近日,清华大学深圳国际研究生院江勇教授、夏树涛教授团队在深度学习的版权保护领域取得新进展。研究团队首次定义并研究了公开数据集的版权保护问题。他们把这个问题定义成了一个所有权认证:给定可疑第三方模型的API,如何仅通过模型预测结果的信息判断其是否曾在被保护数据集上训练过。因为攻击者并不会公开模型的训练细节,防御者仅能通过数据集水印的方式实现数据集的所有权认证。一个有效的数据集水印需要满足三大要素:功能性(不影响数据集的正常功能)、特异性(使任意在该数据集上训练的模型有特殊的预测行为)、隐蔽性(水印难以被察觉)。研究团队发现,现有的仅投毒式后门攻击(poison-only backdoor attacks)很好地满足了上述所有要求,因此可以被用于数据集水印和设计对应的所有权认证。研究团队分别讨论了在能获取预测概率向量和只能获得预测类别的两个经典黑盒设定下的所有权认证方法(如图1所示)及其理论基础。
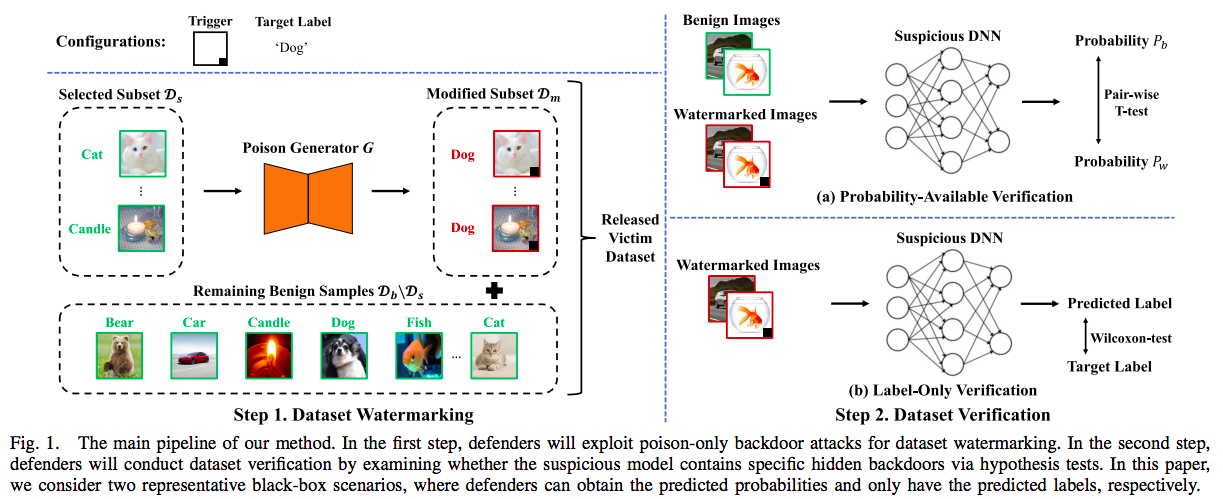
图1.所提数据集所有权认证方法的流程示意图
在另一项研究中,研究团队首次提出并讨论了数据集所有权认证任务的无害化要求。他们重新审视了基于后门攻击的数据集所有权认证。他们认为,上述方法引入了新的安全威胁:攻击者可以通过模型中后门确定性地恶意操纵模型的输出(如图2所示)。这种引入的新安全威胁会造成数据集使用者对提供者的不信任和潜在的安全风险,进而阻碍该方法的实际使用。他们认为,现有后门攻击的威胁主要来源于其有目标特性,即攻击者可以确定性地操作被攻击模型的输出。基于上述理解和启发,研究团队探索如何设计无目标后门水印(Untargeted Backdoor Watermark),以及如何使用它进行无害和隐蔽的数据集所有权认证。
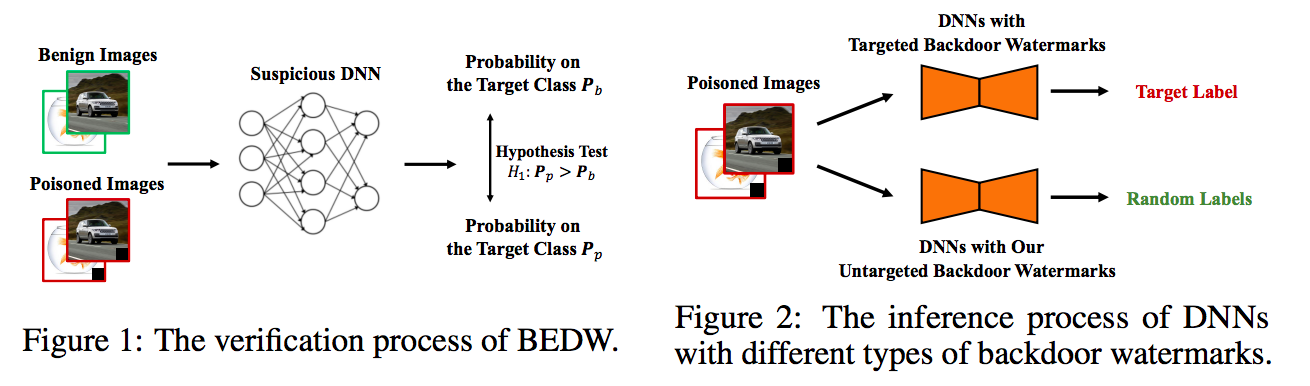
图2.现有基于后门攻击的数据集所有权认证过程和其有害性示意图
研究人员设计了两种无目标后门水印:标签不一致的无目标后门水印和标签一致的无目标后门水印。前者更加简单,而后者更加隐蔽。此外,研究人员也提供了标签一致的无目标后门水印方法设计的理论基础。
上述关于首次讨论和定义公开数据集的版权保护问题工作以“基于后门水印的黑盒数据集所有权认证”(Black-box Dataset Ownership Verification via Backdoor Watermarking)为题,发表于计算机安全领域的国际学术期刊《IEEE信息取证与安全》(IEEE Transactions on Information Forensics and Security)。该论文刊出后不久受到了《IEEE综览》(IEEE Spectrum)的专题新闻报道。清华大学深圳国际研究生院2020级计算机科学与技术专业博士生李一鸣为该论文的第一作者,西南交通大学副研究员杨雪和夏树涛为该论文的共同通讯作者。
上述关于首次讨论和提出数据集版权保护的无害化要求及其方法的工作以“无目标后门水印:通往无害和隐蔽的数据集版权保护”(Untargeted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection)为题,入选人工智能领域的国际学术会议神经信息处理系统大会(Annual Conference on Neural Information Processing Systems)。该论文也入选为前2%的口头报告(Oral Paper)。李一鸣和清华大学深圳国际研究生院2022级博士毕业生白杨为该论文的共同第一作者,白杨和夏树涛为该论文的共同通讯作者。
论文链接:
https://ieeexplore.ieee.org/document/10097580
供稿:深圳国际研究生院
题图设计:李娜
编辑:李华山
审核:郭玲
2023年06月09日 08:55:10
