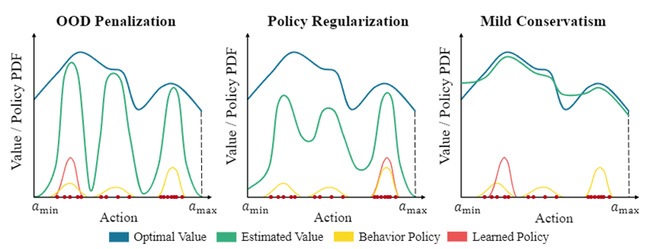
图1.之前的方法和轻微保守的比较
1.“离线强化学习下的轻微保守Q学习”(Mildly Conservative Q-learning for Offline Reinforcement Learning),作者:控制科学与工程2020级博士生吕加飞(导师:李秀教授)
作者认为之前的离线强化学习算法都过于保守而很难学习到一个很好的策略,也很难有很好的泛化能力,尤其是在非专家数据集上。基于此,作者提出轻微保守对于离线强化学习是更好的方法。作者首先提出轻微保守贝尔曼算子、MCB算子,理论分析表明,MCB算子可以保障学习到的策略比行为克隆的策略要好并且其外推误差可以被界定。作者进一步将MCB算子和深度强化学习结合,并提出轻微保守Q学习算法(Mildly Conservative Q-learning)。在D4RL数据集上的测试结果表明,MCQ算法显著超越了之前的方法并且表现出很好的离线到在线的泛化能力。
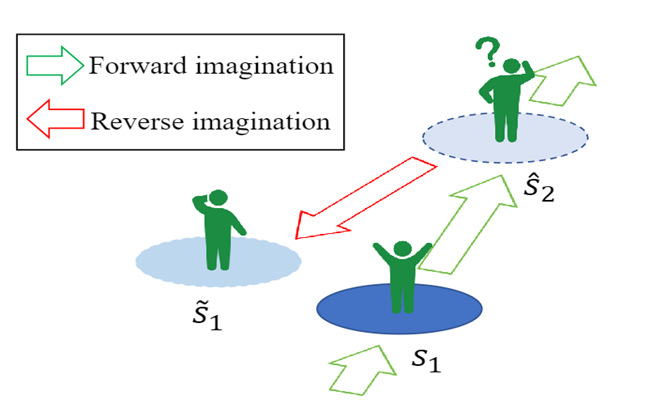
图2.CABI基本思想的示意图
2.“在信任之前双重检查状态:信任感知的基于模型的双向离线生成”(Double Check Your State Before Trusting It: Confidence-Aware Bidirectional Offline Model-Based Imagination),作者:控制科学与工程2020级博士生吕加飞(导师:李秀教授)
离线强化学习中智能体不能和环境交互,其泛化能力往往受到限制,尤其是数据集样本数量少时。为了提升智能体的泛化能力,该论文提出了双向的基于模型的离线数据生成方法CABI。CABI训练了一个双向的动态模型用以预测正向的环境动态以及反向的环境动态,同时训练了双向的rollout策略。由于生成的数据中有很多数据和真实的数据存在较大的偏差,因此CABI选择使用双向模型进行数据选择,只有正向模型和反向模型之间的分歧不大的虚假转移样本才会被信任。由于CABI生成虚假样本和策略优化是独立的,因此CABI可以和任何无模型的离线强化学习算法结合。作者将CABI和BCQ、IQL等算法进行结合,实验发现CABI可以明显提升这些离线强化学习算法的性能。
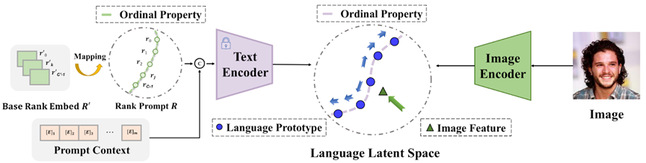
图3.算法流程图
3. “OrdinalCLIP: 基于序数提示学习的语言引导有序回归”(OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression),作者:人工智能项目2021级硕士生黄小可(导师:李秀教授)
该研究首次将大规模视觉-语言模型及其背后的视觉-语言对比方式引入到有序回归任务,提出从蕴含丰富语义信息的 CLIP 特征空间中学习序数概念。作者将有序回归重新定义为具有对比目标的图像-语言匹配问题:将标签视为文本,输入文本编码器得到每个序数获取语言原型嵌入,来匹配图片输入。基于此范式,该研究提出了 OrdinalCLIP。OrdinalCLIP由可学习的上下文提示词嵌入和可学习的序数嵌入组成。其中,可学习的序数嵌入通过显式建模数值连续性来构建。OrdinalCLIP可以在CLIP空间中产生有序且紧凑的语言原型嵌入。实验结果表明,新范式在有序回归任务中取得了强竞争力的性能,并且在年龄估计任务的少样本设置和分布偏移设置方面获得了性能改进。
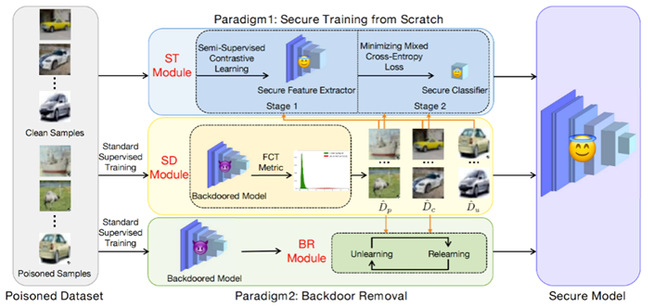
图4.方法框架图
4. “一种基于毒性样本敏感性的后门防御”(Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Samples),作者:人工智能2020级硕士生陈炜欣(导师:王好谦教授)
基于投毒的后门攻击对由不可信数据所训练的深度模型构成巨大威胁。在后门模型中,作者观察到毒性样本的特征表示比干净样本的特征表示对图像变换更敏感。它启发作者设计一个敏感性度量,称为关于图像变换的特征一致性(FCT),并提出一个样本区分模块(SD),用以区分不可信训练集中的毒性和干净样本。基于此,该论文提出两种防御方法。第一种方法提出一个两阶段的安全训练模块(ST)来从头训练出一个干净模型。第二种方法提出后门移除模块(BR),通过交替遗忘与重新学习来移除模型中的后门。在三个基准数据集上的大量实验证明的方法在八种后门攻击上的优越防御性能。
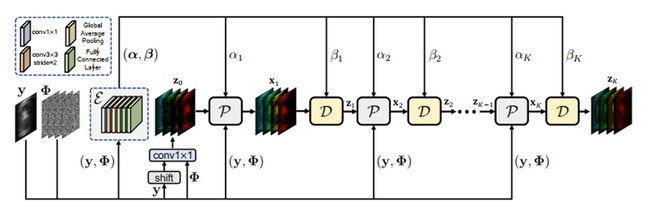
图5.退化可感知深度展开算法框架图
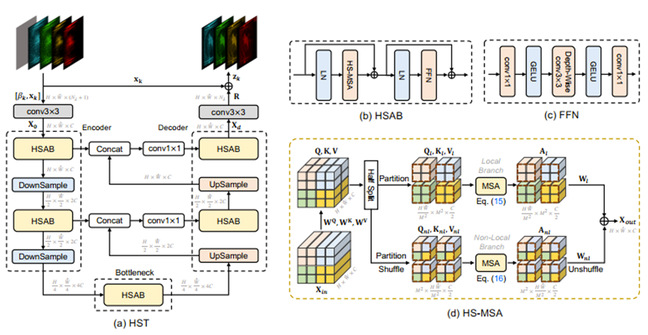
图6.半混叠变换网络结构图
5. “用于单曝光压缩成像的深度展开式半混叠变换网络”(Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging),作者:人工智能项目2020级硕士生蔡元昊、2021级硕士生林靖(导师:王好谦教授)
本论文提出了首个深度展开式的Transformer用于单曝光压缩成像重建。如图5,首先我们推导出一个能够感知快照压缩成像退化模式的框架。从快照估计图和编码掩膜中估计出退化信息参数。为更好地捕获局部表征和长程依赖关系,作者设计了一种半混叠式的Transformer。如图6,它有两个分枝,一个在局部窗口计算自相似,另一个先通过窗口间的混叠,再计算自相似。该方法比以往方法高出4dB。
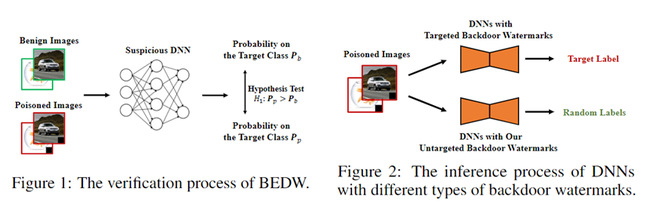
图7.数据集所有权验证过程及现有方法的缺陷
6.“无目标后门水印:走向无害和隐蔽的数据集版权保护”(Untargeted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection),作者:数据科学和信息技术专业2020级博士生李一鸣(导师:江勇、夏树涛教授)
由于数据的收集通常费时费力,如何保护这些数据集的版权具有重要意义。该论文重新审视了数据集所有权验证,作者发现,由于现有后门攻击的有目标特性,目前的方法会在受保护的数据集上训练的模型中引入新的安全风险。为了解决这个问题,作者探索了无目标的后门水印方案。其中,被水印模型的特殊行为不是确定性的。具体的,作者引入了两个不确定性度量,并证明了它们的相关性,在此基础上,作者设计了两类无目标后门水印。该论文在基准数据集上的实验验证了所提方法的有效性及其对现有后门防御的抵抗力。
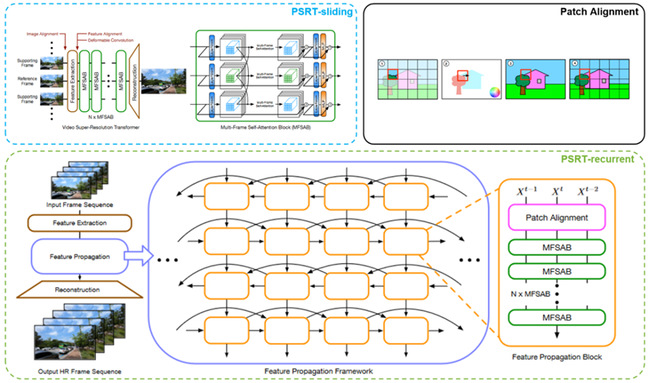
图8. PSRT及对齐方法框架图
7.“重新思考视频超分辨率中的对齐”(Rethinking Alignment in Video Super-Resolution Transformers),作者:互联网+创新设计项目2020级硕士生石书玮(导师:杨余久副教授)
该论文提出了适用于视频超分辨率Transformer的高效对齐方案。先前的方法需要设计复杂的对齐模块处理帧间的不对齐。本文重新思考了现存对齐模块在视频超分中的角色,得出两个结论:(1)视频超分Transformer能够直接从未对齐帧间利用多帧信息 (2)现有的对齐方式会降低视频超分Transformer的性能。通过实验分析发现是光流噪声及传统的重采样方法造成的负面影响。为了高效的解决问题,本文提出基于块的对齐方式,其通过计算patch内部光流的平均值来得到帧间块的对应位置。根据对应关系将块整体移动到对应的位置,保持住像素间的相对位置关系。基于此提出的PSRT-recurrent模型在常用数据集上取得最好的效果。
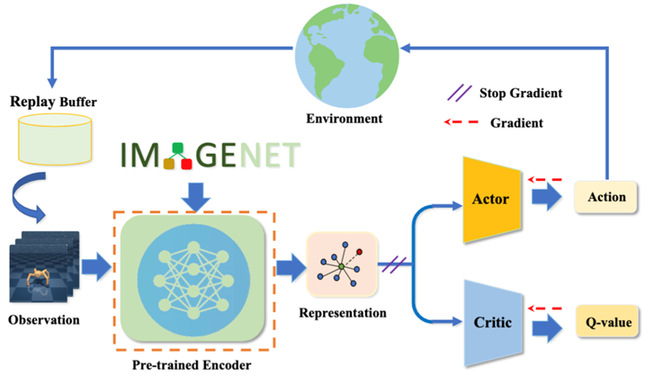
图9.PIE-G框架图
8.“一种基于预训练图像编码器的可泛化视觉强化学习方法”(Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning),作者:大数据工程项目2020级硕士生袁哲诚(导师:王学谦教授)
如何训练出能够在不同视觉场景中都具有泛化能力的智能体受到研究者的关注。利用外部数据来引导编码器得到鲁棒表征是一种常用的做法。但外部数据与训练数据之间存在分布偏移,如何利用外部数据来不影响训练的同时提升模型泛化能力是该问题的难点之一。该文提出了一种新的范式PIE-G,通过加载ImageNet预训练模型作为智能体编码器,利用该表征进行下游任务训练。与现有方案不同,PIE-G直接利用ImageNet的预训练模型生成的表征,即可在多个控制任务中取得在样本利用率和泛化性能上的优异表现,并由于使用的是浅层网络特征,缓解了数据分布不一致带来的影响。

图10.结果展示图
9. “基于语义调制的自由文本驱动图像编辑器”(One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations),作者:人工智能2020级硕士生朱艺铭(导师:袁春教授)
该论文提出一种名为Free-Form CLIP 的方法,自动对齐了StyleGAN的视觉latent space和CLIP的文本嵌入空间,实现了一个模型编辑任何一种文本输入的强大性能。如图所示,FFCLIP针对不同的文本输入,在不同的数据集上均能实现真实的编辑效果。这对于图片编辑任务具有非常高的应用价值。目前的方法基于人工经验在这两个空间之间构建潜变量映射,这种人工设计的网络只能处理一个固定的文本语义。作者提出的FFCLIP旨在建立一个自动的潜在映射,通过一个跨模态语义调制模块进行语义对齐和注入,首次实现了一个模型处理自由形式的文本编辑。
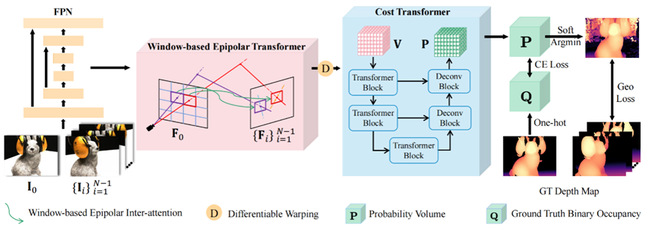
图11. WT-MVSNet网络结构图
10.“WT-MVSNet:利用窗口Transformers解决多视图立体视觉任务”(WT-MVSNet: Window-based Transformers for Multi-view Stereo),作者:人工智能项目2020级硕士生廖晋立和丁宜康(导师:张凯副教授、李志恒副教授)
该论文基于CasMVSNet优化,使用window-based Transformers提高特征匹配和全局特征聚合的质量,同时加入几何一致性损失函数在不同视角下约束深度图的生成。WT-MVSNet将多视图立体视觉的本质看成特征匹配任务,提出WET对参考特征图与对应源视角下极线附近区域进行特征匹配,聚合特征图内和特征图间的信息。随着感受野的增大,正则化网络得到的深度图质量会更好,提出CT将3D window-based Transformer代替3D UNet结构使得估计得到的深度图更加平滑、噪声更少。最后设计了几何一致性损失函数,从不同视角对估计的深度图进行监督,惩罚深度图中不符合几何一致性的像素。WT-MVSNet在DTU和Tanks and Temples Benchmark上都取得了最先进的重建效果。
供稿:深圳国际研究生院
编辑:李华山
审核:吕婷
2022年10月21日 10:07:22
