

1. 吉林大学 计算机科学与技术学院, 吉林 长春 130012;
2. 吉林大学 软件学院, 吉林 长春 130012;
3. 吉林大学 符号计算与知识工程教育部重点实验室, 吉林 长春 130012
收稿日期:2021-06-10
基金项目:国家重点研发计划项目(国科发资【2020】151号);吉林省产业创新专项资金资助项目(2019C053-2)。
作者简介:于哲舟(1961-),男,吉林长春人,吉林大学教授,博士生导师;
刘元宁(1962-),男,吉林长春人,吉林大学教授,博士生导师。
摘要:针对传统虹膜定位算法定位不准确的问题, 利用改进的YOLOV3虹膜定位模型对虹膜定位的准确率加以提高, 使其更好应用于生产实践.使用Densenet-121模型作为特征提取模块, 并在此基础上通过复制骨干网络得到辅助网络的方式使其更有利于检测小目标, 用Non-local注意力机制增强图片获取特征语义信息.采用基于DarkNet-53的YOLOV3模型、Daugman模型及Wilde模型进行对比实验.实验结果表明: 本文的实验模型在虹膜定位中的准确率高达97.1%, 与其他虹膜定位模型相比具有明显优势.
关键词:YOLOV3虹膜定位特征提取目标检测注意力机制
Improved Iris Locating Algorithm Based on YOLOV3
YU Zhe-zhou1,3, LIU Yan2,3, LIU Yuan-ning1,3
1. College of Computer Science and Technology, Jilin University, Changchun 130012, China;
2. College of Software, Jilin University, Changchun 130012, China;
3. Key Laboratory of Symbolic Computing and Knowledge Engineering of Ministry of Education, Jilin University, Changchun 130012, China
Corresponding author: LIU Yuan-ning, E-mail: lyn@jlu.edu.cn.
Abstract: Aiming at the problem of inaccurate locating of traditional iris locating algorithms, an improved YOLOV3 iris locating model is proposed to improve the accuracy of iris locating and make it better applied to production practice. Using the Densenet-121 model as the feature extraction module, and on the basis of it, the auxiliary network is obtained by copying the backbone network to make it more conducive to the detection of small targets, and the non-local attention mechanism is used to enhance the semantic information of the features obtained by the image. The YOLOV3 model, Daugman model and Wilde model based on DarkNet-53 are used for comparative experiments. The experimental results show that the accuracy of the experimental model in this paper is as high as 97.1% in iris locating, which has obvious advantages compared with other iris locating models.
Key words: YOLOV3iris registrationfeature extractionobject detectionattention mechanism
当今最受欢迎的生物特征识别方式是虹膜识别[1-3], 在整个虹膜识别系统流程中, 虹膜定位环节处于核心位置, 虹膜定位的准确率对系统后期的识别产生重大影响.传统的虹膜定位方法容易受到噪声、睫毛遮挡等影响, 导致定位不准确, 所提取到的信息很难在后期的特征识别中使用.YOLOV3模型在目标检测方面效果较好, 采用这种基础模型对虹膜两个内外边界进行定位, 提高了定位准确性.由于原始特征提取网络DarkNet-53层数较少, 不能提取到高质量的虹膜特征.虽然能够大大提高检测速度, 但准确率很低; 随卷积神经网络中卷积层数的不断加深, 提取到的特征也会更为丰富, 随网络层数不断加深, 导致网络模型出现退化.退化主要是由于梯度消失导致网络性能退化, 同时由于虹膜图像在采集时虹膜的大小也不尽相同.卷积神经网络经过多次卷积之后, 特征图的尺寸会变得很小, 所以检测小目标更加困难, 无法更好利用虹膜图片学习到虹膜语义特征, 因此本文针对这些问题对虹膜定位模型作出改进[4-8].
1 改进的YOLOV3结构1.1 Densenet-121网络模型Darknet模型会产生梯度消失问题, Resnet模型可以使梯度消失问题得到有效解决, 但Resnet短路连接方式会导致网络中的参数量变大, 网络的特征利用率变低.Densenet-121结构所采用的连接方式是密集连接, 这样的结构能够有效减少网络参数数量, 克服梯度消失问题.在传统的卷积神经网络模型中, 网络的连接方式是直接连接的.Densenet-121网络使用的是密集连接的方式, 也就是说将网络的每一层与前面的层直接相连.如果网络中有L个层, 那么网络的连接数量就会有
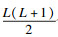
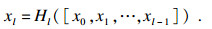 | (1) |
图 1(Fig. 1)
 | 图 1 Densenet网络结构Fig.1 Densenet network structure |
1.2 Non-local注意力机制Non-local注意力机制的作用主要是用来对虹膜图像重点区域进行加强, 增强虹膜图片学习到的语义特征, Non-local操作相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息. Non-local操作能够直接从任意两点间获取到长距离的依赖信息, 同时它也是一个易于集成的网络模块, 虹膜特征信息提取是一种比较优良的注意力机制实现.Non-local的通用式为
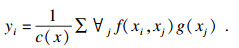 | (2) |
图 2(Fig. 2)
 | 图 2 Non-local注意力机制结构Fig.2 Structure of Non-local attention mechanis |
1.3 辅助网络为进一步增强小目标虹膜学习到的语义特征, 在改进的YOLOV3虹膜定位算法中, 使用复制残余模块的方式获得辅助结构, 扩展整个特征提取网络, 进而优化骨干网络.辅助网络的规模要比骨干网络小, 与原始的YOLOV3剩余模块相比, 增加了辅助网络的剩余模块.在辅助网络中使用较大的接收场, 辅助网络会将收集到的特征位置信息传输到骨干网络上, 骨干网络能够更加准确地学习目标特征信息.在网络中添加辅助网络使整个网络结构与高级或低级语义特征密切联系, 能够有效提高网络性能.辅助网络结构图如图 3所示[12-13].
图 3(Fig. 3)
 | 图 3 辅助网络结构图Fig.3 Auxiliary network structure diagram |
2 实验设计实验数据使用的是吉林大学自主采集的JLUIRIS-v6和JLUIRIS-v7两代虹膜图像, 在虹膜库中选择2 238张经过质量评价挑选后的虹膜图像作为本次实验的训练集和测试集.在进行虹膜定位前要对虹膜图像进行预处理及标注处理.本文所用的工具是labelImg, 标注过的每张图片都生成关于虹膜的内外圆目标框的标签及其坐标值的xml文件.经过标注的虹膜图像如图 4所示.
图 4(Fig. 4)
 | 图 4 虹膜图像预处理Fig.4 Iris image preprocessing |
本文改进实验的batchsize为8, 一共训练80个epoch, 图片输入大小为640×480.Densenet的权重在Imagenet上预训练完成.采用Adam优化器, 由于主干网络已经在Imagenet上预训练, 因此, Densenet的学习率设置为0.000 1, 网络中其他模块的学习率设置成0.001, 学习率每30个epoch下降为原来的1/10.在进行了40个epoch后, 采用多尺度的训练方式, 随机将图片的尺度放大或者缩小来增强模型的尺度不变性.本文采用了随机亮度、随机对比度、图片翻转及图片模糊等数据增强的方式.激活层使用leakey relu激活函数.所有的实验都是在一个单独的1 080 ti上完成, 训练时间为6 h.对于每一个锚点, 根据实际数据设置了9个锚点框, 大小为[(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)], 对于与真实框的IOU大于0.7的锚点框, 将其设置成正样本, IOU小于0.3的锚点框设置成负样本, IOU在0.3~0.7之间的样本不作计算.在Non-local模块中, 放缩系数r设置为2.测试时, NMS非极大值抑制的阈值设置为0.4, 物体的置信度阈值设置为0.75[14-15].
改进的模型结构图如图 5所示.
图 5(Fig. 5)
 | 图 5 改进模型的结构图Fig.5 Structure diagram of improved model |
改进模型的参数如表 1所示.
表 1(Table 1)
| 表 1 改进模型的参数 Table 1 Parameters of improved model |
3 实验结果分析可视化结果如图 6所示.使用Densenet特征提取网络的矩形可视化结果如图 6a所示, 使用Darknet特征提取模型的可视化结果如图 6b所示.
图 6(Fig. 6)
 | 图 6 可视化结果Fig.6 Visualization results |
由于目标检测模型中的标定框和得到的预测框都是基于直角坐标系下的矩形框体, 根据虹膜内圆、外圆的几何特征, 虹膜定位要求输出的是椭圆形的定位框.根据得到的矩形框体输出椭圆形的标注框, 最终本文系统得到的虹膜内外圆定位结果的可视化图像如图 7所示.可知本文模型的内外圆定位效果.
图 7(Fig. 7)
 | 图 7 模型最终可视化图像Fig.7 The final visual image of the model |
与未改进的算法相比, 本文模型训练效果有了显著提升, 同时loss曲线下降的趋势更加平缓, 本文改进网络结构训练集的损失函数图像如图 8所示.由各层loss曲线可知, 本文模型能很快逼近曲线中损失函数的最小值, 收敛速度快, 所以能更好更快地拟合虹膜数据集.
图 8(Fig. 8)
 | 图 8 损失函数图Fig.8 Loss function images (a)—第一层; (b)—第二层; (c)—第三层. |
YOLOV3虹膜图像只需要定位出2种类别的物体, 即虹膜的内圆和外圆边界.在传统Daugman模型中, 虹膜定位精确率为95.6%, Wilde模型定位精确率为95.3%, 基于Darknet的YOLOV3模型定位精确率为92.4%, 本文中通过优化的模型精确率为97.1%.PR曲线如图 9所示, 各模型评价指标对比如表 2所示.
图 9(Fig. 9)
 | 图 9 PR曲线图Fig.9 PR curve |
表 2(Table 2)
| 表 2 各模型评价指标对比 Table 2 Comparison of evaluation indexes of each model ? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 结论1) Darknet本身所特有的优势是速率较快, 但它的特征提取能力差, 容易出现退化现象.经过改进的YOLOV3网络将特征提取模块换成优良的特征提取模型Densenet-121, 并添加了复制网络及Non-local注意力机制增强学习到的语义特征, 着重感兴趣区域, 即使是小目标虹膜也能够学习到大量的特征信息, 测试结果的精确率达到97.1%.
2) 本文模型在虹膜定位上超越了传统虹膜定位算法精确率方面的各项评价指标.
参考文献
| [1] | Kumar M M, Prasad M V N K, Verma M, et al. Secure verifiable and iris authentication system using fully homomorphic encryption[J]. Computers & Electrical Engineering, 2021, 89: 106924. |
| [2] | El-Tokhy M S. Robust multimodal biometric authentication algorithms using fingerprint, iris and voice features fusion[J]. Journal of Intelligent & Fuzzy Systems, 2021, 40(1): 647-672. |
| [3] | Boles W W, Boashash B. A human identification technique using images of the iris and wavelet transform[J]. IEEE Transactions on Signal Processing, 2002, 46(4): 1185-1188. |
| [4] | Jan F, Min-Allah N, Agha S, et al. Robust iris localization scheme for iris recognition[J]. Multimedia Tools and Applications, 2021, 80(3): 4579-4605. DOI:10.1007/s11042-020-09814-5 |
| [5] | Wang Y, Shan S. Accurate disease detection quantification of iris based retinal images using random implication image classifier technique[J]. Microprocess & Microsystems, 2021, 80: 103350. |
| [6] | Noruzi A, Mahlouji M, Shahidinejad A, et al. Iris recognition in unconstrained environment on graphic processing units with CUDA[J]. Artificial Intelligence Review, 2020, 53(5): 3705-3729. DOI:10.1007/s10462-019-09776-7 |
| [7] | Larregui J I, Cazzato D, Castro S M. An image processing pipeline to segment iris for unconstrained cow identification system[J]. Computer Science, 2019, 9(1): 145-159. |
| [8] | Susitha N, Subban R. Reliable pupil detection and iris segmentation algorithm based on SPS[J]. Cognitive Systems Research, 2019, 57: 78-84. DOI:10.1016/j.cogsys.2018.09.029 |
| [9] | Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[J]. arXiv preprint arXiv: 1711.07971.2017[2018-01-30]. https://zhuanlan.zhihu.com/p/33345791. |
| [10] | Hao K L, Feng G R, Ren Y L, et al. Segmentation using feature channel optimization for noisy environments[J]. Cognitive Computation, 2020, 12(6): 1205-1216. DOI:10.1007/s12559-020-09759-9 |
| [11] | Khan T M, Bailey D G, Mohammad A, et al. Real-time iris segmentation and its implementation on FPGA[J]. Journal of Real-Time Image Processing, 2020, 17(5): 1089-1102. DOI:10.1007/s11554-019-00859-w |
| [12] | Zhang M, He Z F, Zhang H, et al. Toward practical remote iris recognition: a boosting based framework[J]. Neuro Computing, 2019, 330: 238-252. |
| [13] | Labati R D, Genovese A, Piuri V, et al. I-SOCIAL-DB: a labeled database of images collected from websites and social media for iris recognition[J]. Computer Vision and Image Understanding, 2021, 105: 1040582021. |
| [14] | 李佳泽. 基于目标检测的虹膜定位研究[D]. 长春: 吉林大学, 2020. (Li Jia-ze. Research on iris location based on target detection[D]. Changchun: Jilin University, 2020. ) |
| [15] | Cheng M M, Liu Y, Lin W Y, et al. BING: binarized normed gradients for objectness estimation at 300fps[J]. Computational Visual Media, 2021, 5(1): 4-21. |
