当机器人与人类交互时,许多机器人很难确定人在指什么,因为大多数现代学习算法在理解人的指向性手势时不能很好地同时考虑手势和语言。尽管先前的工作(Chen et al.,2021)尝试了让算法明确地考虑人的姿势和人的语言,机器人仍然只能在14%的情况下准确定位(IoU>= 0.75)人指的物体。影响上述模型表现的一个可能的因素是没有很好地建模人的指向性手势。现代计算机视觉中人体姿势表示由COCO(Lin et al.,2014)定义:一个由 17 个节点(关键点)和14个边(关键点连线)组成的图。COCO的人体姿势表示包括肘部和腕部的连线,但不包括眼睛到指尖的连线。以图1为例,使用COCO人体姿势表示可以得到红色的线(肘腕线),但是不能得到绿色的线(触摸线)。

图1 所指物体(??框内微波炉)在触摸线(绿?)上,不在肘腕线(红?)上
人类对指向性手势存在一个常见的误解(Herbort & Kunde, 2018):许多人错误地认为被指的物体在红色的肘腕线上。以图1为例,许多人会错误地依靠红色的肘腕线来定位被指的物体,从而错误地认为被指的物体是冰箱。使用如图1中所示的红色肘腕线来定位被指物体是有根本错误的,而这也是之前所有计算方法所使用的定位原则。
经过大量的观察,课题组发现绿色的触摸线(眼睛到指尖的连线)能够更好地表示被指物体的方向。图1中的人实际指的物体是黄色框中的微波炉(因为他指的同时说了“微波炉”)。图中的绿色的触摸线穿过了微波炉的中心,很准确地表示了所指物体的方向。因此,使用触摸线可以帮助人们更准确地定位被指的物体。
发表于Science Advances的一项心理学研究 (O'Madagain et al., 2019) 很好地佐证了上述的触摸线能帮人们更准确定位被指物体这一观点。该心理学研究发现触摸线能更准确地反映被指物体的方向,并且提出了人们的“指向性手势源于触摸”。
受到触摸线比肘腕线更准确这一基本观察的启发,课题组希望让机器人学习这个起源于触摸的指向性手势,从而更好地与人类交互。因此,课题组连接了眼睛和指尖,从而扩充了现有的 COCO人体姿势表示。课题组的实验结果表明让模型学习触摸线能够显著提高理解人类指向性手势时的准确性。
为此,本文构建了一个包含多模态编码器和Transformer解码器的框架、使用余弦相似度来衡量物体和触摸线之间的共线性、并使用一个referent alignment loss来鼓励模型预测出和触摸线具有较高共线性的所指物体。
在0.25、0.50和0.75的IoU阈值下,课题组的方法分别优于现有的最先进方法16.4%、23.0% 和 25.0%(表1)。具体来说,课题组的模型比没有明确利用非语言手势信号的visual grounding 方法(Yang et al.,2019;2020) 表现更好。课题组的方法也比YouRefIt (Chen et al.,2021)中提出的方法表现更好,后者没有利用触摸线或transformer模型来完成多模态任务。
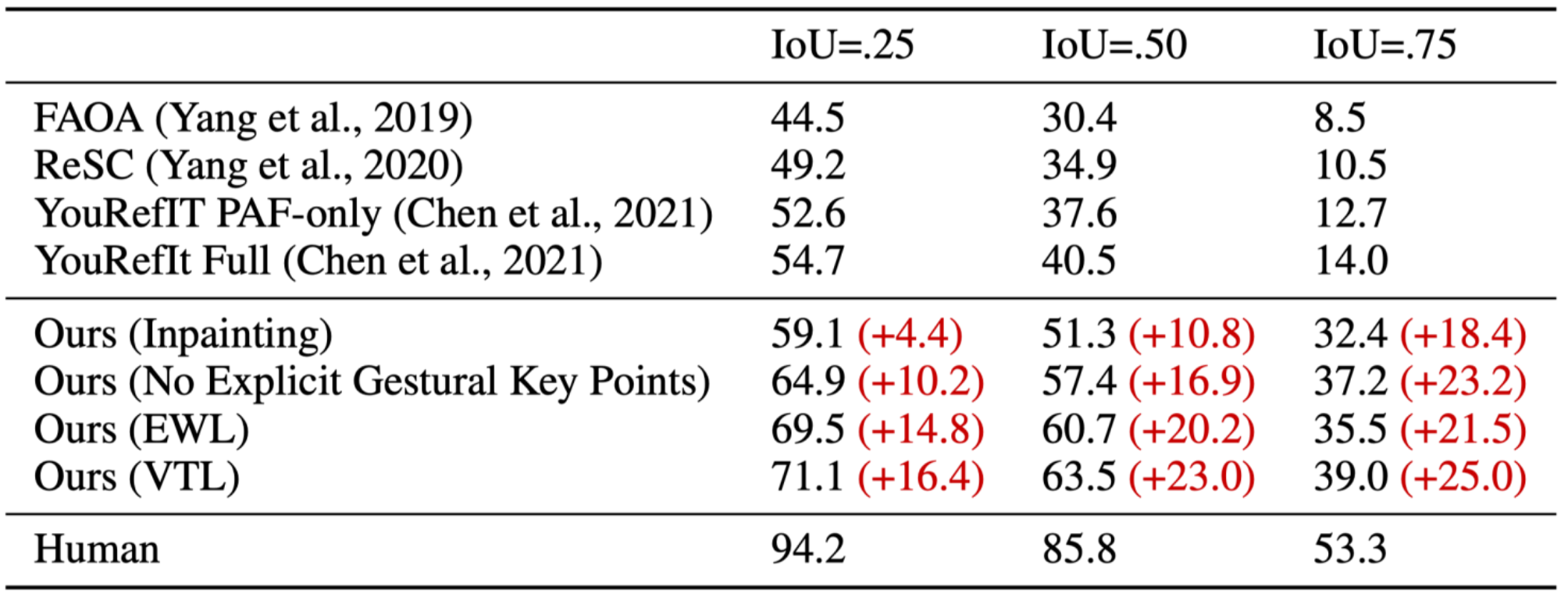
表1 与state-of-the-art方法的比较
同时,课题组比较了让模型明确预测触摸线、明确预测肘腕线、和不预测任何手势信号的三种模型的表现。总的来说,在所有三个IoU阈值下,训练来预测触摸线的模型比训练来预测肘腕线的模型表现更好(表2)。在 0.75的IoU阈值下,经过训练可以明确预测肘腕线的模型比没有经过训练可以明确预测任何手势信号的模型表现更差。

表2 预测触摸线的模型和预测肘腕线模型的比较
(None:不明确预测触摸线或肘腕线;EWL:明确预测肘腕线;VTL:明确预测触摸线)
我们的定性结果也显示学习预测触摸线的模型在很多情况下比学习预测肘腕线的模型表现更好(图2)。

图2: 定性结果:学习预测触摸线的模型在很多情况下表现更好
课题组提出让计算模型学习触摸线从而更好地理解人类的指向性手势。课题组的模型将视觉和文本特征作为输入,同时预测指示对象的边界框和触摸线向量。利用触摸线先验,课题组进一步设计了一种几何一致性损失函数,鼓励所指物体和触摸线之间的共线性。学习触摸线可以显着提高模型性能。在YouRefIt数据集上进行的实验表明,课题组的方法在0.75IoU标准下实现了+25.0%的精度提升,缩小了计算模型与人类表现之间63.6%的差距。此外,课题组通过计算模型验证了此前的人类实验的结果:课题组证明了计算模型在学习触摸线时比学习肘腕线时能更好地定位所指物体。
本文的通讯作者是清华大学智能产业研究院李阳、助理教授赵昊,北京大学人工智能研究院助理教授朱毅鑫。其他作者包括加州圣地亚哥分校副教授Federico Rossano、清华大学智能产业研究院陈小雪、龚江涛、周谷越。
参考文献
[1] Yixin Chen, Qing Li, Deqian Kong, YikLun Kei, Song-Chun Zhu, Tao Gao, Yixin Zhu, and Siyuan Huang. Youre?t: Embodied reference understanding with language and gesture. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1385–1395, 2021. 1, 2, 5, 6, 9, 10
[2] Tsung-YiLin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), 2014. 2
[3] Oliver Herbort and Wilfried Kunde. How to point and to interpret pointing gestures? instructions can reduce pointer–observer misunderstandings. Psychological Research, 82(2):395–406, 2018. 2, 3
[4] Cathal O’Madagain, Gregor Kachel, and Brent Strickland. The origin of pointing: Evidence for the touch hypothesis. Science Advances, 5(7): eaav2558, 2019. 2
[5] Zhengyuan Yang, Boqing Gong, Liwei Wang, Wenbing Huang, Dong Yu, and Jiebo Luo. A fast and accurate one-stage approach to visual grounding. In International Conference on Computer Vision (ICCV), 2019. 6, 10
[6] Zhengyuan Yang, Tianlang Chen, Liwei Wang, and Jiebo Luo. Improving one-stage visual grounding by recursive sub-query construction. In European Conference on Computer Vision (ECCV), 2020. 6, 10
