
 , 刘晏泽1,3, 刘呈隆1,2, 张甜洁1,2
, 刘晏泽1,3, 刘呈隆1,2, 张甜洁1,2 1. 东北大学 工商管理学院,辽宁 沈阳 110819;
2. 东北大学秦皇岛分校 经济学院,河北 秦皇岛 066004;
3. 东北大学秦皇岛分校 管理学院,河北 秦皇岛 066004
收稿日期:2021-12-06
基金项目:国家自然科学基金资助项目(71701036);中央高校基本科研业务费专项资金资助项目(N2123022)。
作者简介:马源源(1983-), 女, 辽宁沈阳人, 东北大学副教授。
摘要:股市中存在与投资者舆情有关的非理性现象,舆情与股市关系的量化研究对发掘股市规律和辅助投资预测具有重要意义.本文基于论坛中的投资者发言,创新性地建立CNN-TLDA混合模型对舆情进行多角度量化分析,从积极度和关注主题两方面探究投资者舆情和股市的相互影响关系,并基于长短时记忆(LSTM)网络对舆情在股市预测中的作用进行探讨.研究表明:中国股市投资者普遍悲观,投资者乐观度和关注主题都与股市高度相关.多角度舆情分析使预测误差下降至41%.研究成果能够辅助投资者的投资决策,也能为股市中个体投资者舆情的分析与利用提供科学参考.
关键词:投资者舆情卷积神经网络LDA模型长短时记忆网络股市预测
Chinese Investors' Multi-perspective Sentiment Analysis and Its Role in Stock Market Forecasting
MA Yuan-yuan1,2
, LIU Yan-ze1,3, LIU Cheng-long1,2, ZHANG Tian-jie1,2 1. School of Business Administration, Northeastern University, Shenyang 110819, China;
2. School of Economics, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China;
3. School of Management, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
Corresponding author: MA Yuan-yuan, E-mail: ma_yuanyuan@163.com.
Abstract: There are irrational phenomena related to investor sentiment in the stock market, and the quantitative study of investor sentiment and stock market is important for discovering stock market patterns and aiding investment forecasting. Based on the investor statements in forums, a CNN-TLDA hybrid model is innovatively built to quantify investor sentiment from multiple perspectives, and explore the interaction between investor sentiment and the stock market from both positive and topic. The roles of investor sentiment in forecasting are investigated based on LSTM (long short-term memory) network. It is shown that Chinese stock market investors are generally pessimistic, and both investor optimism and topics of interest are highly correlated with the stock market. The multi-perspective sentiment analysis reduces the prediction error to 41%. The results of the study can assist investors in their investment decisions and also provide a scientific reference for the analysis and utilization of individual investors′ sentiment in the stock market.
Key words: investor sentimentCNN(convolutional neural network)LDA(latent Dirichlet allocation) modelLSTM(long short-term memory) networkstock market prediction
在以往的股市预测研究中,****们大多仅考虑股市的理性因素[1].但在实际的股市中,存在很多历史数据难以解释的现象[2].例如,行为金融学中所涉及的投资者对股市产生直接影响的重要因素,即投资者情绪[3].股市舆情首先通过媒体进行传播,经由经理人和个人投资者进行传染和扩散,最终对股市整体造成影响[4].因此,有部分研究者开始在股市预测的研究中考虑投资者舆情的影响.Creamer[5]通过收集相关企业的新闻和管理者的社会关系以进行舆论分析,并用分析结果来优化投资组合.Lemmon等[6]发现,投资者舆情对股市的短期预测有辅助作用.Hu等[7]以美国股市为研究对象,借助谷歌指数表示投资者关注度,提高了预测精度.Liang等[8]对报纸新闻、互联网新闻和投资者舆情都进行了分析,从不同角度证明了舆情对于股市的影响效果.Bollen等[9]从7个维度量化了投资者舆情,并证明了量化结果与股市的走势显著相关.
对于量化投资者舆情所必要的自然语言处理来说,重要的一环就是文本数据的编码预处理.Word2Vec作为全新的基于上下文的编码方法,依赖Skip-grams模型或连续词袋(continuous bag-of-words,CBOW)模型来进行词嵌入,能够学习词语间的语义相关关系[10],并且通过使用特定领域语料库提取语义关系方面更准确的特定领域词向量[11].同时,近年来卷积神经网络(convolutional neural networks,CNN)在文本分析领域的应用也使模型能够捕捉句子中的语序信息和词组搭配,使文本分类、结果更加准确[12].Guo等[13]使用TF-IDF表示词语的重要性,建立多通道TextCNN来使模型能够同时捕获词语的上下文关系和重要性.此外,潜在狄利克雷分布(latent Dirichlet allocation,LDA)也被用于提取文档特征[14].这种无监督学习方法能将文档分为指定个数的主题,并获取文档中的重点[15].Wan等[16]提出了一种关联约束LDA模型(AC-LDA)来有效地捕获共现关系,并进一步提高意见词的提取率.Xie等[17]使用基于转换器的双向编码表征和LDA主题模型来分析主题演变,揭示不同语言撰写的科学出版物之间的主题相似性.通过这些方法,不仅可以捕获文本数据中的多种特征,还能够将文本数据数值化,以进一步分析其与股市之间的关系并应用于股市预测.
使用数学模型对股市进行短期预测一直是金融研究领域的核心问题之一,以往研究者们常用的经典模型包括自回归(autoregressive,AR)模型[18]和移动平均(moving average,MA)模型[19],以及以上两个模型的混合模型——移动平均自回归(autoregressive integrated moving average,ARIMA)模型[20].然而,由于影响股市的因素众多并且股指常为非线性,这些时序模型的预测性能都表现一般.随着机器学习模型在金融领域的使用,研究者们尝试应用更多模型来预测股票市场,比如长短时记忆(long short-term memory,LSTM)网络[21, 22],支持向量机(support vector machine,SVM)[23],循环神经网络(recurrent neural network,RNN)[24],反向传播神经网络(back propagation neural network,BPNN)[25-26].
相比于传统时序模型,机器学习模型不但能有效提升模型处理复杂问题的性能,而且易于与其他方法和模型混合使用,其在股市预测领域也得到了广泛的运用[27].相对于BPNN等全连接神经网络模型,LSTM由于能够对数据的时序信息进行学习和遗忘,成为了股市预测的常用模型之一[28].Yadav等[29]为印度股市创建了一个数据集,并为其开发了优化超参数的LSTM.Ghosh等[30]同时使用随机森林模型和LSTM模型对股市进行预测,根据预测进行投资模拟并跑赢了大盘.Moghar等[31]对LSTM在股市中可预测的精度和性能进行了验证.Baek等[32]将2个LSTM组合并添加过拟合模块,提高了模型的预测精度.
综上所述,投资者舆情对股市的影响不可忽视,对舆情的量化分析是科学认识、分析股市的必要过程.目前针对投资者舆情的量化分析主要以投资者情感的积极程度为参考,探究投资者情感积极度与股市之间的关系,而忽视了语义层面的投资者关注主题的变动对股市的影响.本文基于东方财富网股吧中的投资者发言,从投资者发言积极程度和每日投资者关注主题两方面进行文本挖掘,从多角度对投资者舆情进行量化和分析,研究投资者舆情与股市之间的关系和其在股市预测中的作用.
1 模型与方法为了实现对投资者舆情的多角度量化,本文在使用Word2Vec模型将文本数据向量化后,基于文本卷积神经网络(TextCNN)文本分类模型和LDA主题模型进行研究.同时针对LDA模型可能会有主题同质性的问题,引入TF-IDF方法形成TLDA模型,进一步建立CNN-TLDA模型,对文本数据从投资者积极度和关注主题两方面进行多角度量化.进而将量化的多维舆情指标和股市历史数据一起引入LSTM预测模型,形成多角度舆情分析LSTM(MSA-LSTM)预测模型以进一步分析投资者舆情在股市预测中的作用.
1.1 基于Word2Vec的文本处理对于收集到的文本数据,需要将其数值化才能够用于文本分析模型中.与英文数据不同的是,中文句子是由连续的汉字构成,在表达语义的词组与词组之间没有自然划分,因此在中文文本数值化之前,首先需要对数据进行分词,将一个连续的句子拆分成数个词.对于拆分后的词串,需要进行停用词处理,删除对语义判别没有帮助的词和标点,减小处理后的数据规模从而提高模型学习的效率和精度.
经过分词和消除停用词后,即可将处理后的词串进行数值化,将每个词转化为独特的词向量.Word2Vec是谷歌2013年发布的词嵌入模型.它能用上下文预测目标词的连续词袋模型和用目标词预测上下文Skip-gram模型将词训练成词向量.与传统的one-hot encoder方法相比,这种方法不仅能使用独特的词向量表示每一个词,还能够通过词向量表示出词的语义关系,通过余弦相似度还可表示词与词之间的语义相似程度.同时由于该方法生成词向量的维度可以自己定义,根据文献[10],词向量维度一般设定在100到800之间,而在传统方法中,词向量的维度数与独特的词数相同.采用Word2Vec能够大幅降低文本分析模型的计算成本,同时也使词向量搭载的信息更多.
本文选取国内的股票投资论坛——东方财富网股吧,使用网络爬虫技术获取其中的文本数据并进行文本分析.构筑Word2Vec模型训练词向量后,能够得到尺寸为n×k的二维矩阵,其中n为语料中独特的词的个数,k为模型设定的词向量维度.
1.2 基于TextCNN的情绪分类模型TextCNN是融合词向量嵌入的针对文本进行分类的CNN,是由Kim[33]提出的短文本分类模型,是目前性能最好的自然语言处理模型之一.TextCNN能够高效地从语料中捕获到对应特征,由嵌入层、卷积层、池化层和一个全连接层构成,如图 1所示.
图 1(Fig. 1)
 | 图 1 TextCNN网络结构图Fig.1 TextCNN network structure diagram |
在嵌入层,每个词与经由Word2Vec模型训练得到的k维词向量一一对应,于是一个由n个词构成的句子将会作为一个n×k的词向量矩阵输入.卷积层会通过多个卷积核对词向量矩阵进行卷积,每一个卷积核都是k×l的矩阵,其中l是卷积核的大小.每个卷积核从第1个词开始卷积n-l+1次,每一次卷积时起点向后推移一个词,第i次卷积的过程如式(1)所示:
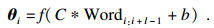 | (1) |
因此,一个长度为n的句子经一个大小为l的卷积核卷积后,可以得到一个(n-l+1)×l维的向量,并输入到池化层中进行池化.池化是一个特征提取和数据降维的过程,本文使用Max-pooling方式,即对于每个卷积后得到的向量,都取其最大值作为特征并输出至全连接层.由此,每一个卷积核卷积得到的向量经过池化后都会输出一个特征值,即无论文本长度是否相同,经过卷积和池化后,都会变成一个特征值输出,即池化层最终能够得到一个m维的向量V,其中m为卷积核的个数,与句子长度n无关.这个向量V即是全连接层的输入.在本文的TextCNN中,全连接层具有2个输出神经元,并且使用softmax作为输出层的激活函数来进行分类,softmax函数如式(2)所示:
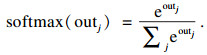 | (2) |
此外,经模型分类后,通过计算每日正向帖子的占比,就可量化每日的投资者积极度,如式(3)所示:
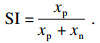 | (3) |
1.3 基于TF-IDF和LDA的TLDA主题模型1.3.1 LDA主题建模LDA主题模型是能够描述语料库中主题特征的一个生成模型.通过词袋方法,将每个待分析的文档以向量的形式表示,向量的维数即为独立的词数,每个维度代表对应词在该文本中的词频.
基于贝叶斯模型,LDA使用一个联合分布计算潜在变量——主题的概率分布,从而将每个文档转化为一个多维向量,向量的维数即为预先设定的主题个数,每个维度代表文档属于该主题的概率分布,同时每个主题的关键词和词的概率分布也可通过模型得到.并且由于主题关键词的产生不依赖具体的文档,因此文档的主题分布和主题的关键词分布是相互独立的.
1.3.2 基于TF-IDF对LDA的改进传统LDA模型使用词袋模型对文档中的每个词编码并输入模型,这种编码方式仅以词频表示文档中词的占比,难以表达词的独特性,可能会导致主题的过度相似.针对这个问题,本文引入TF-IDF与LDA组合成TLDA来优化编码方式.TF-IDF是一种加权方式,用以评估词对于一个语料库中的其中一个文档的重要程度.词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比减少.一个词的TF-IDF值越大,说明此词具有很好的类别区分能力,适合用来分类.
TF-IDF实际上是term frequency(TF)与inverse document frequency(IDF)的乘积,如式(4)所示:
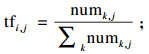 | (4) |
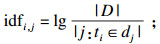 | (5) |
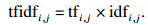 | (6) |
由此,可得到每个词在各个文档中的TF-IDF值,用代替词频作为LDA的输入,模型能够更好地捕获文档的主题特征.
1.4 基于LSTM的预测模型长短时记忆(LSTM)网络是循环神经网络(RNN)的一种.RNN具有记忆环节,将时间序列中前面的数据特征记录下来作为后面数据的特征之一,相比于其他神经网络模型能够更好地处理序列数据.但RNN的循环结构会导致处理长序列数据时前面的数据中的无用特征被长期记录,从而发生梯度消失或梯度爆炸问题.针对这一问题,LSTM在RNN中加入了遗忘环节,对长序列中的不重要信息进行遗忘.
每个LSTM节点包含一个输入门ig,一个输出门og,一个遗忘门fg和一个记忆单元mu.在时刻t时,LSTM基于输入数据int和上一时刻的隐藏状态ht-1对目前时刻的隐藏状态ht进行更新,并向下一时刻传递.更新过程如下式所示:
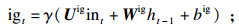 | (7) |
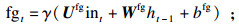 | (8) |
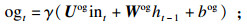 | (9) |
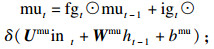 | (10) |
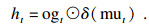 | (11) |
LSTM的单元结构和每个时刻LSTM更新过程如图 2所示.
图 2(Fig. 2)
 | 图 2 LSTM网络结构图Fig.2 LSTM network structure diagram |
2 基于东方财富网股吧和上证指数的实证研究上证指数是以上海证券交易所挂牌上市的全部股票为计算范围,以发行量为权数的加权综合股价指数,能够很好地反映中国的股市行情.本文基于东方财富网股吧,以上证指数为例,探究舆情因素在中国股市中的影响,并对舆情因素对于股市预测的辅助效果进行研究.
2.1 基于论坛发言的多角度舆情分析东方财富网股吧(https://guba.eastmoney.com/)是中国最大的投资者交流论坛,每天都有大量活跃用户在论坛中发表自己对股市的看法.这些数据表现了最真实的一般投资者的舆论,对论坛中的投资者发言进行分析整理,就能够捕获到股票市场中的个体投资者情绪.
本文使用Python爬虫技术从东方财富股吧的上证指数板块中获取到2020年1月16日至2021年10月15日共421个交易日的全部帖子,经数据清理去除重复发言和空白帖子后,得到共计1 316 971条文本数据用于文本分析.为了了解个体投资者的关注重点,将语料进行分词、去除停用词后,进行词频统计以获取关键词.高频词词频如表 1所示,词云如图 3所示.
表 1(Table 1)
| 表 1 股吧发言词频 Table 1 Word frequency of Guba |
图 3(Fig. 3)
 | 图 3 股吧发言词云图Fig.3 Word cloud of Guba |
由表 1和图 3可以看出,首先,股市的整体行情和个股表现都是投资者们关注的重点,股市整体的表现和市场中资金的流向都是投资者们议论的核心主题.其次,在投资者乐观程度方面,下跌等悲观词汇的出现次数远高于上涨等乐观词汇的出现次数,说明投资者整体情绪较为悲观.
2.1.1 基于TextCNN情感分类模型的二元语义分析在本文所获取到的语料中,经分词、去除停用词后可以得到237 458个独特的词,但绝大多数词语只在语料库中出现了一两次,对于词向量训练用处不大,且严重拖慢训练速度.故在基于Word2Vec的语料数值化过程中,为了提高模型学习效率,过滤掉了词频在10以下的词,将余下的36 348个独特的词训练成了36 348个150维的词向量.
在嵌入层中,每个词与其训练得到的词向量一一对应,未训练词向量的词均以一个150维的0表示,由此得到一个尺寸为(237 458, 150)的嵌入层,将文本转化为(n, 150)维的矩阵输入至卷积层,其中n是句子的长度.此外,为了防止句子太短而无法卷积,设定n最小为7,无内容部分用0填充.在卷积层,分别使用尺寸为2, 3, 4, 5的卷积核各64个对输入矩阵进行卷积,卷积后可得到256个特征向量.在池化层中,通过Max-pooling方式,从每个特征向量中得到一个特征值,由此,每个句子都会被转化为一个256维的特征向量.由于模型将进行二元语义分类,全连接层的输出节点数应为2,分别代表积极、消极,为了防止训练数据中出现数据错误,另加一个输出节点以剔除异常数据,由此构建一个尺寸为256×3的全连接层,并使用softmax函数作为激活函数,最终完成文本分类.
为了训练TextCNN模型,本文从获取到的文本数据中随机选取5 000条并对其进行人工标记,将积极的帖子内容标记为1,消极的内容标记为0.标记后的文本中的80%作为训练集对模型进行训练,并用剩余的20%作为测试集,验证模型的分类性能,同时使用one-hot encoding和梯度提升决策树(GBDT)模型进行对比.模型训练结果如表 2所示.
表 2(Table 2)
| 表 2 分类器性能 Table 2 Classifier performance |
结果表明Word2Vec和TextCNN的组合展现了更高的分类准确度,85.4%的准确度足以支持下一步的情绪量化.
图 4展示了每日量化投资者积极度的分布,投资者积极度整体接近正态分布,集中于0.1至0.16之间,即每日看涨的投资者发言经常仅占当日发言的20%以下.这表明了在社交平台上,股民们对股市表现普遍不满,悲观情绪占据舆论的主导,这也符合投资者普遍期望获得更高收益的心理.
图 4(Fig. 4)
 | 图 4 投资者积极度分布Fig.4 Investor positivity distribution |
进一步观察投资者积极度与股市的关系,如图 5所示,以2021年为例,可以看出投资者积极度的量化曲线与股市的涨跌具有良好的拟合效果,这说明投资者积极度受到股市表现影响,且几乎没有滞后,表示投资者在当日内即会对股市变动做出迅速反应,并在社交媒体中产生反馈.同时在部分区间,情绪的变动快于股市变动,说明投资者情绪能够预示或影响股市的变动.
图 5(Fig. 5)
 | 图 5 投资者积极度和股市涨跌曲线图Fig.5 Investor positivity and stock market change |
2.1.2 基于TLDA的主题分析在TLDA模型中,通过多次实验的方式选择合适的主题数,最终本文选取了4个主题,表 3展示了主题划分的结果以及对应的关键词,关键词由主题内独特的高频词组成.
表 3(Table 3)
| 表 3 TLDA主题建模结果 Table 3 Results of TLDA topic modeling |
表 4展示了4个主题的描述性统计,主题的最小值和最大值说明,每日的投资者发言中不一定都存在所有主题,有一些可能只存在一个主题.
表 4(Table 4)
| 表 4 主题分布的描述性统计 Table 4 Descriptive statistics of topic distribution |
图 6为每月的主题分布以及股市指数的平均值曲线.受新冠疫情影响,2020年中国股市整体处于动荡之中,第一季度疫情爆发使经济受挫,股市持续下跌,第二季度开始疫情有所控制,经济回暖,股市大幅反弹,而2021年中国股市并无大幅度波动,以平稳震荡为主.对比主题分布与股指可以看出,首先,主题1在早期股市动荡时期出现较少,2020年7月后和2021年第一季度分布较多,说明投资者对大盘的关注更多在股市平稳震荡时期.其次,主题2在除了新冠肺炎疫情爆发期之外均占据投资者舆论的主体地位,说明个股的表现始终是股民们关注和讨论的重点.最后,在2020年的股市动荡阶段,主题3和主题4的分布较高,其中在2020年初的疫情爆发期和7月的股市暴涨期出现最多,但在2021年第一季度股市平稳时逐渐消失,说明在动荡时期,投资者会更关注股市变动,也会进行更多有关投资行为的讨论.
图 6(Fig. 6)
 | 图 6 主题分布和股指曲线图Fig.6 Topic distribution and stock index curves |
2.1.3 量化情绪与股市的相关性分析为了进一步探寻量化情绪与股市之间的关系,本文分析了投资者积极度、主题向量这些量化情绪与股市的次日收盘价的相关性.同时还分析了量化情绪与能够表示投资者行为的当、次日成交量、成交额、换手率之间的相关性以探寻情绪与投资者行为之间的关系.相关分析结果如图 7所示,其中**表示两变量在置信度(双测)为0.01时显著相关.
图 7(Fig. 7)
 | 图 7 相关分析结果Fig.7 Results of correlation analysis |
从图 7可以看出,在投资者行为方面,投资者积极度、主题1和主题3与当、次日的3个表示投资者行为的指标均显著相关,这表示投资者情绪与投资者行为之间有紧密的联系,投资者积极度和投资者对部分主题的关注度能够反映出当日投资者所进行的投资操作,同样这些量化情绪也能够预示次日投资者将要进行的投资操作.此外,量化情绪与次日行为指标的相关系数均大于与当日行为指标的相关系数,说明投资者的情绪因素具有更高的投资行为预示性.其中投资者积极度和主题1与表示投资者行为的指标显著正相关,说明投资者在进行投资行为时会表现出较高的积极度,也会进行更多关于股市的讨论,同时投资者对股市的关注和较高的积极情绪也能够促进次日的投资行为.同时主题3与股市的行为指数显著负相关,说明股市动荡和对牛市的鼓吹会使得投资者对投资行为更为慎重.
在股指方面,投资者积极度、主题1、主题2与次日收盘价正相关,主题3、主题4与次日收盘价负相关,LDA结果和投资者积极度都与次日收盘价显著相关,且其中LDA结果的相关系数更高.这些结果说明了投资者情绪能够通过某种形式去影响股市,将投资者情绪分析量化并加入回归模型中能够提高模型对股市的解释能力.并且,LDA结果的相关系数远高于投资者积极度的相关系数,说明采用多角度舆情分析的量化结果远优于单独的情感二元极性分析.在所有主题中,主题1和主题3与各指标的相关系数更大,说明与股市整体表现相关的主题更能够反映投资者行为.
2.2 基于LSTM的股市预测多角度情绪分析基于前文的投资者舆情分析,各量化情绪都与股市次日收盘价之间表现出了显著的相关性,说明这些量化情绪的引入能够提升预测模型的预测能力.为进一步分析情绪在股市预测中的作用,本节将LSTM作为初始模型,使用2020年至2021年两年的数据进行验证.
作为对照,本文构建3个LSTM模型并对次日的上证指数收盘价进行预测(见表 5).模型1,不添加任何量化情绪,只使用股市历史数据的LSTM模型.模型2,在模型1的基础上添加基于TextCNN文本分类模型量化得出的投资者积极度作为预测特征值的单角度舆情分析LSTM(SA-LSTM)模型.模型3,对文本进行多角度舆情分析,使用投资者积极度、基于TLDA模型量化得到的主题分布和股市历史数据进行预测的MSA-LSTM.
表 5(Table 5)
| 表 5 预测模型误差值 Table 5 Error value of the prediction model | |||||||||||||||||||||||||
本文使用2020/01/16至2021/08/09的379个交易日的数据对这3个模型分别进行训练,并使用2021/08/10至2021/10/15的42个交易日的数据作为测试集,验证3个模型的性能.图 8是3个模型的拟合曲线图.从图 8可以看出,考虑舆情因素的预测模型的拟合效果更加优秀,其中使用多角度舆情分析能够进一步提升模型的预测性能.表 5是3个模型在测试集上的误差,舆情因素的加入使模型的均方误差降低了38%,从多角度考虑投资者情绪能进一步将均方误差降低至LSTM的41%.这表示考虑舆情因素能够完善预测模型,投资者舆情因素的加入能够增加模型的可解释性,使模型结构更加贴近现实,并且本文提出的多角度舆情量化能够更全面地对投资者行为进行分析.
图 8(Fig. 8)
 | 图 8 预测拟合曲线Fig.8 Prediction fitting curves |
3 结语研究结果表明投资者舆情因素与我国股市具有显著的相关性,加入多维舆情因素能大幅减少预测模型的误差,对我国股市有较好的预测效果.
在中国投资者网络论坛中,大盘的整体情况、个股的表现以及市场中的资金流向等宏观信息是投资者关注的重点.同时股民们对股市的表现普遍不满,悲观词汇占据舆论的主导.
对投资者积极度量化结果表明,股市情绪普遍消极,仅有不到20%的积极评论,将投资者积极度与股市涨跌对比,投资者情绪的变动与股市变动趋势基本一致,表明投资者情绪与股市变动互相影响.对投资者发言的主题建模结果表明,相较于股市整体表现,投资者更经常关注个股的实际情况,并且在股市剧烈动荡时期,投资者会进行更多的投资相关讨论,在股市平稳时期,股市整体表现则是投资者热议的话题.
相关分析结果表明,多个量化情绪均与次日的股市收盘价显著相关,说明了投资者情绪能够通过某种形式去影响股市,量化情绪的引入能够提升预测模型的预测能力.此外,在投资者行为方面,投资者的情绪积极度和对股市整体以及投资行为的关注度与代表股市行为的指标显著相关,说明情绪因素能够对股市的非理性现象作出解释,投资者的乐观程度和关注重点会对投资者行为产生影响.
基于LSTM预测模型进一步分析投资者量化情绪在股市预测中的作用发现:首先,考虑舆情因素可使模型预测的MSE降低38%;其次,与传统的情绪二元分析量化相比,本文提出的多角度舆情量化方法对预测模型的优化效果更好,MSE降低至LSTM模型的41%.说明多角度的舆情分析能够使模型更全面地解释股市中的投资者非理性行为,投资者的情绪积极度和关注重点都能够对股市预测起到辅助作用.
参考文献
| [1] | Li X, Wu P, Wang W. Incorporating stock prices and news sentiments for stock market prediction: a case of Hong Kong[J]. Information Processing and Management, 2020, 57(5): 1-18. |
| [2] | Wu Y, Liu T, Han L, et al. Optimistic bias of analysts' earnings forecasts: does investor sentiment matter in China?[J]. Pacific Basin Finance Journal, 2018, 49: 147-163. DOI:10.1016/j.pacfin.2018.04.010 |
| [3] | de Long J B, Shleifer A, Summers L H, et al. The survival of noise traders in financial markets[J]. The Journal of Business, 1991, 64(1): 1-26. DOI:10.1086/296523 |
| [4] | Barberis N, Xiong W. Realization utility[J]. Journal of Financial Economics, 2012, 104(2): 251-271. DOI:10.1016/j.jfineco.2011.10.005 |
| [5] | Creamer G G. Can a corporate network and news sentiment improve portfolio optimization using the Black-Litterman model?[J]. Quantitative Finance, 2015, 15(8): 1405-1416. DOI:10.1080/14697688.2015.1039865 |
| [6] | Lemmon M, Portniaguina E. Consumer confidence and asset prices: some empirical evidence[J]. Review of Financial Studies, 2006, 19(4): 1499-1529. DOI:10.1093/rfs/hhj038 |
| [7] | Hu H, Tang L, Zhang S, et al. Predicting the direction of stock markets using optimized neural networks with Google Trends[J]. Neurocomputing, 2018, 285: 188-195. DOI:10.1016/j.neucom.2018.01.038 |
| [8] | Liang C, Tang L, Li Y, et al. Which sentiment index is more informative to forecast stock market volatility? Evidence from China[J]. International Review of Financial Analysis, 2020, 71: 101552. DOI:10.1016/j.irfa.2020.101552 |
| [9] | Bollen J, Mao H, Zeng X. Twitter mood predicts the stock market[J]. Journal of Computational Science, 2011, 2(1): 1-8. DOI:10.1016/j.jocs.2010.12.007 |
| [10] | Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07)[2021-10-14]. http://doi.org/10.48550/arXiv.1301.3781. |
| [11] | Khatua A, Khatua A, Cambria E. A tale of two epidemics: contextual Word2Vec for classifying Twitter streams during outbreaks[J]. Information Processing and Management, 2019, 56(1): 247-257. DOI:10.1016/j.ipm.2018.10.010 |
| [12] | Sharma A K, Chaurasia S, Srivastava D K. Sentimental short sentences classification by using CNN deep learning model with fine tuned Word2Vec[J]. Procedia Computer Science, 2020, 167: 1139-1147. DOI:10.1016/j.procs.2020.03.416 |
| [13] | Guo B, Zhang C, Liu J, et al. Improving text classification with weighted word embeddings via a multi-channel TextCNN model[J]. Neurocomputing, 2019, 363: 366-374. DOI:10.1016/j.neucom.2019.07.052 |
| [14] | Ozyurt B, Akcayol M A. A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA[J]. Expert Systems with Applications, 2021, 168: 114231. DOI:10.1016/j.eswa.2020.114231 |
| [15] | Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(4): 993-1022. |
| [16] | Wan C, Peng Y, Xiao K, et al. An association-constrained LDA model for joint extraction of product aspects and opinions[J]. Information Sciences, 2020, 519: 243-259. DOI:10.1016/j.ins.2020.01.036 |
| [17] | Xie Q, Zhang X, Ding Y, et al. Monolingual and multilingual topic analysis using LDA and BERT embeddings[J]. Journal of Informetrics, 2020, 14(3): 101055. DOI:10.1016/j.joi.2020.101055 |
| [18] | Petrevska B. Predicting tourism demand by ARIMA models[J]. Economic Research-Ekonomska Istraivanja, 2017, 30(1): 939-950. DOI:10.1080/1331677X.2017.1314822 |
| [19] | Zhang M, Pi D. A new time series representation model and corresponding similarity measure for fast and accurate similarity detection[J]. IEEE Access, 2017, 5: 24503-24519. DOI:10.1109/ACCESS.2017.2764633 |
| [20] | Pai P F, Lin C S. A hybrid ARIMA and support vector machines model in stock price forecasting[J]. Omega, 2005, 33(6): 497-505. DOI:10.1016/j.omega.2004.07.024 |
| [21] | Fischer T, Krauss C. Deep learning with long short-term memory networks for financial market predictions[J]. European Journal of Operational Research, 2018, 270(2): 654-669. DOI:10.1016/j.ejor.2017.11.054 |
| [22] | Chen K, Zhou Y, Dai F. A LSTM-based method for stock returns prediction: a case study of China stock market[C]//2015 IEEE International Conference on Big Data. New York: IEEE, 2015: 2823-2824. |
| [23] | Huang W, Nakamori Y, Wang S Y. Forecasting stock market movement direction with support vector machine[J]. Computers and Operations Research, 2005, 32(10): 2513-2522. DOI:10.1016/j.cor.2004.03.016 |
| [24] | Hsieh T J, Hsiao H F, Yeh W C. Forecasting stock markets using wavelet transforms and recurrent neural networks: an integrated system based on artificial bee colony algorithm[J]. Applied Soft Computing, 2011, 11(2): 2510-2525. DOI:10.1016/j.asoc.2010.09.007 |
| [25] | Wang J, Wang J. Forecasting stock market indexes using principle component analysis and stochastic time effective neural networks[J]. Neurocomputing, 2015, 156: 68-78. DOI:10.1016/j.neucom.2014.12.084 |
| [26] | Zhang W, Zhang S X, Zhang S, et al. A novel method based on FTS with both GA-FCM and multifactor BPNN for stock forecasting[J]. Soft Computing, 2019, 23(16): 6979-6994. DOI:10.1007/s00500-018-3335-2 |
| [27] | Yuan C, Sun X, Wu Q M J. Difference co-occurrence matrix using BP neural network for fingerprint liveness detection[J]. Soft Computing, 2019, 23(13): 5157-5169. DOI:10.1007/s00500-018-3182-1 |
| [28] | Lin Y, Yan Y, Xu J, et al. Forecasting stock index price using the CEEMDAN-LSTM model[J]. North American Journal of Economics and Finance, 2021, 57: 101421. DOI:10.1016/j.najef.2021.101421 |
| [29] | Yadav A, Jha C K, Sharan A. Optimizing LSTM for time series prediction in Indian stock market[J]. Procedia Computer Science, 2020, 167: 2091-2100. DOI:10.1016/j.procs.2020.03.257 |
| [30] | Ghosh P, Neufeld A, Sahoo J K. Forecasting directional movements of stock prices for intraday trading using LSTM and random forests[J]. Finance Research Letters, 2022, 46: 102280. DOI:10.1016/j.frl.2021.102280 |
| [31] | Moghar A, Hamiche M. Stock market prediction using LSTM recurrent neural network[J]. Procedia Computer Science, 2020, 170: 1168-1173. |
| [32] | Baek Y, Kim H Y. ModAugNet: a new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module[J]. Expert Systems with Applications, 2018, 113: 457-480. |
| [33] | Kim Y. Convolutional neural networks for sentence classification[EB/OL]. (2014-09-03)[2021-10-15]. http://doi.org/10.48550/arXiv:1408.5882. |
