
 , 赵琪珲1, 邢铁军2, 赵大哲1
, 赵琪珲1, 邢铁军2, 赵大哲1 1. 东北大学 计算机科学与工程学院, 辽宁 沈阳 110169;
2. 东软集团股份有限公司, 辽宁 沈阳 110179
收稿日期:2021-01-26
基金项目:国家重点研发计划项目(2018YFC0830601); 中央高校基本科研业务费专项资金资助项目(N171802001); 沈阳市科技计划项目(21-104-1-12)。
作者简介:李大鹏(1982-),男,辽宁沈阳人,东北大学博士研究生;
赵大哲(1960-),女,辽宁沈阳人,东北大学教授,博士生导师。
摘要:为了解决刑期预测任务准确率较差的问题, 提出一种基于多通道分层注意力循环神经网络的司法案件刑期预测模型.该模型对传统的循环神经网络模型进行了改进, 引入了BERT词嵌入、多通道模式和分层注意力机制, 将刑期预测转化为文本分类问题.模型采用分层的双向循环神经网络对案件文本进行建模, 并通过分层注意力机制在词语级和句子级两个层面捕获不同词语和句子的重要性, 最终生成有效表征案件文本的多通道嵌入向量.实验结果表明: 对比现有的基于深度学习的刑期预测模型, 本文提出的模型具有更高的预测性能.
关键词:刑期预测分层注意力机制双向门控循环单元多通道文本分类
Prison Term Prediction of Judicial Cases Based on Hierarchical Attentive Recurrent Neural Network
LI Da-peng1,2
, ZHAO Qi-hui1, XING Tie-jun2, ZHAO Da-zhe1 1. School of Computer Science & Engineering, Northeastern University, Shenyang 110169, China;
2. Neusoft Corporation, Shenyang 110179, China
Corresponding author: LI Da-peng, E-mail: lidp@neusoft.com.
Abstract: In order to solve the problem of poor accuracy of prison term prediction, a prison term prediction model was proposed on the basis of multi-channel hierarchical attentive recurrent neural network. The model improves the traditional recurrent neural network, introduces BERT word embedding, multichannel mode and hierarchical attention mechanism, and transforms the prison term prediction task into text classification problem. The model uses hierarchical bidirectional recurrent neural network to model the legal case text, and captures the importance of different words and sentences at word level and sentence level through hierarchical attention mechanism. Finally, a multi-channel embedding vector that effectively represents the case text is generated. The experimental results show that the proposed model has higher prediction performance compared with the existing prison term prediction model based on deep learning.
Key words: prison term predictionhierarchical attention mechanismbidirectional gated recurrent unitmulti-channeltext classification
近年来, 随着人工智能等新一代信息技术的发展, 司法办案智能化成为司法领域信息技术的研究热点, 尤其是案件判决预测(legal judgment prediction, 简称LJP)日益受到关注[1].LJP使用自然语言处理等技术分析案件卷宗文本, 预测案件罪名、刑罚和适用法律等判决结果, 该技术是司法机关智能辅助办案系统的核心关键技术之一, 可以减少法官、检察官等办案人员的大量案件分析工作并辅助其作出决策, 提高工作效率, 减少犯错的风险.同时, 缺少法律知识的普通人也可通过该技术了解他们所关心案件的预期判决情况.
LJP包括罪名预测、刑期预测等多个子任务.近年来随着计算能力的提高及深度学习技术的发展, 卷积神经网络、循环神经网络等方法被广泛地应用在LJP领域.2017年, Luo等[2]使用支持向量机和循环神经网络预测案件的适用罪名和适用法律, 为LJP任务提出了新的解决方法.同年Vaswani等[3]提出了基于多头自注意力机制的Transformer模型, 提高了文本特征的提取能力.2018年, Google公布BERT(bidirectional encoder representation from transformers)在11项NLP(natural language processing)任务中刷新纪录[4], 引起了业界的广泛关注.陈剑等[5]在司法文书命名实体识别问题上引入BERT模型, 有效提升了实体识别效果.近两年, 许多****对深度学习在LJP领域的应用进行了深入的探索.Li等[6]在2019年设计了一个基于注意力循环神经网络模型, 同时完成案件的罪名预测、刑期预测和法条推荐任务.2020年, Xu等[7]提出了一种新型的基于Bi-GRU(bidirectional gated recurrent unit)神经网络的多任务LJP框架, 引入了被告人位置信息和不同刑期的注意力提升预测的准确率; 同年, Xu等[8]提出了一种基于图蒸馏算子的端到端注意力模型LADAN, 该模型通过利用相似罪名之间的差异很好地解决了LJP任务中罪名易混淆的问题.
2018年“中国法研杯”司法人工智能挑战赛(CAIL2018)提出了刑事案件的罪名预测、法条推荐和刑期预测三个LJP挑战任务, 罪名预测和法条推荐任务准确率均达到95%以上, 相比较而言, 刑期预测任务准确率较差.产生这种情况的原因主要有两个: 1)分析数据的不全面.CAIL2018的刑期预测任务是通过分析一段描述案件犯罪情节的文本来预测刑期, 而在实际的司法实践中, 法官或检察官在量刑时需要考虑的因素不仅仅包括被告人的犯罪情节, 还包括被告人的基本信息(例如健康状况、年龄、前科等)、被捕后的态度表现(坦白、自首、立功情节等)等其他因素, 仅仅依靠犯罪情节来预测量刑结果是不准确的.2)预测模型的局限性.首先, 刑期预测是归结为分类问题还是回归问题还没有定论, 相比较而言, 用回归方式预测刑期效果较差, 准确率不高; 其次, 模型如何能够提取案件文本深层次的语义特征并生成有效表征案件文本的向量表示也是影响刑期预测准确性的关键问题.
为了解决已有研究中存在的上述问题, 本文提出一种基于多通道分层注意力循环神经网络(multi-channel hierarchical attentive recurrent neural network, MHARNN)的司法案件刑期预测模型.相比传统刑期预测模型, 本文在以下三个方面进行了改进: 1)BERT预训练模型, 使用BERT预训练中文词向量作为MHARNN模型的输入, 其强大的词向量表征能力能够有效提升分类器性能.2)多通道模式, MHARNN模型引入多通道模式, 将被告人基本信息、犯罪情节和被告人态度表现三类文本信息分别输入到编码器中各自生成向量表示, 最后三个表示向量拼接后再输入到分类器中.3)分层注意力机制, MHARNN模型引入基于分层注意力机制的Bi-GRU神经网络模型来进行输入文本隐含特征的提取, 其中分层注意力机制可以从词语和句子两个层面捕获不同词语和不同句子对于刑期预测任务的重要性.实验结果表明, 相比其他刑期预测模型, 本文模型预测准确率等性能得到了显著提高.
1 模型描述为了完成案件的刑期预测, 本文提出了MHARNN刑期预测模型, 如图 1所示, 模型可分为三个层次.
图 1(Fig. 1)
 | 图 1 刑期预测模型Fig.1 Prison term prediction model |
1) 输入层.输入层引入多通道模式和BERT中文预训练模型, 将被告人基本信息、犯罪情节和态度表现三类文本转化为BERT词向量序列输入到模型编码层中.
2) 编码层.本文选择使用Bi-GRU神经网络作为编码器用于生成三类文本的向量表示.编码器是一个双层结构, 首先将词向量序列作为输入并结合词语级注意力上下文向量cpw, cfw和caw生成句子向量, 再将生成的多个句子向量序列作为输入并结合句子级注意力上下文向量cps, cfs和cas生成三类文本的向量, 包括基本信息向量dp、犯罪情节向量df和态度表现向量da.
3) 输出层.本文将dp, df和da拼接在一起后输入到Softmax分类器中.分类器会输出不同刑期区间的概率分布Pt, 从而得出该案件的刑期预测结果.
相比于传统的预测模型将案件文书整体输入到编码器中, MHARNN模型多通道模式的优势可归纳为如下两点: 1) 多通道模式下各类输入信息拥有单独的编码器, 编码器能够更好地学习深层特征, 生成的向量表示也能够更准确地表征输入文本数据, 从而提高模型的预测准确率; 2) 多通道模式下, 模型的输入也更加灵活, 比如被告人的态度表现, 除了可以将文本向量作为输入外, 也可以使用One-hot编码对被告人的坦白、自首和立功等情节进行编码, 生成一个代表被告人态度表现的向量, 之后可以将其输入到一个多层感知机中生成与其他两个通道相同维度的特征向量.
1.1 文本编码器案件文本可以视作具有两层结构的序列集合, 即一个案件文本是多个句子组成的序列集合, 而其中每个句子则是由多个词语组成的序列集合.如图 2所示, 本文基于Bi-GRU神经网络构建一个具有两层结构的编码器来学习案件文本的向量表示, 两层结构分为词语级编码器和句子级编码器.
图 2(Fig. 2)
 | 图 2 双层文本编码器Fig.2 Two-layer text encoder |
假设一个文本由n个句子组成, 其中第i个句子si(i∈[1, n])包含m个词语, 用wij(j∈[1, m])表示该句子中的第j个词语,则文本表示向量d可以表示为
 | (1) |
 | (2) |
本文选择Bi-GRU神经网络构建文本编码器.GRU是循环神经网络的一种变体, GRU有两个门, 分别为更新门和重置门.更新门控制前一时刻的状态信息被输入到当前状态中的程度, 更新门的值越大说明前一时刻的状态信息输入越多.重置门控制忽略前一时刻的状态信息的程度, 重置门的值越小说明忽略的信息越多.在任意时刻t, GRU的隐藏状态计算如式(3)~式(6)所示.
 | (3) |
 | (4) |
 | (5) |
 | (6) |
 | (7) |
 | (8) |
1.2 双层注意力机制对于一个案件文本来说, 每个句子包含的信息不同, 对于量刑预测结果的影响是不同的.同样, 一个句子中的词语既可能是与案情紧密相关的词语, 也可能是无关的词语, 它们对于量刑预测结果的重要性也是不同的.因此, 本文在模型中引入分层注意力机制, 给不同的句子或词语赋予不同的权重, 从而摒弃一些噪音数据, 以此来提高分类器的性能.注意力机制本质上是为了对数据中更有价值的部分分配较多的计算资源.
如图 3所示, 本文引入全局的注意力上下文向量cw和cs[9], 分别参与词语级和句子级的注意力计算, 生成句子表示向量s和文本表示向量d.使用随机值初始化cw和cs, 并在模型训练过程中迭代优化.给定一组GRU编码器输出[hi1, hi2, …, hiM], 每个词的注意力值为[αi1, αi2, …, αiM], 其中
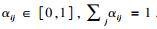
图 3(Fig. 3)
 | 图 3 双层注意力机制Fig.3 Two-layer attention mechanism |
 | (9) |
 | (10) |
 | (11) |
 | (12) |
 | (13) |
 | (14) |
1.3 Softmax分类器Softmax分类器的输入是来自三个通道的文本向量拼接后形成的向量d:
 | (15) |
 | (16) |
本文使用交叉熵作为模型的损失函数, 记为Loss F:
 | (17) |
2 实验与结果分析2.1 实验数据集目前, 国内公开的司法案件数据集较少, 比较知名的是2018年“中国法研杯”提供的CAIL2018数据集[10].CAIL2018数据集涵盖了202个罪名共260余万份真实案件, 可用于LJP相关模型的训练和测试.但通过分析发现, CAIL2018中的案件数据仅包含被告人姓名(已脱敏), 并不包含被告人详细信息, 即无法获取被告人的年龄、身体状况及前科等与量刑结果息息相关的信息, 同时, 部分案件也没有被告人的态度表现信息.基于此种情况, 本文通过中国裁判文书网收集了海量案件判决书, 得益于其比较规范的格式; 通过程序将判决书中的被告人基本信息、犯罪情节、态度表现、罪名和判决结果等内容自动提取并结构化为实验数据集.该数据集中的案件数据包含了模型所需的完整内容, 可以有效验证本文提出的MHARNN模型的性能.实验数据集涵盖了58个罪名共20万个案件, 所有案件均是单被告人且判罚结果均是有期或无期徒刑(不考虑缓刑).数据集不同罪名案件数量的分布是不均衡的, 数量最多的前10个罪名的案件占数据集案件总数的72.1%.本文将数据集随机分为三部分作为训练集、验证集、测试集, 三者的文书数量比例约为8∶1∶1.
本文将刑期归一化处理为以月份为单位的时间常数, 然后划分成不同的区间(单罪名有期徒刑最少为6个月, 最多为15年, 数罪并罚不超过25年), 例如6~8个月、8~12个月, 每个区间为一个类别, 其中无期徒刑单独归类.具体划分规则见表 1.
表 1(Table 1)
| 表 1 刑期区间划分 Table 1 Division of prison term |
2.2 数据预处理过程针对从网上下载的案件判决书, 数据预处理主要包括三个步骤.
1) 结构化: 首先通过关键字对判决书进行段落级别的划分, 将其分为包含基本信息、犯罪情节、态度表现和判决结果等段落, 然后通过关键字和正则表达式从判决结果中提取罪名、刑期等信息, 最终将一份判决书结构化为实验所需的数据样本.
2) 数据清洗: 针对包含基本信息、犯罪情节和态度表现的文本, 去掉其中的冗余词、停用词以及语气助词等没有意义的内容.
3) 向量化: 将清洗后的三部分文本进行分词, 然后使用中文预训练模型ALBERT_TINY将文本中的词转为词向量, 词向量的维度设置为400.
2.3 实验设计为了验证本文提出的MHARNN模型在刑期预测性能方面的优越性, 在相同数据集上进行一系列对比实验, 包括:
1) 从分析模型性能优越性的角度, 选择了CAIL2018比赛中使用的TextCNN[11], RCNN[12], DPCNN[13]和HAN[14]四种刑期预测模型与本文提出的MHARNN模型进行比较.考虑到这些模型不是多通道模型, 在实验过程中, 将三类数据按照基本信息、犯罪情节和态度表现的顺序整合在一起输入到模型中.
2) 从分析BERT词向量、多通道数据和双层注意力机制对性能影响的角度, 设计了多组消融实验进行分析比较.
实验选择TensorFlow工具训练以上提到的所有神经网络模型, 超参数设定隐藏层数为3, 隐藏层节点数为200, 被告人基本信息、犯罪情节和态度表现的Embedding长度分别设置为50, 100和50.本文使用Adam算法来优化训练过程, 学习率设置为0.001, Dropout设置为0.5;使用宏精度(macro-precision, MP)和宏召回率(macro-recall, MR)和宏F1分数三个指标来评价模型性能.
2.4 实验结果分析在相同数据集上, 不同文本分类模型在刑期预测任务上的实验结果如表 2所示.
表 2(Table 2)
| 表 2 不同模型结果对比 Table 2 Comparison of the results of different models |
从结果可以看到, MHARNN模型取得了所有对比模型中最好的效果, 此外, 引入注意力机制的循环神经网络模型HAN也取得了较好的性能.相较于HAN模型, MHARNN模型的F1分数提升了14%.从5类模型的实验结果可见, TextCNN和DPCNN的性能较差, 即卷积神经网络在自然语言处理任务上的效果没有循环神经网络的效果好, 毕竟案件文本作为序列数据, 使用循环神经网络模型处理更加适合.参考CAIL2018的刑期预测任务的准确率, MHARNN模型在MP和MR性能上均得到显著的提升.但是, 相比于罪名预测和法条推荐任务, 刑期预测任务的F1分数仍然相对较低, 除了前文分析的原因外, 数罪并罚导致刑期变化以及案件情节的复杂性仍是困扰刑期预测任务的难题.
为了深入分析多通道数据和双层注意力机制对刑期预测任务性能的影响, 设计消融实验进行分析比较.模型名字中w/o是without的缩写, w/o BERT代表用word2vec词向量替代BERT, w/o attention模型即无双层注意力机制; w/o hierarchical模型即不使用包括词语级和句子级的双层Bi-GRU编码器, 输入文本后直接通过Bi-GRU编码器获得文本表示向量; w/o persona模型是指输入文本只有犯罪情节和态度表现内容; w/o attitude模型是指输入文本只有犯罪情节和基本信息内容.实验结果如表 3所示.
表 3(Table 3)
| 表 3 消融实验结果 Table 3 Results of ablation experiment |
从实验结果可知, 本文模型中使用的BERT词向量、注意力机制以及分层编码器均有效提高了刑期预测的性能, 没有它们, 分类性能都有一定程度的下降.BERT预训练模型通过双向训练Transformer编码器从海量的无标注语料中学习词语信息特征、语言学特征和一定程度的语义信息特征, 具有强大的词向量表征能力.使用BERT Word Embedding作为输入, 使模型F1分数提升6%.注意力机制给不同的句子或词语赋予不同的权重, 起到了摒弃噪音数据的效果.而从数据类别来看, 态度表现内容对刑期预测任务的影响更大, 因为被告人的态度表现与量刑的从轻和从重判罚息息相关.基本信息内容中对量刑有影响的是年龄(如未成年人)、身体状况(如聋哑人)和前科(如累犯认定)等信息, 可见大部分案件的基本信息内容对量刑结果的影响较小, 但对少量案件来说, 缺少基本信息内容会造成较大的预测误差, 可见三类数据一起输入到模型中才会提高预测准确率.
3 结语针对案件判决预测中的刑期预测任务, 本文提出一种基于多通道分层注意力循环神经网络的司法案件刑期预测模型.该模型引入了BERT预训练模型、多通道模式和分层注意力机制, 能够有效提升刑期预测的准确率.对比实验结果表明, 多通道分层注意力循环神经网络模型的学习能力更强, 具备学习深层次语义特征的能力, 从而有效提升刑期预测的性能.下一步工作主要包含两个方面: 一方面需要进一步提升该模型在刑期预测方面的性能; 另一方面, 针对数罪并罚案件在模型架构上进一步改进.
参考文献
| [1] | 黄俏娟, 罗旭东. 人工智能与法律结合的现状及发展趋势[J]. 计算机科学, 2018, 45(12): 1-11. (Huang Qiao-juan, Luo Xu-dong. State-of-the-art and development trend of artificial intelligence combined with law[J]. Computer Science, 2018, 45(12): 1-11.) |
| [2] | Luo B F, Feng Y S, Xu J B, et al. Learning to predict charges for criminal cases with legal basis[C] //Proceedings of the Conference on Empirical Methods in Natural Language Processing. Copenhagen: ACL, 2017: 2727-2736. |
| [3] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C] //Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: MIT Press, 2017: 6000-6010. |
| [4] | Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] //Proceedings of the 57th Annual Conference of the Association for Computational Linguistics. Haikou: ACL, 2019: 4171-4186. |
| [5] | 陈剑, 何涛, 闻英友, 等. 基于BERT模型的司法文书实体识别方法[J]. 东北大学学报(自然科学版), 2020, 41(10): 1382-1388. (Chen Jian, He Tao, Wen Ying-you, et al. Entity recognition method for judicial documents based on BERT model[J]. Journal of Northeastern University(Natural Science), 2020, 41(10): 1382-1388.) |
| [6] | Li S, Zhang H L, Ye L, et al. MANN: a multichannel attentive neural network for legal judgment prediction[J]. IEEE Access, 2019, 7(1): 151144-151154. |
| [7] | Xu Z P, Li X, Li Y L, et al. Multi-task legal judgement prediction combining a subtask of the seriousness of charges[C]// Proceedings of the 19th China National Conference on Computational Linguistics. Haikou: Springer, 2020: 1132-1142. |
| [8] | Xu N, Wang P H, Chen L, et al. Distinguish confusing law articles for legal judgment prediction [C]//Proceedings of the 58th Annual Conference of the Association for Computational Linguistics. Seattle: ACL, 2020: 1022-1031. |
| [9] | Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[C]// Proceedings of the International Conference on Learning Representations. San Diego: ICLR, 2015: 1-15. |
| [10] | Xiao C J, Zhong H X, Guo Z P, et al. Overview of CAIL2018: legal judgment prediction competition [EB/OL]. (2018-10-13)[2020-05-12]. https://arxiv.org/pdf/1810.05851.pdf. |
| [11] | Kim Y. Convolutional neural networks for sentence classification[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014: 1746-1751. |
| [12] | Lai S W, Xu L H, Liu K, et al. Recurrent convolutional neural networks for text classification [C]//Proceedings of the 29th National Conference on Artificial Intelligence. Austin: AAAI, 2015: 2267-2273. |
| [13] | Rie J, Zhang T. Deep pyramid convolutional neural networks for text categorization [C]//Proceedings of the 55th Annual Conference of the Association for Computational Linguistics. Vancouver: ACL, 2017: 562-570. |
| [14] | Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification [C] // Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego: ACL, 2016: 1480-1489. |
