706. DOI:10.1016/j.physa.2017.10.018 |
| [3] | 吴斌. 虚拟社区发现及演化分析研究[J]. 科技纵览, 2017(12): 70-71. (Wu Bin. Discovery and evolution analysis of virtual communities[J]. IEEE Spectrum, 2017(12): 70-71.) |
| [4] | Wang Z, Li Z, Yuan G, et al. Tracking the evolution of overlapping communities in dynamic social networks[J]. Knowledge-Based Systems, 2018, 157: 81-97. DOI:10.1016/j.knosys.2018.05.026 |
| [5] | Castellano C, Fortunato S, Loreto V. Statistical physics of social dynamics[J]. Reviews of Modern Physics, 2009, 81(2): 591-646. DOI:10.1103/RevModPhys.81.591 |
| [6] | Radicchi F, Castellano C, Cecconi F, et al. Defining and identifying communities in networks[J]. Proceedings of The National Academy of Sciences, 2004, 101(9): 2658-2663. DOI:10.1073/pnas.0400054101 |
| [7] | Yang B, Liu D Y. Force-based incremental algorithm for mining community structure in dynamic network[J]. Journal of Computer Science and Technology, 2006, 21(3): 393-400. DOI:10.1007/s11390-006-0393-1 |
| [8] | 陈福集, 杜锦锦. 网络舆情监测技术研究及应用综述[J]. 情报探索, 2014(5): 16-18. (Chen Fu-ji, Du Jin-jin. Review of studies and application of internet public opinion monitoring technologies[J]. Information Research, 2014(5): 16-18.) |
| [9] | Bródka P, Saganowski S, Kazienko P. GED: the method for group evolution discovery in social networks[J]. Social Network Analysis and Mining, 2013, 3(1): 1-14. DOI:10.1007/s13278-012-0058-8 |
| [10] | Sutton R, Barto A. Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 2018. |
| [11] | Palla G, Derenyi I, Farkas I, et al. Uncovering the overlapping community structure of complex networks in nature and society[J]. Nature, 2005, 435(7043): 814-818. DOI:10.1038/nature03607 |
| [12] | Man J Y, Zhu J R, Cao L C. Multi-step community evolution prediction methods via Markov chain and classifier chain[C]//Proceedings of 2019 Chinese Control Conference. Guangzhou, 2019: 7950-7955. |
| [13] | Kaufman L, Rousseeuw P J. Finding groups in data: an introduction to cluster analysis[M]. New York: John Wiley & Sons, 1990. |
| [14] | Newman M E J. Networks: an introduction[M]. New York: Oxford University Press, 2012. |
| [15] | Brodka P, Musial K, Kazienko N P. A performance of centrality calculation in social networks[C]//Proceedings of the 2009 International Conference on Computational Aspects of Social Network. Fontainebleau, 2009: 24-31. |
| [16] | Ley M. DBLP-some lessons learned[J]. Proceedings of Very Large Data Base Endowment, 2009, 2(2): 1493-1500. |
