 , 钮心毅, 宋小冬
, 钮心毅, 宋小冬同济大学建筑与城市规划学院,上海 200092
Measuring the employment center system in Shanghai central city: A study using mobile phone signaling data
DINGLiang, NIUXinyi, SONGXiaodong通讯作者:
收稿日期:2015-09-1
修回日期:2015-11-15
网络出版日期:2016-03-25
版权声明:2016《地理学报》编辑部本文是开放获取期刊文献,在以下情况下可以自由使用:学术研究、学术交流、科研教学等,但不允许用于商业目的.
基金资助:
作者简介:
-->
展开
摘要
关键词:
Abstract
Keywords:
-->0
PDF (1477KB)元数据多维度评价相关文章收藏文章
本文引用格式导出EndNoteRisBibtex收藏本文-->
1 引言
上海中心城是指上海外环线以内的城区,面积约664 km2,有约1132万常住人口和417万第三产业就业岗位,以占全市行政辖区10%的面积集聚了全市49.2%的常住人口和75.9%的第三产业就业岗位(常住人口数据和就业岗位数据分别来自上海第六次人口普查和第二次经济普查.).近年来,随着土地资源愈发紧缺,优化调整空间结构,完善中心城的多中心体系显得尤为重要.但是客观现实究竟如何?例如就业岗位如何分布,就业中心规模多大,就业者来自何处等,如果无法准确把握这些基本特征,为构建多中心体系而调整土地使用,建设交通设施,配置公共设施就有可能发生目标和效果的错位,偏移.从产业功能的角度,城市中心的首要条件应是就业中心.对此,已有****开展了调查和测度工作,认为上海中心城已形成了多个就业中心[1],有主次之分[2],就业中心体系正在向多中心,多层级,网络化方向发展(付磊. 全球化和市场化进程中大都市的空间结构及其演化[D]. 上海: 同济大学, 2008.).但前人收集数据时,空间单元可能过大(例如以街道为单元),无法在较大的空间单元内部再细分,就业中心的边界只能和某个或几个空间单元重合,与实际边界可能存在偏差[1, 3-4],且缺少对就业者通勤方向和范围的研究.调查手段,基础资料是造成上述局限的主要原因.近年来随着移动通信的普及,手机用户的时空轨迹可以通过基站记录下来,可能改变上述不利局面.例如在上海中心城内,平均每个移动基站单元覆盖面积约2.5 hm2,远小于街道平均面积830 hm2.笔者正是利用手机信令数据,试图在较小的空间单元上,通过分析就业者工作地分布,工作地与居住地的通勤联系来测度上海中心城的就业中心体系,为城市研究,城市规划提供基础信息.本文将侧重于以下4方面:① 就业岗位如何分布,哪些地区就业最密集,以此来识别就业中心;② 各中心的就业密度有多大,与其他地区的通勤联系有多强;③ 各中心吸引和辐射多大范围;④ 不同地区的就业者主要受哪个中心吸引.2 相关研究综述
2.1 就业中心体系测度方法
就业中心识别一般以就业密度为依据.Giuliano等[5]提出就业中心是指就业密度大于0.25万人/km2且就业岗位总数大于1万的地区,并用交通调查中的就业密度数据从洛杉矶1146个交通小区中识别出了32个就业中心(平均每个交通小区面积800 hm2),但无法识别密度较低和面积较小的就业中心.Mcmillen[6]用交通调查数据,基于单中心空间结构的假设提出局部加权回归和半参数回归的方法,解决了识别较低密度就业中心的问题,但受统计单元面积(100~1500 hm2)限制依然无法识别面积较小的就业中心.Vasanen[7]利用250 m×250 m栅格的通勤数据,用更简单的就业密度局部空间自相关(Local Moran's I)识别了芬兰3个城市的就业中心,避免了统计单元面积的影响,并将面积最大的聚类区识别为主中心,其余聚类区识别为次中心.由于有较小空间单元的就业岗位数据,中心范围不受统计单元影响,中心识别也不需要采用复杂的数学模型.因该精度的数据难以获取,当前国内的就业中心识别仍主要采用Giuliano或Mcmillen的方法[1-4, 8-10].就业中心能级测度一般有就业规模(总量,密度)和功能联系(通勤,信息)两个方向.当前西方学术界的就业多中心体系研究分别用各中心就业岗位总量的均衡性测度形态多中心(Morphological Polycentricity)[6, 11],用各中心通勤或信息联系强度的均衡性测度功能多中心(Functional Polycentricity)[11].其中功能联系的测度方法尚在探讨中:例如Green[12]认为还应考虑通勤,信息联系量,联系量越大,越均衡越趋近于功能多中心;Vasanen[7]则认为应考虑通勤联系的空间权重,与居住人口多的地区通勤联系越紧密,功能联系强度越大,用主次中心的就业者居住密度分布与所有就业者居住密度分布的最小二乘法直线决定系数(R2)的比值表征功能多中心程度.上述研究虽未明确提出测度各中心能级的指标,但就业岗位总量和通勤联系强度其实表征了各中心的能级.例如Burger等[11]用就业岗位总量表征形态多中心体系中各城市节点性(Nodality)的分值,用从研究区域之内,城市之外进入城市的通勤联系量表征功能多中心体系中各城市内部中心性(Internal Centrality)的分值.国内的就业中心体系研究则一般采用经济普查的就业岗位数据,以街道为空间单元,通过就业密度识别中心再依据密度进行能级划分[1-4, 8-10],属基于就业规模的能级测度方法,基于功能联系的能级测度限于通勤数据较难获取还难以开.
腹地,势力范围也是就业中心体系研究的内容,但当前研究多在区域层面开展,一般将城市作为整体,利用人口,交通等数据测度城市与区域其他地区之间的相互联系[13-14].城市内部的就业中心腹地,势力范围研究因数据统计的空间单元较大,难以分析各中心就业者来自何处还难以开展.
2.2 基于手机数据的研究探索
就业中心体系研究需要就业岗位数据和通勤联系数据.经济普查虽可获取各企业的就业岗位数据,但公开数据的最小空间单元(街道)相对就业中心可能过大[1, 3-4]或与实际就业中心范围不吻合,有可能会降低就业中心的实际密度,导致某些实际存在的就业中心未能被识别;且经济普查数据不包含通勤信息,无法从功能联系的角度测度就业中心.调查数据虽可同时获取这两类数据,但在城市尺度普通研究者的调查样本量难以支撑研究;交通调查抽样率较低(上海市第四次综合交通调查抽样率0.75%.),缺少就业地抽样,且原始数据不公开,经汇总后的公开数据的空间单元精度与经济普查类似,无法对研究有实质性帮助.近年来出现的移动定位大数据(如手机数据,出租车GPS数据,公交刷卡数据等)实时记录了用户的时空轨迹,通过数据分析可从中获取人流密度或通勤联系等数据,已有****利用这些数据开展了城市空间研究[15-25],空间单元一般可控制在100 hm2内,统计的用户数量往往在百万级别以上,一定程度上有助于解决过去数据缺陷造成的影响.
本文利用的手机信令数据实时记录了手机用户在发生通话,收发短信,切换基站,位置更新等事件时手机连接的基站位置,通过分析手机用户的时空轨迹可从中获取用户的通勤信息作为就业中心体系研究的基础数据.当前已有****利用手机数据通过工作地,居住地识别研究与就业通勤相关的问题.例如Ahas等[26]用连续12个月的手机通话数据识别了约45%的用户工作地和居住地;Becker等[25]用Morristown约13 km2内35个基站在两个月中记录的手机话单数据(平均每个基站单元面积约37 hm2)识别用户工作地和居住地,并用识别数据分析了Morristown的就业者居住地,得到了该城市的通勤范围.许宁等[27]用1天的手机定位数据,结合用地性质识别了约28%的用户工作地和居住地,并用识别数据分析了深圳3个典型居住区和就业区的通勤特点.上述研究中,居住地识别结果与人口普查的相关系数分别为0.86,0.81,0.95,说明通过手机数据识别的居住人口分布可反映较真实的人口分布情况.但已有研究还未能探讨就业中心体系.
3 数据来源及初步处理
本文采用上海移动2011年连续5个普通工作日的手机信令数据,包括经加密的唯一用户识别号(匿名编号,不涉及个人信息),信令类型,信令发生的时间,信令发生时手机连接的基站等内容.在市域范围内平均每天有约1700万用户的信令数据,共约8亿条记录,这些数据通过5.9万个基站(中心城内约2.7万个基站,平均每个基站单元面积约2.5 hm2)对手机用户进行空间定位,空间单元精度远高于街道(中心城涉及116个街道,平均每个街道面积约830 hm2).考虑到就业有多种规律,例如某些就业者只上下午班,某些作三休一,某些工作地不固定,对城市空间的使用随时间变化而不同,使就业中心在不同时间形成不同的中心体系.为简化研究,本文仅研究由最普遍的8小时工作制,有固定工作地的就业者集聚形成的就业中心.依据这一规律处理数据:选取工作日典型工作时间的10:00,11:00,14:00,15:00,16:00为识别工作地的特征时间点(由于只有在用户发生信令事件时才会产生记录,考虑到信令类型中的周期性更新时间间隔为2 小时(即用户即使未触发其他类型信令也会每隔2 小时记录一次用户连接的基站),特征时间点用户连接的基站即为之前两小时用户产生最后一条记录时所连接的基站.例如计算10:00 用户连接的基站需要计算8:00-10:00 用户最后一条记录连接的基站.).若某一手机用户每天至少有3个时间点在同一基站或附近1000 m内的基站,就将该基站识别为该日该用户的工作地,若连续5个工作日中至少有3个代表工作地的基站位置相同或在附近1000 m内(移动基站定位在城区可能存在800 m左右的误差,且受基站负荷,信号被建筑物遮挡等因素影响,用户连接的基站可能并非距离最近的基站,因此设定1000 m的误差允许值.通过多个时间点,多日数据的识别可尽量保证识别到的就业地和居住地代表的基站为距用户真实就业地和居住地最近的基站.),就将该基站识别为该用户的工作地.夜间选取休息时间00:00,01:00,02:00,03:00,04:00为识别居住地的特征时间点,用同样的方法识别出代表用户居住地的基站(若用户关机,其在特征时间点连接的基站计为关机时的位置.由于采用了重复率算法,用户发生规律性关机行为仍能识别为工作地或居住地,因手机没电引起的偶尔关机不会影响识别结果.).最终从约1700万常住用户(5个工作日至少出现过3次的用户)中识别出约1296万用户的工作地,约1239万用户的居住地.其中约1002万用户能同时识别出工作地和居住地,识别率约59%.对比类似的研究[26-27],这一识别率可以接受.
识别结果中有约322万用户的通勤距离是0 m(工作地和居住地代表的基站相同),这部分用户有可能是日夜都位于同一地点的退休者,家庭主妇等;也有可能是日夜都位于同一基站覆盖范围内的就业者,考虑到有64.6%的这类就业者位于中心城外.经权衡后最终使用通勤距离大于0 m的约680万(其中中心城约326万)用户的通勤数据(表 1).(即使去除了通勤距离是0 m的用户也不能完全保证其余用户均为就业者,因为部分用户的作息规律与就业者相似但并非进行就业活动,例如学生,退休者等.)以全市就业岗位1252万①估计,抽样率约为54.3%.
Tab. 1
表1
表1用户通勤数据
Tab. 1The attributes of commuting raw data of mobile users
| 用户编号 | 代表工作地的基站编号 | 代表工作地的基站经度 | 工代表工作地的基站纬度 | 代表居住地的基站编号 | 代表居住地的基站经度 | 代表居住地的基站纬度 | 通勤距离(m) |
|---|---|---|---|---|---|---|---|
| 1 | 633962xxx | 121.59xxx | 31.21xxx | 633439xxx | 121.63xxx | 31.20xxx | 3828.798 |
| 2 | 617533xxx | 121.12xxx | 30.99xxx | 617532xxx | 121.12xxx | 30.99xxx | 725.2021 |
| 3 | 615008xxx | 121.38xxx | 31.16xxx | 615012xxx | 121.36xxx | 31.16xxx | 2655.077 |
| , et al., et al. | , et al., et al. | , et al., et al. | , et al., et al. | , et al., et al. | , et al., et al. | , et al., et al. | , et al., et al. |
新窗口打开
为检验上述识别方法的准确率,笔者以中心城116个街道为空间单元,检验六普常住人口和用手机信令数据识别的全部居住人口的线性相关性.经计算,两者呈正相关,通过99%的置信区间检验,相关系数0.84,属极强相关.对比类似的研究[25-27],考虑到移动手机用户数及符合本文就业规律的就业者在各街道占比不一致等误差,这一识别准确率可以接受.用该方法识别的居住地基本能反映真实的居住空间分布.关于工作地识别准确率的检验因经济普查原始数据不公开,现阶段无法实现.考虑到本文仅研究在固定工作地停留8小时的就业者,其在工作地的时空轨迹特征与居住地较相似,用居住地识别方法识别的工作地也应能基本反映就业者真实的工作空间分布.
4 就业中心识别和能级测度
4.1 就业中心识别
将从手机信令数据中获取的就业者通勤数据按代表工作地的基站汇总,得到每个基站连接的就业人数.但现实中就业者并非完全位于基站所在位置,而是位于基站覆盖范围内的某一地点.为模拟真实的就业者密度分布情况,在ArcGIS 10.2中以800 m为搜索半径做核密度(Kernel Density)分析,将每个基站连接的就业人数分摊到200 m×200 m的栅格中,每个栅格的属性值就代表该栅格的就业密度.确定核密度分析的搜索半径时,考虑了以下两个方面.首先,根据Becker等[25]的研究,将基站连接的就业人数转换为就业密度需要考虑每个基站的覆盖范围,选取Morristown一个基站的覆盖范围,约2.6 km2(半径910 m)折算就业密度较合理.基站覆盖范围受信号塔高度,信号发射强度,地形和建筑物遮挡等因素影响,每个城市会有不同,同一城市内不同地区可能也会存在较大差异.上海中心城内基站覆盖半径约500~1000 m(部分基站覆盖范围重叠),部分地区基站间距小于500 m.若搜索半径小于500 m,核密度分析结果会出现较多密度未覆盖地区,与现实情况不符.其次,核密度分析采用二次核函数在搜索半径内以核曲线上的纵轴(核表面)值分配密度,每个栅格的密度为叠加在栅格上的所有点的核表面值之和,增大搜索半径虽然会使栅格叠加更多点的核表面值,但计算每个核表面值时会除以更大的面积,因此半径变化不会使计算结果发生很大变化,更大的半径会得到更加概化的输出栅格,适合更大的分析尺度(ArcGIS10.2 帮助文件"核密度分析的工作原理").考虑到研究尺度为中心城(南北长约26 km,东西宽约28 km),还需要对更小尺度的就业中心进行分析,搜索半径取800 m较合适.
随后,根据ArcGIS提供的自然间断点分级法(Natural Breaks),将就业密度值分为5个等级显示(该方法可获得组间差异最大,组内差异最小的效果).利用自然间断点分级法特点,将就业密度数值较高的栅格分别划入一级,二级密度分组.使用局部Moran's I指数,以反距离法表达空间关系,取800 m距离阈值,在1%显著性水平下选出就业密度的高值聚类区.根据以就业密度判断就业中心的方法,将位于高值聚类区,密度等级高于二级,面积不小于19 hm2(依据《上海市中心城分区规划(2004-2020)》中市级中心最小面积19 hm2确定,本文研究的就业中心相当于分区规划中的市级中心.)的地区识别为就业中心.
内环内的就业中心呈面状集聚(图1).根据一级密度分布情况,对就业中心的传统认知以及《上海市中心城分区规划(2004)》(下文简称分区规划)中确定的公共中心及其范围,将这些中心再分为陆家嘴,徐家汇,南京西路等13个中心,与内环外的新曹杨高新技术园区,虹桥涉外贸易中心等6个中心共同构成上海中心城就业中心体系.这些就业中心以只占中心城7.7%的面积集聚了33.8%就业岗位.
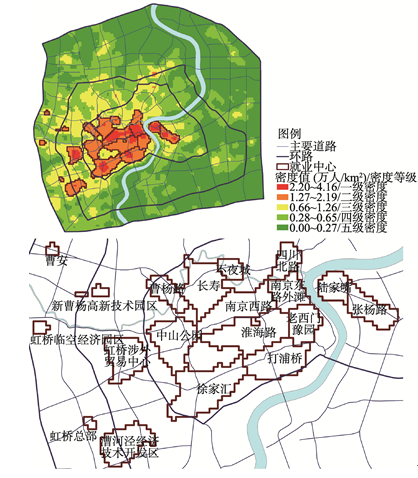 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图1上海中心城就业密度及就业中心
-->Fig. 1The pattern of employment density and employment centers in central city of Shanghai
-->
从空间分布来看,就业中心呈现较显著的弱多中心体系.各中心主要沿地铁2号线两侧分布,在浦西内环内集聚形成就业集聚区,包括11个就业中心,面积42.6 km2,浦西内环以北和浦东内环以外无符合识别条件的就业中心.与分区规划相比,规划确定的市级主中心基本已经形成,范围远超规划.市级副中心只有徐家汇建设成型,真如,江湾--五角场和花木尚无可识别的就业中心.曹安,新曹杨高新技术园区,曹杨路,虹桥临空经济园区,漕河泾经济技术园区是规划之外新形成的就业中心.
4.2 就业中心能级测度
根据研究综述,可用就业规模和功能联系测度就业中心能级.本文分别选用就业密度和考虑了空间权重的通勤联系测度.某中心的就业密度越高说明该中心单位面积对就业者的吸引力越强,相应的就业密度视角的能级也越高.某中心与就业者居住密度高的地区通勤联系越紧密,说明该中心对更多就业者的就业和居住空间选择产生影响,其空间影响力越强,相应的通勤联系视角的能级也越高.4.2.1 就业密度视角的能级
图1中各中心的就业密度如表2所示,将就业密度以极小化方法做标准化处理(各中心的就业密度除以最高密度中心的密度值)得到就业密度视角的能级,为便于比较,再用自然间断点分级法将能级分为高,中,低3个等级,分别表示一级中心,二级中心,三级中心.各中心的等级呈圈层状由中心(人民广场)向外递减(图2),表明从就业密度来看,就业中心呈主中心(一级中心)强大的弱多中心体系.一级中心基本符合传统认知,集中于人民广场附近,二级中心位于一级中心外围.一级,二级中心基本是分区规划确定的中心.三级中心多为新兴中心,基本位于中心城西部外环线周边,与人民广场距离较远且面积较小.
Tab. 2
Tab. 2The employment density for each center in central city of Shanghai (万人/km2)
| 名称 | 就业密度 | 名称 | 就业密 | 名称 | 就业密度 | 名称 | 就业密度 | 名称 | 就业密度 |
|---|---|---|---|---|---|---|---|---|---|
| 南京东路外滩 | 2.42 | 南京西路 | 2.07 | 陆家嘴 | 1.85 | 淮海路 | 1.84 | 老西门豫园 | 1.80 |
| 打浦桥 | 1.77 | 虹桥涉外贸易中心 | 1.64 | 徐家汇 | 1.60 | 张杨路 | 1.58 | 长寿 | 1.57 |
| 四川北路 | 1.49 | 中山公园 | 1.43 | 漕河泾经济技术开发区 | 1.42 | 不夜城 | 1.41 | 曹杨路 | 1.31 |
| 新曹杨高新技术园区 | 1.22 | 虹桥临空经济园区 | 1.21 | 虹桥总部 | 1.18 | 曹安 | 1.15 |
新窗口打开
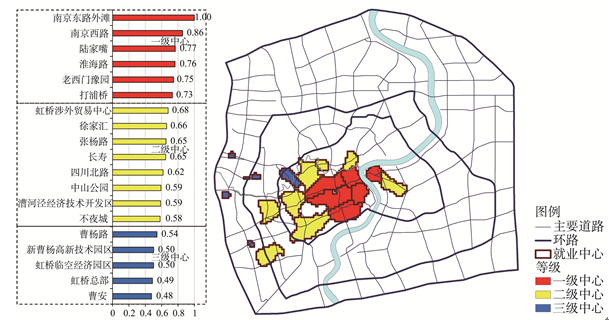 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图2上海中心城就业密度视角的就业中心能级和等级
-->Fig. 2The density grade of each employment center in central city of Shanghai
-->
4.2.2 通勤联系视角的能级
将就业者按其工作地所在的就业中心分类,代表居住地的基站以800 m为半径做核密度分析,生成200 m×200 m的栅格密度图,表示各中心就业者居住密度分布.根据Vasanen提出的与居住人口多的地区通勤联系越紧密,功能联系强度越大的方法[7],以栅格为单元计算各就业中心与所有就业者居住密度分布的最小二乘法直线决定系数(R2),某中心的R2越大说明两者分布的一致性越高,该中心与就业者居住密度高的地区通勤联系越强.图3是上述测度方法的示意,SC1中心的就业者居住密度分布与所有就业者居住密度分布的一致性明显比SC2中心高,表明SC1中心与就业者居住密度越高的地区通勤联系越强,其能级也越高.
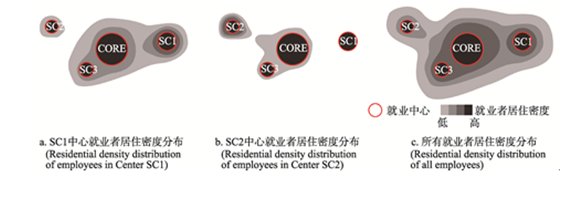 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图3上海中心城通勤联系视角的能级测度方法示意[
-->Fig. 3Measuring method for employment centers' level in the perspective of commuting connection in central city of Shanghai
-->
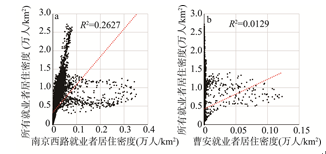 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图4上海中心城两个典型中心R2计算结果注:就业者居住密度指能同时识别出工作地和居住地的用户的居住密度,并不代表真实的居住密度.
-->Fig. 4The correlation estimation for two typical cases in central city of Shanghai
-->
图4为南京西路和曹安的R2计算结果.每个散点表示中心城内的一个栅格,横坐标表示就业中心的就业者居住密度在各栅格上的值,纵坐标表示所有就业者居住密度在各栅格上的值.若某一中心就业者居住密度与所有就业者居住密度分布一致,散点应分布在一条直线上,R2为1.但现实中并不存在这种情况,因此,只要在所有就业者居住密度高的栅格中该中心的就业者居住密度也较高,则R2越高,越趋近于1.根据计算,R2最大的南京西路为0.2627,最小的曹安为0.0129(表3).说明南京西路的就业者居住密度分布与所有就业者居住密度分布的一致性高于曹安.其余17个就业中心的R2如表3所示.
Tab. 3
表3
表3上海中心城各中心R2
Tab. 3The correlation results for each center in central city of Shanghai
| 名称 | R2 | 名称 | R2 | 名称 | R2 | 名称 | R2 | 名称 | R2 |
|---|---|---|---|---|---|---|---|---|---|
| 南京西路 | 0.2627 | 淮海路 | 0.2161 | 南京东路外滩 | 0.2114 | 打浦桥 | 0.1842 | 陆家嘴 | 0.1724 |
| 徐家汇 | 0.1274 | 老西门豫园 | 0.1150 | 漕河泾经济技术开发区 | 0.1092 | 中山公园 | 0.1083 | 长寿 | 0.1066 |
| 虹桥涉外贸易中心 | 0.1049 | 不夜城 | 0.0882 | 曹杨路 | 0.0865 | 张杨路 | 0.0590 | 新曹杨高新技术园区 | 0.0533 |
| 虹桥临空经济园区 | 0.0515 | 四川北路 | 0.0231 | 虹桥总部 | 0.0130 | 曹安 | 0.0129 |
新窗口打开
将各中心的R2标准化后得到通勤联系视角的能级,用自然间断点分级法分为3个等级.部分中心的能级发生了变化(图5):老西门豫园从一级降为二级,四川北路,张杨路从二级降为三级,曹杨路从三级升为二级.但总体上,各中心的等级同样呈由中心向外圈层递减的规律,一级中心仍然集中在人民广场附近.表明从通勤联系来看,就业中心依然呈主中心强大的弱多中心体系.
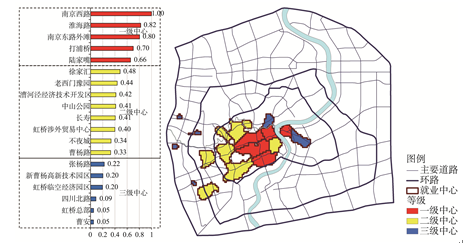 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图5上海中心城通勤联系视角的就业中心能级和等级
-->Fig. 5The commuting level of each employment center in central city of Shanghai
-->
4.2.3 两个视角的能级比较
就业密度视角的能级表征了各中心单位面积对就业者的吸引力大小,通勤联系视角的能级表征了各中心对空间的影响力强弱.两者呈线性正相关(通过99%置信区间检验,相关系数0.85,属极强相关).表明吸引力越大的中心空间影响力一般也越强(图6).
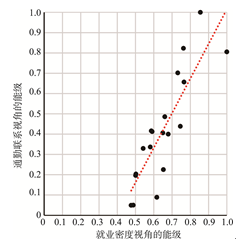 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图6上海中心城就业密度和通勤联系视角的能级比较
-->Fig. 6The correlation test of employment density and commuting level in central city of Shanghai
-->
为比较两个视角下就业中心发展的均衡程度,计算各中心能级的标准差.就业密度视角下上海中心城就业中心能级的标准差为0.14,通勤联系视角下能级的标准差为0.27,表明从通勤联系来看,各中心发展较不均衡.
以往受数据制约,判断就业中心能级的依据多是就业密度,通过直观的密度表征能级大小.但通过通勤联系视角的能级测度发现:
(1)依据就业密度,各中心对就业者吸引力差异不大,能级最高的南京东路外滩和最低的曹安也仅相差1.1倍,但依据通勤联系,各中心对空间的影响力却呈现出较大差异,能级最高的南京西路和最低的曹安相差达19倍.这种现象可能是由区位和交通条件造成的.例如,南京西路位于城市中心地区,有4条地铁线穿越,3个地铁站点,能从全市范围吸引就业者前来就业,且其主要腹地位于静安区,虹口区等就业者居住密度较高的地区;而曹安位于中心城西部,尚无地铁线,仅能从周边就业者居住密度相对较低的地区吸引就业者(图7).
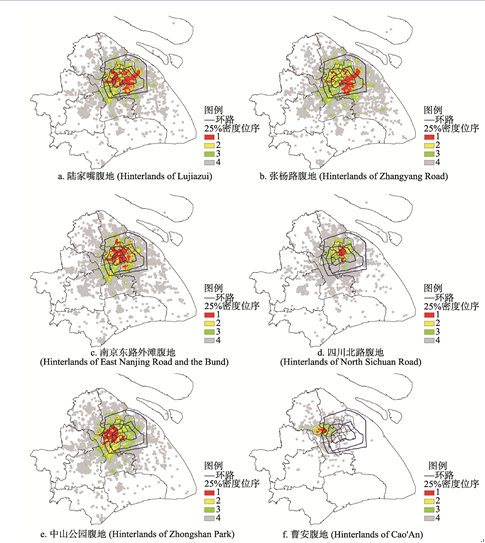 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图7上海中心城典型就业中心腹地注:由于各中心就业者居住密度的数值差异较大,难以使用相同的密度值标准分级,故采用分位数的方法分级.依据四分位数间断值取25%,50%,75%,将密度值位于前25%位序的栅格确定为就业者居住密度的高值区.
-->Fig. 7Hinterlands of the typical employment centers in central city of Shanghai
-->
(2)整体上就业密度越高的中心通勤联系一般也越强,但依然存在个别例外,部分传统认知上能级较高的中心与其他地区的通勤联系较弱.如张杨路,长寿,四川北路的就业密度高于漕河泾经济技术开发区和中山公园,但从通勤联系来看恰恰相反,四川北路的能级远低于中山公园,只有后者的1/5.从区位和交通条件来看,中山公园和四川北路差异不大,甚至四川北路的交通条件更好.四川北路的能级较低可能与其就业岗位类型有关.中山公园有较多生产性服务业岗位(IT,设计等),对就业者学历,专业能力的要求较高,就业者来自全市范围;相比而言,有较多消费性服务业岗位的四川北路对就业者的要求不高,就业者多来自周边地区(图7).
4.2.4 就业中心综合能级
就业密度和通勤联系视角的能级虽然呈显著的线性正相关,但两者不一定完全一致,就业密度高的中心通勤联系有可能相对较弱.因此,就业中心的能级需要从就业密度和通勤联系两方面共同测度,只有就业密度高且通勤联系强的中心才能认为具有较高能级,以两者能级的乘积表征综合能级(下文若无说明,能级均指综合能级).
经计算,南京西路,南京东路外滩等5个中心属于一级中心,老西门豫园,徐家汇等8个中心属于二级中心,张杨路,新曹杨高新技术园区等6个中心属于三级中心(图8).
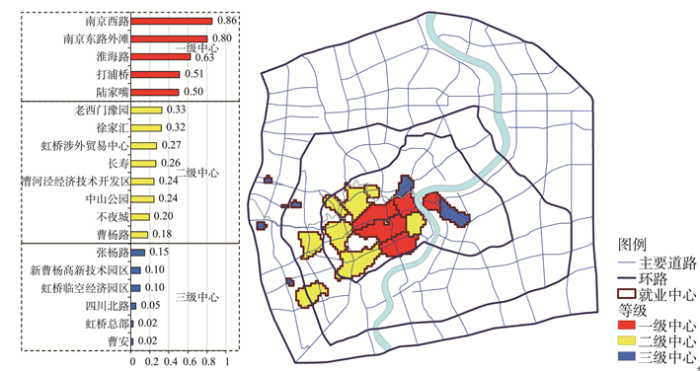 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图8上海中心城就业中心能级和等级
-->Fig. 8The grade of employment center in central city of Shanghai
-->
5 就业中心的腹地和势力范围分析
5.1 就业中心的腹地分析
腹地是指就业中心吸引和辐射的范围,即就业中心的就业者居住密度分布的范围.为比较各中心主要吸引和辐射地区的范围和分布,将密度值按分位数分为4个等级,25%密度位序为1的地区为就业者居住密度的高值区(图7).虽然张杨路紧邻陆家嘴,且腹地面积和陆家嘴相差不大,但其就业者居住密度高值区主要位于浦东,而陆家嘴的就业者居住密度高值区则在浦东和浦西均有分布.同样是两个紧邻的就业中心,四川北路和南京东路外滩的对比则更为显著,四川北路的腹地面积更小,且其就业者居住密度高值区主要位于中心城北部的虹口区.而南京东路外滩的腹地面积更大,就业者居住密度高值区遍布浦西和浦东陆家嘴,世博园.将腹地面积标准化得到腹地面积指标,测度其与能级的关系.随着能级的提高,腹地面积指标逐渐增加(图9),两者呈对数正相关(通过99%的置信区间检验,相关系数0.85,属极强相关).说明就业中心所能吸引和辐射的范围与能级有较大关系,能级越高范围越大,但随着能级提高,范围的增加幅度逐渐减小.
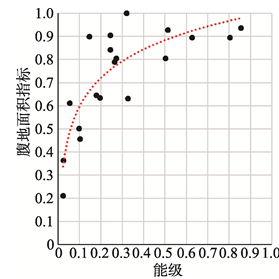 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图9上海中心城能级和腹地面积指标相关性检验
-->Fig. 9The relationship between the level and the size of hinterland in central city of Shanghai
-->
另一方面,腹地面积越大反映了就业者通勤距离可能越长,一般认为能级较高的中心职住平衡比例较低.为检验就业中心能级和职住平衡比例的关系,将代表工作地和居住地基站的直线距离4000 m(按1.4的非直线系数估算,4000 m基站距离约为5600 m实际路网距离或4~6站地铁距离)作为判断就业者是否达到职住平衡的标准,计算各中心的职住平衡比例.就业中心的职住平衡比例总体上呈随能级下降而提高的趋势,且多数就业中心的平均通勤距离大于中心城平均值4584 m(图10).其中陆家嘴的职住平衡比例最低(0.36),远低于中心城所有就业者的职住平衡比例(0.61),平均通勤距离长达7781 m(按1.4的非直线系数估算,实际可能超过10000 m).其次是南京东路外滩,南京西路等传统就业中心.但也有例外,老西门豫园的职住平衡比例高达0.81,甚至高于中心城(0.61);平均通勤距离也只有2681 m,远低于中心城.经计算,能级和职住平衡比例的相关性并不强(虽能通过99%的置信区间检验,但相关系数仅为-0.60),说明就业中心的能级并不是影响职住平衡的决定性因素.
究其原因,老西门不仅是就业中心还是传统高密度居住地区,本身就有较多居住功能.根据Mcmillen等[28]的研究,就业者一般愿意承担更高的住房成本居住在工作地附近以减少通勤时间.对就业中心来说,若能提供较多的居住选择,提高职住功能混合度,就能提高职住平衡比例.以就业密度和居住密度的比值表征职住功能混合度(比值越趋近于1混合度越高,比值越高就业功能越多,比值越低居住功能越多相应的混合度越低),测度就业中心职住功能比与职住平衡的关系.两者呈幂函数负相关(通过99%的置信区间检验,相关系数-0.81)(图11).职住平衡比例高于0.6(60%以上就业的者通勤直线距离小于4000 m)的就业中心,职住功能比多数不超过1.5,即每规划3个就业岗位需要至少配套可供2个就业者居住的居住单元才有可能使就业中心有较高的职住平衡比例.说明在规划中为缓解就业中心职住分离问题,倡导就业中心自身的就业,居住功能混合是有效的方法.即使是能级较高的就业中心也能通过职住功能混合提高职住平衡.
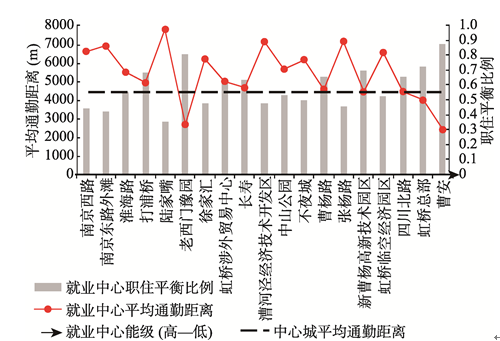 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图10上海中心城就业中心职住平衡比例和平均通勤距离
-->Fig. 10The level of job-housing balance and the average commuting distance for employment centers in central city of Shanghai
-->
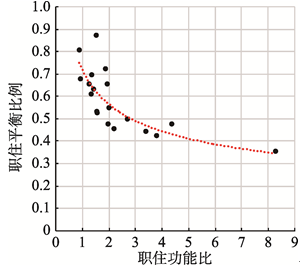 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图11上海中心城职住功能比和职住平衡比例相关性检验
-->Fig. 11The relationship of the mix level of job-housing and the level of job-housing balance in central city of Shanghai
-->
5.2 就业中心的势力范围分析
势力范围是指由就业者居住密度占主导的就业中心划分的空间单元.以第293393号栅格为例,各中心就业者居住密度在该栅格上的值如表4所示,南京西路最高,该栅格属于南京西路的势力范围.据此每个栅格都可确定属于哪个就业中心的势力范围,且每个栅格只属于一个中心.由图12得到以下4点结论:① 各就业中心自身就是其势力范围;② 势力范围存在飞地;③ 黄浦江对势力范围的空间分隔作用较明显,浦西,浦东的就业中心基本被局限在各自范围内;④ 离就业中心较远的地区势力范围呈交替状.Tab. 4
Tab. 4The residential density of each center in the grid of No. 293393 (人/km2)
| 名称 | 就业者居住密度 | 名称 | 就业者居住密度 | 名称 | 就业者居住密度 | 名称 | 就业者居住密度 | 名称 | 就业者居住密度 |
|---|---|---|---|---|---|---|---|---|---|
| 南京西路 | 3509.90 | 长寿 | 1351.13 | 淮海路 | 341.82 | 南京东路外滩 | 243.02 | 陆家嘴 | 162.75 |
| 中山公园 | 152.68 | 徐家汇 | 145.32 | 打浦桥 | 110.26 | 不夜城 | 90.25 | 虹桥涉外贸易中心 | 89.60 |
| 曹杨路 | 81.83 | 张杨路 | 68.88 | 漕河泾经济技术开发区 | 57.41 | 老西门豫园 | 46.00 | 四川北路 | 28.17 |
| 新曹杨 | 9.26 | 虹桥临空经济园区 | 8.94 | 虹桥总部 | 0.07 | 曹安 | 0.02 |
新窗口打开
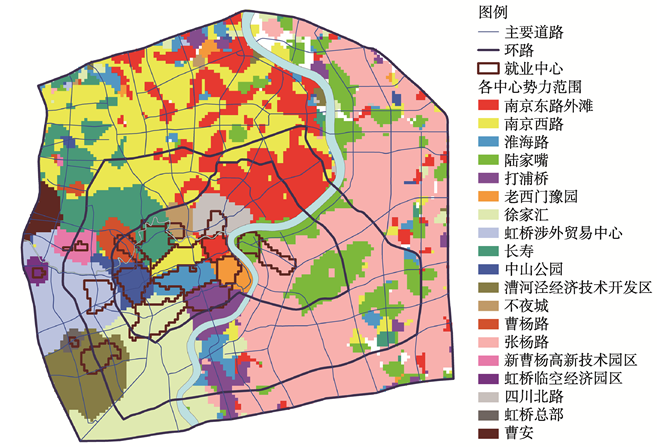 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图12上海中心城就业中心势力范围
-->Fig. 12The influence areas of each employment center in central city of Shanghai
-->
具体来看,中心城北部的大部分地区是南京东路外滩,南京西路,长寿的势力范围,南京西路在浦西中环以北占据较多势力范围,南京东路外滩在地铁1号,3号线北段周边有到较多的势力范围.中心城西南大部分地区是虹桥涉外贸易中心,漕河泾经济技术开发区,徐家汇的势力范围,三者的界线较清晰.浦东大部分地区是张杨路的势力范围,陆家嘴的势力范围主要沿地铁2号线和浦东北部黄浦江一带分布,而世博园以南则成为了淮海路,打浦桥,南京西路,徐家汇等中心的势力范围交替区.距就业中心较远的中心城北部,东部邻近外环线地区是南京东路外滩,南京西路,陆家嘴等中心的势力范围交替区.
值得注意的是陆家嘴基于通勤联系视角的能级较高而势力范围并不大,这是由于陆家嘴的腹地主要位于浦西,但与南京东路外滩,南京西路相比,其就业者在浦西的居住密度并不高,而在浦东大部分地区,陆家嘴的就业者居住密度又不如张杨路高.老西门豫园,淮海路等中心也存在类似情况.因此,就业中心的势力范围面积虽然和腹地面积仍存在较弱的相关性(相关系数0.55,能通过95%的置信区间检验),但与能级基本不相关(相关系数仅为0.39,未能通过90%的置信区间检验).
通过势力范围的分析可知,就业中心周边势力范围划分较明确,无就业中心的地 区势力范围呈交替状,两者形成了较鲜明的对比.在浦西内环以北和浦东内环以外,特别是在势力范围交替较显著的地区增加新的就业中心是构建就业多中心体系的有效手段.
6 结论和讨论
6.1 结论
针对既往就业中心体系研究缺少较小空间单元的就业者通勤数据的问题,利用手机信令数据从约1700万常住用户中获取了约680万用户的就业通勤数据,其中中心城326万用户的通勤数据可通过2.7万个基站进行空间定位.无论是样本量(就业者抽样率54.3%)还是空间单元精度(中心城平均每个基站单元面积约2.5 hm2)均远高于传统调查,统计数据.在此基础上用就业密度识别就业中心,分别用就业密度和通勤联系测度就业中心能级,用各中心就业者居住地分布划分腹地,就业者居住密度占比划分势力范围.研究发现:① 上海中心城就业岗位主要集聚在地铁2号线两侧,浦西内环以北和浦东内环以外无高密度就业集聚区;② 就业中心的等级呈圈层状由中心向外递减,呈主中心强大的弱多中心体系;③ 陆家嘴,南京东路外滩等传统认知上的就业中心的就业密度普遍较高,与其他地区的通勤联系较强,吸引和辐射范围也较大;④ 相比于就业密度,各中心与其他地区的通勤联系差异更加显著;⑤ 能级越高的中心职住平衡比例不一定越低,职住平衡与职住功能混合度的关系更大,混合度越高职住越平衡.⑥ 缺少就业中心的浦西内环以北和浦东内环以外地区是多个就业中心的势力范围交替区.
6.2 讨论
6.2.1 关于手机信令数据特点手机信令数据是一种由事件激发的时空轨迹数据,存在时空分辨率较低的特点.本文通过单日日间10:00-16:00,夜间00:00-04:00各5个特征时间点,一周5个工作日,设定60%的重复率反复识别,尽量保证识别到的就业地和居住地代表的基站为距用户真实就业地和居住地最近的基站.虽然基站定位可能会存在数百米误差,在上海中心城664 km2范围内测度就业中心,手机信令数据的空间分辨率还是可以接受的.
经济普查有就业者真实的就业地数据,人口普查有就业者真实的居住地数据,比用手机信令数据识别的就业地和居住地更加准确.但经济普查的就业地,人口普查的居住地两者之间无法建立联系.与传统数据相比,手机信令数据特点是能同时获取就业者的就业地和居住地,建立两者之间的空间联系.另一方面,手机信令数据只包含"个体--什么时候--在什么地方"的信息[29].用户的行为目的只能按一般行为规律判断.按目前识别方法,对于无固定工作地(如出租车司机),非8小时工作制(如部分服务业就业者)就无法同时识别出工作地和居住地.如何提高这些用户的识别率,需要进一步研究.此外,手机信令数据并不涉及社会经济属性,只能对就业中心体系进行描述性分析,无法分析就业者年龄,职业,收入等因素的对就业中心体系的影响.
6.2.2 关于就业中心体系测度方法
利用手机信令数据,就业中心识别的空间单元摆脱了既定空间单元(一般是街道)的限制,在200 m×200 m的栅格下,基本可根据就业中心实际范围进行识别,有助于识别实际存在,但因所属空间单元较大而难以依据空间单元平均就业密度识别的就业中心,也有助于识别因跨越空间单元而难以划定真实边界的就业中心.与以往用就业密度识别上海中心城就业中心的研究成果[1]相比,本文也识别出了南京东路外滩,淮海路,徐家汇等中心,但是张江,外高桥等产业园区未被识别为就业中心,而规模较小的虹桥总部,新曹杨高新技术园区等地区被识别为就业中心.这可能是由于空间单元差异造成的,也可能与就业中心的界定有一定关系,就本文的识别结果来看,就业中心均为就业高度密集的商务办公或商业区.
此外,用功能联系测度能级的方法学术界尚在探讨中.考虑本文的研究尺度为上海中心城,与Vasanen的研究尺度--中心建成区(Central Built-up Area)[7]较为接近,故采用考虑空间权重的通勤联系紧密程度(R2)测度能级.虽然方法比使用通勤联系量(仅考虑从中心外部吸引就业者的数量,不考虑这些就业者所在的空间位置)复杂,但在中心城尺度更有助于反映就业中心是否对更多的就业者在就业和居住空间选择上产生影响.
6.3 若干建议
本文希望能有助于加深对上海中心城就业中心体系的认知,明确各中心的能级,腹地,势力范围等之间的相关关系和相关程度.研究还发现了某些地区缺少就业中心,某些就业中心职住分离较严重等问题,建议规划可通过土地使用调整,交通设施建设,公共设施配置等手段有针对性地解决这些问题,以帮助构建就业多中心体系.例如,浦西内环以北无符合识别条件的就业中心,这一地区同时也是势力范围交替最频繁的地区,部分就业者需要通勤较远距离前往内环内的就业中心工作,这与职住平衡的发展导向不符.因此,建议在这些地区发展新的就业中心.并且即便是高等级的就业中心要也倡导土地混合利用,避免出现大面积功能单一的就业集聚区.The authors have declared that no competing interests exist.
参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
| [1] | 国内特大城市纷纷采取多中心空间战略来缓解单中心蔓延带来的城市 问题,但是否有效却缺乏系统严谨的检验.从国内外大城市实施多中心战略的效果来看,各方评价褒贬不一,发达国家关于多中心结构能否缓解城市交通拥堵的实证 研究更是对多中心理念的绩效提出了质疑.现通过对上海的实证研究来检验多中心理念的有效性,为我国特大城市多中心战略提供决策依据.运用统计方法和问卷调 查数据对上海中心城区的分析显示,就业中心距主中心越远,其就业者的平均通勤时耗越低,因而强化多中心结构有助于降低整体通勤时耗;外围地区交通路况宽松 和小汽车通勤比率高是多中心结构降低通勤时耗的主要机制,职住平衡在理论上应该是多中心结构降低通勤的机制之一,但在上海案例中没有呈现出随多中心强化而 提高的态势.改善上海交通,应该塑造和强化多中心的空间结构,促进职住平衡和提高外围就业中心交通可达性是重要保障措施. 国内特大城市纷纷采取多中心空间战略来缓解单中心蔓延带来的城市 问题,但是否有效却缺乏系统严谨的检验.从国内外大城市实施多中心战略的效果来看,各方评价褒贬不一,发达国家关于多中心结构能否缓解城市交通拥堵的实证 研究更是对多中心理念的绩效提出了质疑.现通过对上海的实证研究来检验多中心理念的有效性,为我国特大城市多中心战略提供决策依据.运用统计方法和问卷调 查数据对上海中心城区的分析显示,就业中心距主中心越远,其就业者的平均通勤时耗越低,因而强化多中心结构有助于降低整体通勤时耗;外围地区交通路况宽松 和小汽车通勤比率高是多中心结构降低通勤时耗的主要机制,职住平衡在理论上应该是多中心结构降低通勤的机制之一,但在上海案例中没有呈现出随多中心强化而 提高的态势.改善上海交通,应该塑造和强化多中心的空间结构,促进职住平衡和提高外围就业中心交通可达性是重要保障措施. |
| [2] | 当前,国内特大城市纷纷采取多中心空间发展战略来缓解单中心集聚 带来的城市病,然而在实践中次中心往往难以形成,因而明晰就业次中心的形成机制对于多中心城市结构建设具有重要意义.现以上海都市区为例,运用 logistic回归模型探讨其就业次中心的形成机制,并与北京都市区研究结果进行了比较.结果发现,丰富的劳动力要素与交通基础设施对于上海和北京就业 次中心的形成具有重要作用;人力资本与距高速公路距离对上海都市区就业次中心形成也具有正面影响;主、次中心的空间相对位置和经济结构因素也显著影响次中 心的形成,但北京和上海具体表现有所不同,北京就业次中心倾向于靠近主中心分布,服务业增长较快的空间单元更有可能发展成为就业次中心;而上海就业次中心 倾向于远离主中心分布,制造业和服务业发展均对就业次中心形成具有显著影响.此外,政策对于北京、上海就业次中心的形成具有一定促进作用,但效应并不如预 期明显. 当前,国内特大城市纷纷采取多中心空间发展战略来缓解单中心集聚 带来的城市病,然而在实践中次中心往往难以形成,因而明晰就业次中心的形成机制对于多中心城市结构建设具有重要意义.现以上海都市区为例,运用 logistic回归模型探讨其就业次中心的形成机制,并与北京都市区研究结果进行了比较.结果发现,丰富的劳动力要素与交通基础设施对于上海和北京就业 次中心的形成具有重要作用;人力资本与距高速公路距离对上海都市区就业次中心形成也具有正面影响;主、次中心的空间相对位置和经济结构因素也显著影响次中 心的形成,但北京和上海具体表现有所不同,北京就业次中心倾向于靠近主中心分布,服务业增长较快的空间单元更有可能发展成为就业次中心;而上海就业次中心 倾向于远离主中心分布,制造业和服务业发展均对就业次中心形成具有显著影响.此外,政策对于北京、上海就业次中心的形成具有一定促进作用,但效应并不如预 期明显. |
| [3] | . 基于城市空间结构的经典理论和就业中心识别的实证方法.利用北京 市2001年和2004年的就业人口数据,在验证主中心存在的同时,采用两阶段方法,对次中心进行了识别.结果表明,北京目前仍然是一个单中心主导的城市 空间结构,单中心方程对城市总体就业人口密度的解释能力超过了60%.但随着都市区的扩张,中关村等次中心开始陆续出现,并开始影响周边地区的就业分布和 空间形态,这表明北京正向多中心的空间结构转变.此外,还也结合北京城市增长、制度转型和历史路径依赖的特点,对北京城市空间结构的演变机理进行了分析. . 基于城市空间结构的经典理论和就业中心识别的实证方法.利用北京 市2001年和2004年的就业人口数据,在验证主中心存在的同时,采用两阶段方法,对次中心进行了识别.结果表明,北京目前仍然是一个单中心主导的城市 空间结构,单中心方程对城市总体就业人口密度的解释能力超过了60%.但随着都市区的扩张,中关村等次中心开始陆续出现,并开始影响周边地区的就业分布和 空间形态,这表明北京正向多中心的空间结构转变.此外,还也结合北京城市增长、制度转型和历史路径依赖的特点,对北京城市空间结构的演变机理进行了分析. |
| [4] | . 本研究应用非参数计量方法,实证刻画北京都市区人口—就业空间分布演化,揭示在快速城市化和城市增长背景下,北京都市区空间结构特征及发展趋势。研究发现,北京都市区人口和就业分布都呈现多中心空间结构。20 世纪80 年代以来,随着人口郊区化,北京都市区人口次中心数量不断增加,并由近郊向远郊扩展,人口分布呈现明显的分散化和多中心化趋势,但人口分散的空间范围还比较有限。与人口的分散化趋势不同,2004-2008 年,北京都市区就业仍呈现向心集聚的趋势,造成远郊就业次中心的影响不断被弱化,都市区空间结构的多中心性有所降低。这说明北京都市区的单中心或强中心结构可能并未从根本上改变,且人口的分散化和就业的向心集聚导致宏观面上人口—就业的空间失衡。北京都市区多中心空间结构的形成,需要强化郊区次中心的集聚能力,同时注重人口—就业的平衡布局,这是未来北京都市区空间结构调整的重点。 . 本研究应用非参数计量方法,实证刻画北京都市区人口—就业空间分布演化,揭示在快速城市化和城市增长背景下,北京都市区空间结构特征及发展趋势。研究发现,北京都市区人口和就业分布都呈现多中心空间结构。20 世纪80 年代以来,随着人口郊区化,北京都市区人口次中心数量不断增加,并由近郊向远郊扩展,人口分布呈现明显的分散化和多中心化趋势,但人口分散的空间范围还比较有限。与人口的分散化趋势不同,2004-2008 年,北京都市区就业仍呈现向心集聚的趋势,造成远郊就业次中心的影响不断被弱化,都市区空间结构的多中心性有所降低。这说明北京都市区的单中心或强中心结构可能并未从根本上改变,且人口的分散化和就业的向心集聚导致宏观面上人口—就业的空间失衡。北京都市区多中心空间结构的形成,需要强化郊区次中心的集聚能力,同时注重人口—就业的平衡布局,这是未来北京都市区空间结构调整的重点。 |
| [5] | . We investigate employment subcenters in the Los Angeles region using09銇641980 Census journey-towork data. A simple subcenter definition is used, based solely on gross employment density and total employment. We find a surprising dominance of downtown Los Angeles and three large subcenters with which it forms a nearly contiguous corridor. Two-thirds of the region09銇64s employment, however, is outside any of the 32 centers we identify. Most centers have high population densities in and near them, and their workers09銇64 commutes are just 2.4 miles longer than other workers09銇64 commutes. A cluster analysis of employment by industry reveals several distinct types of centers, and a Wide dispersion of sizes and locations within each type. |
| [6] | . |
| [7] | . |
| [8] | |
| [9] | . 本文分析了2008年北京市就业密度空间分布的现状结构,并运用非参数局部回归的方法模拟了2004年和2008年北京市的就业密度曲线,进而分析北京市就业密度分布的空间特征。研究表明:从就业密度的角度,2004年~2008年间,在城市规划的引导作用下,尽管城市单中心结构仍然突出,经济空间结构已经开始出现多中心发展的雏形。其中制造业就业密度呈现出非常显著的郊区化特征,而第三产业则持续地向城市中心区高度聚集。综合来看,单中心集聚力量的延续对未来北京市发展将有可能造成进一步的困扰,如中心城过度拥挤、职住分离、交通压力加大等,建议通过政策手段加快布局调整,进一步培育具有一定规模和集聚能力的郊区次中心,构建"多中心、网络化"的空间结构。 . 本文分析了2008年北京市就业密度空间分布的现状结构,并运用非参数局部回归的方法模拟了2004年和2008年北京市的就业密度曲线,进而分析北京市就业密度分布的空间特征。研究表明:从就业密度的角度,2004年~2008年间,在城市规划的引导作用下,尽管城市单中心结构仍然突出,经济空间结构已经开始出现多中心发展的雏形。其中制造业就业密度呈现出非常显著的郊区化特征,而第三产业则持续地向城市中心区高度聚集。综合来看,单中心集聚力量的延续对未来北京市发展将有可能造成进一步的困扰,如中心城过度拥挤、职住分离、交通压力加大等,建议通过政策手段加快布局调整,进一步培育具有一定规模和集聚能力的郊区次中心,构建"多中心、网络化"的空间结构。 |
| [10] | . 研究以非参数模型计量为基础,从集聚—分散维度和单中心—多中心维度刻画了上海都市区就业、人口空间演化特征,并与北京都市区的研究结果进行了横向比较。研究表明,上海都市区的就业和人口不断向外扩散,同时近、远郊均出现了稳定的再集中,就业和人口的空间多中心性都在增强。而北京只存在人口的分散化和多中心化,就业却呈现集中化和单中心化的态势。因而,上海都市区的就业—人口空间匹配程度高于北京。产业结构差异是造成北京、上海两地就业空间演化特征分异的原因之一,上海制造业比重高于北京,郊区的制造业集聚强化了近、远郊吸纳就业能力,促进了多中心空间结构的形成。北京和上海中心城区的就业、人口规模仍在扩张,导致近邻地区被包络在内,原有的次中心逐渐消失,因而,科学确定中心城区的增长边界,有效防止邻近蔓延,应当成为特大城市未来发展的关注重点。 . 研究以非参数模型计量为基础,从集聚—分散维度和单中心—多中心维度刻画了上海都市区就业、人口空间演化特征,并与北京都市区的研究结果进行了横向比较。研究表明,上海都市区的就业和人口不断向外扩散,同时近、远郊均出现了稳定的再集中,就业和人口的空间多中心性都在增强。而北京只存在人口的分散化和多中心化,就业却呈现集中化和单中心化的态势。因而,上海都市区的就业—人口空间匹配程度高于北京。产业结构差异是造成北京、上海两地就业空间演化特征分异的原因之一,上海制造业比重高于北京,郊区的制造业集聚强化了近、远郊吸纳就业能力,促进了多中心空间结构的形成。北京和上海中心城区的就业、人口规模仍在扩张,导致近邻地区被包络在内,原有的次中心逐渐消失,因而,科学确定中心城区的增长边界,有效防止邻近蔓延,应当成为特大城市未来发展的关注重点。 |
| [11] | . Empirical research establishing the costs and benefits that can be associated with polycentric urban systems is often called for but rather thin on the ground. In part, this is due to the persistence of what appear to be two analytically distinct approaches in understanding and measuring polycentricity: a morphological approach centring on nodal features and a functional approach focused on the relations between centres. Informed by the oft-overlooked but rich heritage of urban systems research, this paper presents a general theoretical framework that links both approaches and discusses the way both can be measured and compared in a coherent manner. Using the Netherlands as a test case, it is demonstrated that most regions tend to be more morphologically polycentric than functionally polycentric. The difference is largely explained by the size, external connectivity and degree of self-sufficiency of a region09銇64s principal centre. |
| [12] | . Polycentricity is often used descriptively with regard to a regional system of settlements, usually referred to as a polycentric urban region (PUR). Although presented in much of the literature as in essence a morphological concept, polycentricity possesses a functional element that receives less attention. Polycentricity is also seen as a normative concept. However, it has not been rigorously defined using formal techniques. This paper argues that defining polycentricity in terms of both morphology and function is possible by drawing on techniques originating in social network analysis. The paper sets out a formal definition and derivation of functional polycentricity based on these techniques, which is then extended to a derivation of an index of regional functional polycentricity. The paper sets out worked examples to show how the techniques described might be utilised. The paper closes with a discussion of issues that may arise when putting these definitions into practice. |
| [13] | . HINTERLAND BOUNDARIES OF NEW YORK CITY AND BOSTON IN SOUTHERN NEWENGLAND Howard L. Green The purpose of this paper is to define and analyze the hinterlandbound- aries in southern New England between two such large cities, New York and Boston. |
| [14] | . 以辐射强度最大法和电话流首位 对地法为基础开发研制了城镇势力圈分析计算机系统HAP。并以上虞市为例分析了势力圈的空间特征和动态变化。揭示了势力圈所具有的空间特征 ,包括势力圈边界由圆弧段构成 ;圆弧的位置及凹凸关系由相邻城镇的规模大小决定 ;势力圈之间存在并存、包含和竞争三种关系。 . 以辐射强度最大法和电话流首位 对地法为基础开发研制了城镇势力圈分析计算机系统HAP。并以上虞市为例分析了势力圈的空间特征和动态变化。揭示了势力圈所具有的空间特征 ,包括势力圈边界由圆弧段构成 ;圆弧的位置及凹凸关系由相邻城镇的规模大小决定 ;势力圈之间存在并存、包含和竞争三种关系。 |
| [15] | . |
| [16] | . The paper will present the main results of research aimed at evaluating different mobile phone data sources for urban analysis and planning for the Monza and Brianza Province (Northern Italy) during 2011. In order to analyze the complex temporal and spatial patterns of this spatial context, the authors used several mobile phone traffic data (i.e. Erlang measures, SMS counts, MSC active clients counts), provided by Telecom Italia, covering two time slots in 2009 and 2010. They therefore integrated manifold mobile phone network data sources in a systemic way for a comprehensive evaluation of the overall potential of these data in describing urban dynamics. |
| [17] | . 基于位置服务(Location Based Service, LBS) 技术为研究城市系统的时空动态规律提供了新的视角, 已往多基于移动通讯(GSM)、全球定位系统(GPS)、社会化网络(SNS) 和无线宽带热点(Wi-Fi) 数据开展研究, 但少有研究利用公交IC 卡刷卡数据进行城市系统分析。普遍存在的LBS数据虽然具有丰富的时间和空间信息, 但缺乏社会维度信息, 使其应用范围受到一定限制。本文基于2008 年北京市连续一周的公交IC 卡(Smart Card Data, SCD) 刷卡数据, 结合2005 年居民出行调查、地块级别的土地利用图, 识别公交持卡人的居住地、就业地和通勤出行, 并将识别结果在公交站点和交通分析小区(TAZ) 尺度上汇总:① 将识别的通勤出行分别从通勤时间和距离角度, 与居民出行调查数据和其他已有北京相关研究进行对比, 显示较好的吻合性;② 对来自3 大典型居住区和去往6 大典型办公区的通勤出行进行可视化并对比分析;③ 对全市基于公交的通勤出行进行可视化, 并识别主要交通流方向。本研究初步提出了从传统的居民出行调查和城市GIS 数据建立规则, 用于SCD数据挖掘的方法, 具有较好的可靠性。 . 基于位置服务(Location Based Service, LBS) 技术为研究城市系统的时空动态规律提供了新的视角, 已往多基于移动通讯(GSM)、全球定位系统(GPS)、社会化网络(SNS) 和无线宽带热点(Wi-Fi) 数据开展研究, 但少有研究利用公交IC 卡刷卡数据进行城市系统分析。普遍存在的LBS数据虽然具有丰富的时间和空间信息, 但缺乏社会维度信息, 使其应用范围受到一定限制。本文基于2008 年北京市连续一周的公交IC 卡(Smart Card Data, SCD) 刷卡数据, 结合2005 年居民出行调查、地块级别的土地利用图, 识别公交持卡人的居住地、就业地和通勤出行, 并将识别结果在公交站点和交通分析小区(TAZ) 尺度上汇总:① 将识别的通勤出行分别从通勤时间和距离角度, 与居民出行调查数据和其他已有北京相关研究进行对比, 显示较好的吻合性;② 对来自3 大典型居住区和去往6 大典型办公区的通勤出行进行可视化并对比分析;③ 对全市基于公交的通勤出行进行可视化, 并识别主要交通流方向。本研究初步提出了从传统的居民出行调查和城市GIS 数据建立规则, 用于SCD数据挖掘的方法, 具有较好的可靠性。 |
| [18] | . Delineating travel patterns and city structure has long been a core research topic in transport geography. Different from the physical structure, the city structure beneath the complex travel-flow system shows the inherent connection patterns within the city. On the basis of taxi-trip data from Shanghai, we built spatially embedded networks to model intra-city spatial interactions and to introduce network science methods into the analysis. The community detection method is applied to reveal sub-regional structures, and several network measures are used to examine the properties of sub-regions. Considering the differences between long- and short-distance trips, we reveal a two-level hierarchical polycentric city structure in Shanghai. Further explorations of sub-network structures demonstrate that urban sub-regions have broader internal spatial interactions, while suburban centers are more influential on local traffic. By incorporating the land use of centers from a travel-pattern perspective, we investigate sub-region formation and the interaction patterns of center鈥搇ocal places. This study provides insights into using emerging data sources to reveal travel patterns and city structures, which could potentially aid in developing and applying urban transportation policies. The sub-regional structures revealed in this study are more easily interpreted for transportation-related issues than for other structures, such as administrative divisions. |
| [19] | . Most of the existing literature focuses on estimating traffic or explaining trip lengths from land use. This research attempts to reveal intraurban land use variations from traffic patterns. Using a seven-day taxi trajectory data set collected in Shanghai, we investigate the temporal variations of both pick-ups and drop-offs, and their association with different land use features. Based on the balance between the numbers of drop-offs and pick-ups and its distinctive temporal patterns, the study area is classified into six traffic ‘source-sink’ areas. These areas are closely associated with various land use types (commercial, industrial, residential, institutional and recreational) as well as land use intensity. The study shows that human mobility data from location aware devices provide us an opportunity to derive urban land use information in a timely fashion, and help urban planners and policy makers in mitigating traffic, planning for public services and resources, and other purposes. |
| [20] | . To summarize, our approach yields important insights into urban phenomena generated by human movements. It represents a quantitative approach to urban analysis, which explicitly identifies ongoing urban transformations. |
| [21] | . |
| [22] | . The spatial arrangement of urban hubs and centers and how individuals interact with these centers is a crucial problem with many applications ranging from urban planning to epidemiology. We utilize here in an unprecedented manner the large scale, real-time ‘Oyster’ card database of individual person movements in the London subway to reveal the structure and organization of the city. We show that patterns of intraurban movement are strongly heterogeneous in terms of volume, but not in terms of distance travelled, and that there is a polycentric structure composed of large flows organized around a limited number of activity centers. For smaller flows, the pattern of connections becomes richer and more complex and is not strictly hierarchical since it mixes different levels consisting of different orders of magnitude. This new understanding can shed light on the impact of new urban projects on the evolution of the polycentric configuration of a city and the dense structure of its centers and it provides an initial approach to modeling flows in an urban system. |
| [23] | 以上海中心城为例,提出了利用手机定位数据识别城市空间结构的方 法.首先,使用移动通讯基站地理位置数据和手机信令数据,依据基站汇总所连接用户数量,采用核密度分析法生成手机用户密度图,分别计算了上海中心城内工作 日10点和23点、休息日15点和23点的多日平均用户密度图.随后,对工作日10点、休息日15点的手机用户密度空间分布进行空间聚类和密度分级,用于 识别城市公共中心的等级和职能类型.最后,对工作日、休息日昼夜手机用户密度比值、夜间手机用户密度进行比较,用于识别就业、游憩、居住功能区及其混合程 度. 以上海中心城为例,提出了利用手机定位数据识别城市空间结构的方 法.首先,使用移动通讯基站地理位置数据和手机信令数据,依据基站汇总所连接用户数量,采用核密度分析法生成手机用户密度图,分别计算了上海中心城内工作 日10点和23点、休息日15点和23点的多日平均用户密度图.随后,对工作日10点、休息日15点的手机用户密度空间分布进行空间聚类和密度分级,用于 识别城市公共中心的等级和职能类型.最后,对工作日、休息日昼夜手机用户密度比值、夜间手机用户密度进行比较,用于识别就业、游憩、居住功能区及其混合程 度. |
| [24] | . 用手机数据识别了用户的日间驻 留地、夜间驻留地,从中提取出日间在上海中心城内驻留用户、夜间在中心城内驻留用户,分别计算出其通勤范围。根据其夜间驻留地、日间驻留地的分布密度识别 出上海中心城的通勤圈,并将其转换为以街道行政边界为空间单元的中心城通勤区。在中心城及通勤区内,超过97%的居民实现了职住平衡。研究表明上海市域空 间结构在"中心城"和"郊区"之间还存在一个"中心城通勤区"层次。中心城通勤区以内、以外区域存在较显著差异。中心城通勤区的识别结果可加深对上海市域 空间结构的认识,为在市域范围内分层次、分区域制定有针对性的规划政策提供依据。 . 用手机数据识别了用户的日间驻 留地、夜间驻留地,从中提取出日间在上海中心城内驻留用户、夜间在中心城内驻留用户,分别计算出其通勤范围。根据其夜间驻留地、日间驻留地的分布密度识别 出上海中心城的通勤圈,并将其转换为以街道行政边界为空间单元的中心城通勤区。在中心城及通勤区内,超过97%的居民实现了职住平衡。研究表明上海市域空 间结构在"中心城"和"郊区"之间还存在一个"中心城通勤区"层次。中心城通勤区以内、以外区域存在较显著差异。中心城通勤区的识别结果可加深对上海市域 空间结构的认识,为在市域范围内分层次、分区域制定有针对性的规划政策提供依据。 |
| [25] | . Cellular data from call detail records can help urban planners better understand city dynamics. The authors use CDR data to analyze people flow in and out of a suburban city near New York City. |
| [26] | . The article introduces a model for the location of meaningful places for mobile telephone users, such as home and work anchor points, using passive mobile positioning data. Passive mobile positioning data is secondary data concerning the location of call activities or handovers in network cells that is automatically stored in the memory of service providers. This data source offers good potential for the monitoring of the geography and mobility of the population, since mobile phones are widespread, and similar standardized data can be used around the globe. We developed the model and tested it with 12 months' data collected by EMT, Estonia's largest mobile service provider, covering more than 0.5 million anonymous respondents. Modeling results were compared with population register data; this revealed that the developed model described the geography of the population relatively well, and can hence be used in geographical and urban studies. This approach also has potential for the development of location-based services such as targeting services or geographical infrastructure. |
| [27] | . <b>目的</b>使用大规模手机定位数据获取居民职住地分布是大数据趋势下城市研究的新兴技术。然而,现有的研究主要使用了长期不规则稀疏采样的手机通话数据,对短期规则采样的手机定位数据缺乏尝试。基于大规模短期规则采样的手机定位数据,提出了一种居民职住地识别的方法。这是首次从大规模短期规则采样的手机定位数据中进行居民职住地识别的尝试,并对识别结果进行了较全面的验证。该研究成果为职住平衡等相关城市问题研究探讨了一种新型大规模数据源的可行性,在低成本大幅度提高相关研究的样本代表性和分析结果可靠性上具有重要意义。 . <b>目的</b>使用大规模手机定位数据获取居民职住地分布是大数据趋势下城市研究的新兴技术。然而,现有的研究主要使用了长期不规则稀疏采样的手机通话数据,对短期规则采样的手机定位数据缺乏尝试。基于大规模短期规则采样的手机定位数据,提出了一种居民职住地识别的方法。这是首次从大规模短期规则采样的手机定位数据中进行居民职住地识别的尝试,并对识别结果进行了较全面的验证。该研究成果为职住平衡等相关城市问题研究探讨了一种新型大规模数据源的可行性,在低成本大幅度提高相关研究的样本代表性和分析结果可靠性上具有重要意义。 |
| [28] | . Bid-rent theory suggests that the dependent variable of a population density function is unobserved (or population equals zero) if land values are relatively low in residential use. If the errors of density and bid-rent function errors are correlated, bid-rent theory implies that OLS population density estimates are subject to selection bias. Combined land use and density estimates for suburban Chicago confirm these predictions. The results provide further evidence that Chicago cannot be modelled adequately as other than a polycentric city. |
| [29] | . 聚焦城市空间的移动定位大数据 研究可分为空间现象描述、空间功能识别、理论模型验证、中心体系分析4种类型。通过文献梳理,发现大数据为空间研究提供了丰富的样本,但当前的数据存在非 全样本、缺少社会经济属性、非随机缺失的缺陷。大数据研究的广度和深度正在不断扩展,呈现出多学科参与的特点,但研究结论还缺少新的理论探索和解决实际问 题的应用。据此提出当前的大数据只是传统数据的有益补充,适用于描述、分析空间现象和规律,适宜于两方面研究:1验证理论模型、提出研究问题;2分析空间 现状、评估空间规划。这两方面研究可通过统计汇总和空间计算的方法实现。 . 聚焦城市空间的移动定位大数据 研究可分为空间现象描述、空间功能识别、理论模型验证、中心体系分析4种类型。通过文献梳理,发现大数据为空间研究提供了丰富的样本,但当前的数据存在非 全样本、缺少社会经济属性、非随机缺失的缺陷。大数据研究的广度和深度正在不断扩展,呈现出多学科参与的特点,但研究结论还缺少新的理论探索和解决实际问 题的应用。据此提出当前的大数据只是传统数据的有益补充,适用于描述、分析空间现象和规律,适宜于两方面研究:1验证理论模型、提出研究问题;2分析空间 现状、评估空间规划。这两方面研究可通过统计汇总和空间计算的方法实现。 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}