
 , 刘畅1, 徐赛2
, 刘畅1, 徐赛2 1. 东北大学计算机科学与工程学院, 辽宁沈阳 110169;
2. 东软集团股份有限公司, 辽宁沈阳 110179
收稿日期:2021-05-19
基金项目:国家自然科学基金资助项目(61671141); 中央高校基本科研业务费专项资金资助项目(N2116015,N2116020)。
作者简介:耿蓉(1979-), 女, 辽宁沈阳人, 东北大学副教授。
摘要:由于天地一体化网络的计算资源受限、能力迥异等问题, 会导致其处理复杂任务的能力减弱, 使得重要的任务处理失败.因此, 本文构建了一种将任务卸载到本地-骨干-边缘接入节点的三层计算卸载开销模型, 并通过基于DQN的最优卸载算法进行最优卸载策略的制定.首先, 依据网络中存在的天基骨干节点、边缘接入节点以及地基骨干节点三种类型计算节点(卸载站点)自身的特点, 给出了不同卸载站点的时延、能耗的开销表达式以及对应的约束条件. 然后, 提出了基于DQN算法来完成低时延、低能耗的卸载过程.仿真结果表明, DQN算法能够提高任务执行的速度, 降低终端设备的能耗, 有效改善网络中计算节点资源迥异的现状.
关键词:天地一体化网络计算卸载卸载开销模型时延能耗DQN
Computational Offloading Algorithm Oriented to the Space-Earth Integration Network
GENG Rong1, WANG Hong-yan1
, LIU Chang1, XU Sai2 1. School of Computer Science & Engineering, Northeastern University, Shenyang 110169, China;
2. Neusoft Corporation, Shenyang 110179, China
Corresponding author: WANG Hong-yan, E-mail: 1289656048@qq.com.
Abstract: Due to the limited computing resources and very different capabilities of the space-earth integration network, the processing power of complex tasks is not strong and important tasks fail to be processed. Therefore, a three-layer computational offloading overhead model that offloads tasks to local-backbone-edge access nodes was established and the optimal offloading strategy was formulated through the optimal offloading algorithm based on DQN(deep Q-learning network). Firstly, based on the characteristics of the three types of computing nodes(offloading sites)in the network, including the space-based backbone nodes, edge access nodes and ground-based backbone nodes, the expressions of the delay, energy consumption and the corresponding expressions of different offload sites were given. Then, based on this, the DQN algorithm was proposed to complete the low-delay, low-energy offloading process. Finally, simulation results show that the DQN algorithm can improve the speed of task execution, reduce the energy consumption of terminal equipment, and effectively improve the current situation of computing node resources in the network.
Key words: space-earth integration networkcomputational offloadingoffloading overhead modeldelayenergy consumptionDQN(deep Q-learning network)
天地一体化网络[1-2]由天基骨干网、天基边缘接入网以及地基节点网(地基骨干网)[3-4]三部分组成.由于目前卫星数量不足、卫星类型单一、在轨升级困难带来的计算资源受限问题使得天基信息系统的综合效能受到阻碍, 并且在空、天、地维度上也不能很好地配合.因此, 本文将计算卸载[5]技术结合到天地一体化网络中, 以缓解天地一体化网络存在的问题.针对由于卫星数量不足、类型单一、再组升级困难带来的计算资源受限和“天弱地强”等问题, 给出了相应的最优卸载算法, 将任务卸载到合适的卸载站点进行计算, 降低网络时延和能耗, 以便高效地完成任务.本文旨在利用计算卸载技术均衡天地一体化网络的负载, 在低时延、低能耗的情况下完成任务, 为未来新型网络处理复杂的密集计算型任务提供理论基础.
目前, 国内外****对一般移动云计算系统中的计算卸载问题进行了广泛的研究[6-8].文献[9-10]给出了计算卸载的经典模型.然而在面对终端计算能力不足的问题时, 文献[11]提出了基于Cloud-RAN的移动云计算系统中近乎最优的能效方案;文献[12]表征了计算和通信负载之间的基本权衡;文献[5]提出了通信和计算功耗之间的最佳权衡;文献[13]提出了一种基于MDP的卸载算法, 该算法可以帮助用户决定是否将多阶段移动应用程序中相同应用阶段的计算任务卸载给附近的所有cloudlet(移动设备或者是计算机, 提供附近移动设备使用的计算能力, 用户可直接访问附近移动设备的资源).此外, 文献[14]给出用户的一组任务, 此任务可以在用户和cloudlet上并行执行, 用户的目标是向每个cloudlet分配最优数量的任务, 使任务执行奖励最大化, 而处理成本最小化.可见, 目前的研究都是基于传统的本地策略来减轻移动系统中有限资源的限制, 而面对天地一体化这种复杂的网络以上解决方法是远远不够的.
因此, 为了解决天地一体化网络中的终端设备在存储、计算和能耗方面的资源需求与运行越来越复杂的移动应用程序之间的矛盾日益突出的问题, 本文突破传统的本地执行策略, 为在高轨骨干节点、地基骨干节点和边缘接入节点服务器上执行任务卸载提供了新的理论和方法, 提出天地一体化网络的本地-骨干-边缘接入节点的三层计算卸载模型, 此模型应用每一层的全部卸载站点数, 使卸载的性能和可伸缩性得到提高, 解决了计算资源受限的难题; 同时通过此模型所给出的各项指标以及约束条件, 本文提出基于DQN算法来制定出最优的卸载策略, 使任务在低时延、低能耗的情况下高效完成, 更加体现了此模型的应用价值.
1 天地一体化网络中的计算卸载模型设计1.1 卸载模型的建立1) 卸载站点模型建立.卸载站点(offloadee)模型的建立需要考虑天地一体化网络的结构与特点, 建立与之相对应的模型.卸载站点用一个五元组Oon

2) 任务模型建立. 每个任务都可以用一个四元组Vin

3) 通信模型建立.当第n个终端设备的第i个计算任务需要执行时, 当前终端就会发送任务卸载请求, 其他的计算节点就会给出响应, 终端根据响应来决定是直接卸载还是划分后卸载, 以及是本地执行还是卸载到其他站点上.在这里, din=0表示终端设备n的任务i在本地执行, 不进行卸载.din>0表示任务被卸载到其他卸载站点来执行.另外, 在卸载过程中, 用式(1)所示的信道速率来选择合适的信道进行数据传输,
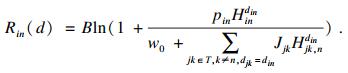 | (1) |
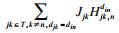
同时, 本文也将采用马尔可夫信道模型来估计任务卸载过程中的信道状况.下面给出有限状态马尔可夫信道模型.
本文使用Gilbert-Elliott通道建立通信链路, 该信道模型是具有两种状态的马尔可夫链: 良好(用0表示)或坏(用1表示).如果信道处于良好状态, 则以高速率(v0)传输数据, 如果信道处于坏的状态, 则以低速率(v1)传输数据.如果第n个时间单位期间信道状态φn良好, 则记φn=0, 否则φn=1.因此, 通道状态φ的状态转移矩阵P由式(2)给出:
 | (2) |
稳态分布表示为μ=(μ0, μ1), 其中μ0, μ1分别表示信道处于良好或坏状态的稳态概率.两种状态的稳态概率计算公式为μ0=p10/(p10+p01), μ1=p01/(p10+p01). 因此, 如果假设终端设备的传输功率是静态的, 则预期的稳态传输速率vμ可表示为vμ=μ0v0+μ1v1.
1.2 任务卸载开销计算根据上面所给出的任务和卸载站点的简单模型, 可以得到任务在不同卸载情况下的卸载开销模型.下面给出任务卸载到天地一体化网络中不同站点的卸载开销模型, 分别是本地执行建模、骨干节点执行建模以及边缘接入节点执行建模.
1) 本地执行.本地执行是任务i在终端设备n直接执行, 不进行任务卸载.用finl代表本地执行时任务i所在的终端设备n的计算能力(单位是CPU的每秒周期数), 并设定这些终端设备具有不同的计算能力, 那么任务本地执行的时耗为
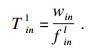 | (3) |
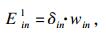 | (4) |
一个任务被执行前, 要求其所有直接先驱任务必须已经完成.下面给出任务就位时间的概念.
定义1 ??就位时间是当前执行任务的所有先驱任务完成的最早时间, 对于本地执行的就位时间表示为
 | (5) |
综上, 终端设备n的任务i在本地执行时的完成时间为本地执行时间与本地计算时的就位时间之和, 即
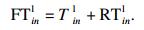 | (6) |
定义2 ??能耗代价EEC(energy efficiency commitment)是任务执行的能源消耗与所需计算完成时间的权重之和.下面给出任务在本地执行时的EEC表达式:
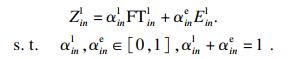 | (7) |
2) 骨干节点执行.骨干节点执行是指将终端设备n的任务i卸载到骨干节点b来执行, 然后再将结果返回至终端设备n.本质上是利用通信开销来换取时间开销和能耗开销.在本文中用finb来代表骨干节点的计算能力(单位是CPU的每秒周期数), 那么任务在骨干节点执行的时间开销T inb为
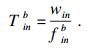 | (8) |
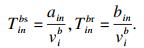 | (9) |
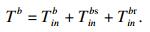 | (10) |
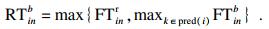 | (11) |
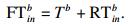 | (12) |
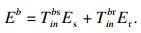 | (13) |
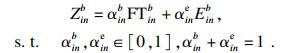 | (14) |
3) 边缘接入节点执行.边缘接入节点执行是指将任务卸载到边缘接入节点来执行, 同样是用通信开销来换取时间开销和能耗开销.用f h来代表边缘接入节点h的计算能力(单位是CPU的每秒周期数), 那么任务在边缘接入节点执行的时间开销T inh为
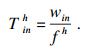 | (15) |
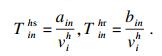 | (16) |
 | (17) |
如果计算延迟很大, 则总延迟主要取决于计算延迟.此时延迟由发送时间、卸载时间以及接收时间三部分组成, 其表达式为
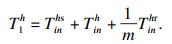 | (18) |
如果计算延迟很短, 则总延迟主要取决于通信延迟, 即发送时间和接收时间, 其延迟表达式为
 | (19) |
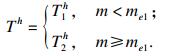 | (20) |
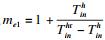
用Ec, Es, Er分别代表任务本身执行计算卸载(computation)时的能耗开销、数据发送到卸载站点时的能耗开销以及卸载终端进行数据接收时的能耗开销, 则边缘接入节点总的能量开销表示为Eh:
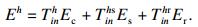 | (21) |
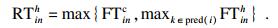 | (22) |
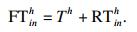 | (23) |
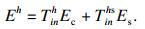 | (24) |
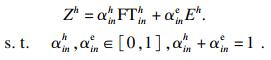 | (25) |
2.1 传统的Q学习(Q-learning)算法Q学习算法是利用动作值函数寻找最优的策略, 寻找到对于每个状态来说的最佳动作, 完成任务最优卸载.具体的一些过程如下所述.
Q学习算法中智能体通过即时动作值和累积奖励值进行状态的转移决策, 针对计算卸载的马尔可夫模型, 当智能终端任务进行卸载时, 对周围的信道状态进行估计, 对计算能力进行监测, 以(Oi, wtotal)为任务的处理状态, 其中Oi代表当前处理任务的卸载站点(offloadee)的编号, wtotal表示截止到当前状态, 处理的任务数据总量; 以(Oi, wi)为任务下一步要进行的动作, 其中wi表示下一步动作时要卸载的数据量大小, 智能终端卸载任务每一步的即时回报(奖励)函数用总时延和总能耗线性表达式的倒数来计算.在Q学习算法中, 每个状态-动作组都需要计算并将其对应的Q值存储在一个表中, 然后通过优化可迭代计算得到Q(s, a)的值来逼近最优值函数, 进而得到最优卸载策略.
2.2 基于DQN的计算卸载算法设计通过上面对于Q学习算法的描述可以看出, Q学习虽然可以通过获得最大的奖励来解决问题, 但并不理想.并且在实际问题中, 天地一体化网络卸载环境复杂多变, 可能的状态会超过1万.在Q表中存储所有的Q值, 会导致Q(s, a)非常大, 这样就很难得到足够的样本来遍历每个状态, 从而导致算法的失败.因此, 提出使用深度神经网络来估计Q(s, a), 而不是计算每个状态动作对的Q值, 这就是DQN的基本思想.
DQN算法就是基于传统Q学习算法基础上利用深度卷积神经网络CNN来加快Q学习算法中卸载过程的收敛速度.在本研究中设置初始的回报函数为0, 回报函数用总时延和总能耗线性表达式的倒数来计算, 因此将1.2小节开销模型进行整合, 首先给出t时刻第i个任务的时延Tti和能耗Eti的表达式:
 | (26) |
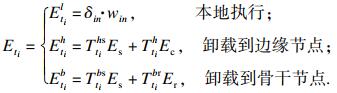 | (27) |
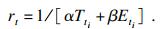 | (28) |
设在t时刻, 智能终端选取动作at环境从状态st转移到st+1所给出的奖例为rt,则rt=r(st, at, st+1); st和rt=是决定st+1与rt的概率分布的因素, 且Qt为t时刻开始时状态动作对的动作估计值.在整个过程中动作的更新迭代规则如式(29)所示:
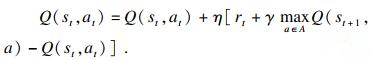 | (29) |
在DQN算法中利用深度CNN压缩状态空间并加快Q学习算法中卸载过程的收敛速度, 神经网络将每一个动作的Q(s, a)值转换成Q网络, 然后利用反向传播和梯度下降方法使得损失函数最小化.损失函数如式(30)所示:
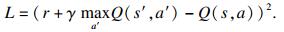 | (30) |
对于每个卸载策略, 深度CNN都是Q值的非线性近似值, 这样就加快了Q学习方案的收敛速度.下面给出DQN原理示意图, 见图 1.
图 1(Fig. 1)
 | 图 1 DQN原理示意图Fig.1 The schematic diagram of DQN |
通过以上分析, 基于DQN的计算卸载策略算法如表 1所示.
表 1(Table 1)
| 表 1 基于DQN的计算卸载算法 Table 1 Computation offloading algorithm based on DQN |
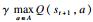 -Q(st, at)]
-Q(st, at)]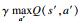 -Q(s, a))2最小值
-Q(s, a))2最小值其中第9步实现了将经验值存储到记忆库中, 然后对Q网络进行训练.DQN中存在1个记忆库, 它能够学习现在正在经历着的, 也可以学习从前经历过的, 甚至是学习别人的经历.所以每一次基于DQN算法变更的期间, 都能够随机抽取一些以往的经历来进行学习.正是因为采用了随机抽取这种做法, 才能够达到打乱经历之间相关性的目的, 使得神经网络能够更有效率地进行更新.
3 算法仿真与性能分析本文的卸载仿真是利用Python+NS网络仿真软件进行的.假设一个场景: 在一定范围内模拟天地一体化网络的结构特点, 考虑到天地一体化网络结构特征, 拟选取2个天基骨干节点、2个地基骨干节点、6个边缘接入节点的模式进行仿真.即1个卸载终端(offloader), 10个计算卸载站点(offloadee), 其中4个用来模仿天基或者地基骨干节点的计算卸载站点(B_offloadee), 剩下的均为边缘接入节点的计算卸载站点(E_offloadee), 它们在不同纬度上呈现随机分布.所有的卸载站点(offloadees)之间通过无线网络连接.offloadee为offloader提供任务计算卸载服务.由上述分析, 采用时延和能耗为指标, 选择经典计算卸载算法[15](基于Lyapunov优化的卸载算法: 此算法在计算卸载技术中应用最为广泛)和基于DQN的计算卸载算法与Q学习算法进行仿真并对比分析评价算法性能.
在进行算法性能分析之前, 利用Python散点图模拟天地一体化网络中计算节点结构的分布和散点分布图, 如图 2所示.其中红色散点代表骨干节点, 最上边的6个红色散点代表天地一体化网络中最上层, 处于最高位置, 拥有强大计算能力的6颗高轨卫星, 具有在固定轨道上移动的特点.最下面的5个红色散点代表的是地基骨干节点, 其分布在地面, 位置固定, 计算能力在理论上最强.处于中间位置的蓝色散点是边缘接入网络的计算节点, 其数量不固定, 具有移动性, 以分布式方式呈现, 计算能力要远小于其他两种计算节点, 正是由于其分布式特点, 使其在与卸载终端距离方面更具优势.
图 2(Fig. 2)
 | 图 2 计算节点分布图Fig.2 Distribution map of calculation nodes |
基于以上模拟天地一体化网络的计算节点进行仿真, 来分析Lyapunov算法(经典计算卸载算法)、Q学习算法、DQN算法在时延、能耗指标下的性能对比.
卸载过程中的时延对比结果如图 3所示, 基于Lyapunov优化的卸载算法最大, 通过DQN算法的计算卸载策略在时延的花费上要低于其他算法.
图 3(Fig. 3)
 | 图 3 时延对比分析图Fig.3 Delay analysis chart |
能耗对比结果如图 4所示.对于某些能耗不充足的卸载终端offloader来说, 其对降低能耗的需求要强于对降低时延的需求, 即用时延来换取能耗, 因此在天地一体化网络任务计算卸载中能耗也显得至关重要.
图 4(Fig. 4)
 | 图 4 能耗对比分析图Fig.4 Comparison analysis of energy consumption |
由图 3和图 4可知, 采取不同卸载算法, 时延开销、能耗开销的整体趋势是一样的, 即采取DQN算法可以同时在时延和能耗开销上进行优化.
在1.2节对卸载开销进行建模的过程中, 就提到权重的问题, 而上述对于时延和能耗的分析是没有设置时延和能耗各自所占的权重进行分析的.下文给出不同权重设置时, 采用不同卸载算法情况下时延和能耗的总开销对比.
由图 5和图 6可知, 当时延和能耗权重采用不同的占比时, DQN算法的卸载策略总开销都是更小的, 再一次证明本文算法的有效性.
图 5(Fig. 5)
 | 图 5 时延和能耗权重各占0Fig.5 Comparison of total cost when each weight of time delay and energy consumption are 0.5 |
图 6(Fig. 6)
 | 图 6 时延权重为0.9能耗权重为0.1时总开销对比Fig.6 Comparison of total cost when the delay weight is 0.9 and energy consumption weight is 0.1 |
4 结语针对天地一体化网络的结构特点, 结合分析计算卸载技术的特点和应用场景, 本文提出将计算卸载技术应用到网络中, 在理论上可以对任务处理的高效性起到极大的推动作用.同时为了解决计算资源受限问题, 建立了与天地一体化网络体系结构一一对应的卸载模型, 不同卸载站点在时延上的开销比例各不相同.在建立时延和能耗的总开销模型中, 提出了设置权重的思想, 可以让卸载端有所取舍.最后对本文提出的DQN计算卸载算法进行仿真, 从时延开销、能耗开销等方面验证算法的有效性.仿真结果表明, 采取DQN计算卸载算法可以同时在时延和能耗开销上进行优化, 高效地完成卸载过程.
参考文献
| [1] | 杨昕, 孙智立. 无线自组网和卫星网络融合的路由方法[J]. 移动通信, 2019, 43(5): 14-20. (Yang Xin, Sun Zhi-li. Routing method for fusion of wireless ad hoc network and satellite network[J]. Mobile Communication, 2019, 43(5): 14-20. DOI:10.3969/j.issn.1006-1010.2019.05.003) |
| [2] | Chen W, Zhang X, Deng P, et al. RSN: a space-based backbone network architecture based on space-air-ground integrated network[C]//2017 IEEE 9th International Conference on Communication Software and Networks(ICCSN). Guangzhou: IEEE, 2017: 798-803. |
| [3] | 李凤华, 陈天柱, 王震, 等. 复杂网络环境下跨网访问控制机制[J]. 通信学报, 2018, 39(2): 1-10. (Li Feng-hua, Chen Tian-zhu, Wang Zhen, et al. Cross-network access control mechanism in complex network environment[J]. Journal of Communications, 2018, 39(2): 1-10. DOI:10.3969/j.issn.1001-2400.2018.02.001) |
| [4] | Shi L, Lu Z, Qin P, et al. Open flow based spatial information network architecture[C]//2015 International Conference on Wireless Communications & Signal Processing(WCSP). Nanjing: IEEE, 2015: 1-5. |
| [5] | Chen X, Jiao L, Li W, et al. Efficient multi-user computation offloading for mobile-edge cloud computing[J]. IEEE/ACM Transactions on Networking, 2015, 24(5): 2795-2808. |
| [6] | Chen M, Hao Y, Li Y, et al. On the computation offloading at ad hoc cloudlet: architecture and service modes[J]. IEEE Communications Magazine, 2015, 53(6): 18-24. DOI:10.1109/MCOM.2015.7120041 |
| [7] | Mach P, Becvar Z. Mobile edge computing: a survey on architecture and computation offloading[J]. IEEE Communications Surveys & Tutorials, 2017, 19(3): 1628-1656. |
| [8] | 张文丽, 郭兵, 沈艳, 等. 智能移动终端计算迁移研究[J]. 计算机学报, 2016, 39(5): 1021-1038. (Zhang Wen-li, Guo Bin, Shen Yan, et al. Research on computing migration of smart mobile terminal[J]. Journal of Computer, 2016, 39(5): 1021-1038.) |
| [9] | Kumar K, Liu J, Lu Y H, et al. A survey of computation offloading for mobile systems[J]. Mobile Networks and Applications, 2013, 18(1): 129-140. DOI:10.1007/s11036-012-0368-0 |
| [10] | Barbarossa S, Sardellitti S, Di Lorenzo P. Communicating while computing: distributed mobile cloud computing over 5G heterogeneous networks[J]. IEEE Signal Processing Magazine, 2014, 31(6): 45-55. DOI:10.1109/MSP.2014.2334709 |
| [11] | Cheng J, Shi Y, Bai B, et al. Computation offloading in cloud-RAN based mobile cloud computing system[C]//2016 IEEE International Conference on Communications(ICC). Malaysia: IEEE, 2016: 1-6. |
| [12] | Li S, Maddah-Ali M A, Yu Q, et al. A fundamental tradeoff between computation and communication in distributed computing[J]. IEEE Transactions on Information Theory, 2017, 64(1): 109-128. |
| [13] | Panigrahi C R, Sarkar J L, Pati B. Transmission in mobile cloudlet systems with intermittent connectivity in emergency areas[J]. Digital Communications and Networks, 2018, 4(1): 69-75. DOI:10.1016/j.dcan.2017.09.006 |
| [14] | Truong-Huu T, Tham C K, Niyato D. To offload or to wait: an opportunistic offloading algorithm for parallel tasks in a mobile cloud[C]//2014 IEEE 6th International Conference on Cloud Computing Technology and Science. Singapore: IEEE, 2014: 182-189. |
| [15] | Zhang W, Wen Y, Guan K, et al. Energy-optimal mobile cloud computing under stochastic wireless channel[J]. IEEE Transactions on Wireless Communications, 2013, 12(9): 4569-4581. DOI:10.1109/TWC.2013.072513.121842 |
