

吉林大学 软件学院,吉林 长春 130012
收稿日期:2021-03-05
基金项目:吉林省自然科学基金资助项目(20180101043JC);吉林省发展和改革委员会基金资助项目(2019C053-9)。
作者简介:李占山(1966-),男,吉林公主岭人,吉林大学教授,博士生导师;
张家晨(1969-),男,吉林德惠人,吉林大学教授。
摘要:互信息过滤式特征选择算法往往仅局限于互信息这一度量标准.为规避采取单一的互信息标准的局限性,在互信息的基础上引入基于距离度量的算法RReliefF,从而得出更好的过滤式准则.将RReliefF用于分类任务,度量特征与标签的相关性;应用最大互信息系数(maximal information coefficient,MIC)度量特征与特征之间的冗余性、特征与标签的相关性;最后,应用熵权法为MIC和RReliefF进行客观赋权,提出了基于熵权法的过滤式特征选择算法(filtering feature selection algorithm based on entropy weight method,FFSBEWM).在13个数据集上进行对比实验,结果表明,FFSBEWM所选择的特征子集的平均分类准确率和最高分类准确率均优于其他对比算法.
关键词:特征选择熵权法互信息过滤式准则信息理论
Filtering Feature Selection Algorithm Based on Entropy Weight Method
LI Zhan-shan, YANG Yun-kai, ZHANG Jia-chen
College of Software, Jilin University, Changchun 130012, China
Corresponding author: ZHANG Jia-chen, E-mail: zhangjc@jlu.edu.cn.
Abstract: Mutual information-based filtering feature selection algorithms are often limited to the metric of mutual information. In order to circumvent the limitations of adopting only mutual information, a distance metric-based algorithm RReliefF is introduced on the basis of mutual information to obtain better filtering criteria. RReliefF is used for the classification tasks to measure the relevance between features and labels. In addition, maximal information coefficient(MIC) is used to measure the redundancy between features and the relevance between features and labels. Finally, entropy weight method is applied to objectively weigh the MIC and RReliefF. On this basis, a filtering feature selection algorithm based on entropy weight method(FFSBEWM) is proposed. Comparing experiments carried out on 13 data sets show that the average classification accuracy and highest classification accuracy of the feature subsets selected by the proposed algorithm are higher than those of the comparison algorithms.
Key words: feature selectionentropy weight methodmutual informationfiltering criteriainformation theory
特征选择是模式识别和数据挖掘中的一个重要预处理步骤.其本质含义是指在不明显损失数据集潜在信息的基础上从原始特征集合中选出部分特征构成特征子集,以此来降低数据集的特征维度,规避维度灾难,提高分类的时间效率,它可以缩减训练时间并产生具有可解释性的模型[1].
一般地,特征选择可以分为过滤式[2]、封装式(包裹式)[3-5]、嵌入式[6-7].过滤式特征选择算法的核心在于过滤标准,即通过某种准则对特征(子集)进行度量.为此人们提出了多种评价准则,如基于距离度量标准的RReliefF[8]、基于互信息理论的准则[9]等.
近年来人们提出了多种基于互信息理论的过滤式特征选择算法,如MIFSU[10]、mRMR[11]、NMIFS[12]、INMIFS[13]、WNMIFS[14]、CFR[15]、WCFR[16]等.
然而上述算法往往只局限于互信息这一度量标准,虽然互信息可以较好地度量变量之间的相关性,但其在实际应用中也有一定的局限性——互信息是基于信息熵理论的,该理论对于连续变量的信息熵,采取了微分熵的计算形式得出.但对于给定的数据集,常常无法知道连续变量的具体概率分布,进而无法计算其概率密度函数,也就不能在真正意义上计算得出连续变量的信息熵.这种情况下人们往往会采取将数据离散化的策略,将原始的连续变量转化为离散变量,又或者采取K-近邻等方式进行估算,这无疑在一定程度上引入了误差.
基于上述考虑,本文为了规避采取单一的互信息标准的局限性,试图在互信息的基础上引入另一种基于距离度量的算法RReliefF,以期能更好地对特征进行筛选.
RReliefF本是用于回归任务中的特征选择算法,它基于距离度量评估特征的重要性,RReliefF算法运行效率高,且对数据类型限制较少,因此可以作为互信息度量的一个有效补充.鉴于分类任务和回归任务的同一性,本文适应性地将RReliefF用于分类任务,度量特征与标签的相关性.
最大互信息系数(maximal information coefficient,MIC)是一种优秀的互信息变形,MIC利用了归一化互信息,使得MIC具有普适性、均衡性的优良特性,本文采用MIC度量特征与特征之间的冗余性、特征与标签的相关性.
RReliefF和MIC分别从距离度量和信息论的角度评估特征,将两者结合可以在某种程度上避免算法限于某一度量标准的单一性和盲目性,最大程度地挖掘特征的重要性.
通常情况下,人们往往会通过为不同事物赋权重的方式将事物结合起来,赋权的方式有主观赋权和客观赋权.主观赋权的随机性和主观性较大,普适性和自适应性较差.本文追求算法的稳定性和普适性,因此摈弃了主观赋权的思路.
熵权法是一种优秀的客观赋权方法,它基于信息熵理论,使得赋权过程更具客观性,赋权结果具有更好的可解释性.基于熵权法的上述特性,本文采用熵权法为RReliefF和MIC赋权,如此可以更充分地发挥两者各自的优势,使最终的度量标准更趋于完善.在此基础上,本文提出了基于熵权法的过滤式特征选择算法(filtering feature selection algorithm based on entropy weight method,FFSBEWM).
1 基于熵权法的过滤式特征选择算法(FFSBEWM)基于熵权法的过滤式特征选择算法框架如图 1所示.
图 1(Fig. 1)
 | 图 1 基于熵权法的过滤式特征选择算法框架Fig.1 The frame of FFSBEWM |
1.1 RReliefF度量数据集的各个特征RReliefF算法原是用于回归任务中的特征选择算法,该算法的伪代码如表 1所示[8].
表 1(Table 1)
| 表 1 RReliefF伪代码 Table 1 Pseudocode of RReliefF |
表 1中:C表示标签;A表示特征;N[C]表示对一个样本Ri,选取的近邻样本Ij与Ri的回归值不同的权重;N[A]表示对一个样本Ri,选取的近邻样本Ij与Ri的特征A取值不同的权重;N[C] & N[A]表示对一个样本Ri,选取的两个近邻样本Ij与Ri的特征A取值不同并且回归值不同的权重;m为总共选取的样本个数;f(Ri)为样本Ri的特征值;f(Ij)为样本Ij的特征值;d(i,j)=
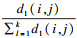
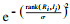
由表 1可知,对于特征A的权重,该算法选取g个最近邻样本,利用该样本与近邻样本间的距离来评估A的重要性.
RReliefF可以发现属性之间的强依赖关系,且具有良好的鲁棒性.
回归任务中样本的标签是连续值,而分类任务中样本的标签是离散值,且离散值在逻辑上是一种特殊的连续值,因此RReliefF同样可以应用于分类任务.设定g=5,假定数据集的特征个数为l,对特征{A1,A2,…,Al}应用RReliefF算法进行度量,得到各个特征的权重值,以向量r表示,r=[W[A1],W[A2],…,W[Al]]T.
1.2 MIC度量各个特征与标签的相关性MIC最初由Reshef等[17]提出,它基于互信息理论.在此本文对互信息理论予以简单介绍.
互信息用于评价两个变量的统计相关性.对离散型随机变量X和Y,其互信息定义如下:
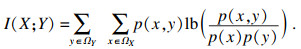 | (1) |
除了式(1)外,对离散变量X,Y之间的互信息也可以用信息熵来表示.其定义如下:
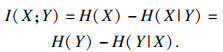 | (2) |
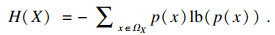 | (3) |
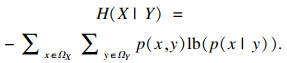 | (4) |
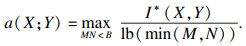 | (5) |
MIC本质上是一种归一化互信息,归一化互信息的值被限制在(0,1)之间,屏蔽了互信息绝对值的数量级差异,因此MIC具有更高的准确性和普适性.鉴于此,应用式(5)度量各个特征与标签的相关性.假定数据集的特征个数为l,对特征{A1,A2,…,Al}中的每个特征Ai,以及标签C,应用式(5)计算出该特征与标签的MIC值,最终得到向量q=[a(A1;C),a(A2;C),…,a(Al;C)]T.
1.3 应用熵权法进行客观赋权熵权法是一种优秀的客观赋权方法,在数学相关领域有很多应用.其依据的原理是指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低.应用熵权法为指标RReliefF和MIC赋权的过程如下[18].首先对r,q数据进行标准化:
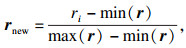 | (6) |
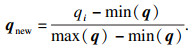 | (7) |
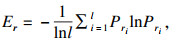 | (8) |
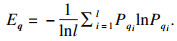 | (9) |
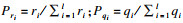
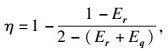 | (10) |
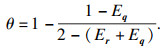 | (11) |
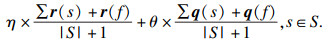 | (12) |
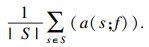 | (13) |
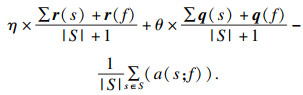 | (14) |
2 实验2.1 数据集与对比算法为了验证所提算法(FFSBEWM)的优劣性,本文将所提算法与相关算法进行了对比.实验用到了3个分类器:K-近邻(K-nearest neighbor,KNN)分类器、支持向量机(support vector machines,SVM)分类器以及鉴别分析(discriminant analysis,DA)分类器.本文在13个数据集上进行了实验,数据集的各项信息如表 2所示.
表 2(Table 2)
| 表 2 数据集 Table 2 Data sets | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
这些数据集来自UCI机器学习数据库以及Scikit-feature特征选择资源库.由表 2知,实验中采用的数据集涵盖了低维(特征维度小于200)、中维(特征维度介于200到1 000之间)、高维(特征维度大于1 000)数据集;涵盖了小样本(样本数小于1 000)、中样本(样本数大于1 000小于5 000)、大样本(样本数大于5 000)数据集;特征属性既包括实数型,又包括整数型.综上,本文选取的数据集具有代表性.
2.2 实验实施实验过程分为两个阶段:第一个阶段是利用各个算法对特征进行选择,得出各个算法所选择的特征子集;第二个阶段是对筛选出的特征子集的优越性进行评价,即将筛选出的数据放入分类器中进行分类,统计平均分类准确率和最高分类准确率.本文采用平均分类准确率和最高分类准确率作为评价指标,平均分类准确率的形式化描述如下:
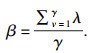 | (15) |
最高分类准确率即为当v取1到γ时,所有λ的最大值.最高分类准确率度量了算法所选择的最优特征子集的分类性能.其形式化描述如下:
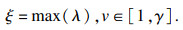 | (16) |
表 3(Table 3)
| 表 3 各个算法所选择的特征子集在KNN(K=5)分类器上的平均分类准确率 Table 3 Average classification accuracy of feature subsets selected by different algorithms using KNN(K=5) classifier | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 4(Table 4)
| 表 4 各个算法所选择的特征子集在SVM分类器上的平均分类准确率 Table 4 Average classification accuracy of feature subsets selected by different algorithms using SVM classifier |
表 5(Table 5)
| 表 5 各个算法所选择的特征子集在DA分类器上的平均分类准确率 Table 5 Average classification accuracy of feature subsets selected by different algorithms using DA classifier |
表 6(Table 6)
| 表 6 各个算法所选择的特征子集在KNN(K=5)分类器上的Nb, Ne, Nw统计表 Table 6 Nb, Ne, Nw statistics of feature subsets selected by different algorithms using KNN(K=5) classifier |
表 7(Table 7)
| 表 7 各个算法所选择的特征子集在SVM分类器上的Nb, Ne, Nw统计表 Table 7 Nb, Ne, Nw statistics of feature subsets selected by different algorithms using SVM classifier |
表 8(Table 8)
| 表 8 各个算法所选择的特征子集在DA分类器上的Nb, Ne, Nw统计表 Table 8 Nb, Ne, Nw statistics of feature subsets selected by different algorithms using DA classifier |
由表 3、表 4可看出,在KNN(K=5)和SVM分类器上,FFSBEWM均在9个数据集上取得最高准确率,并且这些数据集涵盖了低中高维数据集.除此之外,即便FFSBEWM在某些数据集上未取得最高准确率,其依旧排名第二或第三.由表 5可知,FFSBEWM所选择的特征子集在5个数据集上取得了最高的准确率,虽然相比SVM和KNN(K=5)分类器略有逊色,但纵向对比来看依旧说明FFSBEWM相比其他算法具有一定优势.由表 6~表 8可知,FFSBEWM胜于其他算法的数据集个数远大于不胜于其他算法的数据集个数,在KNN(K=5),SVM,DA分类器上平均胜出的数据集个数分别为11.6,9.1,8.2,胜出率分别为89.23%,70%,63%.综合上述论证,FFSBEWM的平均分类准确率显著优于其他算法.
各个算法在三个分类器上的最大最高分类准确率如表 9所示.由表 9可知,FFSBEWM在6个数据集上最大最高分类准确率排名第一,这6个数据集同样涵盖低中高维;FFSBEWM在4个数据集上排名第二或第三.FFSBEWM算法的最大最高分类准确率整体上同样优于其他算法.
表 9(Table 9)
| 表 9 各个算法所选择的特征子集在KNN(K=5),SVM和DA分类器上的最大最高分类准确率 Table 9 Maximal highest classification accuracy of feature subsets selected by different algorithms using KNN(K=5), SVM and DA classifier | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
为了分析分类准确率与特征子集大小的关系,选取了具有代表性的4个数据集,见图 2~图 4.
图 2(Fig. 2)
 | 图 2 各个算法所选择的特征子集的分类准确率随特征数变化图(KNN(K=5)分类器)Fig.2 The classification accuracy of feature subsets selected by different algorithms with different number of features(KNN(K=5)classifier) (a)—Libras Movement数据集;(b)—COIL20数据集;(c)—ORL数据集;(d)—Semeion数据集. |
图 3(Fig. 3)
 | 图 3 各个算法所选择的特征子集的分类准确率随特征数变化图(SVM分类器)Fig.3 The classification accuracy of feature subsets selected by different algorithms with different number of features(SVM classifier) (a)—Libras Movement数据集;(b)—COIL20数据集;(c)—ORL数据集;(d)—Semeion数据集. |
图 4(Fig. 4)
 | 图 4 各个算法所选择的特征子集的分类准确率随特征数变化图(DA分类器)Fig.4 The classification accuracy of feature subsets selected by different algorithms with different number of features(DA classifier) (a)—Libras Movement数据集;(b)—COIL20数据集;(c)—ORL数据集;(d)—Semeion数据集. |
由图 2~图 4可知,整体而言,随着所选特征个数的增多,特征子集的分类准确率相应提高.这是因为当选择的特征数较小时,特征子集所包含的信息也较少,因此分类准确率较低,反之亦然.值得一提的是这种正相关关系并非绝对.除此之外,尽管同一算法在同一分类器上的曲线走势并不完全一致,但FFSBEWM的曲线整体上均位于所有曲线的最上方,即无论所选特征子集的大小,FFSBEWM所选择的特征子集的分类性能均优于其他算法.这也进一步说明了即使不同分类器会对算法产生一些影响,但这些影响在本文讨论的范围内是非实质性的.
3 结语本文提出了一种基于熵权法的过滤式特征选择算法,在13个数据集上的实验结果显示本文算法选择的特征子集的平均分类准确率和最高分类准确率均优于其他算法.
但本文算法准确率还不够高,在个别数据集上略差于其他算法或者比其他算法的领先程度不够高;受数据集本身影响较大,导致在某些数据集上算法的稳定性较差;本文算法在不同的分类器上的表现也略有差异.后续将进一步对特征选择的过程框架予以改进,以期提高所选择的特征子集的分类准确率,同时完善特征选择的过滤式标准,加入对算法稳定性的度量,提高算法的稳定性.
参考文献
| [1] | Zhou H F, Zhang Y, Zhang Y J, et al. Feature selection based on conditional mutual information: minimum conditional relevance and minimum conditional redundancy[J]. Applied Intelligence, 2019, 49(3): 883-896. DOI:10.1007/s10489-018-1305-0 |
| [2] | Senawi A, Wei H L, Billings S A. A new maximum relevance-minimum multicollinearity(MRmMC) method for feature selection and ranking[J]. Pattern Recognition, 2017, 67: 47-61. DOI:10.1016/j.patcog.2017.01.026 |
| [3] | Wu B, Zhou M Z, Shen X P, et al. Simple profile rectifications go a long way[C]//European Conference on Object-Oriented Programming. Berlin: Springer, 2013: 654-678. |
| [4] | Qiu C Y. A novel multi-swarm particle swarm optimization for feature selection[J]. Genetic Programming and Evolvable Machines, 2019, 20(4): 503-529. DOI:10.1007/s10710-019-09358-0 |
| [5] | Djellali H, Ghoualmi N. Improved chaotic initialization of particle swarm applied to feature selection[C]//2019 International Conference on Networking and Advanced Systems(ICNAS). Matsue: IEEE, 2019: 1-5. |
| [6] | Baranauskas J A, Netto O P, Nozawa S R, et al. A tree-based algorithm for attribute selection[J]. Applied Intelligence, 2018, 48(4): 821-833. DOI:10.1007/s10489-017-1008-y |
| [7] | Apolloni J, Leguizamón G, Alba E. Two hybrid wrapper-filter feature selection algorithms applied to high-dimensional microarray experiments[J]. Applied Soft Computing, 2016, 38: 922-932. DOI:10.1016/j.asoc.2015.10.037 |
| [8] | Robnik-ikonja M, Kononenko I. An adaptation of Relief for attribute estimation in regression[EB/OL]. (1997-07-08)[2021-08-10]. http://www.clopinet.com/isabelle/Projects/reading/robnik97-icml.pdf. |
| [9] | Das A, Das S. Feature weighting and selection with a Pareto-optimal trade-off between relevancy and redundancy[J]. Pattern Recognition Letters, 2017, 88: 12-19. DOI:10.1016/j.patrec.2017.01.004 |
| [10] | Kwak N, Choi C H. Input feature selection for classification problems[J]. IEEE Transactions on Neural Networks, 2002, 13(1): 143-159. |
| [11] | Peng H C, Long F H, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238. |
| [12] | Estévez P A, Tesmer M, Perez C A, et al. Normalized mutual information feature selection[J]. IEEE Transactions on Neural Networks, 2009, 20(2): 189-201. |
| [13] | Li Y, Ma X F, Yang M X, et al. Improved feature selection based on normalized mutual information[C]//2015 14th International Symposium on Distributed Computing and Applications for Business Engineering and Science(DCABES). Guiyang: IEEE, 2015: 518-522. |
| [14] | Zhang P B, Wang X, Li X P, et al. EEG feature selection based on weighted-normalized mutual information for mental fatigue classification[C]//2016 IEEE International Instrumentation and Measurement Technology Conference Proceedings. Taipei: IEEE, 2016: 1-6. |
| [15] | Gao W F, Hu L, Zhang P, et al. Feature selection considering the composition of feature relevancy[J]. Pattern Recognition Letters, 2018, 112: 70-74. |
| [16] | Zhou H F, Wang X Q, Zhang Y. Feature selection based on weighted conditional mutual information[J/OL]. Applied Computing and Informatics, 2020[2021-08-10]. https://www.emerald.com/insight/content/doi/10.1016/j.aci.2019.12.003/full/pdf?title=feature-selection-based-on-weighted-conditional-mutual-information. |
| [17] | Reshef D N, Reshef Y A, Finucane H K, et al. Detecting novel associations in large data sets[J]. Science, 2011, 334(6062): 1518-1524. |
| [18] | Zhu Y X, Tian D Z, Yan F. Effectiveness of entropy weight method in decision-making[J/OL]. Mathematical Problems in Engineering, 2020[2021-08-10]. https://downloads.hindawi.com/journals/mpe/2020/3564835.pdf. |
