������, ���, ����
(������ҵ��ѧ ����ѧԺ, ���� 710072)
ժҪ:
Ϊ���������ƶȼ����м������̼������������Ķ�����ͬʱ�����̽ڵ�϶������£�ʵ������ƥ���㷨��Ѱ��ʱ�临�ӶȺ����ƶ�ƥ�����ֵ��������ۺ��Ż������һ���������̵��Ŵ�ƥ���㷨�����Ŵ��㷨���벢Ӧ������������ͽṹ�����ƶȼ���Ѱ�Ź�����. ȷ���Ŵ��㷨�IJ������뷽ʽ��������̰���㷨���г�ʼ��Ⱥ�����ã���������Ŵ����ӣ������Ч�ļ��ԣ���������̽ڵ�϶�ʱ����ƥ�����Ѱ������. ʵ���о������������̽ڵ����϶�ʱ�������㷨��Ѱ��ʱ�仨�Ѻ����ƶ�ֵ������������Ż����������������������㷨. ���Ŵ��㷨Ӧ�õ����̵����ƶȼ��㼰��Ѱ�Ź��̣�������Ч�ؿ���ʱ�临�ӶȲ���֤�Ϻõ�ƥ��������.
�ؼ���: ҵ������ �ı����ƶ� ����֪ʶ�� ƥ�����ƶ� �Ŵ��㷨
DOI��10.11918/j.issn.0367-6234.2016.07.025
�����:TP315
���ױ�ʶ��:A
������Ŀ:������Ȼ��ѧ����(51375395)
Process matching method based on semantic repository
CHANG Guanyu, YANG Haicheng, SUN Peng
(School of Mechanical Engineering, Northwestern Polytechnical University, Xi��an 710072, China)
Abstract:
To calculate the process similarity with consideration of deep semantics correlation between business processes, and to optimize the time complexity and matching result when the node number of business process becomes larger and larger, a process matching method based on GA (Genetic Algorithm) is put forward. This method is applied in similarity calculation for both process semantic and process structure, in which encoding is determined, and greedy algorithm is utilized to initialize the population of GA. By defining genetic operations and adopting some strategies for simplifying, the optimization of business process matching with large node number is fulfilled. As is expected, the experiments prove that the overall performance of algorithm proposed in this paper is better than the others that exist, especially when the count of process nodes grows to a large number. So it is concluded that the application of GA in business process similarity calculation and corresponding process optimization can effectively control the time complexity, meanwhile ensure the quality of the matching result, which shows a good practicability.
Key words: business process text similarity semantic repository match similarity genetic algorithm
������, ���, ����,. �ں�����֪ʶ�������ƥ���㷨[J]. ��������ҵ��ѧѧ��, 2016, 48(7): 150-155. DOI: 10.11918/j.issn.0367?6234.2016.07.025.
CHANG Guanyu, YANG Haicheng, SUN Peng. Process matching method based on semantic repository[J]. Journal of Harbin Institute of Technology, 2016, 48(7): 150-155. DOI: 10.11918/j.issn.0367?6234.2016.07.025.

������Ŀ ������Ȼ��ѧ����(51375395) ����� ������(1985��)���У���ʿ�о��� ͨѶ���� ���(1959��)���У����ڣ���ʿ����ʦ��dengxiao@mail.nwpu.edu.cn ������ʷ �ո�����: 2015-03-26
Contents -->Abstract Full text Figures/Tables PDF
�ں�����֪ʶ�������ƥ���㷨
������, ���

 , ����
, ���� ������ҵ��ѧ ����ѧԺ������ 710072
�ո�����: 2015-03-26
������Ŀ: ������Ȼ��ѧ����(51375395)
�����: ������(1985��)���У���ʿ�о���
ͨѶ����: ���(1959��)���У����ڣ���ʿ����ʦ��dengxiao@mail.nwpu.edu.cn
ժҪ: Ϊ���������ƶȼ����м������̼������������Ķ�����ͬʱ�����̽ڵ�϶������£�ʵ������ƥ���㷨��Ѱ��ʱ�临�ӶȺ����ƶ�ƥ�����ֵ��������ۺ��Ż������һ���������̵��Ŵ�ƥ���㷨�����Ŵ��㷨���벢Ӧ������������ͽṹ�����ƶȼ���Ѱ�Ź�����. ȷ���Ŵ��㷨�IJ������뷽ʽ��������̰���㷨���г�ʼ��Ⱥ�����ã���������Ŵ����ӣ������Ч�ļ��ԣ���������̽ڵ�϶�ʱ����ƥ�����Ѱ������. ʵ���о������������̽ڵ����϶�ʱ�������㷨��Ѱ��ʱ�仨�Ѻ����ƶ�ֵ������������Ż����������������������㷨. ���Ŵ��㷨Ӧ�õ����̵����ƶȼ��㼰��Ѱ�Ź��̣�������Ч�ؿ���ʱ�临�ӶȲ���֤�Ϻõ�ƥ��������.
�ؼ���: ҵ������ �ı����ƶ� ����֪ʶ�� ƥ�����ƶ� �Ŵ��㷨
Process matching method based on semantic repository
CHANG Guanyu, YANG Haicheng
, SUN Peng School of Mechanical Engineering, Northwestern Polytechnical University, Xi��an 710072, China
Abstract: To calculate the process similarity with consideration of deep semantics correlation between business processes, and to optimize the time complexity and matching result when the node number of business process becomes larger and larger, a process matching method based on GA (Genetic Algorithm) is put forward. This method is applied in similarity calculation for both process semantic and process structure, in which encoding is determined, and greedy algorithm is utilized to initialize the population of GA. By defining genetic operations and adopting some strategies for simplifying, the optimization of business process matching with large node number is fulfilled. As is expected, the experiments prove that the overall performance of algorithm proposed in this paper is better than the others that exist, especially when the count of process nodes grows to a large number. So it is concluded that the application of GA in business process similarity calculation and corresponding process optimization can effectively control the time complexity, meanwhile ensure the quality of the matching result, which shows a good practicability.
Key words: business process text similarity semantic repository match similarity genetic algorithm
���������ʲ�����Ч����ȡ������Ϣϵͳ�����̹�������ˮƽ������Ч���������ƶȲ�ѯ�������Ϊ����ҵ�����̹���ˮƽ�Ĺؼ�����֮һ[1]. �������Լ��㷽�棬��ע�����̽ڵ��ϵ��ı���ǩ�����ƶ��ǽ������������Է����Ļ���[2-3]. ��ͳ�Ļ����ı���ƥ���������������������Ѱҵ������ģ��֪ʶ��. ������ƥ��ͼ������Թؼ��ʺ��ַ�ƥ��[4-5]��������ֵ[6]�Ľ��Ƴ̶�Ϊ��������ģ�ͱ�ǵ��ı���ǩ�����ض��Ĺؼ��ʻ��ַ�����ô���ַ�ʽ��ȷ�г�Ч��[7]. ���ǣ��������Ƶ�Ӧ��û�п��������칹�ԵĴ���. ��ʹ�ò����Թؼ��ʺ��ַ�ƥ��Ϊ�����Ĵ�ͳ��������ƥ������ʵ�ָ���ȷ�������ѯ[8]. ��������֪ʶ����������ƶ���һ�ּ����ı����ı������������������Ƴ̶ȵĶ�������. ��ˣ����������������֪ʶ��ĸ������ƶȼ��㷽��������Ӧ��������ƥ���е��ı���ǩ�����ƶȼ����У����������ƥ���ȷ��.
������ƥ����̵�Ѱ���㷨�ϣ��ִ�ļ�������ƥ���㷨���߱����Ե��ص㣬�������̽ڵ�϶�ʱ�������ֳ����ԵIJ���. ����̰���㷨[9]�������ںܶ�ʱ���ڵõ�һ��ƥ�����Լ�ƥ������ƶ�ֵ�����ܿ��ܵõ��IJ�������ƥ��. ����Ϊ���͵�����ʽ�㷨��A*�㷨[10]����Ȼ����ȷ���ҵ����Ž⣬�����ʱ���ۿ��ܻ����Žڵ������Ӷ���������. ��ˣ��������һ�ֻ����Ŵ��㷨[11-12]�������Ż����㷨��ּ�ڽڵ����϶�ʱ�����������ƶ��ϴﵽ��Ϊ�����ֵ���ֿ�����ƥ��Ѱ�Ź��̵�ʱ��ķ��ϴ��ڿ��Խ��ܵķ�Χ.
1 �ڵ��������ƶȼ���ģ�� 1.1 �������ƶȼ���ؼ���������1?��ԭ���ƶ�[13]. ��s1��s2Ϊ������ԭ,��ԭ������ΪD(s1,s2)�����ƶȼ�ΪSsem(s1,s2)����
${{S}_{\text{sem}}}\left( {{s}_{1}},{{s}_{2}} \right)\frac{\alpha \times \left( {{d}_{1}}+{{d}_{2}} \right)}{\left( D\left( {{s}_{1}},{{s}_{2}} \right)+\alpha \right)\times \max \left( \left( {{d}_{1}}-{{d}_{2}} \right),1 \right)}.$
����:d1��d2 �ֱ�����ԭs1����ԭs2�����IJ�Σ���>0,���������ƶ�Ϊ0.5ʱs1��s2֮��ľ���.
����2?��ԭ���ƥ��[14]. ��S1={s11,s12,��,s1m} ��S2={s21,s22,��,s2n}�ֱ�Ϊ����m��n����ԭ�ļ��ϣ�����m��n. �����S1��S2��һ�����伯��ΪM. ����ԭ�����ƥ����ָһ�����伯��Mopt,�������������ĵ��伯��M����
$\sum\limits_{\left( {{s}_{1i}},{{s}_{2j}} \right)\in {{M}^{\text{opt}}}}{{{S}_{\text{sem}}}\left( {{s}_{1i}},{{s}_{2j}} \right)}\ge \sum\limits_{\left( {{s}_{1i}},{{s}_{2j}} \right)\in M}{{{S}_{\text{sem}}}\left( {{s}_{1i}},{{s}_{2j}} \right)}.$
����Ssem Ϊ������ԭ������ƶ�.
����3?�������ƶ�. ��C1��C2Ϊ�������C1��m ����ԭ����s11,s12,��,s1m��C2��n����ԭ����s21,s22,��,s2n����m��n . MoptΪ���������������ԭ���ϵ����ƥ�䣬��C1��C2 �����ƶ�Ϊ[15]
${{S}_{\text{Concept}}}\left( {{C}_{1}},{{C}_{2}} \right)=\sum\limits_{\underset{\left( {{s}_{i}},{{s}_{j}} \right)\in {{M}^{\text{opt}}}}{\mathop{i=1}}\,}^{m}{{{w}_{i}}\times {{S}_{\text{sem}}}\left( {{s}_{i}},{{s}_{j}} \right)}.$
����wi��Ϊ��ͬ����ԭӳ�丳��IJ�ͬȨֵ.
����4 �������ƶ�. �����S1������L1��m������C11��C12������C1m������S2������L2��n������C21��C22������C2n�������S1����S2�����ƶ�Ϊ[16-17]
$S\left( {{S}_{1}},{{S}_{2}} \right)=\underset{\begin{smallmatrix} i=1\cdots m \\ j=1\cdots n \end{smallmatrix}}{\mathop{\max }}\,\left( {{S}_{\text{concept}}}\left( {{C}_{1i}},{{C}_{2j}} \right) \right).$
����SConcept(C1i,C2j)��ʾ����C1i��C2j֮������ƶ�.
1.2 ���̽ڵ���������ƶȼ�������5 ͬ������ƶ�[18]. ��l1,l2�ʦ�Ϊ�ı���ǩ��W Ϊ���д���ʵļ��ϣ�w�� ����P(W)Ϊ�����ı���ǩΪ�����ʻ㼯�ϵĺ���. s��W��P(W)�ɻ�ȡ�������ʵ�ͬ���. ��w1=w(l1),w2=w(l2),��wi��ws �ֱ�Ϊ��ͬ�ʻ��ͬ��ʵ�Ȩֵ. S(l1,l2)Ϊl1��l2 ���������ƶȣ�
$\begin{align} & S({{l}_{1}},{{l}_{2}})=[2\cdot {{w}_{i}}\cdot |{{w}_{1}}\cap {{w}_{2}}|+{{w}_{s}}\cdot (|s({{w}_{1}},{{w}_{2}})|+ \\ & |s({{w}_{2}},{{w}_{1}})\left| )]/ \right|{{w}_{1}}+{{w}_{2}}|. \\ \end{align}$
����$s\left( {{w}_{1}},{{w}_{2}} \right)=\underset{w\subseteq {{w}_{1}}-{{w}_{2}}}{\mathop{\cup }}\,s\left( w \right)\cap \left( {{w}_{2}}-{{w}_{1}} \right)$Ϊw2��w1��ͬ��ʼ���.
����6?�ı���ǩ���������ƶ�. ��l1,l2����Ϊ�ı���ǩ��WΪ���д���ʵļ��ϣ�w������P(W)Ϊ�����ı���ǩ�ɵ��ʼ��ϵĺ���. sword �ǻ�������֪ʶ���һ���ʻ����ƶȺ���. ��w1=w(l1),w2=w(l2)��MΪ�ʻ㼯��w1��w2�Ĵʻ㵥�伯��. MoptΪʹ�ôʻ�ӳ�����ƶ�ֵ֮������ӳ��. S(l1,l2)Ϊ�ı���ǩl1��l2���������ƶȣ���
$S\left( {{l}_{1}},{{l}_{2}} \right)=\frac{2}{\left| {{w}_{1}} \right|+\left| {{w}_{2}} \right|}\sum\limits_{\left( {{w}_{1i}},{{w}_{2j}} \right)\in {{M}^{\text{opt}}}}{{{s}_{\text{word}}}\left( {{w}_{1i}},{{w}_{2j}} \right)}.$
����:|w1|��|w2| �ֱ��ʾw1��w2�еĴʻ�����w1i��w2j�ֱ��ʾw1 ��w2 �е�һ������.
����7?�ڵ��������ƶ�. ��B1(N1,E1,��1,��1,��1)��B2(N2,E2,��2,��2,��2)����������ͼ����n1��N1 �� n2��N2�ֱ�ΪB1��B2��һ���ڵ�. SΪ���ƶȺ���. ��ô���Զ���ڵ�n1��n2���Ե����ƶ�Ϊ
${{S}_{\text{att}}}\left( {{n}_{1}},{{n}_{2}} \right)=\underset{\begin{matrix} \left( {{t}_{1}},{{l}_{1}} \right)\in {{\alpha }_{1}}\left( {{n}_{1}} \right), \\ \left( {{t}_{2}},{{l}_{2}} \right)\in {{\alpha }_{2}}\left( {{n}_{2}} \right), \\ {{t}_{1}}={{t}_{2}} \\\end{matrix}}{\mathop{{{F}_{AVG}}}}\,S\left( {{l}_{1}},{{l}_{2}} \right).$
�������ƶ�һ�����������ƶȽ������ʹ��.
����8?�ڵ��������ƶ�. ��������ͼB1(N1,E1,��1,��1,��1)��B2(N2,E2,��2,��2,��2)����n1��N1 �� n2��N2�ֱ�ΪB1��B2�Ľڵ�. ��t�� T��T��[0,1]Ϊ�ڵ����͵����ƶȺ�������
${{S}_{\text{typ}}}\left( {{n}_{1}},{{n}_{2}} \right)=t\left( {{\tau }_{1}}\left( {{n}_{1}} \right),{{\tau }_{2}}\left( {{n}_{2}} \right) \right)$
Ϊ�ڵ��������ƶȺ���. t��Ԥ�ȶ����. ��ѡ�����²ο�������ʽ��
$\eqalign{ & t\left( {{t_1},{t_2}} \right) = \left\{ \matrix{ 1,{\rm{if }}{t_1} = {t_2}; \hfill \cr 0,{\rm{else;}} \hfill \cr} \right. \cr & t\left( {{t_1},{t_2}} \right) = {S_{{\rm{sem}}}}\left( {{t_1},{t_2}} \right). \cr} $
���ϣ������������ͼ 1�Ľڵ����ƶȼ���ģ��.
Figure 1
 ͼ 1 �ڵ����ƶȼ���ģ��
ͼ 1 �ڵ����ƶȼ���ģ�� 2 �������ƶȼ���ģ�͵�2��Ҫ�о������ƶ���ҵ�����̵Ľṹ���ƶ�. �ṹ���ƶȻ���ͼ�༭����������[19] .
����9?ͼ�ı༭����. ��B1(N1,E1,��1,��1,��1)��B2(N2,E2,��2,��2,��2)����������ͼ,SΪ���ƶȺ�����M��(N1
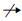
$\left| {{s}_{n}} \right|+\left| {{s}_{e}} \right|+2\cdot \sum\limits_{\left( n,m \right)\in M}{\left( 1-S\left( n,m \right) \right)}.$
ͼ�ı༭���������������̵�������С������. ����㷽���ǣ�1��ȥ�����롱��ɾ�����ڵ㡰���롱��ɾ�������Լ����滻���ڵ�ƽ�������ƽ��ֵ�ķ������ֵIJ�.
����10?ͼ�༭�������ƶ�. ��B1=(N1,E1,��1,��1,��1)��B2=(N2,E2,��2,��2,��2)Ϊ��������ͼ��SΪ���ƶȺ�������M�� (N1
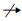
$\left\{ \begin{align} & {{s}_{\text{ged}}}\left( {{B}_{1}},{{B}_{2}} \right)=1-avg\left( {{s}_{nv}},{{s}_{ev}},{{s}_{bv}} \right), \\ & {{s}_{nv}}=\frac{\left| {{s}_{n}} \right|}{\left| {{E}_{1}} \right|+\left| {{E}_{2}} \right|}, \\ & {{s}_{ev}}=\frac{\left| {{s}_{e}} \right|}{\left| {{E}_{1}} \right|+\left| {{E}_{2}} \right|}, \\ & {{s}_{bv}}=\frac{2\cdot \sum\limits_{\left( n,m \right)\in M}{\left( 1-S\left( n,m \right) \right)}}{\left| {{N}_{1}} \right|+\left| {{N}_{2}} \right|-\left| {{s}_{n}} \right|}. \\ \end{align} \right.$
����11?�ȼ�ӳ������ŵȼ�ӳ��. ��B1(N1,E1,��1,��1,��1)��B2(N2,E2,��2,��2,��2)Ϊ��������ͼ����ڵ�����ƶȺ���ΪS��N1��N2��[0,1]. һ���ֲ�����MS��(N1
���ŵȼ�ӳ��MSopt��N1
$\sum\limits_{\left( {{n}_{1}},{{n}_{2}} \right)\in M_{\text{S}}^{\text{OPT}}}{S\left( {{n}_{1}},{{n}_{2}} \right)}\ge \sum\limits_{\left( {{n}_{1}},{{n}_{2}} \right)\in {{M}_{S}}}{S\left( {{n}_{1}},{{n}_{2}} \right)}.$
����12?����ƥ�����ƶ�. ��B1=(N1,E1,��1,��1,��1)��B2=(N2,E2,��2,��2,��2)Ϊ��������ͼ. ��SΪ���������ڵ�����ƶȵĺ�������ts ΪӦ���ԵĽڵ����ͼ���. ��MSopt�� N1��/ N2Ϊͨ�����ƶȺ���S���������ŵȼ�ӳ�䣬���к�����ts �е�����. ��ôB1 ��B2 ��Ľڵ�ƥ�����ƶ�Ϊ
$\begin{align} & {{S}_{\text{nm}}}=\left( 2\cdot \sum\limits_{\left( n,m \right)\in M_{\text{S}}^{\text{opt}}}{S\left( n,m \right)} \right)/ \\ & \left| \left\{ n\left| n\in {{N}_{1}},{{\tau }_{1}}\left( n \right)\notin {{t}_{s}} \right. \right\} \right|+ \\ & \left| \left\{ n\left| n\in {{N}_{2}},{{\tau }_{2}}\left( n \right)\notin {{t}_{s}} \right. \right\} \right|. \\ \end{align}$
�������϶��壬�������ƶȼ���ģ����ͼ 2.
Figure 2
 ͼ 2 �������ƶȼ���ģ��
ͼ 2 �������ƶȼ���ģ�� 3 ����ƥ�����Ѱ���㷨��Ʊ��������һ�ֻ����Ŵ��㷨��ƥ�����Ѱ���㷨��ʹ�ü���Ч�ʺ�ƥ��Ч����������Ӧ������. �㷨�ؼ����ϸ������.
3.1 ���̱�����һ����n ���ڵ������Pn�����ñ���1,2,��,n��1,n��ÿ���ڵ���б���. ����һ����m���ڵ������Pm���������Ϊ1,2,��,m��1,m. �����������̵Ľڵ�������n��m. ��Ϊ���ܿ���n��ʾ�ڵ����϶�����̽ڵ���. �������ڵ����ֱ�Ϊn��m������Pn������Pm����ƥ��ʱ�������λ����Ϊn������ÿһ������λ�ϵ�ȡֵ��Χ��1~n,��ÿһ������λ�ϵ�ȡֵ���ظ�. ������ÿ������λ����Pn��һ���ڵ㣬���û���λ��ȡֵ����Pm�е�һ���ڵ�. ע�n��m������ڻ���λ��ȡֵ�У�����m��ֵm+1,��,n-1,n��û�������. ��ˣ���ij����λ��ȡֵΪm+1,��,n-1,n�е�һ��ʱ����ʾ�û���λ����������Pn�Ľڵ㲻����Pm�нڵ�ƥ��.
3.2 ��Ⱥ��ʼ�����ȣ�����ȷ��һ����ʾ�ڵ������ƶȵľ���S. ��P9��P7Ϊ�����������ƶȾ���S9��7Ϊ
${{S}_{9\times 7}}=\begin{matrix} {} & \begin{matrix} 1 & 2 & \cdots & 7 \\\end{matrix} \\ \begin{matrix} 1 \\ 2 \\ \vdots \\ 9 \\\end{matrix} & \left[ \begin{matrix} {{S}_{11}} & {{S}_{12}} & \cdots & {{S}_{17}} \\ {{S}_{21}} & {{S}_{22}} & \cdots & {{S}_{27}} \\ \vdots & \vdots & {{S}_{11}} & \vdots \\ {{S}_{91}} & {{S}_{92}} & \cdots & {{S}_{97}} \\\end{matrix} \right] \\\end{matrix}$
ʽ�У�sijΪP9�ĵ�i���ڵ��P7�еĵ�j���ڵ�����ƶ�ֵ.
���Բ���̰���㷨���ɳ�ʼ��Ⱥ. ���������ƶȾ���S(��S9��7)�У��ҵ�ֵ����һ��sij ��Ȼ����ֵ���к���д������λ�ĵ�һλ���õ�j,������������������������ʾ����. Ȼ����i�к͵�j�е��������ƶ�ֵ���õ�һ���µ����ƶȾ���S�䣬Ȼ����Ѱ��S����ֵ����Ԫ���ظ����Ϲ��̣�ֱ������S����������Ϊ0����õ���һ������. ��������������������õ��ĸ������Ϊ(7,3,1,6,2,5,4,����)������������Ԫ�ز�ȷ��. ��ʱ������δ���ֵı�������ȥ�õ�(7,3,1,6,2,5,4,8,9). �˼�Ϊ̰���㷨�Ľ��. �ٶԸø���ĸ�������λ��ֵ������䶯������ñ������ӽ��б��죬�ɵõ���ʼ��Ⱥ. ����̰���㷨��ʼ����Ⱥ����ͨ�����ű�����ѡ����ԣ���֤�Ŵ��㷨���յ�ƥ����һ��������̰���㷨.
3.3 ��Ӧ�Ⱥ���ƥ���Ŀ������������ƶ�����ƥ��. ���ݶ���11�еĽڵ�ƥ�����ƶȶ���,���Խ���Ӧ�Ⱥ�����Ϊ����m�����нڵ�ӳ�����ƶ�֮�ͣ���˽ڵ�ƥ������ƶ���Ӧ�Ⱥ����������£�
$f=\sum\limits_{i=1}^{m}{{{s}_{i,m\left( i \right)}}},$
����:m(i)Ϊ��������i����λ�ϵ�ֵ��si,m(i)Ϊ�����̽ڵ����ƶȾ����е�i�е�m(i)�е�ֵ. ����Щƥ���ϵĽڵ�����ƶ�֮�ͣ������һ����Ӧ�Ⱥ���.
�������̵Ľṹ���ƶȶ��壬���Էֱ��
$\left\{ \matrix{ \left| {{s_n}} \right| = \sum\limits_{i = 1}^n {{x_i};} \hfill \cr {s_{nv}} = {{\left| {{s_n}} \right|} \over {m + n}}; \hfill \cr {x_i} = \left\{ \matrix{ 1,{\rm{if }}{{\rm{s}}_{i,m\left( i \right)}} > 0; \hfill \cr 0,{\rm{else}}; \hfill \cr} \right. \hfill \cr {s_{ev}} = {{\left| {{s_e}} \right|} \over {\left| {{E_1}} \right| + \left| {{E_2}} \right|}}; \hfill \cr {s_{bv}} = {2 \over {m + n - \left| {{s_n}} \right|}}\sum\limits_{i = 1}^n {{x_i}\left( {1 - {{\rm{s}}_{i,m\left( i \right)}}} \right)} . \hfill \cr} \right.$
ʽ�У�m(i) Ϊ��������i����λ�ϵ�ֵ��si,m(i)Ϊ�����̽ڵ����ƶȾ����е�i �е�m(i)�е�ֵ. ��һ���õ��ṹ���ƶȵ���Ӧ�Ⱥ�����
$f=1-{{F}_{\text{avg}}}\left( {{s}_{nv}},{{s}_{ev}},{{s}_{bv}} \right).$
3.4 �Ŵ�����������ڲ����˷Ƕ����Ʊ��룬���Ա���������Ҫ���ö�Ӧ��ɢ���ֵı��췽��. �ڴ˲���ӳ�以��ģʽ�ı��췽�����������ת������λ�����ϵķ��������Ŵ�����������Ŵ�������.
3.5 �����趨��Ⱥ��ģ��������Ľڵ��������趨. ���磬ƥ���У��ڵ�϶�����̽ڵ���Ϊn������Ӧ����Ⱥ��ģ����Ϊn~2n. ��������Ϊ�ڵ���3~5�������߲���ij�����ƺ���Af(n) ������AΪһ����������f(n)Ϊһ���ڵ�����������. ������ʿ���ΪPc=0.9���������ΪPm=0.01.
���յ��㷨�����������£�
Figure 3
 ͼ 3 �Ŵ�ƥ���㷨����ͼ
ͼ 3 �Ŵ�ƥ���㷨����ͼ 4 ʵ�����ǰ���������ýڸ������̽ڵ�����ͬ�������̿��е����̷ֳ�98�࣬��2~99���ڵ�����̸�����ڵ�������һ��. ÿһ������һ����8~12��. ͨ���Բ�ͬ������̵�ƥ�����,�۲��㷨�����ܱ���. ���������ƶȵļ����ϲ����˻��ڡ�֪����������֪ʶ�⼰��ʻ��������ƶȼ��㷽���������ǰ�ĵķ���ʵ��������Ժ����ƶȼ���. ʵ��ʱ,����ͨ��ȷ���ض�ֵ�Բ��Խ����Ӱ����ȷ�����ʵ�ʵ�����;���,��ȷ���Ľض�ֵ�����£�ͨ��ƥ������ƶȽ����ƥ����̵�ʱ��������ȷ��ƥ���ۺ�Ч��.
�������ƶ�ʱ��ɱ�����Ccosts,t��
${{C}_{\text{cost}}}\left( s,t \right)=\frac{At\left( 1-s \right)}{s-{{s}_{0}}+\alpha }+{{C}_{n}}.$
ʽ��:tΪ���ķѵ�ʱ�䣬AΪ�������ڳ�����sΪ�������ƶ�ֵ��s0Ϊͨ��̰���㷨�õ������ƶ�ֵ����Ϊһ��С�ij������Ա����ĸΪ�㣻CnΪ�����̽ڵ����ļ�����. ͨ������Cn�ĵ��ڣ�ʹ���ڽڵ�����ʱ�������ɱ��ʵ���С. Cn��ȷ���볣��A������أ������ȡCn=��Ae��n. ����ʵ�������ص㣬Ҳ�ɲ������±��Σ�
${{C}_{\text{cost}}}\left( s,t \right)=\ln \left( \frac{At\left( 1-s \right)}{s-{{s}_{0}}+\alpha }+{{C}_{n}} \right).$ (1)
ʵ��֤�����ض�ֵ(��)��ѡȡ������ƥ���㷨��ʵ���Ծ߱���ҪӰ�죬�ر���A*�㷨�ڽڵ���������Լ��15���ڵ�ʱ��ƽ����ʱ�Ὺʼ����1 s/�ٶ�. ������54���ڵ�ʱ�������ʱ�Ѿ�����2 d����˲�������[9]���飬�����½�ȡ0.6����ʱ�õ���A*�㷨�����ƶ�ֵ�ͺ�ʱ�����涼���ڿɽ��ܷ�Χ��. ʵ���ж�̰���㷨��A*�㷨���Ŵ��㷨���а���ʱ�临�Ӷȡ�ƥ�����Լ�ʱ��ɱ����۵�ָ��ĶԱȣ��ضϲ����Ŀ�ѡ0.6��0.8,����=0.6ʱ���ԱȽϹ�����. �������̵����ƶ�ֵ����ֵ��С��Ϊ�������ر���ʵ��������3���㷨�õ������ƶ�ֵ��ȥ̰���㷨�õ���ֵ��ͼ,�����ͼ 4. ��ͼ 4��֪������=0.6��ȣ��� ȡ0.8ʱ������ƥ�����ƶȵľ���ֵ�����½���. ��Ϊ���ı��,ֱ�Ӻ������ƶ�ֵ��С�Ľڵ�ƥ�䣬�Ӷ������������ƶ�ֵ�½�.
Figure 4
 ͼ 4 �㷨��ƥ��Ч���Ƚ�
ͼ 4 �㷨��ƥ��Ч���Ƚ� ��ͼ 4��������ؿ���3���㷨�õ������ƶ�ֵ�IJ���. ����̰���㷨��������������ֵ�õ���ֵʼ����0����ˣ�̰���㷨����Ϊһ����Ϊ0��ֱ�ߣ���������������᷽����. ����Ϊ0.6ʱ�����Կ����Ŵ��㷨��A*�㷨��Լ�ڽڵ����ﵽ45����֮ǰ��ƥ���������ȫ�غϵģ����ڵ���>45ʱ���Ŵ��㷨��ֵ��ʼ����A*�㷨֮��. ��˵���Ŵ��㷨�ڽڵ�������45ʱ�������ٱ�֤���ƶ�ֵ�����Ž�. ����Ϊ0.8ʱ���Ŵ��㷨��A*�㷨�õ������ƶ�ֵ��̰���㷨��ͬ������̰���㷨��ֵ������Ϊһ����Ϊ0��ֱ�ߣ������ں��᷽���ϣ���ͼ 4(b)��ʾ. ��ˣ�������0.8ʱ��̰���㷨����õ�. ����������0.8ʱ���ض�ֵ���ڼ����㷨. Ȼ�����ʵ����Ҫ�����Խ�����ñȽϴ���0.8. ������ù���,����ʹ��ƥ�䲻�����������Ž�,�Ӷ�����ƥ���㷨ʧȥ����.
5 �㷨ʱ�临�ӶȽ�������ڲ����˽ض�ֵ��ƥ������Ӱ���ʵ��ȡ��=0.6��3���㷨��ʱ�临�ӶȽ��в���. ͼ 5Ϊ3���㷨���Žڵ������ӣ�ʱ�临�Ӷȵ����. �����ʾ�ڵ����������ʾÿ100������ƥ�����ķѵ�ʱ��. ����ʱ���Ƚϴ�ͼ���������ʱ���������.
Figure 5
 ͼ 5 �㷨ƽ��ʱ�临�Ӷ���ڵ�����仯����
ͼ 5 �㷨ƽ��ʱ�临�Ӷ���ڵ�����仯���� ��ͼ 5��֪��̰���㷨��ʱ���ϱ������. ͬʱ��A*�㷨������ڵ�������ʱ��ʱ���̰���㷨�൱. ���ڵ���>5ʱ��A*�㷨ʱ�临�Ӷȼ������������ڽڵ���Ϊ37��������Խ�Ŵ��㷨�ʾ�����������. �ڽڵ���Ϊ37����A*�㷨��ʱ��ķ�ԼΪ11(e11msԼΪ12 s). A*�㷨��ʱ�临�ӶȻ����������Žڵ�����������������ż������ʱ��ķѽ��ͻ���ͻȻ����������˵��A*�㷨�IJ����Խϴ�. �Ŵ��㷨��ʱ�临�ӶȻ����ȶ���ʼ�ձ�����11��������������. ��������ʵ����������ΪA*�㷨���������Ե�Ӱ��ܴ�ͬʱ�临�Ӷ����Žڵ��������ӻ����ָ���������ƣ��������������ֳ�����������ż�в���. ������̰���㷨,���Žڵ���������,ʱ�临�Ӷȳʶ�������ģʽ���������Ч����״̬�ռ䱬ը����. �Ŵ��㷨�ĸ��Ӷ�ȡ��������������ͽ������̣��߱����Ӷ�С�ҿɿص�����.
6 ʱ��ɱ����Ȼ���ʽ(1)���������������µ�ȡֵ��A=0.01,��=0.001��Cn=��Ae��n. ��ʵ�����ݽ��ж��δ������ó�ʱ��ɱ�Ч���Ա�����.
���Կ�����ͼ 6��������ͼ 5��һ�µ�. ��ͼ 6�ɵ�̰���㷨�ijɱ�������һֱά�������. ��Ϊ̰���㷨��ʱ�临�ӶȺ�С��ʹ��̰���㷨��һЩӦ�ó�����ʼ�վ�������. �Ŵ��㷨�ڽڵ���<37ʱ���ɱ�����ʼ�մ���A*�㷨������37ʱ����A*�㷨�൱������43���ڵ�ʱ���Ŵ��㷨�����A*�㷨���ֳ����ƣ�����ʱ��ɱ�����ȶ�����������. �����ڵ�������43ʱ������A*�㷨�����ƥ�������ֵ�Dz����Ŵ��㷨�����㡱��. �ۺ�ǰ��ʵ�����������̽ڵ�ﵽһ������ʱ�������Ŵ��㷨������������ƥ����һ���ܼ��ƥ�����Ч����ʱ��ɱ���ѡ����ʵ��Ӧ����˵���߱����Ե���������.
Figure 6
 ͼ 6 ���ƶȼ����ۺϴ�����ڵ�����ı仯���ƶԱ�
ͼ 6 ���ƶȼ����ۺϴ�����ڵ�����ı仯���ƶԱ� 7 ����1) �����̽ڵ���������ƶȺ����̽ṹƥ���㷨������������о�. ������̽ڵ��������ƶȺ����̽ṹ���ƶȵ���ض���,�����˱��ĵ��������ƶȼ���ģ��.
2) ����������ƶ�Ѱ�Ź��̣������һ�ֻ����Ŵ��㷨�Ĺ���Ѱ���㷨.
3) ��Ŀ���㷨������ʵ����֤��ͨ����ʵ�����ݵķ�����֤���˱�����Ƶ�����ƥ���㷨��ƥ���ʱ�临�ӶȺ�ƥ�����������ۺ��Ż��������Ա����е�ƥ�����Ѱ���㷨�������㷨���ֳ��ܺõ�ʵ�ü�ֵ.
����ʱ���ʵ��������������Ȼ������ƥ���г����˶�����Ŀ��죬�����н�һ������Ŀռ䣬��ʵ�ֱ������������ƥ�䣬�����������㷨��ƥ��Ѱ�Ź����е�Ӧ�õ�.
�����
[1]JIN T, WANG J, LA ROSA M, et al. Efficient querying of large process model repositories[J].Computers in Industry,2013, 64(1): 41-49.(
 0)
0)[2]WANG P, LIU H. Assessing sentence similarity using wordnet based word similarity[J].Journal of Software,2013, 8(6): 1451-1458.(
0)[3] LI H, TIAN Y, CAI Q. Improvement of semantic similarity algorithm based on WordNet[C]// 2011 6th IEEE Conference on Industrial Electronics and Applications (ICIEA). Beijing: IEEE, 2011��564-567. (
0)[4]������, ¬ӱӱ. ����Lucene���ļ�ȫ�ļ������о���Ӧ��[J].�͵���Ӧ��,2014(1): 51-54.(
0)[5]������, ������. Lucene��ȫ�ļ������о���Ӧ��[J].����������뷢չ,2010, 20(2): 12-15.(
0)[6]������. һ�ָĽ������������������ı�����ģ��[J].ͼ���鱨����,2011(19): 115-119.(
0)[7]BERRETTI S, DELBIMBO A, VICARIO E. Efficient match-ing and indexing of graph models in content-based retrieval[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2001, 23(10): 1089-1105.(
0)[8] COLOMOPALACIOS R, GOMEZBERBIS J M, GARCIAC-RESPO A, et al. SeMatching: using semantics to perform pair matching in mentoring processes[C]//2nd World Summit on the Knowledge Society. Chania: Springer Verlag, 2009��137-146. (
0)[9] DIJKMAN R, DUMAS M, GARCIABANUELOS L. Graph matching algorithms for business process model similarity search[C]//7th International Conference on Business Process Management. Ulm: Springer Verlag, 2009��48-63. (
0)[10]THANUJA M K, MALA C. A search tool using genetic algorithm[M].Chania: Springer, 2011: 138-143.(
0)[11] HONDA K, NAGATA Y, ONO I. A parallel genetic algorithm with edge assembly crossover for 100,000-city scale TSPs[C]// 2013 IEEE Congress on Evolutionary Computation (CEC). Cancun: IEEE,2013��1278-1285. (
0)[12] CEKMEZ U, OZSIGINAN M, SAHINGOZ O K. Adapting the GA approach to solve Traveling Salesman Problems on CUDA architecture[C]// 2013 IEEE 14th International Symposium on Computational Intelligence and Informatics (CINTI). Budapest: IEEE, 2013��423-428. (
0)[13]���, ���, ��˿·, ��. ����֪���Ĵʻ��������ƶȼ��㷽���о�[J].�����Ӧ���о�,2010(9): 3329-3333.(
0)[14]������, ������. ����ӳ���и������ƶȼ���ĸĽ�[J].ɽ����ͬ��ѧѧ��(��Ȼ��ѧ��),2008(4): 38-40.(
0)[15]����. �������ƶ��о�[J].����֪ʶ�뼼��(ѧ������),2007, 6: 1609-1611.(
0)[16]����ϼ, ��Ӣ��, ������, ��. һ�ָĽ��ĸ����������ƶȼ��㷽��[J].���������,2012(12): 176-178.(
0)[17]����, ֣��. �Ľ��ĸ����������ƶȼ���[J].��������������,2010(5): 1121-1124.(
0)[18]DIJKMAN R, DUMAS M, DONGEN B V, et al. Similarity of business process models: Metrics and evaluation[J].Information Systems,2011, 36(2): 498-516.(
0)[19] ZHU J, PUNG H K. Process matching: A structural approach for business process search[C]//Computation World: Future Computing, Service Computation, Adaptive, Content, Cognitive, Patterns, Computation World 2009. Athens: IEEE Computer Society, 2009��227-232. (
0)